线程相关
一丶锁
1.锁:LOCK(一次放一个)
线程安全,多线程操作的时候,内部会让所有线程排队处理,如list/dict/Queue
线程不安全 + 人 => 排队处理
需求:
a.创建100个线程,在列表中追加8
b.创建100个线程
v = []
锁
把自己的添加到列表中。
在读取列表的最后一个。
解锁


import threading
import time
v = []
lock = threading.Lock()
def func(arg):
lock.acquire()
v.append(arg)
time.sleep(0.01)
m = v[-1]
print(arg,m)
lock.release()
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
2.锁 Rlock(一次放一个)
import threading
import time
v = []
lock = threading.RLock()
def func(arg):
lock.acquire()
lock.acquire()
v.append(arg)
time.sleep(0.01)
m = v[-1]
print(arg,m)
lock.release()
lock.release()
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
3.锁 BoundedSemaphone(一次放n个) 信号量
import time
import threading
lock = threading.BoundedSemaphore(3)
def func(arg):
lock.acquire()
print(arg)
time.sleep(1)
lock.release()
for i in range(20):
t =threading.Thread(target=func,args=(i,))
t.start()
4.锁 Condition(1次方法x个)
import time
import threading
lock = threading.Condition()
# ############## 方式一 ##############
def func(arg):
print('线程进来了')
lock.acquire()
lock.wait() # 加锁
print(arg)
time.sleep(1)
lock.release()
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
while True:
inp = int(input('>>>'))
lock.acquire()
lock.notify(inp)
lock.release()
def xxxx():
print('来执行函数了')
input(">>>")
# ct = threading.current_thread() # 获取当前线程
# ct.getName()
return True
def func(arg):
print('线程进来了')
lock.wait_for(xxxx)
print(arg)
time.sleep(1)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
5.锁 Event(一次放所有)
import time
import threading
lock = threading.Event()
def func(arg):
print('线程来了')
lock.wait() # 加锁:红灯
print(arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
input(">>>>")
lock.set() # 绿灯
lock.clear() # 再次变红灯
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
input(">>>>")
lock.set()
总结:
线程安全,列表和字典线程安全;
为什么要加锁?
- 非线程安全
- 控制一段代码
二丶threading.local原理
1.threading.local
作用:内部自动为每一个线程维护一个空间(字典),用于当前存取的属于自己的值,保证线程之间的数据隔离
{
线程ID:{...}
线程ID:{...}
线程ID:{...}
}
2.threading.loacl 原理
import time
import threading
DATA_DICT = {}
def func(arg):
ident = threading.get_ident()
DATA_DICT[ident] = arg
time.sleep(1)
print(DATA_DICT[ident],arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
import time
import threading
INFO = {}
class Local(object):
def __getattr__(self, item):
ident = threading.get_ident()
return INFO[ident][item]
def __setattr__(self, key, value):
ident = threading.get_ident()
if ident in INFO:
INFO[ident][key] = value
else:
INFO[ident] = {key:value}
obj = Local()
def func(arg):
obj.phone = arg # 调用对象的 __setattr__方法(“phone”,1)
time.sleep(2)
print(obj.phone,arg)
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
三丶关于线程安全
你的PC或者笔记本还是单核吗? 如果是,那你已经out了.
随着纳米技术的不断进步, 计算机芯片的工艺也在进步,但是已经很难在工艺上的改进来提高 运算速度而满足 摩尔定理, 所以intel, amd相继在采用横向的扩展即增加更多的CPU, 从而双核, 4核, N核不断推出,于是我们进入了多核时代.
于是一个问题出现了, 多核时代的出现对于我们程序员而言意味着什么, 我们如何利用多核的优势?
在回答这个问题之前,建议对 进程 和 线程 不熟悉的读者可以先补下相关的知识.
当然方案是,可以采用 多进程, 也可以采用 多线程. 二者的最大区别就是, 是否共享资源, 后者是共享资源的,而前者是独立的. 所以你也可能想起了google chrome为什么又开始使用独立的进程 来作为每个tab服务了(不共享数据,意味着有更好的安全性).
相对于进程的轻型特征,多线程环境有个最大的问题就是 如何保证资源竞争,死锁, 数据修改等.
于是,便有了 线程安全 (thread safety)的提出.
线程安全
Thread safety is a computer programming concept applicable in the context of multi-threaded programs.
A piece of code is thread-safe if it functions correctly during simultaneous execution by multiple threads.
In particular, it must satisfy the need for multiple threads to access the same shared data,
and the need for a shared piece of data to be accessed by only one thread at any given time.
上面是wikipedia中的解释, 换句话说, 线程安全 是在多线程的环境下, 线程安全能够保证多个线程同时执行时程序依旧运行正确, 而且要保证对于共享的数据,可以由多个线程存取,但是同一时刻只能有一个线程进行存取.
既然,多线程环境下必须存在资源的竞争,那么如何才能保证同一时刻只有一个线程对共享资源进行存取?
加锁, 对, 加锁可以保证存取操作的唯一性, 从而保证同一时刻只有一个线程对共享数据存取.
通常加锁也有2种不同的粒度的锁:
fine-grained(所谓的细粒度), 那么程序员需要自行地加,解锁来保证线程安全
coarse-grained(所谓的粗粒度), 那么语言层面本身维护着一个全局的锁机制,用来保证线程安全
前一种方式比较典型的是 java, Jython 等, 后一种方式比较典型的是 CPython (即Python).
前一种本文不进行讨论, 具体可参考 java 中的多线程编程部分.
至于Python中的全局锁机制,也即 GIL (Global Interpreter Lock), 下面主要进行一些讨论.
GIL
什么是 GIL ? 答案可参考wikipedia中的说明, 简单地说就是:
每一个interpreter进程,只能同时仅有一个线程来执行, 获得相关的锁, 存取相关的资源.
那么很容易就会发现,如果一个interpreter进程只能有一个线程来执行, 多线程的并发则成为不可能, 即使这几个线程之间不存在资源的竞争.
从理论上讲,我们要尽可能地使程序更加并行, 能够充分利用多核的功能, 那么Python为什么要使用 全局的 GIL 来限制这种并行呢?
这个问题,其实已经得到了很多的讨论, 不止十年, 可以参考下面的文档:
反对 GIL 的声音:
An open letter to Guido van Rossum (这个文章值得一看,下面有很多的留言也值得一看)
认为 GIL 不能去除的:
It isn't Easy to Remove the GIL (这个文章来自python作者 Guido, 他说明了什么要使用 GIL)
其它的一些讨论很容易从Google来搜索得到, 譬如: GIL at google.
那么,简单总结下双方的观点.
认为应该去除 GIL 的:
不顺应计算机的发展潮流(多核时代已经到来, 而 GIL 会很影响多核的使用)
大幅度提升多线程程序的速度
认为不应该去除 GIL 的(如果去掉,会):
写python的扩展(module)时会遇到锁的问题,程序员需要繁琐地加解锁来保证线程安全
会较大幅度地减低单线程程序的速度
后者是 Guido 最为关切的, 也是不去除 GIL 最重要的原因, 一个简单的尝试是在1999年(十年前), 最终的结果是导致单线程的程序速度下降了几乎2倍.
归根结底,其实就是多进程与多线程的选择问题, 有一段话比较有意思, 可以参考 http://www.artima.com/forums/flat.jsp?forum=106&thread=214235.
我引用如下:
I actually don't think removing the GIL is a good solution.
But I don't think threads are a good solution, either.
They're too hard to get right, and I say that after spending literally years studying threading in both C++ and Java.
Brian Goetz has taken to saying that no one can get threading right.
引自 Bruce Eckel 对 Guido 的回复. 而 Bruce Eckel 是何许人, 如果你了解 java 或者 C++, 那么应该不会不知道他.
个人的观点
那么,从我自己的角度来看(我没有太多的多线程编程经验), 先不论多线程的速度优势等,我更加喜欢多进程的是:
简单,无需要人为(或者语言级别)的加解锁. 想想 java 中的多线程编程,程序员通常会在此处出错(java程序员可以思考下)
安全, 这也是浏览器为什么开始使用多进程的一个原因
依照Python自身的哲学, 简单 是一个很重要的原则,所以, 使用 GIL 也是很好理解的.
当然你真的需要充分利用多核的速度优势,此时python可能并非你最佳的选择,请考虑别的语言吧,如 java, erlang 等.
作者链接:https://www.cnblogs.com/mindsbook/archive/2009/10/15/thread-safety-and-GIL.html
四丶线程池
# ######################## 线程####################
import time
import threading
def task(arg):
time.sleep(50)
while True:
num = input('>>>')
t = threading.Thread(target=task,args=(num,))
t.start()
######################## 线程池 ###################
import time
from concurrent.futures import ThreadPoolExecutor
def task(arg):
time.sleep(50)
pool = ThreadPoolExecutor(20)
while True:
num = input('>>>')
pool.submit(task,num)
五丶生产者消费模型
三部件:
生产者
队列:先进先出
扩展: 栈,后进先出
消费者
问:生产者,消费者模型解决了什么问题:解决了不同等待的问题
import time
import queue
import threading
q = queue.Queue() # 线程安全
def producer(id):
"""
生产者
:return:
"""
while True:
time.sleep(2)
q.put('包子')
print('厨师%s 生产了一个包子' %id )
for i in range(1,4):
t = threading.Thread(target=producer,args=(i,))
t.start()
def consumer(id):
"""
消费者
:return:
"""
while True:
time.sleep(1)
v1 = q.get()
print('顾客 %s 吃了一个包子' % id)
for i in range(1,3):
t = threading.Thread(target=consumer,args=(i,))
t.start()
六丶关于join
Python多线程与多进程中join()方法的效果是相同的。
下面仅以多线程为例:
首先需要明确几个概念:
知识点一:
当一个进程启动之后,会默认产生一个主线程,因为线程是程序执行流的最小单元,当设置多线程时,主线程会创建多个子线程,在python中,默认情况下(其实就是setDaemon(False)),主线程执行完自己的任务以后,就退出了,此时子线程会继续执行自己的任务,直到自己的任务结束,例子见下面一。
知识点二:
当我们使用setDaemon(True)方法,设置子线程为守护线程时,主线程一旦执行结束,则全部线程全部被终止执行,可能出现的情况就是,子线程的任务还没有完全执行结束,就被迫停止,例子见下面二。
知识点三:
此时join的作用就凸显出来了,join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在终止,例子见下面三。
知识点四:
join有一个timeout参数:
- 当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
- 没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。
一:Python多线程的默认情况
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.start()
print('主线程结束!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
其执行结果如下
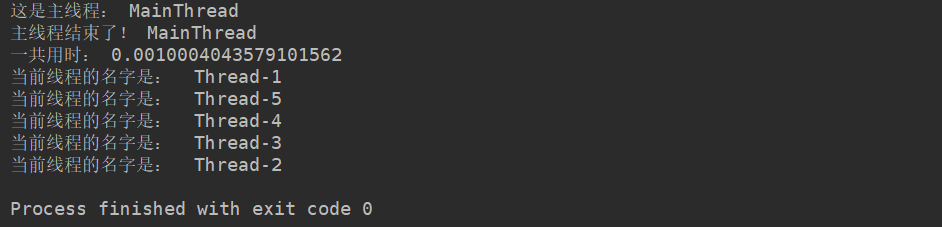
关键点:
- 我们的计时是对主线程计时,主线程结束,计时随之结束,打印出主线程的用时。
- 主线程的任务完成之后,主线程随之结束,子线程继续执行自己的任务,直到全部的子线程的任务全部结束,程序结束。
二:设置守护线程
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.setDaemon(True)
t.start()
print('主线程结束了!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
其执行结果如下,注意请确保setDaemon()在start()之前。

关键点:
- 非常明显的看到,主线程结束以后,子线程还没有来得及执行,整个程序就退出了。
三:join的作用
import threading
import time
def run():
time.sleep(2)
print('当前线程的名字是: ', threading.current_thread().name)
time.sleep(2)
if __name__ == '__main__':
start_time = time.time()
print('这是主线程:', threading.current_thread().name)
thread_list = []
for i in range(5):
t = threading.Thread(target=run)
thread_list.append(t)
for t in thread_list:
t.setDaemon(True)
t.start()
for t in thread_list:
t.join()
print('主线程结束了!' , threading.current_thread().name)
print('一共用时:', time.time()-start_time)
其执行结果如下:
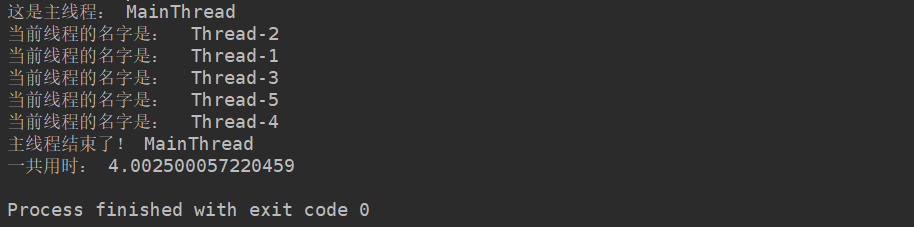
关键点:
- 可以看到,主线程一直等待全部的子线程结束之后,主线程自身才结束,程序退出。
总结:
start: 现在准备就绪,等待CPU调度
setName: 为线程设置名称
getName: 获取线程名称
setDaemon: 设置为后台线程或前台线程(默认),如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止.如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止.
join: 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
run: 线程被CPU调度后自动执行线程对象的run方法
ps:小补充
在脚本运行过程中有一个主线程,若在主线程中创建了子线程,当主线程结束时根据子线程daemon属性值的不同可能会发生下面的两种情况之一:
如果某个子线程的daemon属性为False,主线程结束时会检测该子线程是否结束,如果该子线程还在运行,则主线程会等待它完成后再退出;
如果某个子线程的daemon属性为True,主线程运行结束时不对这个子线程进行检查而直接退出,同时所有daemon值为True的子线程将随主线程一起结束,而不论是否运行完成。
属性daemon的值默认为False,如果需要修改,必须在调用start()方法启动线程之前进行设置。另外要注意的是,上面的描述并不适用于IDLE环境中的交互模式或脚本运行模式,因为在该环境中的主线程只有在退出Python IDLE时才终止。
import threading
import time
#继承Thread类,创建自定义线程类
class mythread(threading.Thread):
def __init__(self, num, threadname):
threading.Thread.__init__(self, name=threadname)
self.num = num
#重写run()方法
def run(self):
time.sleep(self.num)
print(self.num)
#创建自定义线程类对象,daemon默认为False
t1 = mythread(1, 't1')
t2 = mythread(5, 't2')
#设置线程对象t2的daemon属性为True
t2.daemon = True
print(t1.daemon)
print(t2.daemon)
#启动线程
t1.start()
t2.start()
把上面的代码存储为ThreadDaemon.py文件,在IDLE环境中运行结果如下图所示
在命令提示符环境中运行结果如下图所示。
可以看到,在命令提示符环境中执行该程序时,线程t2没有执行结束就跟随主线程一同结束了,因此并没有输出数字5。

