

第一次个人编程作业
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| ·Estimate | ·估计这个任务需要多少时间 | 1200 | 1600 |
| Development | 开发 | 120 | 240 |
| ·Analysis | ·需求分析 (包括学习新技术) | 240 | 300 |
| ·Design Spec | ·生成设计文档 | 120 | 60 |
| ·Design Review | ·设计复审 | 30 | 40 |
| ·Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| ·Coding | ·具体编码 | 240 | 600 |
| ·Code Review | ·代码复审 | 30 | 30 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 90 | 60 |
| ·Test Repor | ·测试报告 | 60 | 60 |
| ·Size Measurement | · 计算工作量 | 30 | 30 |
| ·Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1140 | 1600 |
解题思路
拿到这个题目,能够明显的看出是字符串的提取问题。由于对python还不是特别熟悉,我决定用C++写。我的思路是把姓名和手机先判断出来,判断出来后删除,再对地址进行分析。
首先通过判断第一个字符确定是五级地址分离还是七级地址分离。我发现姓名之后都有一个”,”,因此可以利用这个逗号把姓名先提取出来,然后消除。我通过百度了解到,手机号码可以利用正则表达式提取。省份的话,除了黑龙江省,其余带“省”字的省份都是两个字,因此把黑龙江特殊处理,我用暴力把省分离,市的话也是类似方法。对于第三级和第四级地址的分离,则是采用正则表达式,那么剩余的则是详细地址。至于七级地址里详细地址的分离,依旧采用正则表达式。最后,就是根据题目的要求输出。
设计实现
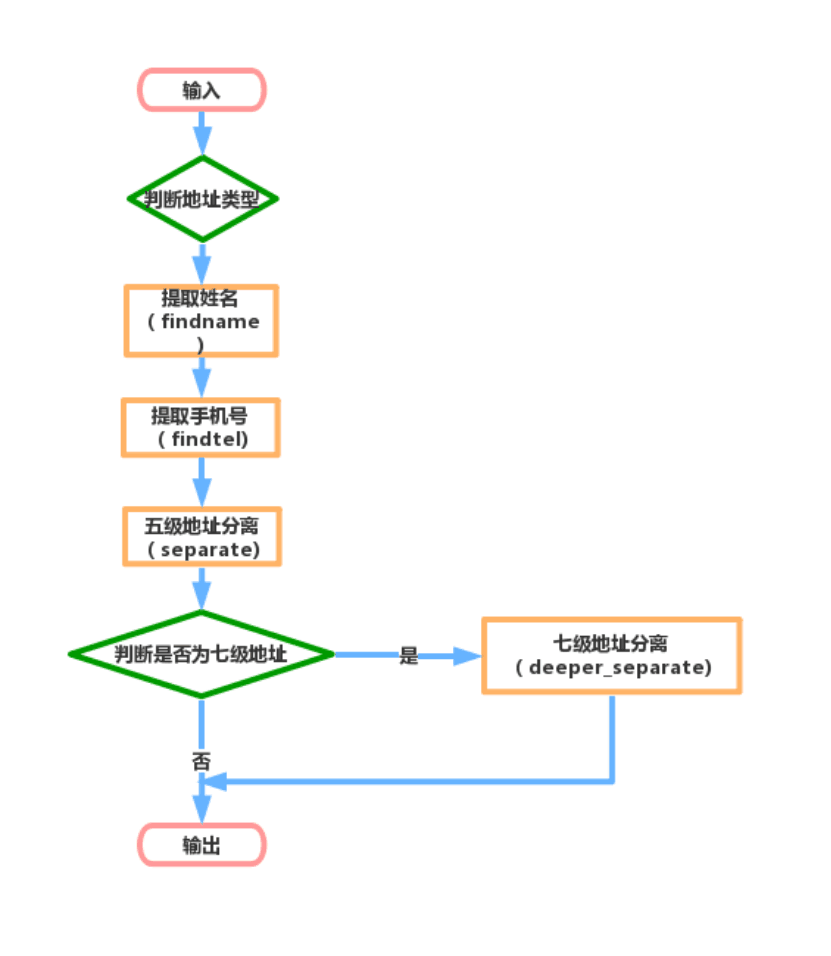
代码设计主要包括主程序和诸多功能函数,例如、类型判断函数(leixing)、寻找名字函数(findname)、手机号分离函数(findtel),地址分离函数(separate)等。内部的调用关系大致是,主程序执行,先调用类型判断函数,确定是哪级分离,之后删除X!(表级数)的两个字符;然后依次调用寻找名字、手机号分离的函数,最终的到姓名、手机、地址等三个独立的字符串,紧接着调用地址分离函数对地址进行一级一级的提取。
具体流程下图所示:
关键代码
本次代码中最难最关键的是通过正则表达式达到分离效果
| 划分内容 | 代码展示 |
|---|---|
| 11位手机号码 | regex r("\d{11}"); |
| 县/区/县级市级划分 | regex r("^.+(县/市/区)"); |
| 街道/镇/乡划分 | regex q("^.+(街道/镇/乡)"); |
| 街/路/巷 | regex q("^.+(街/路/巷)"); |
| 门牌号 | regex q("^.+(号)"); |
此外,C++文本的读取也写入也让我卡了好久……
| 内容 | 代码展示 |
|---|---|
| 读取 | ifstream input; input.open(argv[1]); |
| 写入 | ofstream out; out.open(argv[1]); |
| 头文件加 fstream |
关键函数代码展示
string findtel(string a)//寻找手机号
{
smatch tel;
regex r("\\d{11}");
regex_search(a, tel, r);
string newtel = tel.str();
return newtel;
}
int sign1,sign2;
sign1 = loc.find('省');//分离省
if (sign1 == 5)
{
pro = loc.substr(0, sign1+1);
loc.erase(0, 6);//擦除省
}
else if (sign1 == 7)
{
pro = loc.substr(0, sign1+1);
loc.erase(0, 8);//擦除省
}
else//地址没有省字
{
flag1 = 1;
sign2 = loc.find('龙');
if (sign2==3)
{
pro = loc.substr(0, 6);
loc.erase(0, pro.length());
}
else
{
pro = loc.substr(0, 4);
loc.erase(0, pro.length());
}
}
//县/区/县级市
regex r("^.+(县|市|区)");
smatch t;
regex_search(loc, t, r);
country = t.str();
loc = regex_replace(loc, r, "");
//街道/镇/乡
regex q("^.+(街道|镇|乡)");
smatch p;
regex_search(loc, p, q);
town = p.str();
loc = regex_replace(loc, q, "");
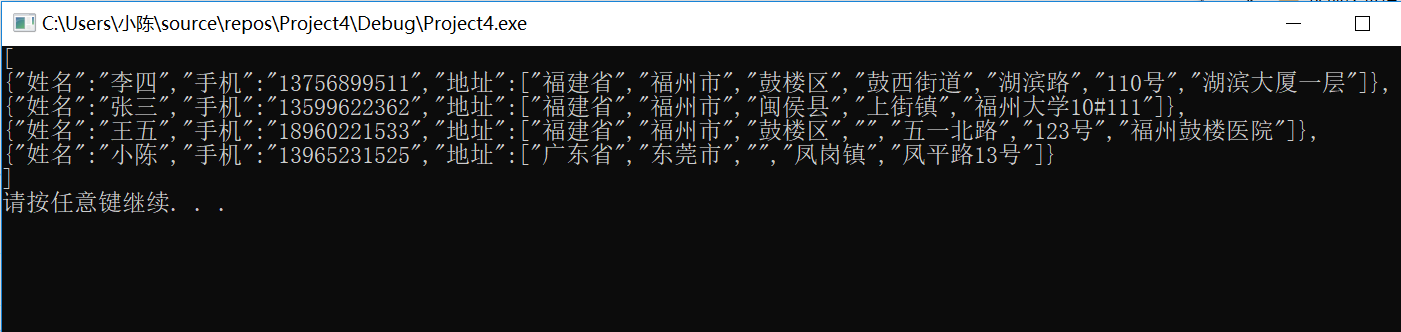
运行结果展示
输入数据:

输出数据:
性能分析展示
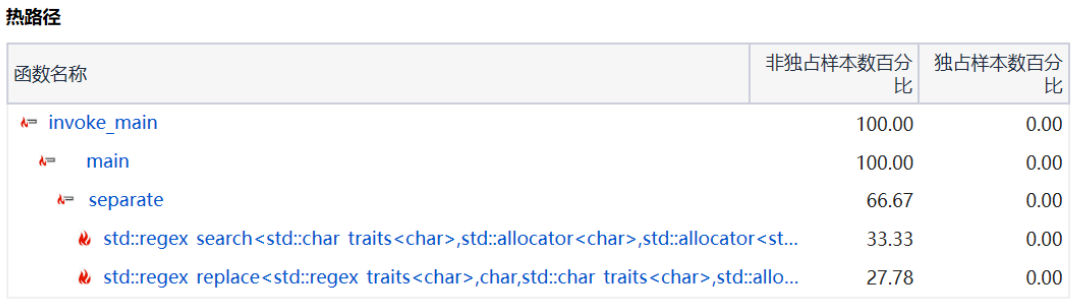
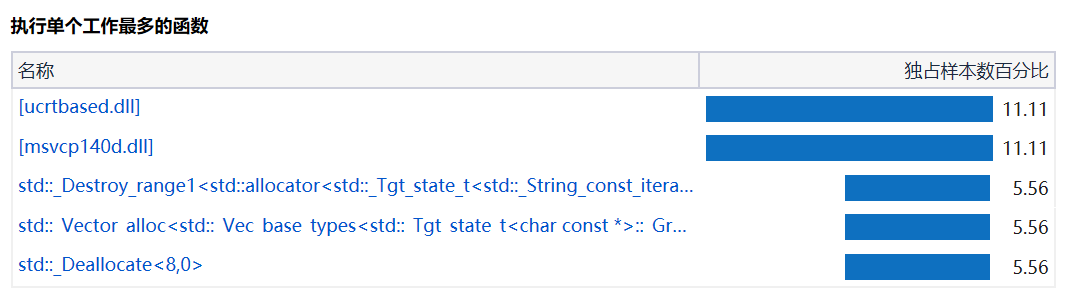
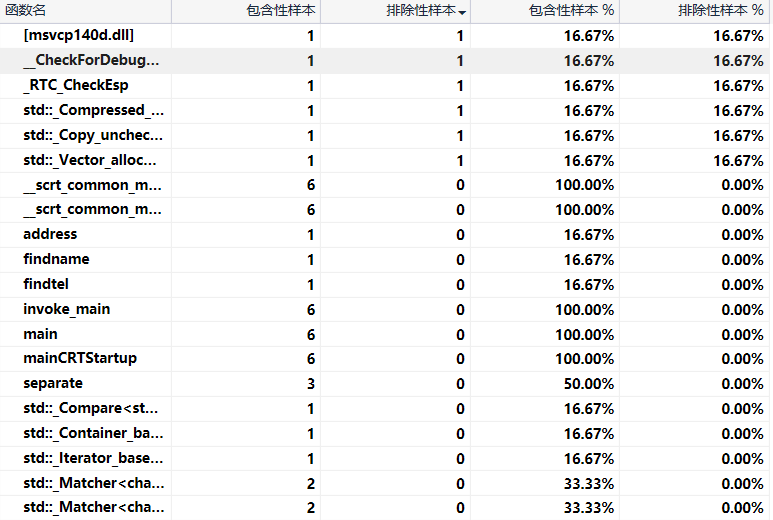
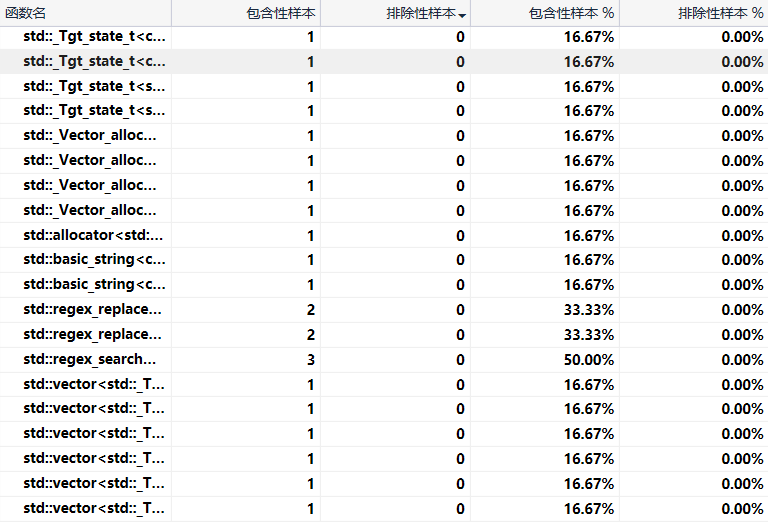 程序中消耗最大的函数可从百分比中得以体现。
程序中消耗最大的函数可从百分比中得以体现。
单元测试及覆盖率
我看了构建之法2.1里面相关的内容,但由于代码上的问题比较多(呜呜),且书里是用C#写的。这块没有理解清楚,所以没有做。这次作业之后会好好研究尝试的(保证)
看书觉得几个比较印象深刻的点在这先总结下:
- 创建单元测试的主要步骤:
- 设置数据
- 使用被测试类型的功能
- 比较实际结果和预期结%果
- 100%的代码覆盖率并不等于100%的正确性
异常分析
我的异常主要在于输出会出现乱码和文件读取。(心态爆炸
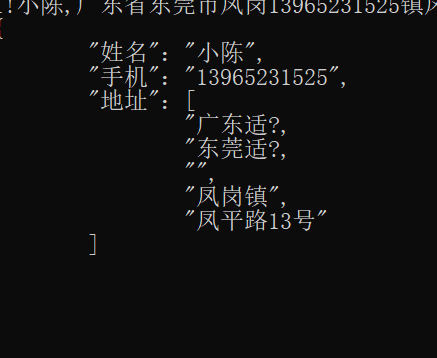
输出乱码展示:
- 省字的输出一直会出现乱码。后来换了一种输出方式。可能是没有转码所以导致省变成适,引号变成问号。
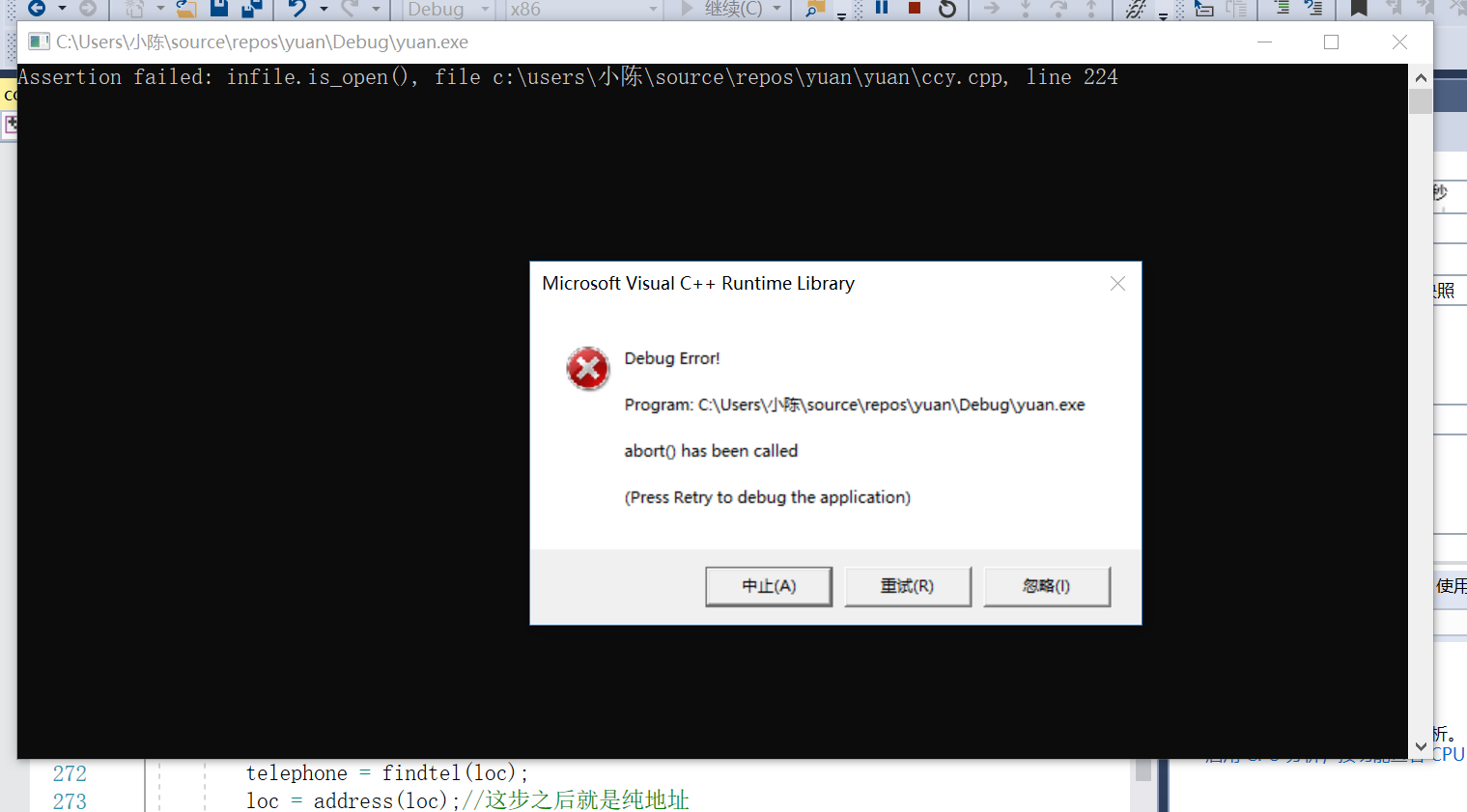
- 所有函数完成之后,想加入文件的读取,运行时一直出错,原因可能是头文件忘写以及文本地址复制后,“"要改成”//“。
- 三级难度的样例无法通过。
(有点难,暂时没有处理
心路历程与收获
- 能力低下,菜到安详……拿到题目力不从心,要求好多啊……造成这种感觉的原因主要有两个方面:第一方面:对github,vs等工具使用的不熟悉,学习新知识例如单元测试等的效率太低;第二方面,编程能力低。
- 从一些采用java和python编写该题的同学了解到,他们的代码量,远小于用C++编写。python虽然暑假有自学,但是感觉太过皮毛。接下来考虑深度学习python,并争取在下次作业尝试用python编程。
- 通过这次的编程作业,我重温了C++的string库函数,尝试正则表达式以及C++文件的读取与写入。虽然学习过程艰难、心累,但还是有所收获吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号