
TVM设备添加以及代码生成
因为要添加的设备是一种类似于GPU的加速卡,TVM中提供了对GPU编译器的各种支持,有openCl,OpenGL和CUDA等,这里我们选取比较熟悉的CUDA进行模仿生成。从总体上来看,TVM是一个多层的结构
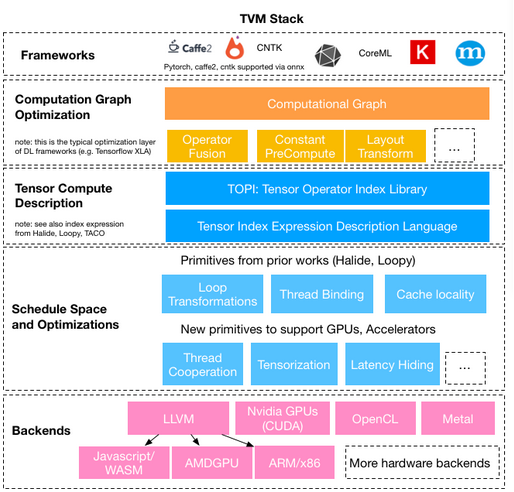
从上一个文档(TVM调试)中,基本可以发现,TVM在python这一层提供了相关的设备接口,然后使用tvm.build真正的编译,然后调用get_source函数来获得想要的源码(或者IR,比如llvm选项提供的是LLVM的IR,或者PTX选项提供的就是NVPTX类型的IR)。
因此,添加新设备(device)推测的步骤就是:
- 补全相应的python接口
- 找到python和C交互的接口
- 正确维护中间代码的IR pass变换中新设备引入的特性
- 代码生成对新设备和新特性的支持
- 添加编译选项支持(非必须)
以下就分别就这4个步骤进行介绍。
1. 补全相应的python接口
我之前给的那个测试代码中使用的是字符串解析的方式,但是从其他tutorial中发现,还存在一种tvm.target.cuda()的设备建立方式,这个很明显比字符串解析相对找起来容易(字符串最终对应的也是这种方式)。按照这种方式找到了tvm/python/tvm/target.py文件中,这个类中定义了现在能支持的target。添加新的target叫做dpu

def dpu(model='unknown', options=None): """Returns a dpu target. Parameters ---------- model: str The model of dpu device options : str or list of str Additional options """
opts = _merge_opts(['-model=%s' % model], options) return _api_internal._TargetCreate("dpu", *opts)
每个设备都包括硬件自身的上下文信息和硬件上运行软件运行时也就是runtime,在TVM中相关的软件运行时信息在tvm/python/tvm/_ffi/runtime_ctypes.py文件中,添加对dpu的支持
在class TVMContext的两个掩码MASK2STR和STR2MASK中分别添加:
13: 'dpu',
和
'dpu':13,
2. 找到python和C交互的接口
回到刚才的target.py文件中来,核心的代码只有两句
opts = _merge_opts(['-model=%s' % model], options)
return _api_internal._TargetCreate("dpu", *opts)
第一句是将model和相关的options组合在一起,就是个字符串相关的拼接,没有特别多需要关注的内容,而后边有一个_api_internel._TargetCreate的函数调用,从名字上看起来非常的重要,是创建真正的Target的,但是,我们在tvm/python文件中无论如何都找不到该函数的实现

前边已经提到过TVM中使用的是python提供接口,真正的实现都是在C++中,因此,这里我们猜测是调用了C语言的实现。下面列一下TVM相关的文件夹

3rdparty是很多第三方库的实现
build 目录是我们建立的编译后的.so文件所在的位置
docs 是相关的文档
include C++代码的include的主目录
jvm 是java相关的文件夹
nnvm 是中间的nnvm算子所在的目录
python 是python文件所在的目录,所有与python相关的都在该目录中
rust apps conda docker golang web verilog都是特有领域中的内容,对一般项目没有影响
tests 是测试文件,中间包含了作者写的很多测试,是学习TVM的另一个手段
Tutorial是官网上相关的历程
vta 是TVM的软件栈
cmake包含了所有的编译配置文件,和CmakeLists.txt共同工作
src 是全部的C++代码
topi 是Tensor Operator Index Library,后续进行详细介绍
在src目录下搜索_TargetCreate,得到src/codegen/build_module.cc:116中有相关的内容
TVM_REGISTER_API("_TargetCreate") .set_body([](TVMArgs args, TVMRetValue* ret) { std::string target_name = args[0]; std::vector<std::string> options; for (int i = 1; i < args.num_args; ++i) { std::string arg = args[i]; options.push_back(arg); } *ret = CreateTarget(target_name, options); });
这段代码的意思就是通过一种TVM_REGISTER_API的注册机制,注册_TargetCreate函数,真正的函数体是.set_body内执行的,实际上C++中tvm::CreateTarget函数。TVM_REGISTER_API的注册机制在TVM项目中非常普遍,其实现在项目中也有,不是我们主要的研究内容,不需要改,所以不另行赘述。
3. 正确维护中间代码的IR pass变换中新设备引入的特性
上边提到,在src/codegen/build_module.cc文件中的tvm::CreateTarget函数中添加对dpu的支持
else if (target_name == "dpu") { t->device_type = kDLDPU; }
这里边的kDLDPU是一个DLDeviceType类型值,实现是在3rdparty/dlpack/include/dlpack/dlpack.h中添加的
kDLDPU =13,
同时在include/tvm/runtime/device_api.h:200补充对kDLDPU的支持
case kDLDPU: return "dpu";
Target部分添加完了,还需要补充运行时的内容。
运行时的内容在src/runtime/目录下,需要在module.cc中添加对dpu 的支持。
在RuntimeEnabled函数中,添加
else if (target == "dpu") { f_name = "device_api.dpu"; }
这只是添加了一个名字的支持,还需要新建一个dpu目录,里边存放DPUModuleNode、DPUWorkspace等支持,测试代码的getSource函数的真正实现也存放在这里边,主要模仿CUDA和openCl的实现进行。目前存放有dpu_common.h、dpu_device_api.cc、dpu_module.cc、dpu_module.h四个文件,大概1K行代码,实现逻辑也不是很复杂。
4. 代码生成对新设备和新特性的支持
上边准备好了module部分,也就是运行时,但是我们这里第一步想要实现的是一个能在dpu编译器上运行的C代码。因此需要在codegen部分添加对dpu这个设备的支持。
codegen是在tvm.build(Python)中形成的,在其对应的C++实现上是codegen/build_module.cc文件,之前添加了名字的支持,现在还需要添加这个真正的Target调用点
Target DPU(const std::vector<std::string>& options ) { return CreateTarget("dpu", options); }
最主要的codegen对DPU的支持是新建CodeGenDPU类,这个类的实现在该目录的codegen_dpu.h和codegen_dpu.cc文件内。特别说一下这个部分,其他的函数可以不实现,有两个函数必须实现
runtime::Module BuildDPU(Array<LoweredFunc> funcs) { using tvm::runtime::Registry; bool output_ssa = false; CodeGenDPU cg; cg.Init(output_ssa); for (LoweredFunc f : funcs) { cg.AddFunction(f); } std::string code = cg.Finish(); if (const auto* f = Registry::Get("tvm_callback_dpu_postproc")) { code = (*f)(code).operator std::string(); } return DPUModuleCreate(code, "dpu", ExtractFuncInfo(funcs), code); } TVM_REGISTER_API("codegen.build_dpu") .set_body([](TVMArgs args, TVMRetValue* rv) { *rv = BuildDPU(args[0]); });
5. 添加编译选项支持
上边可以说是完成了从设备添加到代码生成的部分,但是如果只有上边的话,新添加的设备一直无法运行。但如果仅是对一个设备进行修改的话,这部分并没有必要。后来排查发现是部分代码未编译进去导致的。所以开始修改cmake配置。
在上一个TVM调试文档中提到,编译需要打开LLVM和CUDA选项,这里新添加了dpu的设备,需要增加一个新的编译选项,在cmake/config.cmake中添加
1 2 | #Build DPUset(USE_DPU ON) |
cmake目录下还存在着modules和util目录,modules是指定了相关设备的目录等配置,util文件夹下的内容用来寻找比如CUDA等的配置。暂时我们只需要modules下添加DPU.cmake
这部分的配置代码相对比较简单,就是指定runtime对应的目录
1 2 3 4 5 6 7 8 9 10 | # DPU Moduleif(USE_DPU) message(STATUS "Build with DPU support") file(GLOB RUNTIME_DPU_SRCS src/runtime/dpu/*.cc) list(APPEND RUNTIME_SRCS ${RUNTIME_DPU_SRCS})else() message(STATUS "NOT BUILD DPU SUPPORT")endif(USE_DPU) |
这里修改完config.cmake,需要重新拷贝到build目录下,以使下次配置生效。我在上边也提到了,编译tvm时是cmake目录下的config.cmake和CMakeLists.txt共同工作生效。在CMakeLists.txt中添加
1 2 | tvm_option(USE_DPU "Build with DPU" ON)include(cmake/modules/DPU.cmake) |
然后在build目录下,运行cmake命令,重新编译生效。
1 2 | cmake -DCMAKE_BUILD_TYPE=Debug ../make |
这里不加-DCMAKE_BUILD_TYPE=Debug的话,C++代码无法进行调试。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律