ExpressionGenerator - 基于双向二叉树数据结构的算术表达式生成器
一. 项目基本信息
项目仓库:Github
二. PSP2.1表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 1280 | 1740 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 55 |
| · Design Spec | · 生成设计文档 | 40 | 41 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 31 |
| · Design | · 具体设计 | 40 | 66 |
| · Coding | · 具体编码 | 1000 | 1422 |
| · Code Review | · 代码复审 | 40 | 41 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 64 |
| Reporting | 报告 | 70 | 103 |
| · Test Report | · 测试报告 | 20 | 24 |
| · Size Measurement | · 计算工作量 | 20 | 21 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 58 |
| 合计 | 1370 | 1868 |
三. 设计实现过程及代码说明
1. 分析及设计
一个算术表达式可以由多个子表达式组成,一个子表达式运算完的结果又可以作为操作数参与另一个子表达式的运算,这样的结构让人很容易想到二叉树,而事实上通过谷歌搜索关于表达式方面的编程信息时,更多被提及的是Expression Tree , 而Expression Tree 的经典实现就是使用二叉树(参见Wikipedia )

二叉表达式树的特点有:
-
每个叶子结点都用来存储数据,每个非叶子结点都用来存储运算符
-
每个操作符结点的左右子结点均不为空
-
通过先序、中序和后序遍历后,便可得到表达式的前缀、中缀和后缀书写形式
利用这种特点并结合项目需求,我们可以大概将主要任务概括为
-
构建表达式
-
通过指定的操作符个数随机构建二叉树
-
递归遍历二叉树,如如果遍历到的结点是操作符结点且缺少孩子结点,则在空缺的位置添加数据随机的数字结点
-
-
中序遍历表达式
-
递归获取每个操作符结点对应的子表达式,通过结点关系和运算符优先级添加括号及进行其他处理
-
计算子表达式
-
-
处理遍历结果
-
将表达式及运算结果写入文件
-
通过人机交互获取用户输入的答案,将之与正确答案进行比对
-
2. 具体实现
( 1 ) 数据结构说明
二叉表达式树及其结点的类签名如下


( 2 ) 构建二叉表达式树
在构造方法中随机生成一个操作符作为根结点的数据,指定操作符的个数为下面插入操作符结点做准备,指定range 限制书中数据结点的数据范围, 然后调用初始化方法init() ;而初始化方法中主要是随机插入operatorCount 个操作符结点以及根据这些操作符结点的位置插入数据结点。


( 3 ) 递归插入运算符结点
随机决定插入操作符的位置是当前处理结点的左或者右结点,通过操作符类型的随机性及操作符位置的随机性减少构造出来表达式出现重复的概率


以含有三个操作符的二叉表达式树为例,假如随机产生的操作符依次为+ 、÷、-,则进行完当前操作后,可能出现的树形结构有:
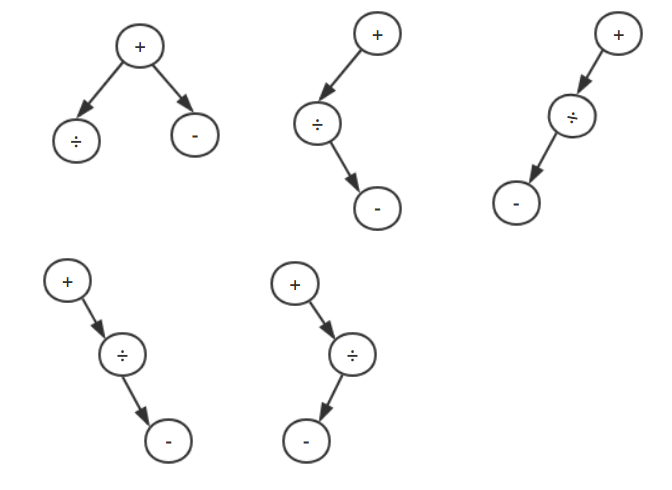

( 4 ) 插入数据结点
逻辑比较简单,看注释即可


( 5 ) 中序递归遍历二叉树
需要考虑的地方:
-
如果当前处理结点是数字结点,直接返回其数据
-
如果是操作数结点,获取其左右子树的表达式并与中间的符号连接成新的子表达式
-
如果当前处理结点是减号操作符结点,并且子树的运算结果大于右子树的运算结果,将运算结果取绝对值,同时将左右子表达式的位置交换,而对于原二叉树的数据结构不作处理
-
如果当前处理结点是操作符结点,通过
parent引用获取当前处理结点的父结点,判断当前处理结点的的优先级是否低于父结点操作符的优先级,若是,在子表达式加上左右括号


每个结点的遍历结果都存放到一个TraverseResult 对象中,其中包含了该结点对应的子表达式(形如1、1 + 2、(1 + 2) x3 )及其运算结果,想获取表达式树的完整表达式,只需调用该树对象的getResult()方法即可


假设随机产生的数字序列为7、8、5、4 ,则在上述构造的树形基础上插入数字后得到的完整表达式树结构及其中序遍历的结果如下图所示:

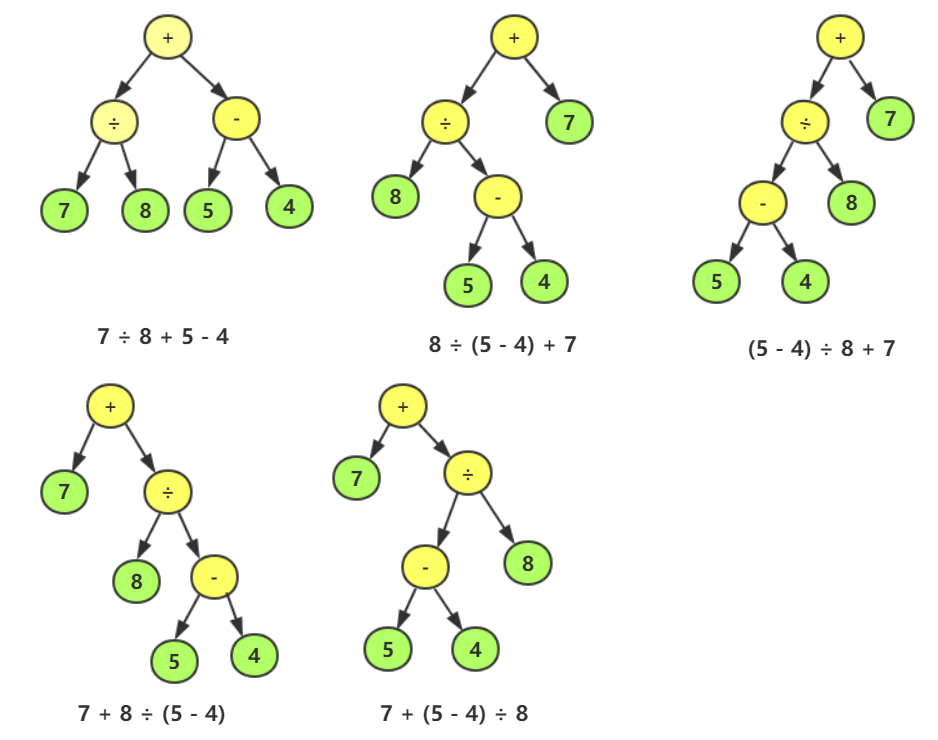
( 6 ) 运算
数据结点的数据类型全为分数


通过随机函数产生分子和分母,然后构造Fraction 对象,在构造中当内部属性赋值完之后调用reduce 方法进行化简;重写toString() 方法,主要用于分数的打印展示,处理带分数和整数的情况。


使用操作符枚举类定义操作符号与计算器的对应规则


具体的运算逻辑封装在Calculator 类中,只需通过Symbol 枚举类获取到当前操作符对应的计算器然后调用calculate方法即可。

( 7 ) 程序入口
主程序入口在AppEntry类 , 主要介绍写入题目和答案及比对答案的代码
写入题目和答案 :随机产生运算符个数(最大为3个),结合指定的数据最大取值范围及题目数量构造若干表达式树,获取这些表达式树的中序遍历结果塞进集合results, 将results丢给writeList函数处理写入文件逻辑
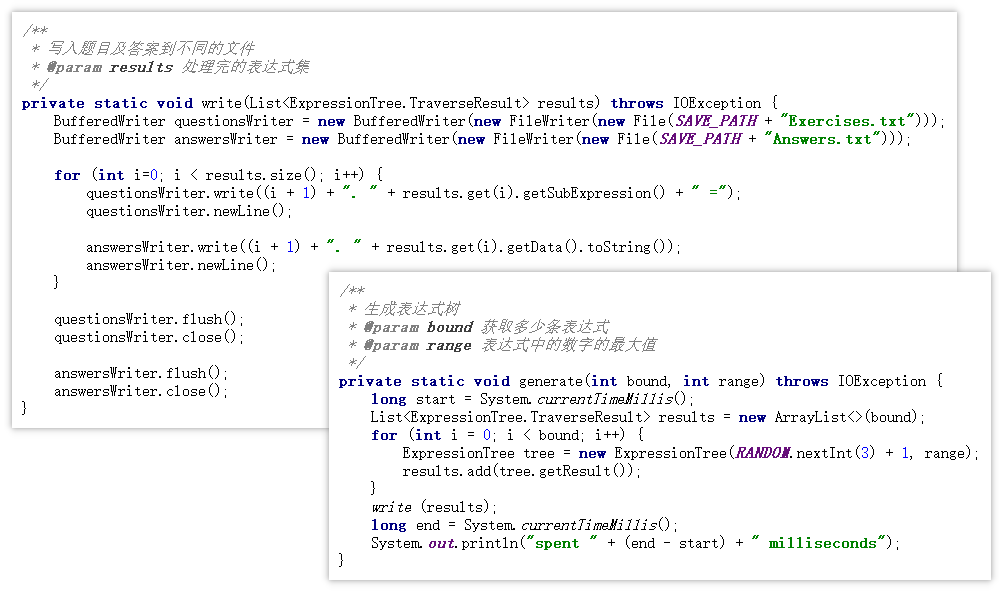

比对答案 :同时打开正确答案文件和用户提交的答案文件,逐行比对,用集合记录正误的题目标号,然后对集合中的数据进行格式输出处理,将得到的正误情况写入文件。


四. 测试运行
1. 功能测试
下面是, 模拟用户解答前20道题目并比对答案的例子。
文件说明:
-
exercies.txt : 题目文件
-
answer.txt : 正确答案文件
-
submit.txt :用户提交的答案文件
-
Grade.txt :对答案结果文件

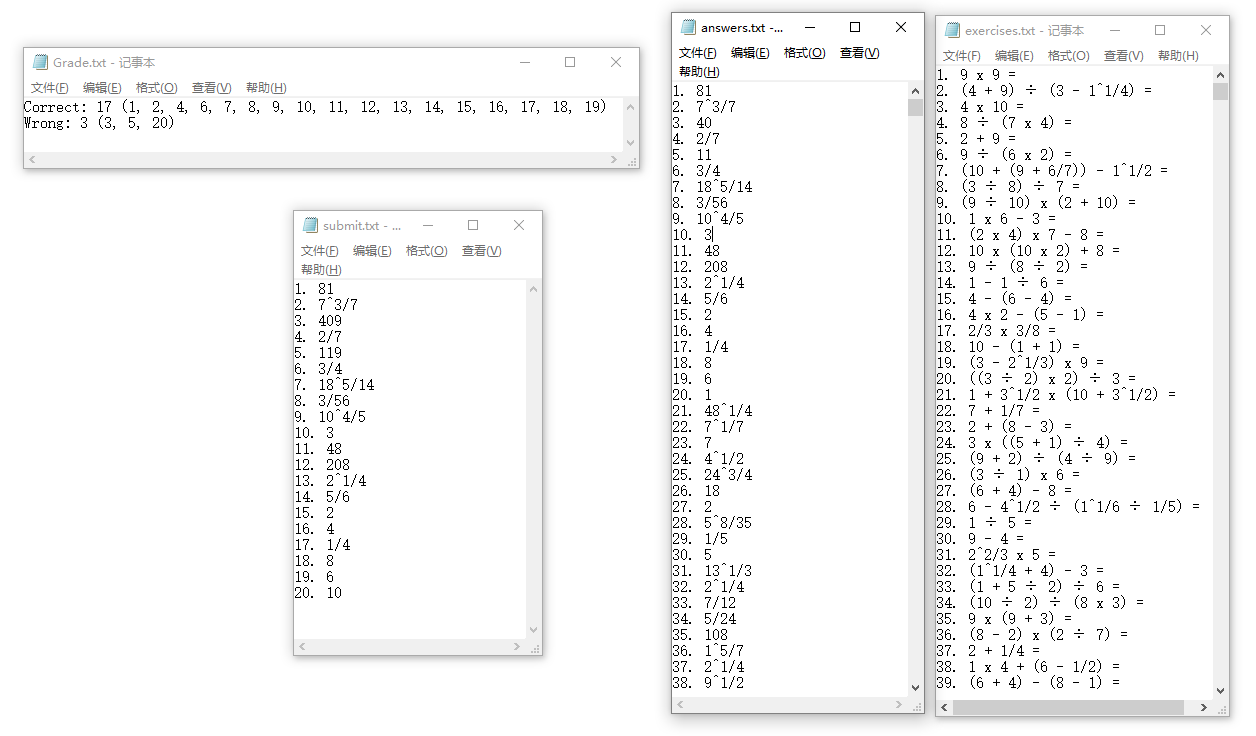
测试用例在项目的test-result文件夹下的first子文件夹中
2. 代码覆盖率
使用maven插件对测试文件进行代码覆盖率统计,结果如下所示,我们认为有些地方(比如要将入口程序类实例化)并没有必要写进测试文件,所以统计达到的覆盖会比实际需要用到的样例测试低。


五. 效能分析
在i5-3230M处理器,win10 64位操作系统,12GB主存的机器上,简单统计生成10、100、1000、10000、100000道操作符数为3、操作数最大取值为100的题目并进行遍历的所用的时间
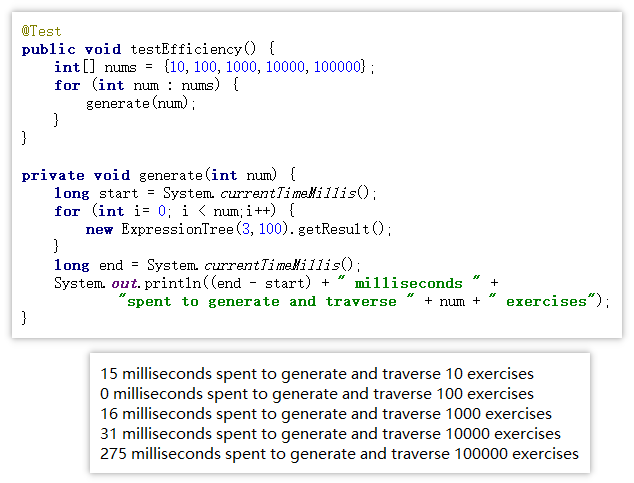

影响效能的因素:
递归
本项目中很多二叉树的操作使用了递归,而在递归的时候会进行很深层次的调用函数,所以需要调用很多函数递归(即为调用自身),需要建立许多的访问链和控制链,占用大量内存。而且调用时传递参数,申请空间,返回时恢复现场,都有时间的开销
IO读写
写入题目和答案等文件、比对答案中的文件读写操作会增加程序执行时间
六. 项目小结
在本次结对编程中,我跟张灏泓同学一起探讨分析项目需求,设计具体的实现流程,然后我负责编码,张灏泓在旁观察协助。在编码实现的过程中我们在分数化简、分数运算、表达式添加括号等地方的实现细节上遇到了问题,经过我们很多次的讨论和测试后最终将问题解决,稍微总结在结对编程中收获:
-
结对编程的过程是一个互相学习的过程,无论是项目分析和设计还是具体的编码,都是一个相互学习对方的技能和思想,提升自己水平的机会。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号