互斥锁与现成的诸多方法
互斥锁与现成的诸多方法
互斥锁
-
互斥锁的本质
互斥锁其实就是将并发变成串行,但是为了数据的安全就牺牲了程序的执行效率,互持锁只应该出现在多个程序操作数据的地方,其他地方都尽量不加,否则会让程序变得非常慢,我们以后自己加锁的情况很少,所以只需要直到锁的功能即可。
-
行锁、表锁、乐观锁、悲观锁
1.表级锁定(table-level)
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大打折扣。
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。2.行级锁定(row-level)
行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎。3.乐观锁
乐观锁不是数据库自带的,需要我们自己去实现。乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。
通常实现是这样的:在表中的数据进行操作时(更新),先给数据表加一个版本(version)字段,每操作一次,将那条记录的版本号加1。也就是先查询出那条记录,获取出version字段,如果要对那条记录进行操作(更新),则先判断此刻version的值是否与刚刚查询出来时的version的值相等,如果相等,则说明这段期间,没有其他程序对其进行操作,则可以执行更新,将version字段的值加1;如果更新时发现此刻的version值与刚刚获取出来的version的值不相等,则说明这段期间已经有其他程序对其进行操作了,则不进行更新操作。
4.悲观锁
与乐观锁相对应的就是悲观锁了。悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作,这点跟java中的synchronized很相似,所以悲观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我们直接调用数据库的相关语句就可以了。 -
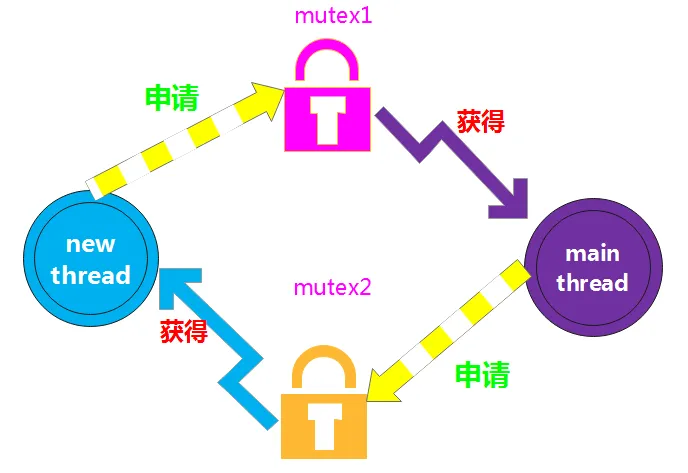
互斥锁的使用方法
from multiprocessing import Process,Lock import time import json import random def search(name): with open(r'data.json','r',encoding='utf-8')as f: data = json.load(f) print('%s正在查票,当前余票为:%s'% (name,data.get('ticket_num'))) def buy(name): with open(r'data.json','r',encoding='utf-8')as f: data = json.load(f) time.sleep(random.randint(1,5)) if data.get('ticket_num') > 0: data['ticket_num'] -= 1 with open(r'data.json','w',encoding='utf-8')as f: json.dump(data,f) print('%s成功购买前往理想乡的车票'% name) else: print('%s很遗憾买不到票,今晚都睡不着了'% name) def run(name,mutex): search(name) mutex.acquire() # 枪锁 buy(name) mutex.release() # 施放锁 if __name__ == '__main__': mutex = Lock() l1 = ['joseph','Alice','Trump','Jason'] for i in l1: p = Process(target=run,args=('用户名%s'% i,mutex)) p.start()
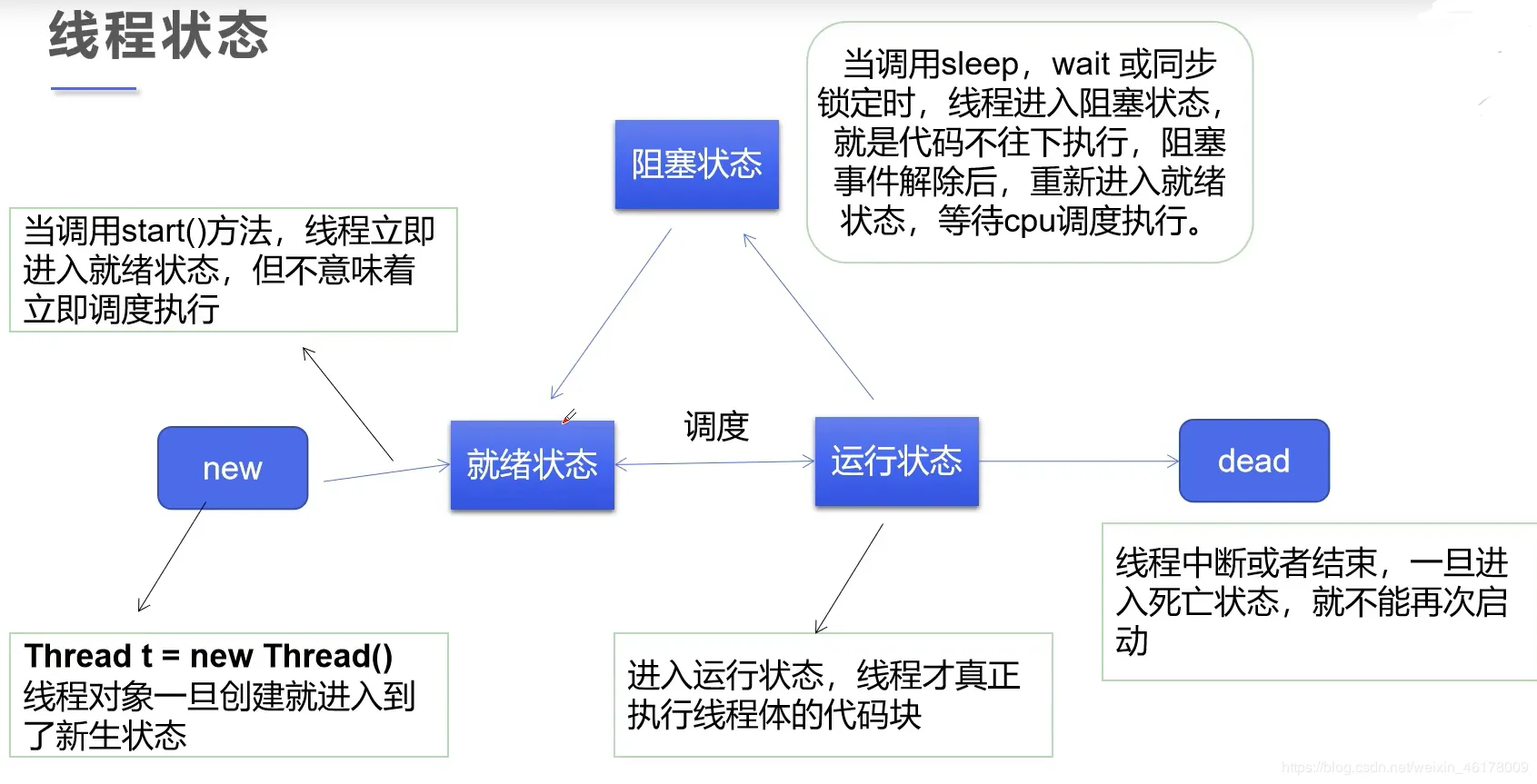
线程理论
-
进程
进程是资源单位,相当于车间,负责给内部提供相应的资源它本身就拿到了全部的资源
-
线程
线程是执行单位,相当于车间中的流水线,从进程中拿取数据,然后进行执行他的数据全是从进程中拿取
-
进程的形式
一个进程中至少拥有一个线程,如果没有线程那么此进程就没有存在的必要性
多进程其实就是申请多个内存空间需要拿到全部的代码,耗费的资源大,线程都是从进程中拿去数据
多线程,多线程本质上都是从进程中拿取自己所需要的代码即可不需要拿的过多,所以多线程占用的资源较少
在同一个进程下的多个线程之间是可以互相资源利用的
创建线程的两种方式
方式一:
from threading import Thread
import time
def task(name):
print(f'{name}正在执行')
time.sleep(3)
print(f'{name}执行结束')
t = Thread(target=task,args=('joseph',))
t.start() # 两个都可以执行,但是最好写上下方的启动代码,以增加兼容性和规范性
print('主线程')
if __name__ == '__main__':
t = Thread(target=task, args=('joseph',))
t.start()
print('主线程')
"""
开设线程不需要完整的拷贝代码,所以无论什么系统都不会出现反复草早的情况,也不需要像启动进程时一样使用启动脚本,但是为了兼容性和规范性我们最好也写上启动脚本
"""
方式二:
from threading import Thread
import time
class MyThred(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name}正在执行')
time.sleep(3)
print(f'{self.name}执行结束')
obj = MyThred('jsoeph')
obj.start()
print('主线程')
多线程实现TCP服务端并发
- 与进程相比多线程用的资源更少,更加方便使用,还可以提高效率
join方法
1.和进程一样都是需要等到子线程结束那么这个主线程才会结束
from threading import Thread
import time
def task(name):
print(f'{name}正在执行')
time.sleep(3)
print(f'{name}执行结束')
if __name__ == '__main__':
t = Thread(target=task, args=('joseph',))
t.start()
t.join()
print('主线程')
同一个进程下线程间数据共享
1.线程和进程不同,每个进程都是独立的个体,全部都拥有全部的代码,所以之间交互比较困难,但是线程之间的数据都是可以互相调用的,主线程也可以使用子线程更改的数据
from threading import Thread
count = 999
def func():
global count
count = 666
t = Thread(target=func)
t.start()
t.join()
print(count) # 666
线程对象相关方法
1.进程号
在同一个进程下的多个线程都拥有同一个进程的进程号
2.线程名
from threading import Thread,current_thread
from threading import Thread
count = 999
def func():
global count
count = 666
print(current_thread().name) # Thread-1
t = Thread(target=func)
t.start()
t.join()
print(current_thread().name) # MainThread
print(count) # 666
3.进程下的线程数
active_count()
守护线程
1.守护线程和守护进程一样都是只要被守护线程结束,那么就会立即结束,进程下所有的非守护线程结束,那么主线程(主进程才会真正结束)
from threading import Thread
import time
def task():
print('子进程运行task函数')
time.sleep(3)
print('子进程运行task函数结束')
t = Thread(target=task)
t.daemon = True
t.start()
print('主进程')
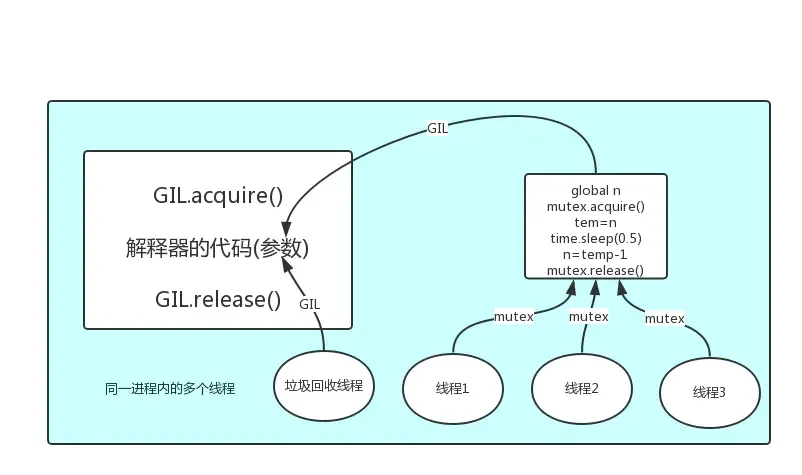
GIL全局解释器锁
储备知识
1.python解释器也是由编程语言写出来的
Cpython 用C写出来的
Jpython 用Java写出来的
Pypython 用python写出来的
ps:最常用的就是Cpython(默认)
# 官方文档对GIL的解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
"""
1.GIL的研究是Cpython解释器的特点 不是python语言的特点
2.GIL本质也是一把互斥锁
3.GIL的存在使得同一个进程下的多个线程无法同时执行(关键)
言外之意:单进程下的多线程无法利用多核优势 效率低!!!
4.GIL的存在主要是因为cpython解释器中垃圾回收机制不是线程安全的
"""
1.误解:python的多线程就是垃圾 利用不到多核优势
python的多线程确实无法使用多核优势 但是在IO密集型的任务下是有用的
2.误解:既然有GIL 那么以后我们写代码都不需要加互斥锁
不对 GIL只确保解释器层面数据不会错乱(垃圾回收机制)
针对程序中自己的数据应该自己加锁处理
3.所有的解释型编程语言都没办法做到同一个进程下多个线程同时执行
ps:我们平时在写代码的时候 不需要考虑GIL 只在学习和面试阶段才考虑!!!