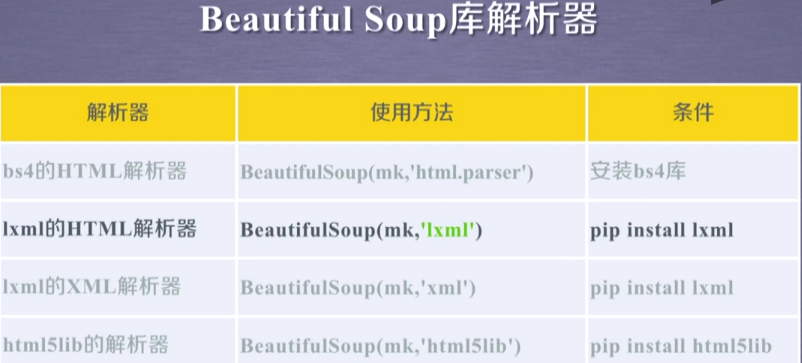
Beautiful Soup
1、BeautifulSoup安装:pip install beautifulsoup4
2、BeautifulSoup使用:
#倒入demo样例 import requests def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' demo = getHTMLText(url) print(demo)
#BeautifulSoup使用 import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup)
3、BeautifulSoup库的基本元素:
BeautifulSoup库是解析、遍历、维护‘标签树’的功能库

import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.a) #<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> print(soup.a.name) #a print(soup.a.attrs) #{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'} print(soup.a.string) #Basic Python print(soup.a.comment) #None
4、基于bs4的HTML的遍历方法
1)下行遍历:从根向叶子遍历

import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.head) #<head><title>This is a python demo page</title></head> print(len(soup.body.contents)) #5 for tag in soup.body.children: print(tag)
2)上行遍历:从叶子向根遍历

import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.a.parent.name) #p for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name) #p body html [document]
3)平行遍历:同级之间遍历(同一父元素的兄弟元素才同用平行遍历)


import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.a.next_sibling) # and print(soup.a.previous_sibling) #Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
5、基于bs4的HTML的格式输出
bs4库的prettify()方法
import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup) print(soup.prettify()) /*
#print(soup)输出 <html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> </body></html>
#print(soup.prettify())输出 <html> <head> <title> This is a python demo page </title> </head> <body> <p class="title"> <b> The demo python introduces several python courses. </b> </p> <p class="course"> Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2"> Advanced Python </a> . </p> </body> </html> */
6、信息标记的三种形式
1)XML


2)JSON


3)YAML




7、信息提取的一般方法



实例:找出所有a标签中的href链接
import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 for link in soup.findAll('a'): print(link.get('href')) /* http://www.icourse163.org/course/BIT-268001 http://www.icourse163.org/course/BIT-1001870001 */
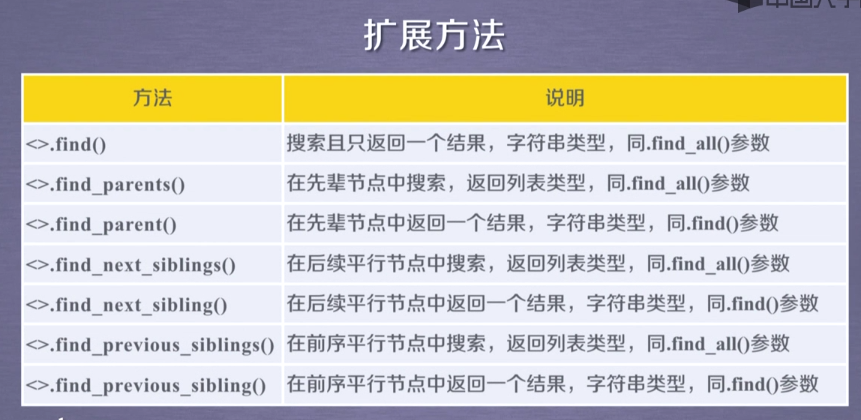
8、基于bs4库的HTML内容查找方法
soup.find_all(name, attr, recursive, string, **kwargs)返回一个列表类型,存储查找的结果。

import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.findAll('a')) #查所有的a标签 #[ < aclass ="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1" > Basic Python < / a >, < a class ="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2" > Advanced Python < / a >] print(soup.findAll(['a','b'])) #查所有的a和b标签 #[<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] #http://www.icourse163.org/course/BIT-268001 for tag in soup.findAll(True): #查所有的标签 print(tag.name) #html head title body p b p a a
#查属性 import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.findAll('p','course')) print(soup.findAll('a',id='link1'))
import requests import re from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('error') if __name__ == '__main__': url = 'http://python123.io/ws/demo.html' soup = BeautifulSoup(getHTMLText(url), 'html.parser') #html.parser为解释器 print(soup.findAll(string = 'Basic Python')) #['Basic Python'] print(soup(string='Basic Python')) # 简写['Basic Python'] print(soup.findAll(string = re.compile('Python'))) print(soup(string=re.compile('Python'))) #简写 #['Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n', 'Basic Python', 'Advanced Python']

作业:定向爬取中国大学排名 http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
import requests from bs4 import BeautifulSoup import bs4 #从网络上获取大学排名页面内容 def getHTMLText(url): try: respone = requests.get(url, timeout = 30) respone.raise_for_status() respone.encoding = respone.apparent_encoding return respone.text except: return '' #提取网页内容中信息到合适的数据结构 def fillUnivList(ulist, html): soup = BeautifulSoup(html, 'html.parser') for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[3].string]) #按要求输出格式化内容 def printUnivList(ulist, num): tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" #{3}指定format函数的第4个参数(参数从0开始)来chr(12288)填充 print(tplt.format("排名", "学校名称", "总分", chr(12288))) #chr(12288)以中文空格来填充,解决中文对齐的问题 for i in range(num): u = ulist[i] print(tplt.format(u[0], u[1], u[2], chr(12288))) if __name__ == '__main__': uinfo = [] url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) #20 univ /* 排名 学校名称 总分 1 清华大学 95.9 2 北京大学 82.6 3 浙江大学 80 4 上海交通大学 78.7 5 复旦大学 70.9 6 南京大学 66.1 7 中国科学技术大学 65.5 8 哈尔滨工业大学 63.5 9 华中科技大学 62.9 10 中山大学 62.1 11 东南大学 61.4 12 天津大学 60.8 13 同济大学 59.8 14 北京航空航天大学 59.6 15 四川大学 59.4 16 武汉大学 59.1 17 西安交通大学 58.9 18 南开大学 58.3 19 大连理工大学 56.9 20 山东大学 56.3 */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号