三 数据挖掘算法
K-近邻 K-NN 可简单理解为 近朱者赤近墨者黑
欧式距离 文本分类计算时 余弦策略
MBR Memory-Based Reasoning 记忆基础推理法
Collaborative Filtering 协同过滤
应用场景 稀疏事件 医疗-罕见病 反欺诈
计算步骤 1、算距离 2、找邻居 3、做分类
常见问题 k值设定 一般低于训练样本数的平方根
购物篮分析和关联规则
规则的度量 支持度和置信度
支持度 广泛程度 1000小票中100张同时购买A和B AB的支持度为10%
置信度 条件概率 P(y|x) >P(y)
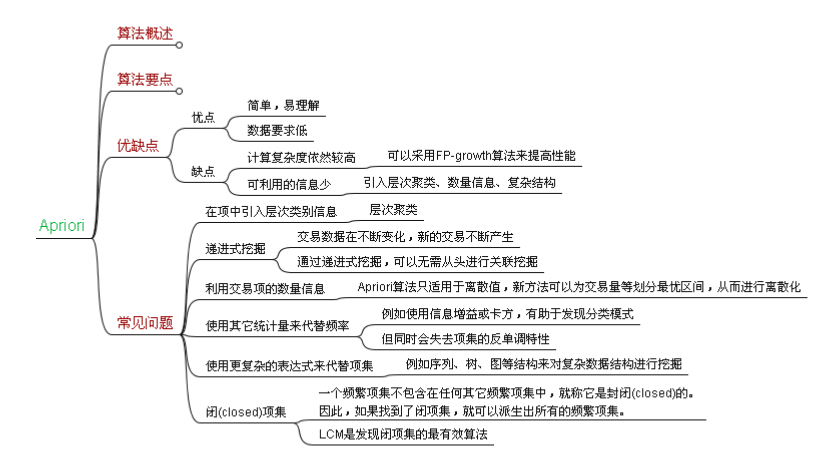
Apriori算法 原则 频繁项集的所有非空子集一定也是频繁的 frequent

回归分析
应用 信用评分 logistic 逻辑回归
聚类分析
常用于客户细分
数据探索和预处理
文本www等分类
K-Means算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号