

寒假学习23——了解特斯拉自动驾驶
来源于 Tesla AI Day
特斯拉算法的核心任务就是如何理解我们所看到的一切呢?也就是说,不使用高端的设备,比如激光雷达,仅仅使用摄像头就能够将任务做得很好。Tesla使用环绕型的8个摄像头获得输入。
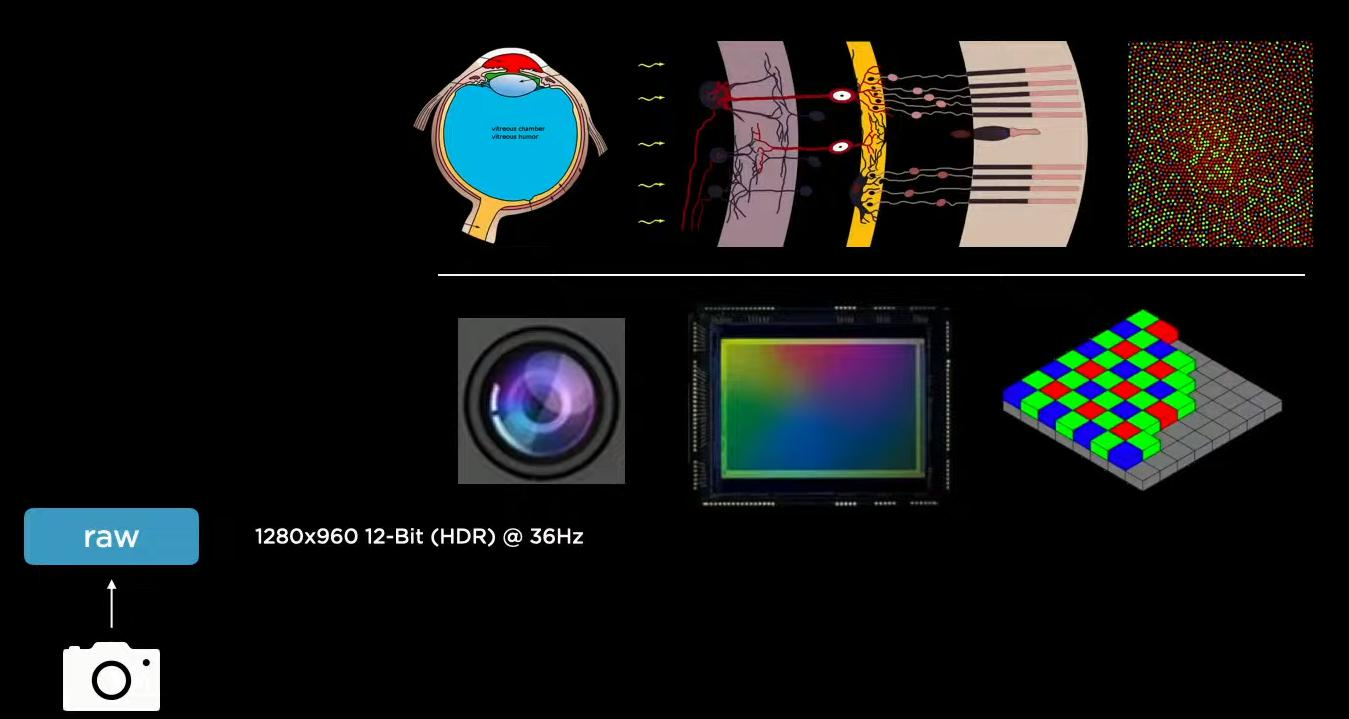
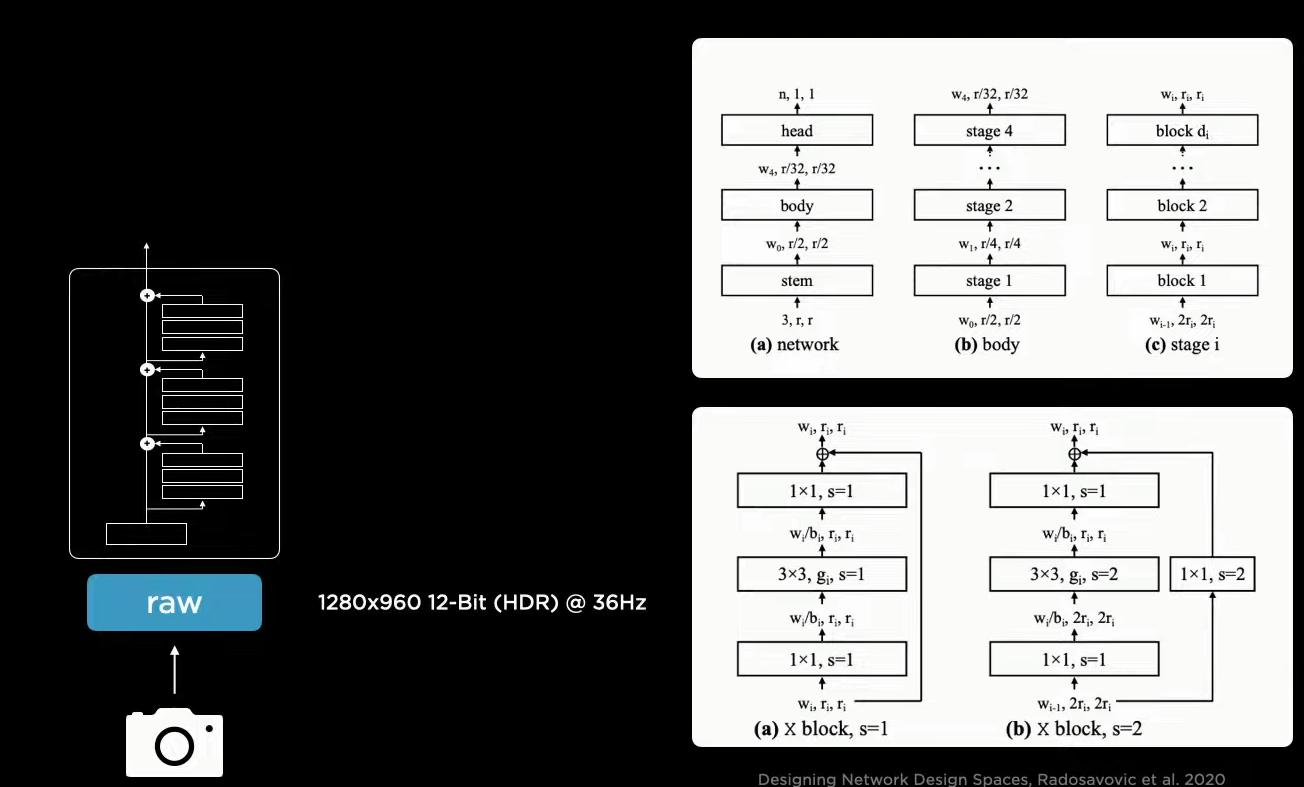
第一步是特征提取模块Backbone,无论什么任务都离不开特征提取,8个摄像头获取的图片数据均经过Backbone进行特征提取.。
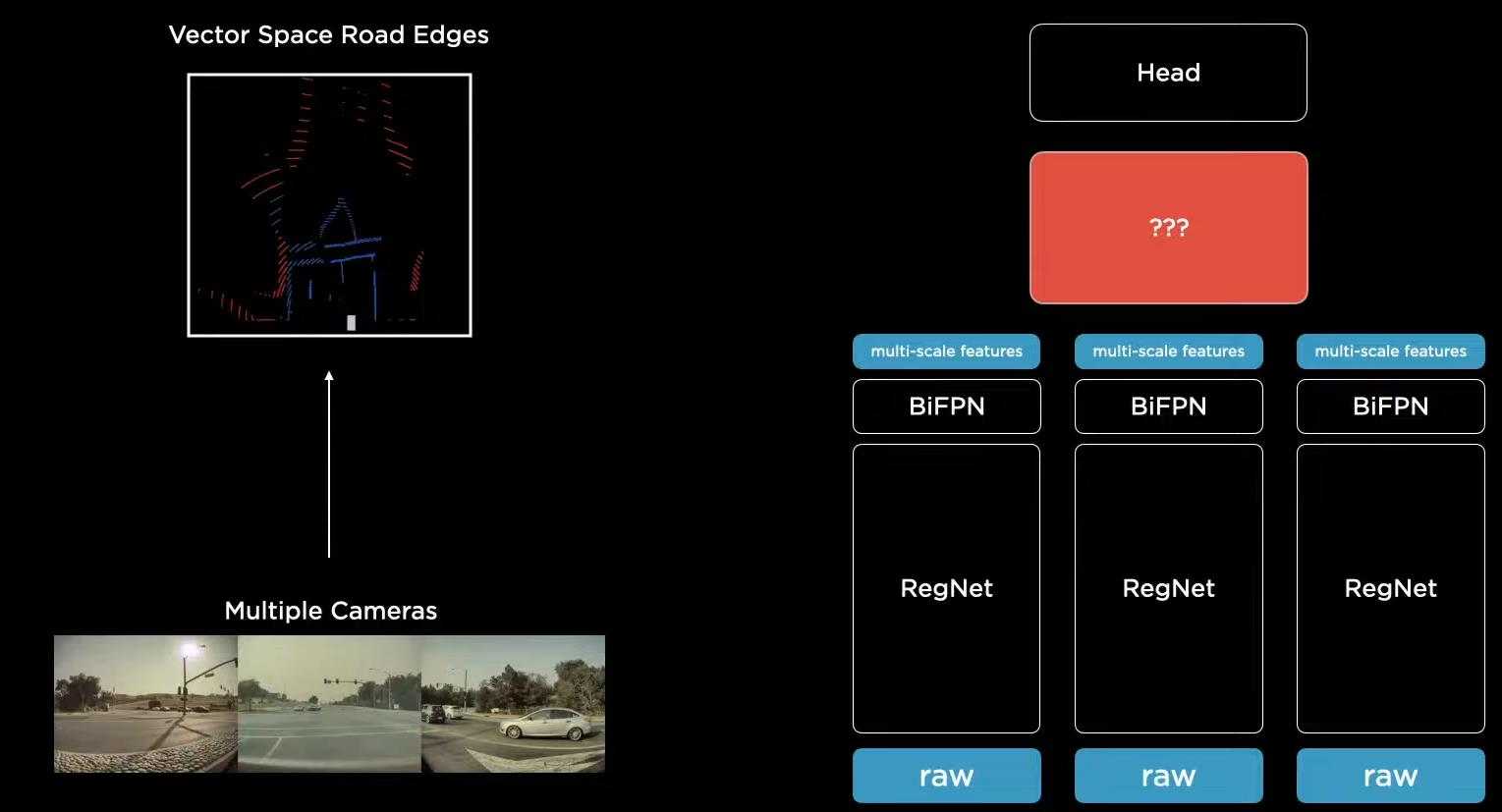
在自动驾驶过程中有一个问题,离得近的物体比较大,离得远的物体比较小,为了解决这个问题,可以采用FPN的思想,获得多尺度的特征。在这里,他使用的是EfficientDet的BiFPN。

在整体架构上,首先经过Backbone(这里使用的RegNet)和BiFPN获得多尺度的特征。然后连接不同的下游任务,比如目标检测、车道线检测等。所有的下游任务均共享一套特征。这有三个好处,第一,共享特征可以保证特征提取得更加的高效。第二,共享特征能够对下游任务进行拓展,相当于下游任务之间各自为政。第三,我们可以对特征进行缓存,加入新的下游任务时直接基于提取的特征进行训练,而不必重头开始训练。

四年前的Tesla是单个视角的,但是这样获取的信息是片面的,我们更希望获得更加全方位的信息。因此,我们通过8个视角获取多视角信息。但是如果8个视角各种为政,将带来两个问题。首先,8个视角的信息肯定是有重复的。其次,8个视角的信息肯定会带来干扰,需要去分辨出各个视角的信息。因此,在自动驾驶的过程中,很容易出现抖动。

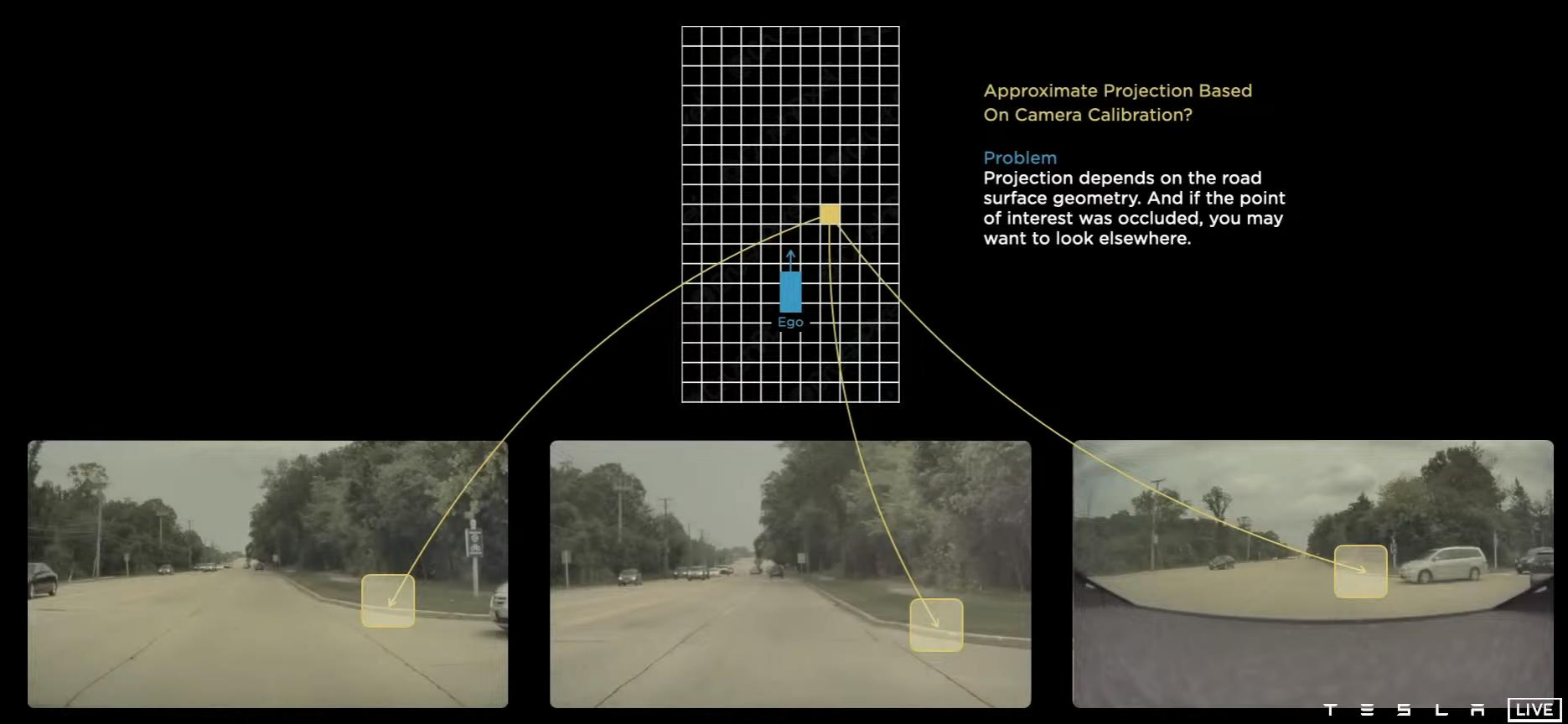
2D很难整合信息,那么类似于三维重建,我们能不能在3D维度上整合获得全局信息呢?因此,我们首先可以对8个摄像头获取的图像信息进行特征提取,然后将所得到的特征映射到3维的向量空间。
这又引入了一个问题,类似于三维重建,如何进行特征对齐?即不同视角下相同的信息映射到三维空间的同一个点上。如果映射不对,那只能是一步错,步步错。然后还有一个问题,如果路况不好,收集信息比较困难,干扰比较大,那么肯定很难进行特征对齐。对于这个问题,Tesla的工程师并没有提到解决方案。
于是,Tesla在构建向量空间的时候使用了Transformer,3D的q查2D的,从而实现对特征进行整合的效果。
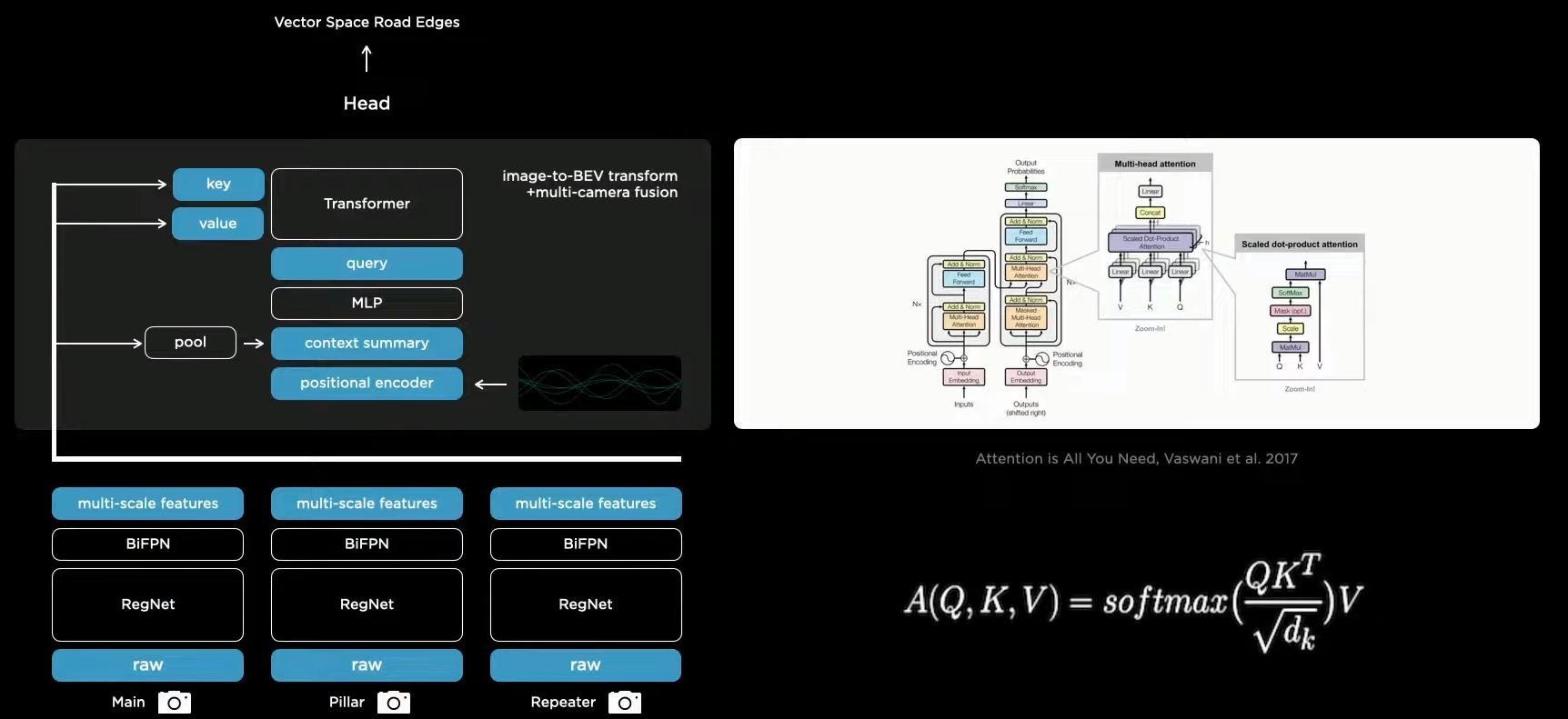
车辆的摄像头很可能出现摄像头的偏移情况。因此,还需要一个偏移模型。

但是,还不够,汽车并不是静止的,还需要时序特征。比如汽车在行驶中看到了一个不能掉头的交通标志,那么后面即使看不见了,在这条道行驶依然不能掉头。

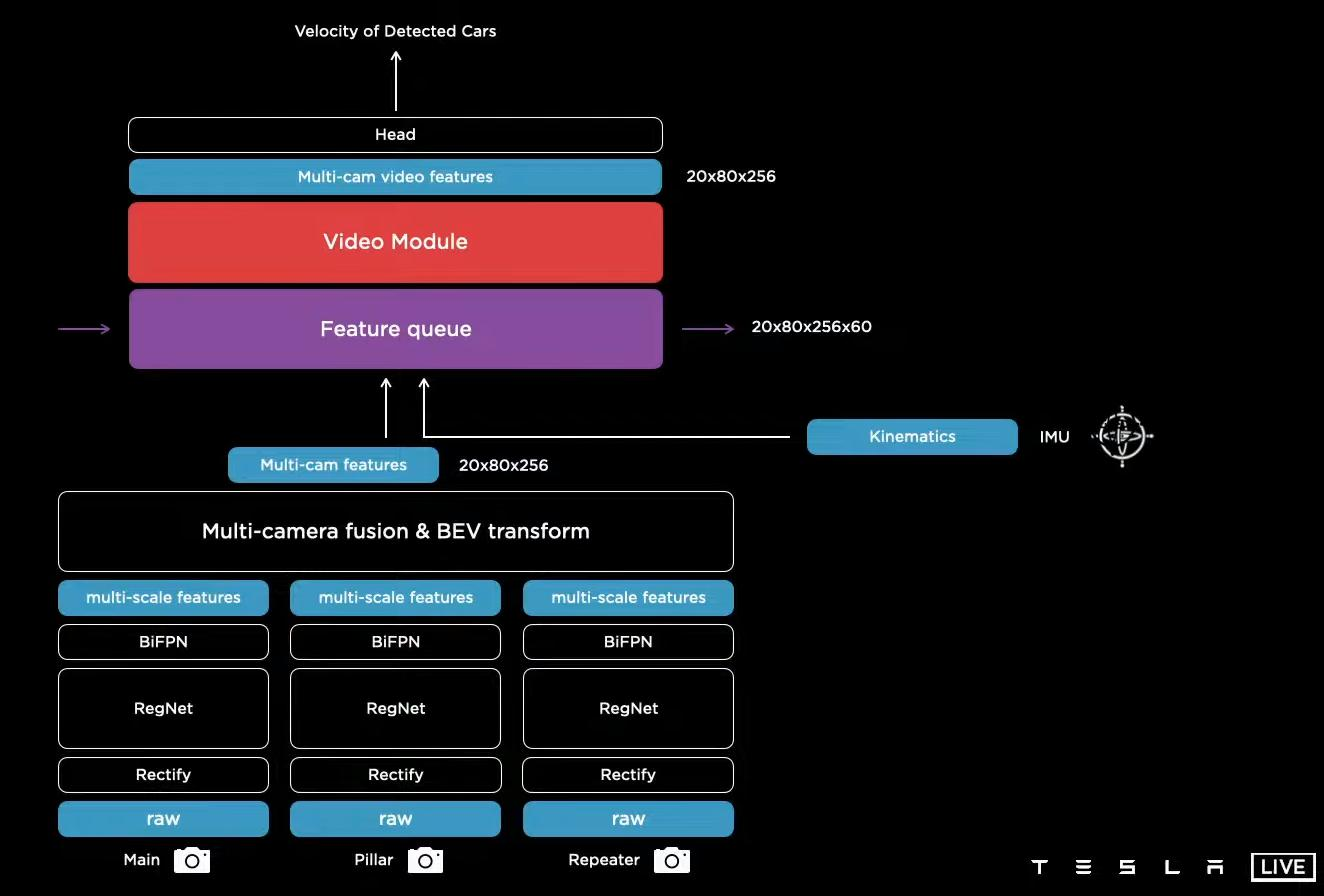
因此,在模型中还加入了记忆模块,我们可以看到,Feature queue是一个20*80*256*60的序列,其中20*80很显然是特征图大小,256是通道数,60是序列长度。特征序列相当于是一个缓存区。我们还可以注意到,Tesla也使用了一些传感器的特征。(IMU)。后面特征维度变为20*80*256很显然是做了一个全局的池化。
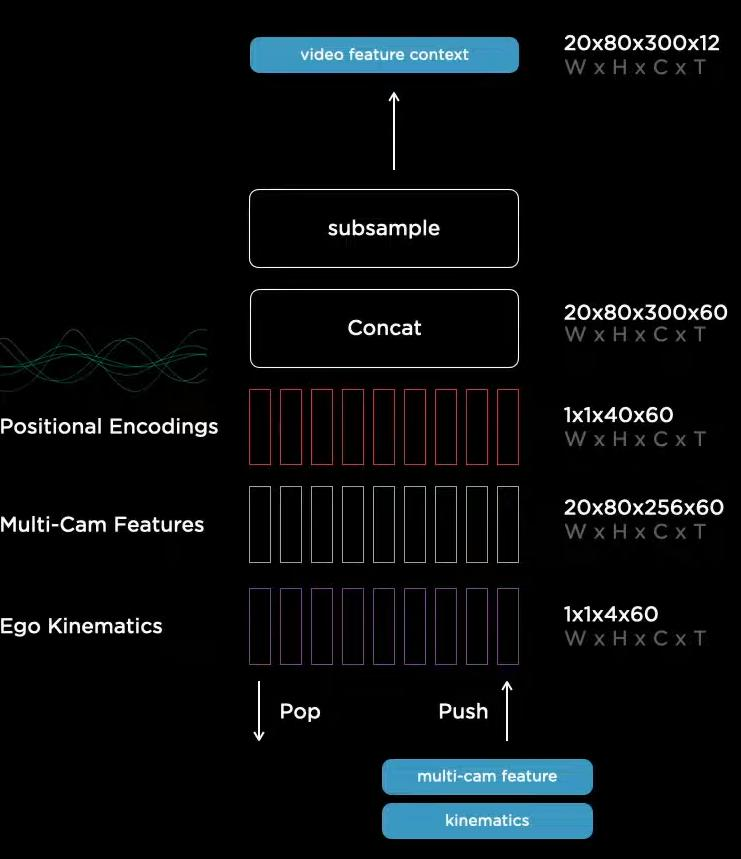
时间序列是在不断更新的,将60时刻的图像特征和传感器特征拼接,并加入表示时刻的位置编码。最后为了节省时间,进行了一次压缩。
对于序列的应用,是不断的更新的,只保留60个时序特征,并经过LSTM进行处理。
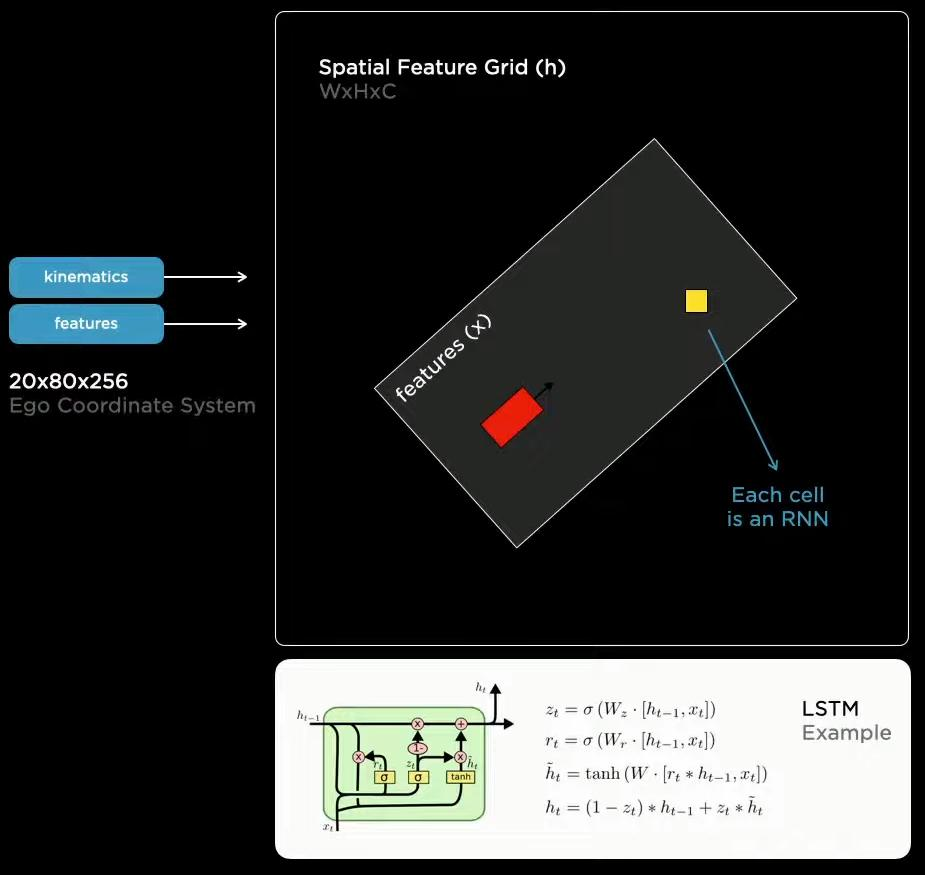
序列能够很好的解决遮蔽现象,虽然当前时刻有遮挡现象,但是序列中依然储存着之前的信息。

整体框架如下,首先通过CNN和BiFPN获得多尺度特征,并映射到3D向量空间,然后缓存一个60时刻的时间序列的特征,并使用LSTM进行处理,最后的相互之间独立的下游任务。也就是Tesla工程师所说的4D(3D+时间)
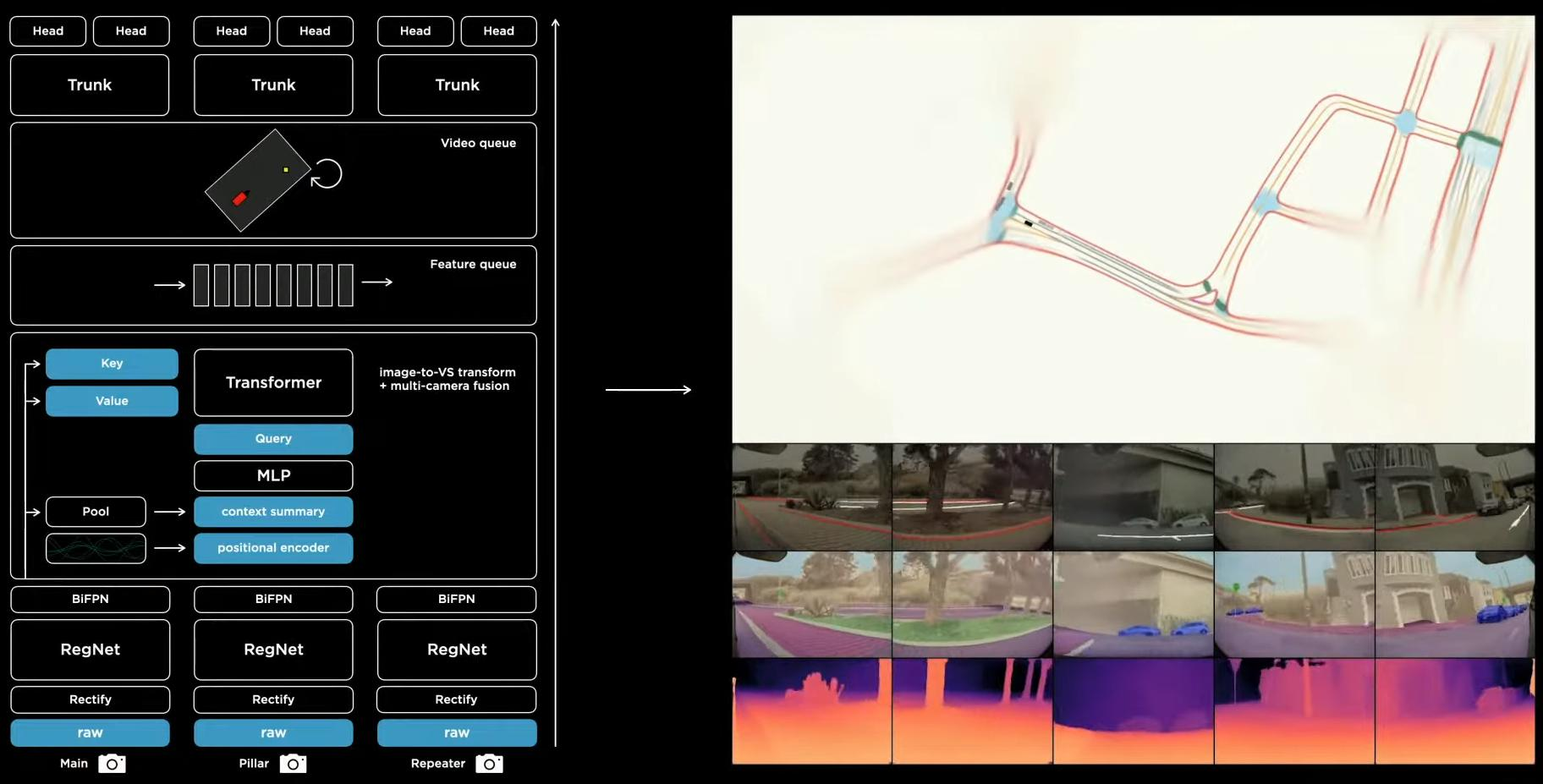
在标注过程中,用户上传数据后,2D的标准直接使用机器打标。而人工标注的是3D与2d的映射关系。

然而,特殊场景太多,采集数据工作量可能太大,因此,还使用计算机模拟场景。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
2023-02-20 2023.2.20学习记录
2023-02-20 软件工程开课博客