ceph day 2 作业
1、安装ceph-mds
2、创建cephFS 和data存储池
magedu@ceph-file^passw0rd
ceph day2作业:
1.用户权限管理和授权流程
2.用普通用户挂载rbd和cephfs
3.mds高可用
多mds active
多mds active加standby
一、Ceph-Fs文件存储服务
1.1部署mds服务(node2当作mds服务器)
root@ceph-node2:/home/long# apt-cache madison ceph-mds
root@ceph-node2:/home/long# apt install ceph-mds=16.2.5-1bionic
1.2安装mds服务
ceph@ceph-node1:~/ceph-cluste$ ceph-deploy mds create ceph-node2
1.3验证mds服务
ceph@ceph-node1:~/ceph-cluste$ ceph mds stat
1 up:standby ##当前为备用状态,需要分配pool才可以使用
1.4创建CephFs metadata 和data存储池
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create ceph-metadata 32 32##存储元数据
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create cephfs-data 64 64##为数据存储池
1.5创建cephFs并且验证
ceph@ceph-node1:~/ceph-cluste$ ceph fs new mycephfs ceph-metadata cephfs-data
new fs with metadata pool 8 and data pool 9
查看指定cepgFs状态
ceph@ceph-node1:~/ceph-cluste$ ceph fs status mycephfs
mycephfs - 0 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-node2 Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
ceph-metadata metadata 96.0k 13.8G
cephfs-data data 0 13.8G
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
1.6验证cephFs服务状态
ceph状态已经变更为active
1.7 客户端挂载cephalexinFS
ceph@ceph-node1:~/ceph-cluste$ cat ceph.client.admin.keyring
[client.admin]
key = AQBwGB9h5+gtLxAAAg4qKMnI6veZVLxI47NWRg==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[root@node01 ~]# mount -t ceph 192.168.1.20:6789:/ /mnt -o name=admin,secret=AQBwGB9h5+gtLxAAAg4qKMnI6veZVLxI47NWRg==
##验证挂载点
##验证数据
[root@node01 ~]# cp /etc/passwd /mnt
[root@node01 ~]# ls -l /mnt/passwd
-rw-r--r-- 1 root root 2463 Aug 23 00:44 /mnt/passwd
[root@node01 ~]# dd if=/dev/zero of=/mnt/ceph-fs-testfiles bs=4M count=25
验证数据
删除数据
命令总结
列出存储池显示id
ceph@ceph-node1:~/ceph-cluste$ ceph pg stat ##查看pg状态
297 pgs: 297 active+clean; 302 MiB data, 1.3 GiB used, 44 GiB / 45 GiB avail
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool stats mypool ##查看指定pool和全部pool状态
pool mypool id 2
nothing is going on
查看集群存储状态
查看集群存储状态详细详情
ceph@ceph-node1:~/ceph-cluste$ ceph osd stat ##查看osd状态
9 osds: 9 up (since 97m), 9 in (since 3d); epoch: e222
查看osd底层详细信息
显示osd和节点的对应情况
ceph@ceph-node1:~/ceph-cluste$ ceph mon stat ##显示mon的节点状态
e3: 3 mons at {ceph-node1=[v2:192.168.1.10:3300/0,v1:192.168.1.10:6789/0],ceph-node2=[v2:192.168.1.20:3300/0,v1:192.168.1.20:6789/0],ceph-node3=[v2:192.168.1.30:3300/0,v1:192.168.1.30:6789/0]}, election epoch 20, leader 0 ceph-node2, quorum 0,1,2 ceph-node2,ceph-node1,ceph-node3
显示mon的底层信息
二、集群维护
2.1 node节点 和mon节点,单节点维护,可以将admin认证文件同步到mon或者node节点
ceph@ceph-node1:~/ceph-cluste$ ceph --admin-socket /var/run/ceph/ceph-osd.0.asok --help
--admin daemon #在mon节点获取daemon服务帮助
ceph@ceph-node1:~/ceph-cluste$ ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok help
mon状态
查看配置信息
ceph@ceph-node1:~/ceph-cluste$ ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show
2.2 ceph集群的停止或重启
重启之前,要提前设置ceph集群不要将osd标记为out,避免node节点关闭服务后被踢出ceph集群
ceph@ceph-node1:~/ceph-cluste$ ceph osd set noout
noout is set
ceph@ceph-node1:~/ceph-cluste$ ceph osd unset noout ##启动服务后取消noout
2.2.1 关闭顺序
关闭服务前设置noout
关闭存储客户端停止读写数据
如果使用了RGW,关闭RGW
关闭cephFS元数据服务
关闭ceph OSD
关闭ceph manager
关闭ceph monitor
启动顺序
跟上边刚好相反
2.3 存储池、PG与 CRUSH
副本池:replicated定义每个对象在集群中保存多少个副本,默认为三个副本,一主两备,实现高可用,副本池也是ceph默认的存储池类型
但不是所有的应用都支持纠删码池,RBD只支持副本池而radosgw则可以支持纠删码池
2.3.1 副本池IO
2.3.2 纠删码池IO
##创建纠删码池
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create erasure-testpool 16 16 erasure
ceph@ceph-node1:~/ceph-cluste$ ceph osd erasure-code-profile get default
k=2 ##k为数据块的数量,及要将原始对象分割成的块数量,
m=2 ##编码块(chunk)的数量,即编码函数计算的额外快的数量
plugin=jerasure ##默认的纠删码池插件
technique=reed_sol_van
##写入数据
ceph@ceph-node1:~/ceph-cluste$ sudo rados put -p erasure-testpool testfile1 /var/log/syslog
##验证数据
ceph@ceph-node1:~/ceph-cluste$ ceph osd map erasure-testpool testfile1
osdmap e248 pool 'erasure-testpool' (10) object 'testfile1' -> pg 10.3a643fcb (10.b) -> up ([5,0,7,NONE], p5) acting ([5,0,7,NONE], p5)
##验证当前pg状态
ceph@ceph-node1:~/ceph-cluste$ ceph pg ls-by-pool erasure-testpool | awk '{print$1,$2,$15}'
PG OBJECTS ACTING
10.0 0 [5,8,2,NONE]p5
10.1 0 [8,4,2,NONE]p8
10.2 0 [1,4,NONE,6]p1
10.3 0 [7,3,1,NONE]p7
10.4 0 [8,1,5,NONE]p8
10.5 0 [2,NONE,7,5]p2
10.6 0 [5,NONE,1,8]p5
10.7 0 [3,0,NONE,6]p3
10.8 0 [0,7,3,NONE]p0
10.9 0 [3,0,NONE,7]p3
10.a 0 [4,7,NONE,2]p4
10.b 1 [5,0,7,NONE]p5
10.c 0 [4,NONE,6,0]p4
10.d 0 [4,7,NONE,2]p4
10.e 0 [4,6,NONE,0]p4
10.f 0 [6,NONE,5,2]p6
* NOTE: afterwards
##测试获取数据
ceph@ceph-node1:~/ceph-cluste$ rados -p erasure-testpool get testfile1 -
ceph@ceph-node1:~/ceph-cluste$ sudo rados -p erasure-testpool get testfile1 /tmp/testfile1
2.3.3 PG与PGP
PG #归置组
PGP #归置组的组合,pgp相当于是pg对应osd的一种配列组合关系
相对与存储来说,PG是一个虚拟组件,它是对象映射到存储池使用的虚拟层
2.3.4 PG 和OSD 的关系
ceph基于crush算法将归置组PG分配至OSD
当一个客户端存储对象时候,crush算法映射每一个对象至归置组(PG)
2.3.5 PG分配计算
Total OSDs * PGPerOSD/replication facter ==>total PGs
磁盘总数 * 每个磁盘的PG数 /副本数 ==>ceph集群总PG数(略大于2的n次方)
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create testpool2 60 60
pool 'testpool2' created
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create testpool3 40 30
pool 'testpool3' created
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create testpool4 45 45
pool 'testpool4' created
不是2的n次方,有警告
2.3.6 验证PG与PGP 组合
ceph@ceph-node1:~/ceph-cluste$ ceph pg ls-by-pool mypool | awk '{print$1,$2,$15}'
PG OBJECTS ACTING
2.0 0 [3,6,0]p3
2.1 0 [2,6,3]p2
2.2 0 [5,1,8]p5
2.3 0 [5,2,8]p5
2.4 0 [1,7,3]p1
2.5 0 [8,0,4]p8
2.6 0 [1,6,3]p1
2.7 0 [3,7,2]p3
2.8 0 [3,7,0]p3
2.9 0 [1,4,8]p1
2.a 0 [6,1,3]p6
2.b 0 [8,5,2]p8
2.c 0 [6,0,5]p6
2.d 0 [6,3,2]p6
2.e 0 [2,8,3]p2
2.f 0 [8,4,0]p8
2.10 1 [8,1,5]p8
2.11 0 [4,1,8]p4
2.12 0 [7,1,3]p7
2.13 0 [7,4,2]p7
2.14 0 [3,7,0]p3
2.15 0 [7,1,3]p7
2.16 0 [5,7,1]p5
2.17 0 [5,6,2]p5
2.18 0 [8,4,2]p8
2.19 0 [0,4,7]p0
2.1a 0 [3,8,2]p3
2.1b 0 [6,5,2]p6
2.1c 0 [8,4,1]p8
2.1d 0 [7,3,0]p7
2.1e 0 [2,7,5]p2
2.1f 0 [0,3,8]p0
* NOTE: afterwards
2.3.7 PG 的状态
ceph@ceph-node1:~/ceph-cluste$ ceph pg stat
458 pgs: 1 active+undersized+degraded, 15 active+undersized, 442 active+clean; 305 MiB data, 1.1 GiB used, 44 GiB / 45 GiB avail; 1/919 objects degraded (0.109%)
##在mon节点添加删除pool参数mon_allow_pool_delete = true
ceph@ceph-node1:~/ceph-cluste$ cat /etc/ceph/ceph.conf
[global]
fsid = 9794f4ef-1914-431b-b775-e85038312e18
mon_allow_pool_delete = true
public_network = 192.168.1.0/24
cluster_network = 192.168.2.0/24
mon_initial_members = ceph-node2
mon_host = 192.168.1.20
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
##重启mon服务
systemctl restart ceph-mon.target
##删除pool
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rm testpool4 testpool4 --yes-i-really-really-mean-it
pool 'testpool4' removed
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rm testpool3 testpool3 --yes-i-really-really-mean-it
pool 'testpool3' removed
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rm testpool2 testpool2 --yes-i-really-really-mean-it
pool 'testpool2' removed
##查看pool详细信息
ceph health detail
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool application enable erasure-testpool erasure-testpool --yes-i-really-mean-it
enabled application 'erasure-testpool' on pool 'erasure-testpool'
##查看PG状态
ceph@ceph-node1:~/ceph-cluste$ ceph pg stat
265 pgs: 265 active+clean; 300 MiB data, 1.0 GiB used, 44 GiB / 45 GiB avail
##此状态active+clean为正常状态
2.3.8 数据读写流程
具体写操作如下:
1、app向客户端发送某个对象的请求,此请求包含对象和存储池,然后ceph客户端对访问的对象做hash计算,并根据hash计算出对象所在的PG,完成对象从pool至PG的映射。
APP访问pool ID 和object ID
ceph client 对object 做哈希
ceph client 对该哈希值取PG总数的模。得到PG编号(比如32),第2和第3部基本保证了一个pool内部的所有PG将会被均匀的使用
ceph client 对pool取哈希
ceph client 将pool ID 和PG ID 组合在一起得到完整的ID
ceph client从MON 获取最新的cluster MAP
ceph client根据上面第2部计算出该object将要的PG ID
ceph client在根据CRUSH算法计算出PG中木匾主和备OSD ID ,即可对OSD 进行读写
2.4 ceph 存储池操作
2.4.1 列出存储池
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool ls detail
ceph@ceph-node1:~/ceph-cluste$ ceph osd lspools
##获取存储池事件信息
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool stats mypool
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rename myrdb1 myrdb2
##显示存储池的用量信息
rados df
##存储池的删除
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create mypool 32 32
pool 'mypool' created
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool nodelete
nodelete: false
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set mypool nodelete true
set pool 14 nodelete to true #如果true就表示不能删除
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set mypool nodelete false
set pool 14 nodelete to false
ceph@ceph-node1:~/ceph-cluste$ ceph tell mon.3 injectargs:mon-alllow-pool-delete=true
ceph@ceph-node2:~/ceph-cluste$ ceph tell mon.3 injectargs:mon-alllow-pool-delete=true
ceph@ceph-node3:~/ceph-cluste$ ceph tell mon.3 injectargs:mon-alllow-pool-delete=true
#删除pool
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rm mypool mypool --yes-i-really-really-mean-it
pool 'mypool' removed
2.4.2 存储池配额
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: N/A #默认不限制数量大小
max bytes : N/A #默认不限制空间大小
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set-quota mypool max_objects 10
set-quota max_objects = 10 for pool mypool ##限制对象数量10个
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set-quota mypool max_bytes 1024
set-quota max_bytes = 1024 for pool mypool 限制字节1024
2.4.3 存储池可用参数
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool size
size: 3
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool min_size
min_size: 2
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool pg_num
pg_num: 32
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool crush_rule
crush_rule: replicated_rule
ceph osd pool get -h
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool nodelete
nodelete: false #控制是否可删除
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool nopgchange
nopgchange: false #控制是否可更改存储池的pg num 和pgp num
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set mypool pg_num 64
set pool 15 pg_num to 64
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: 10 objects (current num objects: 0 objects)
max bytes : 1 KiB (current num bytes: 0 bytes)
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set-quota mypool max_bytes 21474836480
set-quota max_bytes = 21474836480 for pool mypool
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: 10 objects (current num objects: 0 objects)
max bytes : 20 GiB (current num bytes: 0 bytes)
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set-quota mypool max_objects 1000
set-quota max_objects = 1000 for pool mypool
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: 1k objects (current num objects: 0 objects)
max bytes : 20 GiB (current num bytes: 0 bytes)
#noscrub和nodeep-scrub:控制是否进行轻量级或是否深度扫描,可临时解决IO问题
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool noscrub
noscrub: false
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool get mypool nodeep-scrub
nodeep-scrub: false
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool set mypool nodeep-scrub true
set pool 15 nodeep-scrub to true #设置禁止pool深度扫描
关闭深度扫描和轻量级扫描有告警
ceph@ceph-node2:/etc/ceph$ ceph daemon osd.3 config show |grep scrub
"mds_max_scrub_ops_in_progress": "5",
"mon_scrub_inject_crc_mismatch": "0.000000",
"mon_scrub_inject_missing_keys": "0.000000",
"mon_scrub_interval": "86400",
"mon_scrub_max_keys": "100",
"mon_scrub_timeout": "300",
"mon_warn_pg_not_deep_scrubbed_ratio": "0.750000",
"mon_warn_pg_not_scrubbed_ratio": "0.500000",
"osd_debug_deep_scrub_sleep": "0.000000",
"osd_deep_scrub_interval": "604800.000000", #定义深度清洗时间间隔7天
"osd_deep_scrub_keys": "1024",
"osd_deep_scrub_large_omap_object_key_threshold": "200000",
"osd_deep_scrub_large_omap_object_value_sum_threshold": "1073741824",
"osd_deep_scrub_randomize_ratio": "0.150000",
"osd_deep_scrub_stride": "524288",
"osd_deep_scrub_update_digest_min_age": "7200",
"osd_max_scrubs": "1", #定义一个ceph OSD daemon 内能够同时进行scrubbing的操作数
"osd_requested_scrub_priority": "120",
"osd_scrub_auto_repair": "false",
"osd_scrub_auto_repair_num_errors": "5",
"osd_scrub_backoff_ratio": "0.660000",
"osd_scrub_begin_hour": "0",
"osd_scrub_begin_week_day": "0",
"osd_scrub_chunk_max": "25",
"osd_scrub_chunk_min": "5",
"osd_scrub_cost": "52428800",
"osd_scrub_during_recovery": "false",
"osd_scrub_end_hour": "0",
"osd_scrub_end_week_day": "0",
"osd_scrub_extended_sleep": "0.000000",
"osd_scrub_interval_randomize_ratio": "0.500000",
"osd_scrub_invalid_stats": "true", #定义扫描是否有效
"osd_scrub_load_threshold": "0.500000",
"osd_scrub_max_interval": "604800.000000", #定义最大执行扫描间隔7天
"osd_scrub_max_preemptions": "5",
"osd_scrub_min_interval": "86400.000000", #定义最小执行扫描间隔1天
"osd_scrub_priority": "5",
"osd_scrub_sleep": "0.000000",
2.4.1 存储池快照
#创建快照
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool mksnap mypool mypool-snap
created pool mypool snap mypool-snap #命令1
ceph@ceph-node1:~/ceph-cluste$ rados -p mypool mksnap mypool-snap2
created pool mypool snap mypool-snap2 命令2
#验证快照
ceph@ceph-node1:~/ceph-cluste$ rados lssnap -p mypool
1 mypool-snap 2021.08.25 10:10:23
2 mypool-snap2 2021.08.25 10:11:25
2 snaps
#删除快照
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool rmsnap mypool mypool-snap
removed pool mypool snap mypool-snap
2.4.2 数据压缩
略
三、ceph的权限管理和授权流程
3.1 cephx认证流程
ceph使用cephx协议对客户端进行身份认证
cephx用于对ceph保存得数据进行认证访问和授权,用于对访问得请求进行认证和授权检测,与mon通信得请求都要经过ceph认证通过。
3.1.1 授权流程
每个mon节点都可以对客户端进行身份认证并分发密钥,因此多个mon节点就不存在单点故障和认证性能瓶颈
mon节点会返回用于身份认证得数据结构,其中包含ceph服务时用到得session key
session key 通过客户端密钥进行加密,密钥是在客户端提前配置好的/etc/ceph/ceph.client/admin.keyering
客户端使用session key向mon请求所需要的服务,mon向客户端提供一个ticket,用于向实际处理数据得OSD等服务验证客户端身份,MON和OSD共享同一个secret,因此OSD会信任任何所有MON发放的ticket。
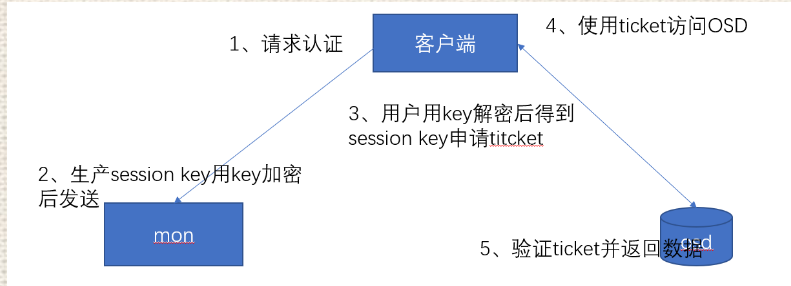
3.1.2 访问流程
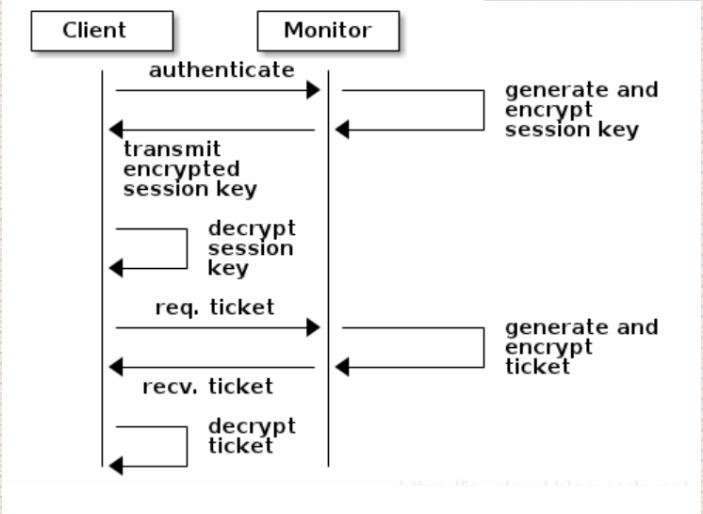
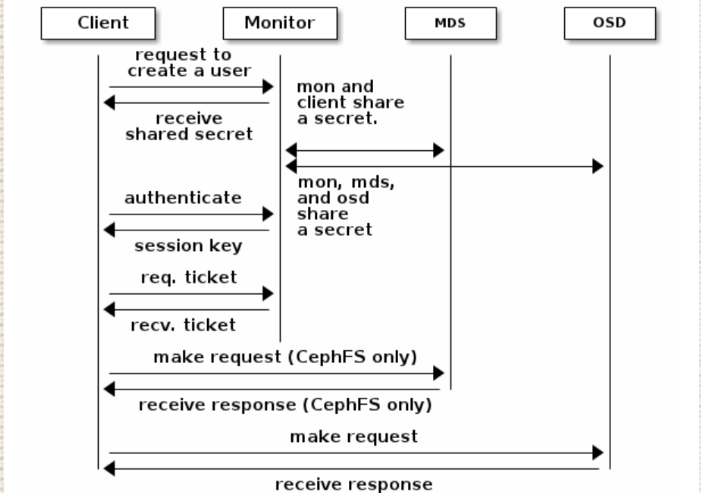
3.2 权限管理
一般系统的身份认真无非三点:账号、角色和认真鉴权,Ceph 的用户可以是一个具体的人或系统角色(e.g. 应用程序),Ceph 管理员通过创建用户并设置权限来控制谁可以访问、操作 Ceph Cluster、Pool 或 Objects 等资源。
ceph@ceph-node1:~/ceph-cluste$ ceph auth ls
mds.ceph-node2 #MDS守护进程用户
key: AQDESSNhzZ88ABAAxYvMCIspXRStGBzNLFI9Gw== #密钥
caps: [mds] allow #守护进程授权用户
caps: [mon] allow profile mds
caps: [osd] allow rwx
osd.0 #OSD守护进程用户
key: AQBROR9hJ7ByHxAAnnyKNCf11IuYWqQSIr1XeQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBbOR9hi49EHBAAdWpL+A0ifbAjamDsSlzbDQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQBoOR9h5HSJHBAAOs6CZPTz+2oWRCLXpGuyCg==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQB4OR9h3RO9JxAA6uLi2gjhiLUhkaVdFrOtZA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQCDOR9hscrgMRAAKx/qw2VV+A5XtoJhrlba7Q==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQCROR9hNNPcIRAAUrcXfFgKk2DP4qJRN4y7BA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQCgOR9hJmnHAxAAwe/hbvTwQwrALGN9GVL4SA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.7
key: AQCrOR9hLWMADBAAYJOlOVBxfkxFT4ogXbOC/g==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQC2OR9hjrSJJxAAiuDRJTVCMULUxpt7zkFelQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin #admin管理员用户
key: AQBwGB9h5+gtLxAAAg4qKMnI6veZVLxI47NWRg==
caps: [mds] allow *
caps: [mgr] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBwGB9hG/0tLxAAy3warOj1OXf2svytAg2r2g==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-mgr
key: AQBwGB9hagouLxAAph0VvcuXbllnZdEWvjmeJg==
caps: [mon] allow profile bootstrap-mgr
client.bootstrap-osd
key: AQBwGB9hlRUuLxAA92jhEjQ89tTitt/Mc8zzvw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rbd
key: AQBwGB9huSAuLxAAqSWvpONTcOzcKxfxsygCKg==
caps: [mon] allow profile bootstrap-rbd
client.bootstrap-rbd-mirror
key: AQBwGB9hgiwuLxAAik4UCOXdlOyVkjda1RZH0g==
caps: [mon] allow profile bootstrap-rbd-mirror
client.bootstrap-rgw
key: AQBwGB9h7DcuLxAA7VjNeOt+Mwh3Dk09fDsMlw==
caps: [mon] allow profile bootstrap-rgw
client.rgw.ceph-node3
key: AQCcSh9hNr++IRAAWYKEFOsp0/fsoUR+okS1ug==
caps: [mon] allow rw
caps: [osd] allow rwx
mgr.ceph-node2
key: AQAdPx9hcuIcDhAAPQZ9oPflcq71ICRPEaxNDw==
caps: [mds] allow *
caps: [mon] allow profile mgr
caps: [osd] allow *
mgr.ceph-node3
key: AQCDHR9hFysIHBAA54gtaYZI9TA0VHo5/UBAoA==
caps: [mds] allow *
caps: [mon] allow profile mgr
caps: [osd] allow *
installed auth entries:
Ceph 的用户类型可以分为以下几类:
- 客户端用户
- 操作用户(e.g. client.admin)
- 应用程序用户(e.g. client.cinder)
- 其他用户
- Ceph 守护进程用户(e.g. mds.ceph-node1、osd.0)
用户命名遵循 <TYPE.ID> 的命名规则,其中 Type 有 mon,osd,client 三者,L 版本以后添加了 mgr 类型。
NOTE:为 Ceph 守护进程创建用户,是因为 MON、OSD、MDS 等守护进程同样遵守 CephX 协议,但它们不能属于真正意义上的客户端。
Ceph 用户的密钥:相当于用户的密码,本质是一个唯一字符串。e.g. key: AQB3175c7fuQEBAAMIyROU5o2qrwEghuPwo68g==
Ceph 用户的授权(Capabilities, caps):即用户的权限,通常在创建用户的同时进行授权。只有在授权之后,用户才可以使用权限范围内的 MON、OSD、MDS 的功能,也可以通过授权限制用户对 Ceph 集群数据或命名空间的访问范围。以 client.admin 和 client.cinder 为例:
client.admin key: AQB3175cZrKQEBAApE+rBBXNvbZs16GkpOjXhw== # 允许访问 MDS caps: [mds] allow * # 允许访问 Mgr caps: [mgr] allow * # 允许访问 MON caps: [mon] allow * # 允许访问 OSD caps: [osd] allow * client.cinder key: AQDVgMFcn/7sEhAA1sLOM+CTWkkGGJ47GRqInw== # 在 MON 中具有引导 RBD 的权限 caps: [mon] profile rbd # 在 OSD 中具有通过 RBD 访问 Pool volumes、vms、images 中的数据权限 caps: [osd] profile rbd pool=volumes, profile rbd pool=vms, profile rbd pool=images
3.2.1 列出指定用户信息
ceph@ceph-node1:~/ceph-cluste$ ceph auth get osd.3
[osd.3]
key = AQB4OR9h3RO9JxAA6uLi2gjhiLUhkaVdFrOtZA==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
exported keyring for osd.3
3.2.2 ceph授权和使能
授权类型:
- allow:在守护进程进行访问设置之前就已经具有特定权限,常见于管理员和守护进程用户。
- r:授予用户读的权限,读取集群各个组件(MON/OSD/MDS/CRUSH/PG)的状态,但是不能修改。
- w:授予用户写对象的权限,与 r 配合使用,修改集群的各个组件的状态,可以执行组件的各个动作指令。
- x:授予用户调用类方法的能力,仅仅和 ceph auth 操作相关。
- class-read:授予用户调用类读取方法的能力,是 x 的子集。
- class-write:授予用户调用类写入方法的能力,是 x 的子集。
- *:授予用户 rwx 权限。
- profile osd:授权用户以 OSD 身份连接到其它 OSD 或 MON,使得 OSD 能够处理副本心跳和状态汇报。
- profile mds:授权用户以 MDS 身份连接其它 MDS 或 MON。
- profile bootstrap-osd:授权用户引导 OSD 守护进程的能力,通常授予部署工具(e.g. ceph-deploy),让它们在引导 OSD 时就有增加密钥的权限了。
- profile bootstrap-mds:授权用户引导 MDS 守护进程的能力。同上。
NOTE:可见 Ceph 客户端不直接访问 Objects,而是必须要经过 OSD 守护进程的交互。
MON能力
包括r/w/x和allow profile cap(ceph得运行图)
mon 'allow rwx'
mon 'allow profile osd'
OSD能力
包括rwx、class-read、class-write、和profile osd,另外osd还允许进行存储池和名称空间设置
MDS能力 只需要allow或空都表示支持
3.2.2 用户管理
ceph@ceph-node1:~/ceph-cluste$ ceph auth add client.joy mon 'allow r' osd 'allow rwx pool=mypool' #添加认证key
added key for client.joy
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.joy #验证key
[client.joy]
key = AQAP+SZhVSxGDhAApLe7LD+FrMWeBWF0QHfpXw==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.joy
ceph@ceph-node1:~/ceph-cluste$ ceph auth get-or-create client.joy osd 'allow rwx pool=mypool'
[client.joy]
key = AQAP+SZhVSxGDhAApLe7LD+FrMWeBWF0QHfpXw==
ceph@ceph-node1:~/ceph-cluste$ ceph auth get-or-create client.joy osd 'allow rwx pool=mypool' # 再次创建用户
[client.joy]
key = AQAP+SZhVSxGDhAApLe7LD+FrMWeBWF0QHfpXw==
ceph@ceph-node1:~/ceph-cluste$ ceph auth get-or-create-key client.joy mon 'allow r' osd 'allow rwx pool=mypool' #此命令是创建用户并返回密钥,用户有key就显示没有被创建
AQAP+SZhVSxGDhAApLe7LD+FrMWeBWF0QHfpXw==
ceph@ceph-node1:~/ceph-cluste$ ceph auth print-key client.joy #打印密钥
AQAP+SZhVSxGDhAApLe7LD+FrMWeBWF0QHfpXw==ceph@ceph-node1:~/ceph-cluste$
#修改用户能力
ceph@ceph-node1:~/ceph-cluste$ ceph auth caps client.joy mon 'allow r' osd 'allow rw pool=mypool'
updated caps for client.joy
#删除用户
ceph@ceph-node1:~/ceph-cluste$ ceph auth del client.joy
updated
#导出用户认证信息至keyring文件
ceph@ceph-node1:~/ceph-cluste$ touch ceph.client.joy.keyring
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.joy -o ceph.client.joy.keyring
exported keyring for client.joy
ceph@ceph-node1:~/ceph-cluste$ cat ceph.client.joy.keyring
[client.joy]
key = AQB4/iZhJCotBRAAxgeLPIR6BvP6lUuyKnJDVQ==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
#密钥环文件多用户
ceph@ceph-node1:~/ceph-cluste$ ceph-authtool ./ceph.client.joy.keyring --import-keyring ./ceph.client.admin.keyring
importing contents of ./ceph.client.admin.keyring into ./ceph.client.joy.keyring
ceph@ceph-node1:~/ceph-cluste$ cat ceph.client.joy.keyring
[client.admin]
key = AQBwGB9h5+gtLxAAAg4qKMnI6veZVLxI47NWRg==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[client.joy]
key = AQB4/iZhJCotBRAAxgeLPIR6BvP6lUuyKnJDVQ==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
#用密钥环回复用户,对比密钥没有改变
ceph@ceph-node1:~/ceph-cluste$ cat ceph.client.joy.keyring
[client.joy]
key = AQB4/iZhJCotBRAAxgeLPIR6BvP6lUuyKnJDVQ==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph auth del client.joy
updated
ceph@ceph-node1:~/ceph-cluste$ ceph auth import -i ceph.client.joy.keyring
imported keyring
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.joy
[client.joy]
key = AQB4/iZhJCotBRAAxgeLPIR6BvP6lUuyKnJDVQ==
caps mon = "allow r"
caps osd = "allow rwx pool=mypool"
exported keyring for client.joy
四、用普通用户挂载RBD 和Ceph FS
4.1 创建存储池
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool create rdb-data1 32 32
pool 'rdb-data1' created
#在存储池启用rdb
ceph@ceph-node1:~/ceph-cluste$ ceph osd pool application enable rdb-data1 rbd --yes-i-really-mean-it
enabled application 'rbd' on pool 'rdb-data1'
#初始化rbd
ceph@ceph-node1:~/ceph-cluste$ rbd pool init -p rdb-data1
4.2创建img镜像
ceph@ceph-node1:~/ceph-cluste$ rbd create data-img1 --size 3G --pool rdb-data1 --image-format 2 --image-feature layering
ceph@ceph-node1:~/ceph-cluste$ rbd create data-img2 --size 5G --pool rdb-data1 --image-format 2 --image-feature layering
#验证镜像
ceph@ceph-node1:~/ceph-cluste$ rbd ls --pool rdb-data1
data-img1
data-img2
ceph@ceph-node1:~/ceph-cluste$ rbd ls --pool rdb-data1 -l
NAME SIZE PARENT FMT PROT LOCK
data-img1 3 GiB 2
data-img2 5 GiB 2
#查看镜像详细信息
ceph@ceph-node1:~/ceph-cluste$ rbd --image data-img2 --pool rdb-data1 info
rbd image 'data-img2':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 2d004c714c19f
block_name_prefix: rbd_data.2d004c714c19f
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Aug 26 11:14:53 2021
access_timestamp: Thu Aug 26 11:14:53 2021
modify_timestamp: Thu Aug 26 11:14:53 2021
4.3 用普通用户配置centos客户端使用RBD
#配置客户端yum源
[root@node01 ~]# yum install -y epel-release
[root@node01 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y
#安装ceph-common
[root@node01 ~]# yum install -y ceph-common
4.3.1 客户端用普通用户longlong挂载rdb
#创建普通用户
ceph@ceph-node1:~/ceph-cluste$ ceph auth add client.longlong mon 'allow r' osd 'allow rwx pool rdb-data1 '
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.longlong
[client.longlong]
key = AQDoNidhX5R7HxAAVGV69DTmIkAifGx7aL6BNQ==
caps mon = "allow r"
caps osd = "allow rwx pool rdb-data1 "
exported keyring for client.longlong
#导出用户keyring
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.longlong -o ceph.client.longlong.keyring
exported keyring for client.longlong
#同步用户认证文件
ceph@ceph-node1:~/ceph-cluste$ cp ceph.client.longlong.keyring ceph.conf root@192.168.1.132:/etc/ceph/
#客户端验证普通用户
[root@node01 ~]# ceph --user longlong -s
cluster:
id: 9794f4ef-1914-431b-b775-e85038312e18
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node2,ceph-node1,ceph-node3 (age 9m)
mgr: ceph-node2(active, since 9m), standbys: ceph-node3
mds: 1/1 daemons up
osd: 9 osds: 9 up (since 9m), 9 in (since 28h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 10 pools, 361 pgs
objects: 310 objects, 300 MiB
usage: 1.1 GiB used, 44 GiB / 45 GiB avail
pgs: 361 active+clean
客户端映射镜像
[root@node01 ~]# [root@node01 ~]# rbd -p --user longlong rdb-data1 map data-img2
/dev/rbd0
[root@node01 ~]#[root@node01 ~]# rbd -p --user longlong rdb-data1 map data-img1
/dev/rbd1
客户端验证镜像
[root@node01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 300M 0 part /boot
├─sda2 8:2 0 2G 0 part
└─sda3 8:3 0 47.7G 0 part /
sr0 11:0 1 1024M 0 rom
rbd0 252:0 0 5G 0 disk
rbd1 252:16 0 3G 0 disk
#格式化并使用rbd镜像
[root@node01 ~]# mkfs.ext4 /dev/rbd1
[root@node01 ~]# mkfs.ext4 /dev/rbd0
#挂载
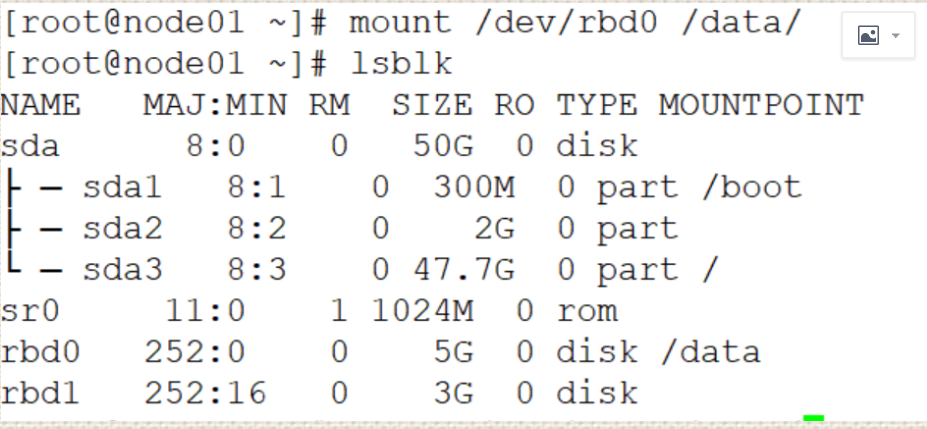
#更改/etc/rc.d/rc.local自启动挂载

[root@node01 ~]# chmod a+x /etc/rc.d/rc.local
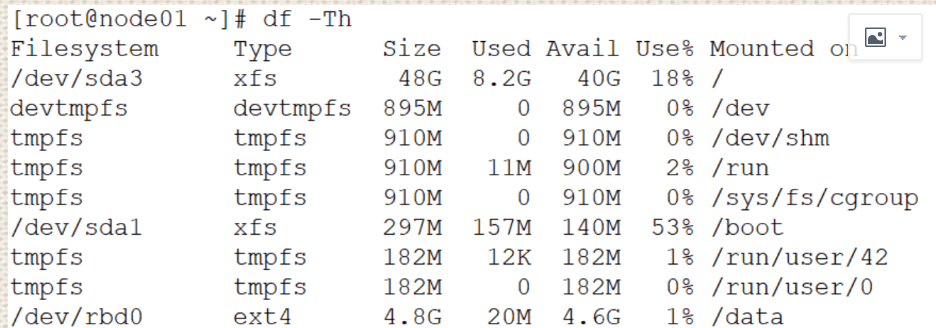
#用普通用户挂载ceph FS
ceph@ceph-node1:~/ceph-cluste$ ceph -s
cluster:
id: 9794f4ef-1914-431b-b775-e85038312e18
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node2,ceph-node1,ceph-node3 (age 44m)
mgr: ceph-node2(active, since 44m), standbys: ceph-node3
mds: 1/1 daemons up
osd: 9 osds: 9 up (since 44m), 9 in (since 28h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 10 pools, 361 pgs
objects: 379 objects, 509 MiB
usage: 2.2 GiB used, 43 GiB / 45 GiB avail
pgs: 361 active+clean
ceph@ceph-node1:~/ceph-cluste$ ceph osd lspools
1 device_health_metrics
3 myrbd1
4 .rgw.root
5 default.rgw.log
6 default.rgw.control
7 default.rgw.meta
8 ceph-metadata
9 cephfs-data
15 mypool
16 rdb-data1
#创建普通用户yanyan,生产key scp 到客户端/etc/ceph/
ceph@ceph-node1:~/ceph-cluste$
ceph@ceph-node1:~/ceph-cluste$ ceph auth add client.yanyan mon 'allow r' mds 'allow rw' osd 'allow rwx pool=caphfs-date'
added key for client.yanyan
ceph@ceph-node1:~/ceph-cluste$ ceph auth get yanyan
Error EINVAL: invalid entity_auth yanyan
ceph@ceph-node1:~/ceph-cluste$ ceph auth get clientyanyan
Error EINVAL: invalid entity_auth clientyanyan
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.yanyan
[client.yanyan]
key = AQCwhSdhydDeKxAAmJ2Vl3QKCr8r5kCjHg55tg==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=caphfs-date"
exported keyring for client.yanyan
ceph@ceph-node1:~/ceph-cluste$ ceph auth get client.yanyan > cephfs.client.yanyan.keyring
exported keyring for client.yanyan
ceph@ceph-node1:~/ceph-cluste$ scp cephfs.client.yanyan.keyring root@192.168.1.132:/etc/ceph/
#用yanyan挂载cephfs
[root@node01 ~]# mount -t ceph 192.168.1.10:6789,192.168.1.20:6789,192.168.1.30:6789:/ /mnt/ -o name=yanyan,secret=AQCwhSdhydDeKxAAmJ2Vl3QKCr8r5kCjHg55tg== #燕燕得密钥
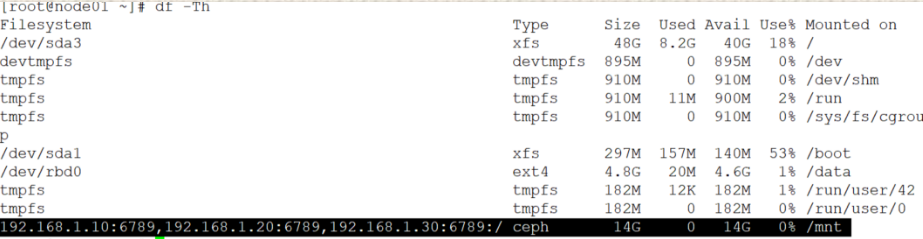
挂载成功
五、caph FS 得mds高可用
ceph@ceph-node1:~/ceph-cluste$ ceph mds stat
mycephfs:1 {0=ceph-node2=up:active}
ceph@ceph-node1:~/ceph-cluste$ ceph-deploy mds create ceph-node1 --overwrite-conf
ceph@ceph-node1:~/ceph-cluste$ ceph mds stat
mycephfs:1 {0=ceph-node2=up:active} 1 up:standby
ceph@ceph-node1:~/ceph-cluste$ ceph-deploy --overwrite-conf mds create ceph-node3
ceph@ceph-node1:~/ceph-cluste$ ceph mds stat
mycephfs:1 {0=ceph-node2=up:active} 2 up:standby
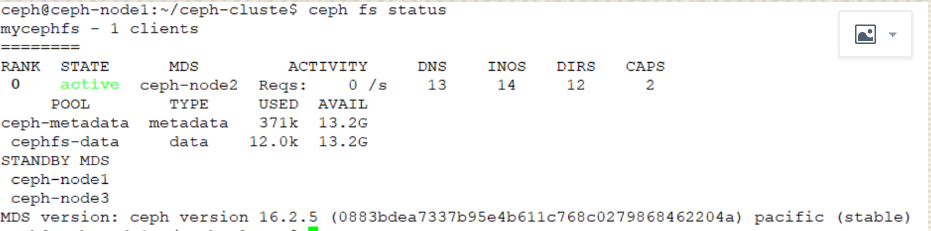
一主两备
ph@ceph-node1:~/ceph-cluste$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 55
flags 12
created 2021-08-23T15:24:30.610682+0800
modified 2021-08-26T19:12:56.051989+0800
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 397
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=204123}
failed
damaged
stopped
data_pools [9]
metadata_pool 8
inline_data disabled
balancer
standby_count_wanted 1
[mds.ceph-node2{0:204123} state up:active seq 9 addr [v2:192.168.1.20:6800/3929115012,v1:192.168.1.20:6801/3929115012]]
ceph@ceph-node1:~/ceph-cluste$ ceph fs set mycephfs max_mds 2
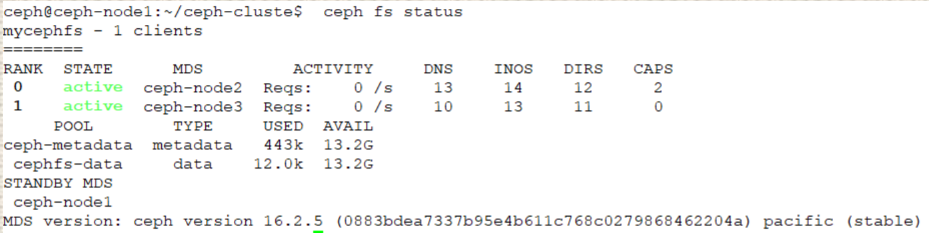
#重启node3节点ceph-mds@node03.service
root@ceph-node3:/home/long# systemctl restart ceph-mds@node03.service
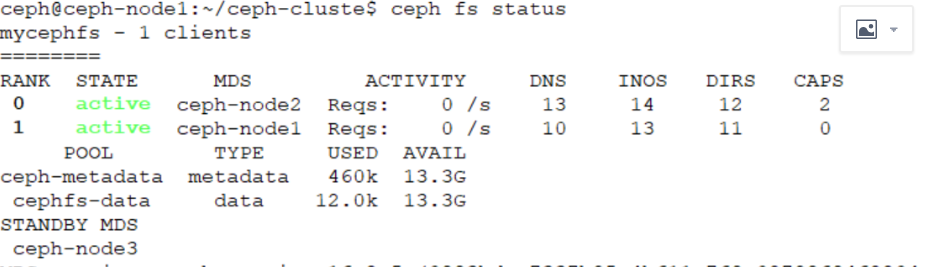
服务启动没有成功,重启服务器才可以
因只有三个节点,所以只能到这里了,至于四个节点做两主两备,只要更改ceph.conf配置文件,再将配置文件重新push到各个节点就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号