深度学习与医学图像处理 案例学习2——CNN肺炎检测(CXR图像)
文章来源:https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia/notebooks
什么是肺炎?
肺炎是肺部的一种炎症状态,主要影响小肺泡。典型的症状包括干咳、胸痛、发热和呼吸困难。病情的严重程度是可变的。肺炎通常由病毒或细菌感染引起,很少由其他微生物、某些药物或疾病(如自身免疫性疾病)引起。危险因素包括囊性纤维化、慢性阻塞性肺疾病(COPD)、哮喘、糖尿病、心力衰竭、吸烟史、咳嗽能力差(如中风后)和免疫系统弱。诊断通常是基于症状和身体检查。胸部x光检查、血液检查和痰液培养可以帮助确诊。该病可根据获得性进行分类,如社区或医院获得性肺炎或卫生保健相关肺炎。
数据集中共有训练、验证、测试三个文件夹,每个文件夹又包含正常与肺炎两个子文件夹,图片格式为jpeq。
#导入包
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import keras from keras.models import Sequential from keras.layers import Dense, Conv2D , MaxPool2D , Flatten , Dropout , BatchNormalization from keras.preprocessing.image import ImageDataGenerator from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report,confusion_matrix from keras.callbacks import ReduceLROnPlateau import cv2 import os
#查看样本基本情况
PATH='/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/' print('number of normal in training set:',len(os.listdir(PATH+'train/'+'NORMAL'))) print('number of pneumonia in training set:',len(os.listdir(PATH+'train/'+'PNEUMONIA'))) print('number of normal in validation set:',len(os.listdir(PATH+'val/'+'NORMAL'))) print('number of pneumonia in validation set:',len(os.listdir(PATH+'val/'+'PNEUMONIA'))) print('number of normal in test set:',len(os.listdir(PATH+'test/'+'NORMAL'))) print('number of pneumonia in test set:',len(os.listdir(PATH+'test/'+'PNEUMONIA')))
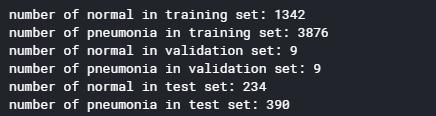
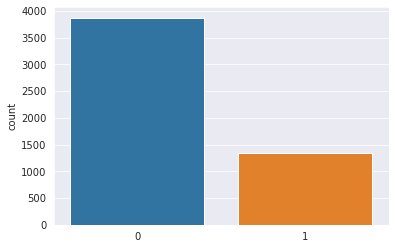
样本不均衡,训练集中肺炎约为正常的三倍,验证集数据数量过小,只有9个。
#数据读取
labels=['PNEUMONIA','NORMAL'] img_size=150 def get_training_data(data_dir): x_data=[] y_data=[] for label in labels: path=os.path.join(data_dir,label) class_num=labels.index(label) for img in os.listdir(path): try: img_arr=cv2.imread(os.path.join(path,img),cv2.IMREAD_GRAYSCALE) #加载灰度图像 resized_arr=cv2.resize(img_arr,(img_size,img_size)) x_data.append(resized_arr) #n,150,150 y_data.append(class_num) #n except Exception as e: print(e) return np.array(x_data),np.array(y_data)
x_train,y_train = get_training_data('/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/train')
x_test,y_test = get_training_data('/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/test')
x_val,y_val = get_training_data('/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/val')
#显示类别数量对比
sns.set_style('darkgrid')
sns.countplot(y_train)
#显示图像
plt.figure(figsize = (5,5)) plt.imshow(x_train[0], cmap='gray') plt.title(labels[y_train[0]]) plt.figure(figsize = (5,5)) plt.imshow(x_train[-1], cmap='gray') plt.title(labels[y_train[-1]])

#归一化,增加维度准备喂入网络
x_train = np.array(x_train) / 255 x_val = np.array(x_val) / 255 x_test = np.array(x_test) / 255 x_train = x_train.reshape(-1, img_size, img_size, 1) x_val = x_val.reshape(-1, img_size, img_size, 1) x_test = x_test.reshape(-1, img_size, img_size, 1)
#数据增强器
datagen = ImageDataGenerator( featurewise_center=False, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=False, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range = 30, # randomly rotate images in the range (degrees, 0 to 180) zoom_range = 0.2, # Randomly zoom image width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1, # randomly shift images vertically (fraction of total height) horizontal_flip = True, # randomly flip images vertical_flip=False) # randomly flip images datagen.fit(x_train)
#卷积神经网络CNN
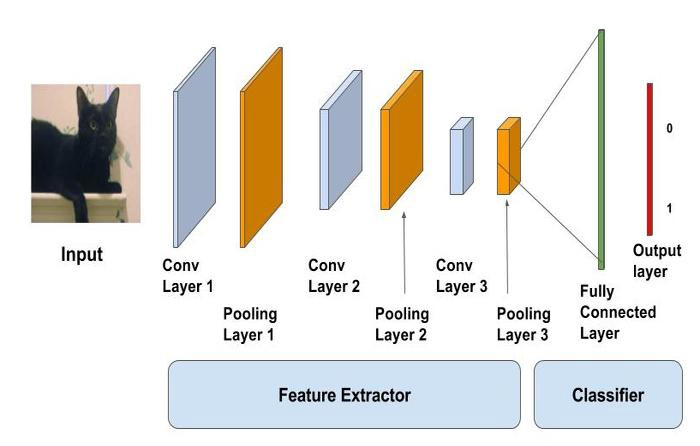
model = Sequential() model.add(Conv2D(32 , (3,3) , strides = 1 , padding = 'same' , activation = 'relu' , input_shape = (150,150,1))) #150,150,32 model.add(BatchNormalization()) #150,150,32 model.add(MaxPool2D((2,2) , strides = 2 , padding = 'same')) #75,75,32 model.add(Conv2D(64 , (3,3) , strides = 1 , padding = 'same' , activation = 'relu')) #75,75,64 model.add(Dropout(0.1)) #75,75,64 model.add(BatchNormalization()) #75,75,64 model.add(MaxPool2D((2,2) , strides = 2 , padding = 'same')) #38,38,64 model.add(Conv2D(64 , (3,3) , strides = 1 , padding = 'same' , activation = 'relu')) #38,38,64 model.add(BatchNormalization()) #38,38,64 model.add(MaxPool2D((2,2) , strides = 2 , padding = 'same')) #19,19,64 model.add(Conv2D(128 , (3,3) , strides = 1 , padding = 'same' , activation = 'relu')) #19,19,128 model.add(Dropout(0.2)) #19,19,128 model.add(BatchNormalization()) #19,19,128 model.add(MaxPool2D((2,2) , strides = 2 , padding = 'same')) #10,10,128 model.add(Conv2D(256 , (3,3) , strides = 1 , padding = 'same' , activation = 'relu')) #10,10,256 model.add(Dropout(0.2)) #10,10,256 model.add(BatchNormalization()) #10,10,256 model.add(MaxPool2D((2,2) , strides = 2 , padding = 'same')) #5,5,256 model.add(Flatten()) #5*5*256=6400 model.add(Dense(units = 128 , activation = 'relu')) #128 model.add(Dropout(0.2)) #128 model.add(Dense(units = 1 , activation = 'sigmoid')) #1 model.compile(optimizer = "rmsprop" , loss = 'binary_crossentropy' , metrics = ['accuracy']) model.summary()

#智能学习率函数
learning_rate_reduction = ReduceLROnPlateau(monitor='val_accuracy', patience = 2, verbose=1,factor=0.3, min_lr=0.000001)
#训练
history = model.fit(datagen.flow(x_train,y_train, batch_size = 32) ,epochs = 12 , validation_data = datagen.flow(x_val, y_val) ,callbacks = [learning_rate_reduction])
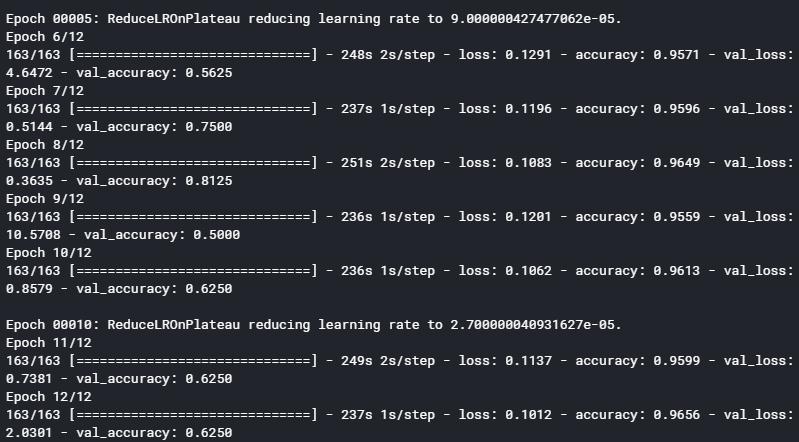
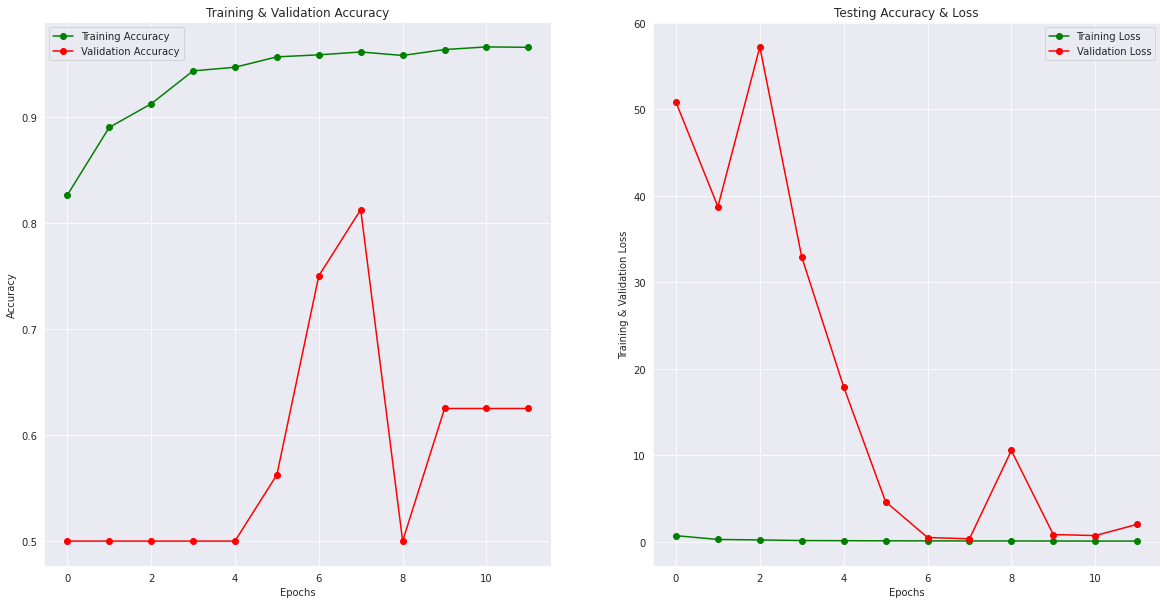
没有GPU花费了将近50分钟,训练集上的结果逐渐优化,验证集上结果一般。
epochs = [i for i in range(12)] fig , ax = plt.subplots(1,2) train_acc = history.history['accuracy'] train_loss = history.history['loss'] val_acc = history.history['val_accuracy'] val_loss = history.history['val_loss'] fig.set_size_inches(20,10) ax[0].plot(epochs , train_acc , 'go-' , label = 'Training Accuracy') ax[0].plot(epochs , val_acc , 'ro-' , label = 'Validation Accuracy') ax[0].set_title('Training & Validation Accuracy') ax[0].legend() ax[0].set_xlabel("Epochs") ax[0].set_ylabel("Accuracy") ax[1].plot(epochs , train_loss , 'g-o' , label = 'Training Loss') ax[1].plot(epochs , val_loss , 'r-o' , label = 'Validation Loss') ax[1].set_title('Testing Accuracy & Loss') ax[1].legend() ax[1].set_xlabel("Epochs") ax[1].set_ylabel("Training & Validation Loss") plt.show()
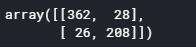
#测试集结果
predictions = model.predict_classes(x_test) predictions = predictions.reshape(1,-1)[0] cm = confusion_matrix(y_test,predictions) cm
#sklearn.metrics.confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None)

#显示预测正确图像
correct = np.nonzero(predictions == y_test)[0] i = 0 for c in correct[:6]: plt.subplot(3,2,i+1) plt.xticks([]) plt.yticks([]) plt.imshow(x_test[c].reshape(150,150), cmap="gray", interpolation='none') plt.title("Predicted {},Actual {}".format(predictions[c], y_test[c])) i += 1
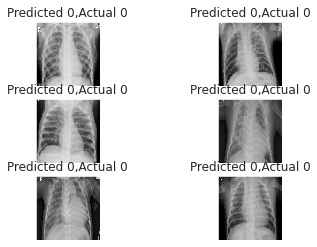
#显示错误预测图像
incorrect = np.nonzero(predictions != y_test)[0] i = 0 for c in incorrect[:6]: plt.subplot(3,2,i+1) plt.xticks([]) plt.yticks([]) plt.imshow(x_test[c].reshape(150,150), cmap="gray", interpolation='none') plt.title("Predicted {},Actual {}".format(predictions[c], y_test[c])) i += 1
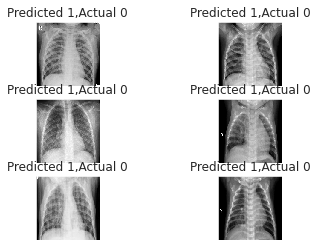
#保存模型
model.save('model.h5')
欢迎讨论!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号