spring-springmvc-mybatis-shiro-mysql-dubbo-mongodb-redis-rabbitmq-quartz-druid-fastDFS-vsftpd-Swagger2-logback-ELK 学习笔记
一、Dubbo背景
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
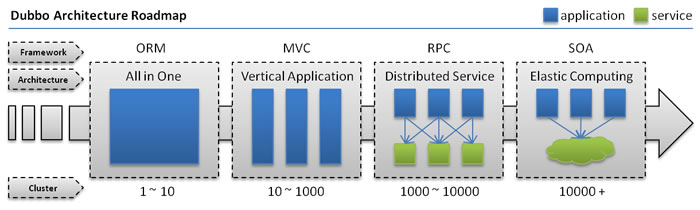
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
二、需求
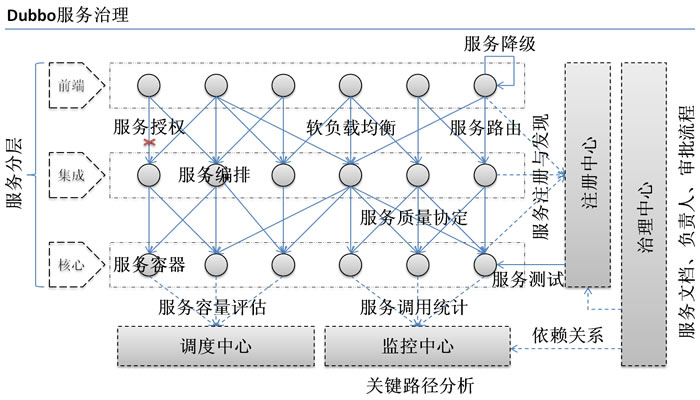
在大规模服务化之前,应用可能只是通过 RMI 或 Hessian 等工具,简单的暴露和引用远程服务,通过配置服务的URL地址进行调用,通过 F5 等硬件进行负载均衡。
当服务越来越多时,服务 URL 配置管理变得非常困难,F5 硬件负载均衡器的单点压力也越来越大。 此时需要一个服务注册中心,动态的注册和发现服务,使服务的位置透明。并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对 F5 硬件负载均衡器的依赖,也能减少部分成本。
当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。 这时,需要自动画出应用间的依赖关系图,以帮助架构师理清理关系。
接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器? 为了解决这些问题,第一步,要将服务现在每天的调用量,响应时间,都统计出来,作为容量规划的参考指标。其次,要可以动态调整权重,在线上,将某台机器的权重一直加大,并在加大的过程中记录响应时间的变化,直到响应时间到达阀值,记录此时的访问量,再以此访问量乘以机器数反推总容量。
以上是 Dubbo 最基本的几个需求。
三、架构
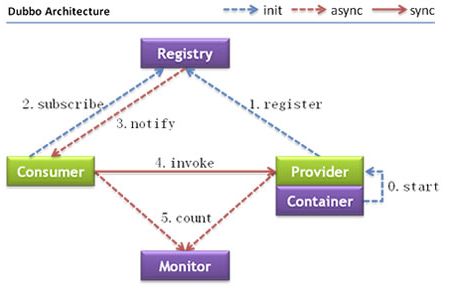
Provider:暴露服务的服务提供方
Consumer:调用远程服务的服务消费方
Registry:服务注册与发现的注册中心
Monitor: 统计服务的调用次调和调用时间的监控中心
Container: 服务运行容器
调用关系说明
0.服务容器负责启动,加载,运行服务提供者。
1.服务提供者在启动时,向注册中心注册自己提供的服务。
2.服务消费者在启动时,向注册中心订阅自己所需的服务。
3.注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
4.服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
5.服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 架构具有以下几个特点,分别是连通性、健壮性、伸缩性、以及向未来架构的升级性。
连通性
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
- 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
健状性
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
伸缩性
- 注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
- 服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
升级性
当服务集群规模进一步扩大,带动IT治理结构进一步升级,需要实现动态部署,进行流动计算,现有分布式服务架构不会带来阻力。下图是未来可能的一种架构:
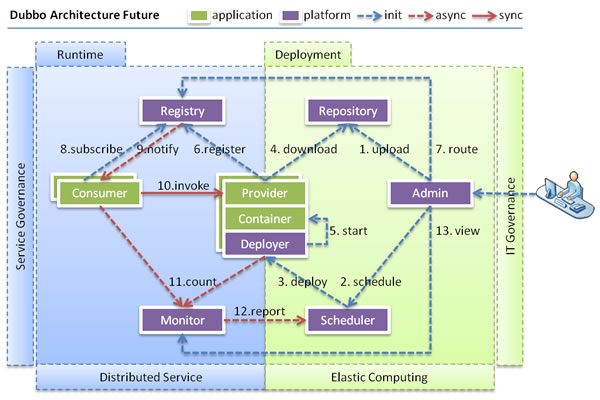
当服务集群规模进一步扩大,带动IT治理结构进一步升级,需要实现动态部署,进行流动计算,现有分布式服务架构不会带来阻力:
Deployer: 自动部署服务的本地代理。
Repository: 仓库用于存储服务应用发布包。
Scheduler: 调度中心基于访问压力自动增减服务提供者。
Admin: 统一管理控制台。
异步调用
基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小。
本地调用
本地调用,使用了Injvm协议,是一个伪协议,它不开启端口,不发起远程调用,只在JVM内直接关联,但执行Dubbo的Filter链。
四、用法
本地服务spring配置
local.xml:
<bean id=“xxxService” class=“com.xxx.XxxServiceImpl” /> <bean id=“xxxAction” class=“com.xxx.XxxAction”> <property name=“xxxService” ref=“xxxService” /> </bean>
远程服务:(Spring配置)
在本地服务的基础上,只需做简单配置,即可完成远程化:
将上面的local.xml配置拆分成两份,将服务定义部分放在服务提供方remote-provider.xml,将服务引用部分放在服务消费方remote-consumer.xml。
并在提供方增加暴露服务配置,在消费方增加引用服务配置。
如下:
remote-provider.xml:
<!-- 和本地服务一样实现远程服务 --> <bean id=“xxxService” class=“com.xxx.XxxServiceImpl” /> <!-- 增加暴露远程服务配置 --> <dubbo:service interface=“com.xxx.XxxService” ref=“xxxService” />
remote-consumer.xml:
<!-- 增加引用远程服务配置 --> <dubbo:reference id=“xxxService” interface=“com.xxx.XxxService” /> <!-- 和本地服务一样使用远程服务 --> <bean id=“xxxAction” class=“com.xxx.XxxAction”> <property name=“xxxService” ref=“xxxService” /> </bean>
实例:
spring-provider.xml
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.springframework.org/schema/beans" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd"> <!-- 提供方应用信息,用于计算依赖关系 --> <dubbo:application name="journey-dubbo-core-provider"/> <!-- 使用zookeeper注册中心暴露服务地址 --> <dubbo:registry id="journey-dubbo-provider" address="zookeeper://192.168.74.128:2181" check="false" subscribe="false" register=""/> <!-- 用dubbo协议在20880端口暴露服务 --> <dubbo:protocol id="journey-dubbo" name="dubbo" port="20880"/> <dubbo:provider registry="journey-dubbo-provider" protocol="journey-dubbo"/> <!--监控中心--> <!--监控中心协议,如果protocol="registry 表示从注册中心发现监控中心地址,否则直连监控中心"--> <dubbo:monitor protocol="registry"/> <!-- 具体的bean实现 --> <bean id="userService" class="com.dubbo.core.user.service.UserServiceImp" /> <!-- 声明需要暴露的服务接口 --> <dubbo:service interface="com.dubbo.api.user.service.IUserService" ref="userService" timeout="500000"/> </beans>
spring-consumer.xml:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd "> <!-- 消费方应用名,用于计算依赖关系,不是匹配条件,不要与提供方一样 --> <dubbo:application name="dubbo-customer" /> <!-- 使用zookeeper注册中心暴露服务地址 --> <dubbo:registry address="zookeeper://192.168.74.128:2181" /> <!--监控中心--> <!--监控中心协议,如果protocol="registry 表示从注册中心发现监控中心地址,否则直连监控中心"--> <dubbo:monitor protocol="registry"/> <!-- 生成远程服务代理,可以像使用本地bean一样使用demoService --> <dubbo:reference id="userService" interface="com.dubbo.api.user.service.IUserService" /> </beans>
五、Shiro特性
Shiro是一个强大的简单易用的Java安全框架,主要用来更便捷的认证,授权,加密,会话管理等等。
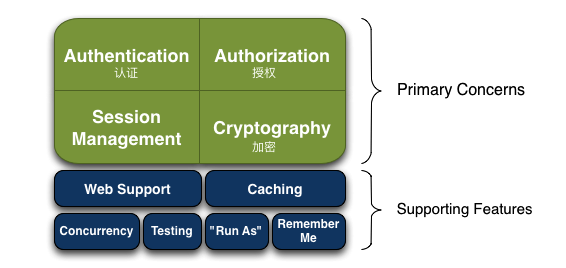
六、Shiro架构
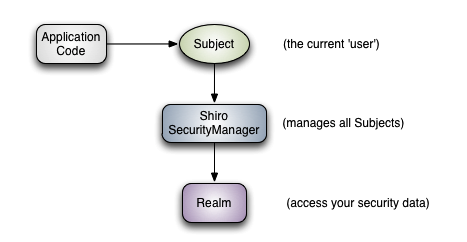
从图中可以看出shiro有三个主要核心概念:
Subject:主角,当前参与应用安全部分的主角。可以是用户,第三方服务,cron 任务,或者任何东西。主要指一个正在与当前软件交互的东西。 所有Subject都需要SecurityManager,当与Subject进行交互时实际上这些交互行为被转换为与SecurityManager的交互。
SecurityManager:安全管理员,Shiro架构的核心,它就像Shiro内部所有原件的保护伞。然而一旦配置了SecurityManager,SecurityManager就用到的比较少,开发者大部分时间都花在Subject上面。 当与Subject进行交互的时候,实际上是SecurityManager在背后帮你举起Subject来做一些安全操作。
Realms:Realms作为Shiro和应用的连接桥,当需要与安全数据交互的时候,像用户账户,或者访问控制,Shiro就从一个或多个Realms中查找。 Shiro提供了一些可以直接使用的Realms,也可以定制自己的Realms。
更细节的架构
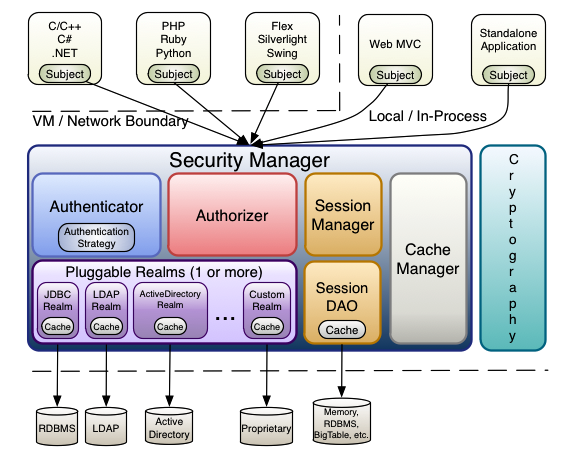
七、Shiro使用
<dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-core</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-spring</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>org.apache.shiro</groupId> <artifactId>shiro-ehcache</artifactId> <version>1.2.2</version> </dependency>
spring-shiro.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd" default-lazy-init="true"> <!--安全管理器--> <bean id="securityManager" class="org.apache.shiro.web.mgt.DefaultWebSecurityManager"> <!--设置自定义Realm--> <property name="realm" ref="myShiroRealm"/> <!--将缓存管理器,交给安全管理器--> <property name="cacheManager" ref="shiroEhcacheManager"/> </bean> <!-- 項目自定义的Realm --> <bean id="myShiroRealm" class="com.dubbo.web.shiro.MyShiroRealm"/> <!-- Shiro Filter --> <bean id="shiroFilter" class="org.apache.shiro.spring.web.ShiroFilterFactoryBean"> <!-- 安全管理器 --> <property name="securityManager" ref="securityManager"/> <!-- 默认的登陆访问url --> <property name="loginUrl" value="/login"/> <!-- 登陆成功后跳转的url --> <property name="successUrl" value="/index"/> <!-- 没有权限跳转的url --> <property name="unauthorizedUrl" value="/unauth"/> <property name="filterChainDefinitions"> <value> /commons/** = anon <!-- 不需要认证 --> /static/** = anon /login = anon /** = authc <!-- 需要认证 --> </value> </property> </bean> <!-- 用户授权信息Cache, 采用EhCache --> <bean id="shiroEhcacheManager" class="org.apache.shiro.cache.ehcache.EhCacheManager"> <property name="cacheManagerConfigFile" value="classpath:ehcache-shiro.xml"/> </bean> <!-- 在方法中 注入 securityManager ,进行代理控制 --> <bean class="org.springframework.beans.factory.config.MethodInvokingFactoryBean"> <property name="staticMethod" value="org.apache.shiro.SecurityUtils.setSecurityManager"/> <property name="arguments" ref="securityManager"/> </bean> <!-- 保证实现了Shiro内部lifecycle函数的bean执行 --> <bean id="lifecycleBeanPostProcessor" class="org.apache.shiro.spring.LifecycleBeanPostProcessor"/> <!-- AOP式方法级权限检查 --> <bean class="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator" depends-on="lifecycleBeanPostProcessor"/> <!-- 启用shrio授权注解拦截方式 --> <bean class="org.apache.shiro.spring.security.interceptor.AuthorizationAttributeSourceAdvisor"> <property name="securityManager" ref="securityManager"/> </bean> </beans>
ehcache-shiro.xml
<?xml version="1.0" encoding="UTF-8"?> <ehcache updateCheck="false" name="shiroCache"> <defaultCache maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="false" diskPersistent="false" diskExpiryThreadIntervalSeconds="120" /> </ehcache>
shiroFilter
<!--Shiro过滤器--> <filter> <filter-name>shiroFilter</filter-name> <filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class> <init-param> <param-name>targetFilterLifecycle</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>shiroFilter</filter-name> <url-pattern>/*</url-pattern> <dispatcher>REQUEST</dispatcher> <dispatcher>FORWARD</dispatcher> </filter-mapping>
八、Druid简介
Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一些限制,可以让程序员实现一些特殊的需求,比如向密钥服务请求凭证、统计SQL信息、SQL性能收集、SQL注入检查、SQL翻译等,程序员可以通过定制来实现自己需要的功能。
Druid是目前最好的数据库连接池,在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource。Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。
九、Druid功能
1、替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
2、可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
3、数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
4、SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
5、扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter机制,很方便编写JDBC层的扩展插件。
十、Druid使用
在pom文件中添加
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.0.27</version> </dependency>
十一、配置DruidDataSource
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <!-- 基本属性 url、user、password --> <property name="url" value="${master_driverUrl}" /> <property name="username" value="${master_username}" /> <property name="password" value="${master_password}" /> <!-- 配置初始化大小、最小、最大 --> <property name="initialSize" value="5" /> <property name="maxActive" value="100" /> <property name="minIdle" value="10" /> <!-- 配置获取连接等待超时的时间 --> <property name="maxWait" value="60000" /> <property name="validationQuery" value="SELECT 'x'" /> <property name="testOnBorrow" value="true" /> <property name="testOnReturn" value="true" /> <property name="testWhileIdle" value="true" /> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="60000" /> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="300000" /> <property name="removeAbandoned" value="true" /> <property name="removeAbandonedTimeout" value="1800" /> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="true" /> <property name="maxPoolPreparedStatementPerConnectionSize" value="20" /> <property name="logAbandoned" value="true" /> <!-- 配置监控统计拦截的filters --> <property name="filters" value="mergeStat" /> </bean>
通常来说,只需要修改initialSize、minIdle、maxActive。
如果用Oracle,则把poolPreparedStatements配置为true,mysql可以配置为false。分库分表较多的数据库,建议配置为false。
DruidFilter
<servlet> <servlet-name>DruidStatView</servlet-name> <servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>DruidStatView</servlet-name> <url-pattern>/druid/*</url-pattern> </servlet-mapping> <filter> <filter-name>DruidWebStatFilter</filter-name> <filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> <init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param> <init-param> <param-name>profileEnable</param-name> <param-value>true</param-value> </init-param> <init-param> <param-name>principalCookieName</param-name> <param-value>USER_COOKIE</param-value> </init-param> <init-param> <param-name>principalSessionName</param-name> <param-value>USER_SESSION</param-value> </init-param> </filter> <filter-mapping> <filter-name>DruidWebStatFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
(另附SpringBootDruid)
#数据库设置 start spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driverClassName=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.74.128:3306/journey?useUnicode=true&characterEncoding=UTF-8 spring.datasource.username=root spring.datasource.password=root # 下面为连接池的补充设置,应用到上面所有数据源中 # 初始化大小,最小,最大 spring.datasource.initialSize=5 spring.datasource.minIdle=5 spring.datasource.maxActive=20 # 配置获取连接等待超时的时间 spring.datasource.maxWait=60000 # 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 spring.datasource.timeBetweenEvictionRunsMillis=60000 # 配置一个连接在池中最小生存的时间,单位是毫秒 spring.datasource.minEvictableIdleTimeMillis=300000 spring.datasource.validationQuery=SELECT 'X' spring.datasource.testWhileIdle=true spring.datasource.testOnBorrow=false spring.datasource.testOnReturn=false # 打开PSCache,并且指定每个连接上PSCache的大小 spring.datasource.poolPreparedStatements=true spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 spring.datasource.filters=stat,wall,log4j # 通过connectProperties属性来打开mergeSql功能;慢SQL记录 spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 合并多个DruidDataSource的监控数据 #spring.datasource.useGlobalDataSourceStat=true
DaraSourceConfig
package com.xsjt.conf; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import java.sql.SQLException; /** * 数据库连接池配置 * @author Journey * */ @Configuration public class DataSourcesConfig { /** * druid初始化 * @return * @throws SQLException */ @Primary //默认数据源 @Bean(name = "dataSource",destroyMethod = "close") @ConfigurationProperties(prefix = "spring.datasource") public DruidDataSource Construction() throws SQLException { return new DruidDataSource(); } /** * druid监控 * 访问:http://localhost:8080/druid/login.html * @return */ @Bean public ServletRegistrationBean druidServlet() { ServletRegistrationBean reg = new ServletRegistrationBean(); reg.setServlet(new StatViewServlet()); reg.addUrlMappings("/druid/*"); //reg.addInitParameter("allow", "127.0.0.1"); //reg.addInitParameter("deny",""); reg.addInitParameter("loginUsername", "admin"); reg.addInitParameter("loginPassword", "admin"); return reg; } /** * druid监控过滤 * @return */ @Bean public FilterRegistrationBean filterRegistrationBean() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(); filterRegistrationBean.setFilter(new WebStatFilter()); filterRegistrationBean.addUrlPatterns("/*"); filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"); return filterRegistrationBean; } }
十二、mysql读写分离简介
为什么要进行(主从复制)读写分离
分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量。
在进行数据库读写分离的时候,我们首先要进行数据库的主从配置,最简单的是一台Master和一台Slave(大型网站系统的话,当然会很复杂,这里只是分析了最简单的情况)。通过主从配置主从数据库保持了相同的数据,我们在进行读操作的时候访问从数据库Slave,在进行写操作的时候访问主数据库Master。这样的话就减轻了一台服务器的压力。
在进行读写分离案例分析的时候。首先,配置数据库的主从复制,使用mysqlreplicate命令快速搭建 Mysql 主从复制。
MySQL主从复制的原理

(linux mysql 开启远程访问方式 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'root' WITH GRANT OPTION; 其中%分号可以是制定地址 最后使用命令 FLUSH PRIVILEGES)
MySQL主从复制的基本过程
MySQL主从复制的两种情况:同步复制和异步复制,实际复制架构中大部分为异步复制。复制的基本过程如下:
- 1.Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。
- 2.Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置。
- 3.Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”。
- 4.Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
十三、MySQL主从复制的使用
两种方式:基于日志(binlog) 基于GTID(全局事务标示符)
http://dev.mysql.com/doc/refman/5.6/en/replication.html 官方教程
准备工作
两台服务器
version 5.1.73
主数据库:192.168.74.130
从数据库:192.168.74.131
修改主数据库的配置文件
vi /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disablingsymbolic-links is recommended to prevent assorted security risks
symbolic-links=1
# 设置服务器ID
server-id=1
# 设置需要写日志的数据库
# binlog-do-db=test
# 设置不需要写日志的数据库
# binlog-ignore-db=mysql
# 日志基于行模式
# binlog_format=row
# 二进制日志文件存放位置
log-bin=mysqlmaster-bin.log
#注意:下面这个参数需要修改为服务器内存的70%左右
innodb_buffer_pool_size = 512M
innodb_flush_log_at_trx_commit=1
sql_mode=STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_AUTO_VALUE_ON_ZERO
lower_case_table_names=1
log_bin_trust_function_creators=1
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
修改之后要重启mysql服务:
service mysqld restart
从数据库的的配置文件
注意:(server-id配置为大于主数据库的server-id即可)
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disablingsymbolic-links is recommended to prevent assorted security risks
symbolic-links=1
# 设置服务器ID
server-id=2
# 设置需要写日志的数据库
# binlog-do-db=test
# 设置不需要写日志的数据库
# binlog-ignore-db=mysql
# 日志基于行模式
# binlog_format=row
# 二进制日志文件存放位置
log-bin=mysqlslave-bin.log
#注意:下面这个参数需要修改为服务器内存的70%左右
innodb_buffer_pool_size = 512M
innodb_flush_log_at_trx_commit=1
sql_mode=STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,NO_AUTO_VALUE_ON_ZERO
lower_case_table_names=1
log_bin_trust_function_creators=1
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
service mysqld restart
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.74.131' IDENTIFIED BY 'repl';
在主数据库上创建用于主从复制的账户(192.168.74.131)
主数据库锁表(禁止再插入数据以获取主数据库的的二进制日志坐标)FLUSH TABLES WITH READ LOCK;

使用命令
show master status;
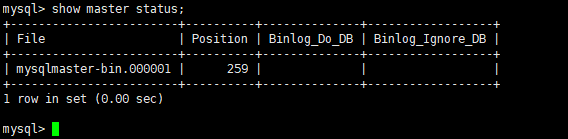
二进制日志文件是mysqlmaster-bin.000001 位置是259
在主数据库上使用mysqldump命令创建一个数据快照
mysqldump -u root -p -h 127.0.0.1 -P 3306 --all-database --triggers --routines --events >all.sql

解锁第2.6.2步主数据的锁表操作
UNLOCK TABLES;
将上备份好的数据库快照all.sql上传到从数据库
mysql -u root -p -h 127.0.0.1 -P 3306 < all.sql

给从数据库设置复制的主数据库信息(注意修改MASTER_LOG_FILE和MASTER_LOG_POS的值)
CHANGE MASTER TO MASTER_HOST='192.168.74.130',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_LOG_FILE='mysqlmaster-bin.000001',MASTER_LOG_POS=259;

启动从数据库的复制线程
start slave;
查询数据库的slave状态
SHOW slave STATUS \G
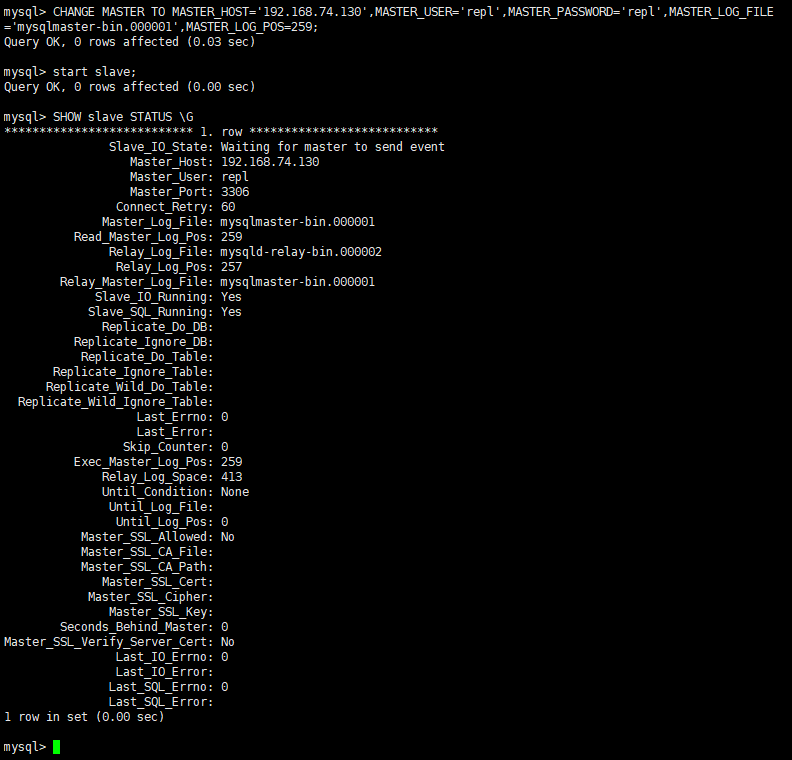
可以看到:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
一主一从的主从复制就实现了。
十四、Spring AOP 实现MySQL读写分离
实现读写分离的两种方法
- 第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单。
- 第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:Annotation,spring AOP ,反射。
创建用于配置动态分配的读写的数据源ChooseDataSource.java
package com.dubbo.util.aspect; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import org.apache.commons.lang3.StringUtils; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; /** * 获取数据源,用于动态切换数据源 */ public class ChooseDataSource extends AbstractRoutingDataSource { public static Map<String, List<String>> METHOD_TYPE_MAP = new HashMap<String, List<String>>(); /** * 实现父类中的抽象方法,获取数据源名称 * @return */ protected Object determineCurrentLookupKey() { return DataSourceHandler.getDataSource(); } // 设置方法名前缀对应的数据源 public void setMethodType(Map<String, String> map) { for (String key : map.keySet()) { List<String> v = new ArrayList<String>(); String[] types = map.get(key).split(","); for (String type : types) { if (StringUtils.isNotBlank(type)) { v.add(type); } } METHOD_TYPE_MAP.put(key, v); } } }
DataSourceAspect进行具体方法的AOP拦截
package com.dubbo.util.aspect;
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.stereotype.Component;
/**
* 切换数据源(不同方法调用不同数据源)
*/
@Aspect
@Component
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class DataSourceAspect {
protected Logger logger = LoggerFactory.getLogger(this.getClass());
@Pointcut("execution(* com.dubbo.core.*.dao.*.*(..))")
public void aspect() {
}
/**
* 配置前置通知,使用在方法aspect()上注册的切入点
*/
@Before("aspect()")
public void before(JoinPoint point) {
String className = point.getTarget().getClass().getName();
String method = point.getSignature().getName();
logger.info(className + "." + method + "(" + StringUtils.join(point.getArgs(), ",") + ")");
try {
for (String key : ChooseDataSource.METHOD_TYPE_MAP.keySet()) {
for (String type : ChooseDataSource.METHOD_TYPE_MAP.get(key)) {
if (method.startsWith(type)) {
DataSourceHandler.putDataSource(key);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
数据源的Handler类 DataSourceHandler.java
package com.dubbo.util.aspect; /** * 数据源的Handler类 * */ public class DataSourceHandler { // 数据源名称线程池 public static final ThreadLocal<String> holder = new ThreadLocal<String>(); /** * 在项目启动的时候将配置的读、写数据源加到holder中 */ public static void putDataSource(String datasource) { holder.set(datasource); } /** * 从holer中获取数据源字符串 */ public static String getDataSource() { return holder.get(); } }
spring-db.xml读写数据源配置
driver=com.mysql.jdbc.Driver url=jdbc:mysql://192.168.74.132:3306/journey url1=jdbc:mysql://192.168.74.133:3306/journey username=root password=root password1=root initialSize=0 maxActive=20 maxIdle=20 minIdle=1 maxWait=60000 timeBetweenEvictionRunsMillis=3000 minEvictableIdleTimeMillis=300000 maxPoolPreparedStatementPerConnectionSize=20 druid.filters= <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.3.xsd"> <!-- 引入配置文件 <bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="location" value="classpath:jdbc.properties" /> </bean> --> <bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="locations"> <list> <value>classpath:jdbc.properties</value> <value>classpath:mongo.properties</value> <value>classpath:redis.properties</value> </list> </property> </bean> <bean id="statFilter" class="com.alibaba.druid.filter.stat.StatFilter" lazy-init="true"> <property name="logSlowSql" value="true" /> <property name="mergeSql" value="true" /> </bean> <bean id="readDataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> <property name="url" value="${url}" /> <property name="username" value="${username}" /> <property name="password" value="${password}" /> <property name="filters" value="stat" /> <property name="maxActive" value="20" /> <property name="initialSize" value="1" /> <property name="maxWait" value="60000" /> <property name="minIdle" value="1" /> <property name="timeBetweenEvictionRunsMillis" value="3000" /> <property name="minEvictableIdleTimeMillis" value="300000" /> <property name="validationQuery" value="SELECT 'x'" /> <property name="testWhileIdle" value="true" /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> <property name="poolPreparedStatements" value="true" /> <property name="maxPoolPreparedStatementPerConnectionSize" value="20" /> </bean> <bean id="writeDataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close" init-method="init" lazy-init="true"> <property name="driverClassName" value="${driver}" /> <property name="url" value="${url1}" /> <property name="username" value="${username}" /> <property name="password" value="${password1}" /> <property name="initialSize" value="${initialSize}" /> <property name="maxActive" value="${maxActive}" /> <property name="minIdle" value="${minIdle}" /> <property name="maxWait" value="${maxWait}" /> <property name="proxyFilters"> <list> <ref bean="statFilter" /> </list> </property> <property name="filters" value="${druid.filters}" /> <property name="connectionProperties" value="password=${password1}" /> <property name="testWhileIdle" value="true" /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> <property name="validationQuery" value="SELECT 'x'" /> <property name="timeBetweenLogStatsMillis" value="60000" /> <property name="minEvictableIdleTimeMillis" value="${minEvictableIdleTimeMillis}" /> <property name="timeBetweenEvictionRunsMillis" value="${timeBetweenEvictionRunsMillis}" /> </bean> <!-- 配置动态分配的读写 数据源 --> <bean id="dataSource" class="com.dubbo.util.aspect.ChooseDataSource" lazy-init="true"> <property name="targetDataSources"> <map key-type="java.lang.String" value-type="javax.sql.DataSource"> <!-- write --> <entry key="write" value-ref="writeDataSource" /> <!-- read --> <entry key="read" value-ref="readDataSource" /> </map> </property> <property name="defaultTargetDataSource" ref="writeDataSource" /> <property name="methodType"> <map key-type="java.lang.String"> <!-- read --> <entry key="read" value=",get,select,count,list,query" /> <!-- write --> <entry key="write" value=",add,create,update,delete,remove," /> </map> </property> </bean> </beans>
配置了readDataSource和writeDataSource两个数据源,但是交给 SqlSessionFactoryBean进行管理的只有dataSource,使用了com.dubbo.util.aspect.ChooseDataSource来进行数据源的选择,默认的数据源是writeDataSource。methodType是定义了方法的关键字,那些是选择读库,那个是写库。
在Dao层通过切面选择数据源
package com.dubbo.core.user.service; import java.util.List; import javax.annotation.Resource; import org.springframework.stereotype.Service; import com.dubbo.api.service.user.IUserService; import com.dubbo.core.user.dao.IUserDao; import com.dubbo.model.user.User; @Service("userService") public class UserServiceImp implements IUserService { @Resource IUserDao mIUserDao; @Override public User getUserById(int userId) { return mIUserDao.selectByPrimaryKey(userId); } @Override public User getUserByUsername(String username) { return mIUserDao.selectByPrimaryUsername(username); } @Override public void addUser(User user) { mIUserDao.insert(user); } @Override public List<User> getAllUser() { return mIUserDao.selectAllUsers(); } @Override public int delUserById(Integer userId) { return mIUserDao.deleteByPrimaryKey(userId); } @Override public int updateUser(User user) { return mIUserDao.updateByPrimaryKey(user); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号