自己写个 Drools 文件语法检查工具——栈的应用之编译器检测语法错误
一、背景
当前自己开发的 Android 项目是一个智能推荐系统,用到 drools 规则引擎,于我来说是一个新知识点,以前都没听说过的东东,不过用起来也不算太难,经过一段时间学习,基本掌握。关于 drools 规则引擎的内容,后面再整理JBoss 官网上面有详细的文档,网上资料也比较多。学习 drools 规则引擎的传送门:
Drools 官网首页: https://www.drools.org/
Drools 官方文档: https://docs.jboss.org/drools/release/7.12.0.Final/drools-docs/html_single/index.html
这里主要是因为自己使用 Android Studio 在编写 drools 文件时,没有了智能提示,IDE 不对语法进行检查了,出现了两次多写 ) 的错误。这就跟用记事本写东西程序一样,慌的不行,所以自己写一个简单的语法检查的脚本。对 drools 文件进行一个初步的判断。
二、Drools 规则引擎简单介绍
Drools 规则引擎的使用场景
对于某些企业级应用,经常会有大量的、错综复杂的业务规则配置,用程序语言来描述,就形如:if-else 或者 switch-case等。像这种不同的条件,做不同的处理就是一种规则。用通俗易懂的结构来表示:当 XXX 的时候,做 XXX 的事。理论上这样的问题都可以用规则引擎来解决。但是我们也不是说为了使用规则引擎去使用它,我们视具体业务逻辑而定,一般来说,条件(规则)比较复杂,情况种类比较多,条件可能会经常变化等,这时候,选择规则引擎去解决问题是比较明智的。
譬如随着企业管理者的决策变化,某些业务规则也会随之发生更改。对于我们开发人员来说,我们不得不一直处理软件中的各种复杂问题,需要将所有数据进行关联,还要尽可能快地一次性处理更多的数据,甚至还需要以快速的方式更新相关机制。
Drools 规则引擎的优点
Drools 规则引擎实现了将业务决策从应用程序中分离出来。
优点:
1、简化系统架构,优化应用
2、方便系统的整合,它们是独立的,允许不同背景的人进行合作
3、减少编写“硬代码”业务规则的成本和风险,每个规则控制所需的最小信息量
4、它们很容易更新,提高系统的可维护性,减小维护成本
Drools的基本工作工程
我们需要传递进去数据,用于规则的检查,调用外部接口,同时还可能获取规则执行完毕之后得到的结果
Fact对象:
指传递给drools脚本的对象,是一个普通的javabean,原来javaBean对象的引用,可以对该对象进行读写操作,并调用该对象的方法。当一个java bean插入到working Memory(内存存储)中,规则使用的是原有对象的引用,规则通过对fact对象的读写,实现对应用数据的读写,对其中的属性,需要提供get和set方法,规则中可以动态的前往working memory中插入删除新的fact对象
Drl文件内容:
例子:
hello.drl文件如下:
package rules.testword
rule "test001"
when
//这里如果为空,则表示eval(true)
then
System.out.println("hello word");
end
Drools的基础语法:
包路径,引用,规则体 (其中包路径和规则体是必须的)
package:
包路径,该路径是逻辑路径(可以随便写,但是不能不写,最好和文件目录同名,以(.)的方式隔开),规则文件中永远是第一行。
rule:
规则体,以rule开头,以end结尾,每个文件可以包含多个rule ,规则体分为3个部分:LHS,RHS,属性 三大部分。
LHS:
(Left Hand Side),条件部分,在一个规则当中“when”和“then”中间的部分就是LHS部分,在LHS当中,可以包含0~N个条件,如果 LHS 为空的话,那么引擎会自动添加一个eval(true)的条件,由于该条件总是返回true,所以LHS为空的规则总是返回true。
RHS:
(Right Hand Side),在一个规则中“then”后面的部分就是RHS,只有在LHS的所有条件都满足的情况下,RHS部分才会执行。RHS部分是规则真正做事情的部分,满足条件触发动作的操作部分,在RHS可以使用LHS部分当中的定义的绑定变量名,设置的全局变量、或者是直接编写的java代码,可以使用import的类。不建议有条件判断。
三、drools 文件的形式
Drools是一款基于Java的开源规则引擎,所以 Drools 文件语法完全兼容 java 语法,以 .drl 为后缀。大致形式如下:
package droolsexample
// list any import classes here.
import com.sample.ItemCity;
import java.math.BigDecimal;
// declare any global variables here
dialect "java"
/*
规则1
*/
rule "Pune Medicine Item"
when
item : ItemCity (purchaseCity == ItemCity.City.PUNE,
typeofItem == ItemCity.Type.MEDICINES)
then
BigDecimal tax = new BigDecimal(0.0);
item.setLocalTax(tax.multiply(item.getSellPrice()));
end
/**
规则2
*/
rule "Pune Groceries Item"
when
item : ItemCity(purchaseCity == ItemCity.City.PUNE,
typeofItem == ItemCity.Type.GROCERIES)
then
BigDecimal tax = new BigDecimal(2.0);
item.setLocalTax(tax.multiply(item.getSellPrice()));
end
和 java 文件类似,先声明包名,然后导入相关的类。一个规则由:
rule "xxx"
when
xxx
then
xxx
end
这样的形式构成。其中单行注释以 // 开头,多行注释形如 /* */ 。
四、Drools 文件语法初步检查
目的
检测 .drl 文件中 ( ) 、 { } 、 " " 是否成对出现。如果出现错误,指出错误行数。
思路
利用 栈 的数据结构来进行检测。
首先我们需要给出一个空栈,然后把待检测的代码中的字符一一入栈,在入栈的过程中,如果字符是一个开放符号a(也就是我们的左括号),则把它压入栈中,如果是一个封闭符号(右括号)b,则此时先判断一下栈是否为空,如果为空的话,则报错(也就是待检测的代码中的括号不一一对应),如果栈不为空,则比较b和栈顶元素a,如果该封闭字符b和a字符匹配(也就是他们的括号能够匹配),则弹出栈顶元素,如果不匹配,则报错。当吧所有待检测的代码全部迭代完后,此时如果栈不为空,则报错。
上面的思路中,我们还要将注释中的符号排除在外。
步骤
1、读取 drl 文件内容为字符串。
2、通过正则匹配,将 :// 替换为其它不受影响的字符或者字符串 ,避免误判断。
3、通过正则匹配,将 // 单行注释替换为空格。正则表达式为 //.*
4、通过正则匹配,将 /* 和 */ 替换为不受影响的字符,如 #。(纯粹是为了计算出错行数)
5、借助栈的数据结构,进行判断。
python 脚本实现
# coding=utf-8
import re
def remove_annotation(file_path):
with open(file_path, "r", encoding="UTF-8") as f:
text = f.read()
re_uri = "://"
text1 = re.sub(re_uri, "_____", text)
re_single = "//.*"
text2 = re.sub(re_single, " ", text1)
re_multi1 = "/\*"
text3 = re.sub(re_multi1, "#", text2)
re_multi2 = "\*/"
result = re.sub(re_multi2, "#", text3)
return result
def check_syntax(text):
try:
clist = []
row_num = 1
for c in text:
if c == '\n':
row_num = row_num + 1
if not clist or (clist[-2] != '\"' and clist[-2] != '#'):
if c == '\"':
clist.append(c)
clist.append(row_num)
if c == '#':
clist.append(c)
clist.append(row_num)
if c == '(':
clist.append(c)
clist.append(row_num)
if c == '{':
clist.append(c)
clist.append(row_num)
if c == ')':
if clist[-2] == '(':
clist.pop()
clist.pop()
else:
print("多余的 ) , 可能错误行数为 " + str(row_num))
return -1
if c == '}':
if clist[-2] == '{':
clist.pop()
clist.pop()
else:
print("多余的 } , 可能错误行数为 " + str(row_num))
return -1
else:
if c == '\"':
if clist[-2] == '\"':
clist.pop()
clist.pop()
if c == '#':
if clist[-2] == '#':
clist.pop()
clist.pop()
if clist:
print("存在多余的 ( 或者 { 或者 \" 可能的错误行数为:" + str(clist[-1]))
return -2
else:
print("语法检查初步正确!")
return 0
except IndexError:
print("存在多余的 ) 或者 } 或者 \" 可能的错误行数为: " + str(row_num))
return -1
except Exception as e:
print(e)
print("其它错误!")
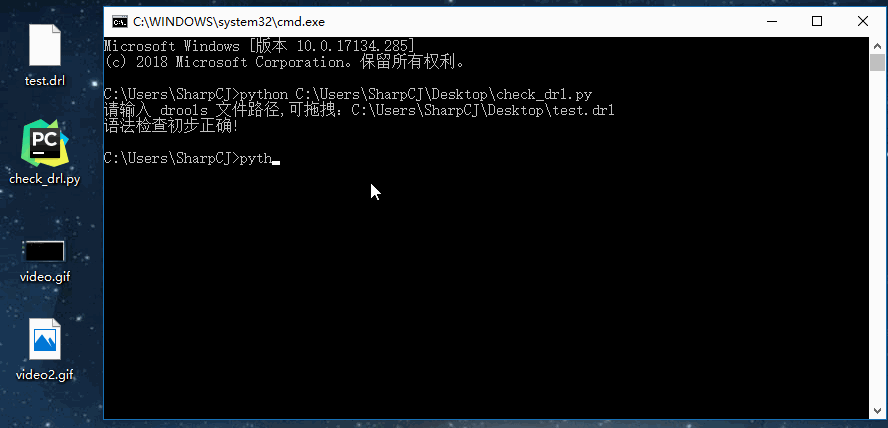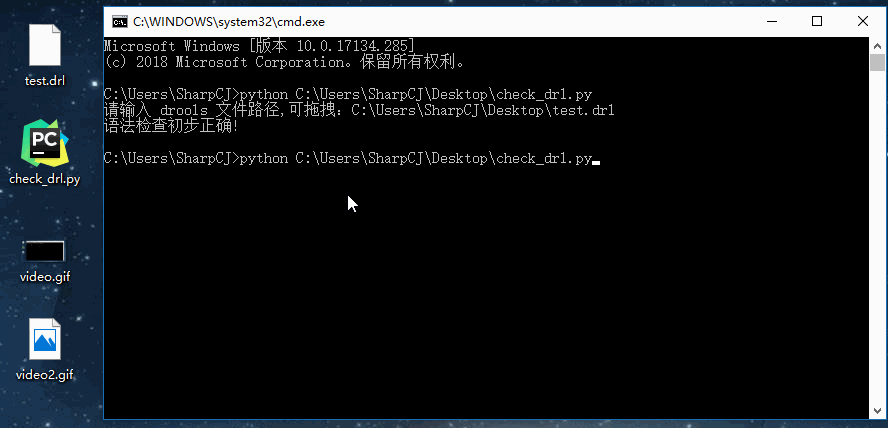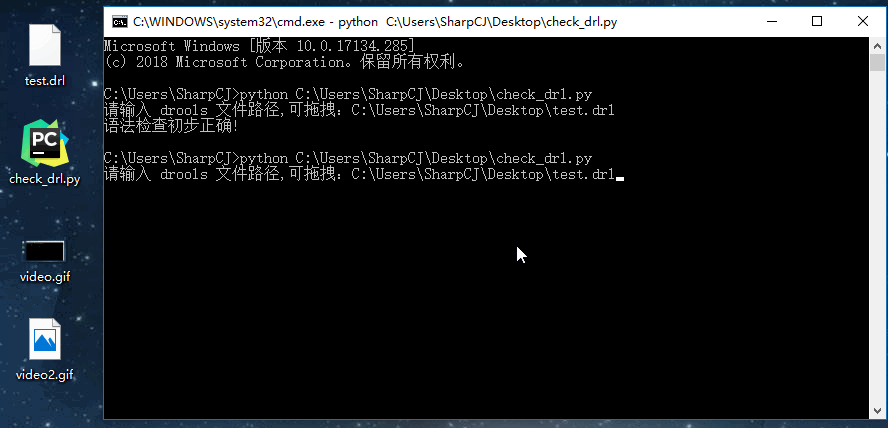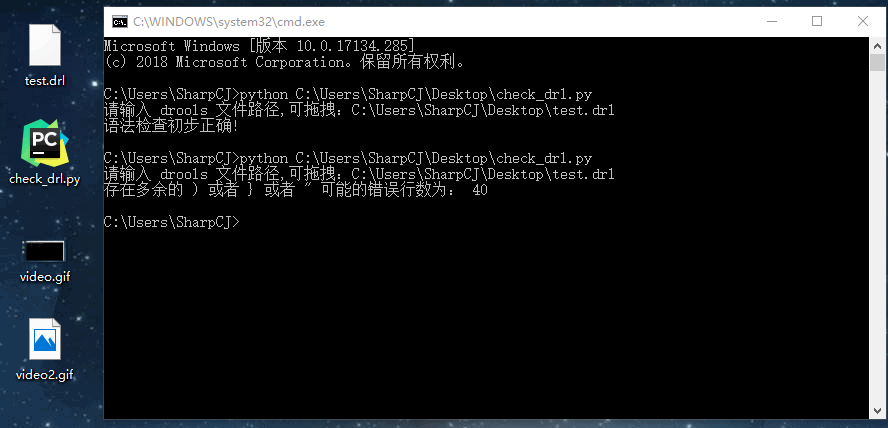
drl_path = input("请输入 drools 文件路径,可拖拽:")
content = remove_annotation(drl_path)
check_syntax(content)
演示实例:
drools 文件就取用上面的例子,命名为 test.drl ,如图:
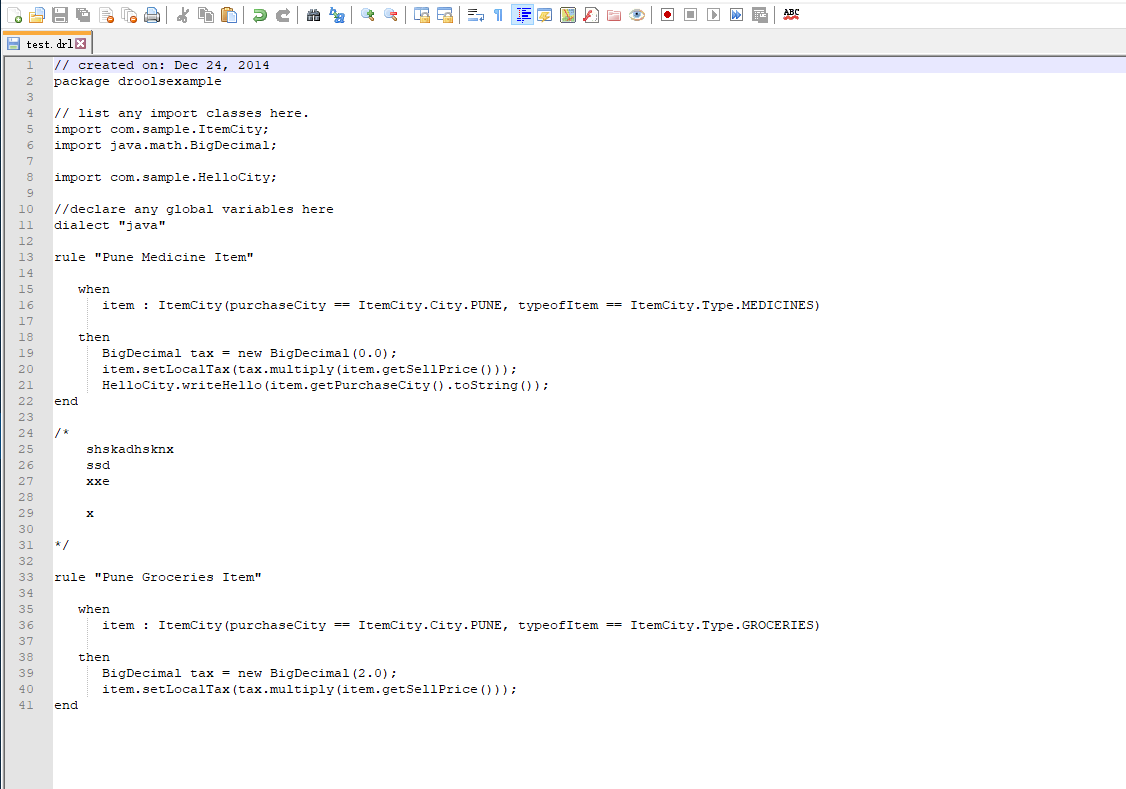
上面的脚本保存为 check_drl.py 文件。
结果如下:

下面将故意将 drools 文件第 40 行增加一个 ) ,如下图:
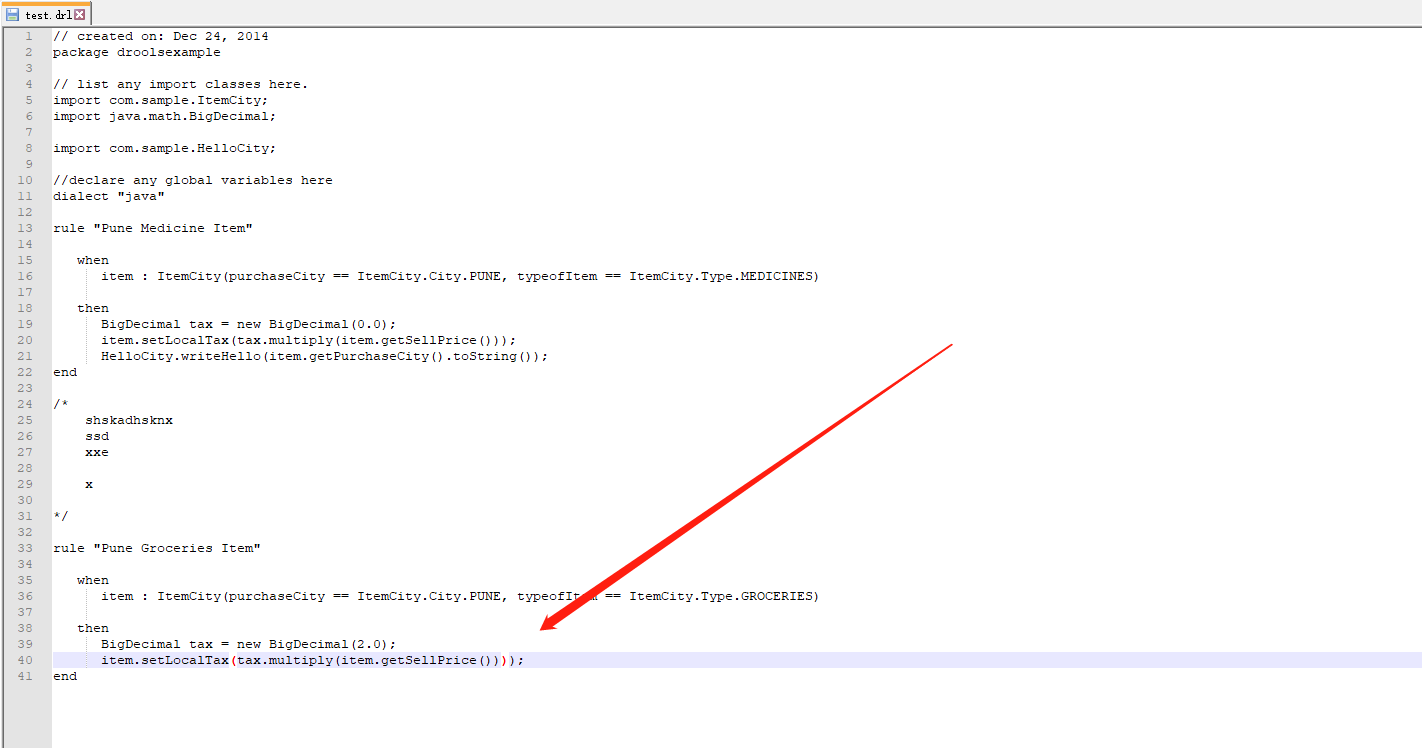
再次测试如下图:
结语
本文简单介绍了一下 Drools 规则引擎的使用场景以及 drool 文件的简单语法检测,主要是利用了栈数据结构后进先出的思想。本来是计划用 java 来写这个工具的,后来想了一下,还是觉得 python 比较实在,有很多优势,列举一二:
python 的列表 list 直接可以代替 java 的 Stack<E> ;
python 结合正则表达式,处理字符串更方便;
python 获取 list 倒数第二个元素,可以直接使用 list[-2] ,java 可能需要 stack.get(stack.size()-2) ;
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号