Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop
下载地址:http://hadoop.apache.org/releases.html
选择对应版本的二进制文件进行下载
2.解压配置
以hadoop-2.6.5.tar.gz为例
解压文件
tar -zxvf hadoop-2.6.5.tar.gz
移动到/opt 目录下
mv hadoop-2.6.5 /opt
配置JDK环境变量
追加Hadoop的bin和sbin目录到环境变量PATH中,这里不多讲。
使用 source命令使配置立即生效
例如:source /etc/profile
配置四个配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
本例共四个主机,分别是s10,s11,s12,s13
s10:名称结点
s11、s12:数据结点
s13:辅助名称结点
/etc/hosts 文件配置主机映射如下:

core-site.xml 配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://s10:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.6.5/tmp</value> </property> </configuration>
hdfs-site.xml 配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>s13:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop-2.6.5/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop-2.6.5/hdfs/data</value> </property> </configuration>
mapred-site.xml 配置
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xml 配置
<?xml version="1.0"?> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>s10</value> </property> </configuration>
修改 slaves 文件内容为对应的数据结点
s11
s12
为了保险,此处直接配置JAVA_HOME到 /opt/hadoop-2.6.5/etc/hadoop/hadoop-env.sh 中,防止出现JAVA_HOME is not set and could not be found.错误
hadoop-env.sh文件第一行有效代码(不包含注释)改为
export JAVA_HOME=/usr/soft/jdk1.8.0_181
3. 配置四台主机 ssh 无密码相互访问,复制配置好的 /opt/hadoop-2.6.5 到其它三台主机
快速配置四台主机ssh无密码访问方法如下:
①在四台主机上分别执行 ssh-keygen -t rsa 生成公钥和私钥
②把四台主机的公钥分别追加到s0主机~/.ssh/authorized_keys 文件中
③远程复制 authorized_keys 文件到其它三台主机
更多细节请参考:https://www.cnblogs.com/jonban/p/sshNoPasswordAccess.html
配置完成后使用 ssh 命令在每一台主机上手动登录一下其它三台主机,完成第一次访问的确认,以后就可以直接登录了
远程复制配置好的 /opt/hadoop-2.6.5 到其它三台主机,记得配置JDK环境变量和Hadoop环境变量,参考第2步
4. 格式化文件系统为hdfs
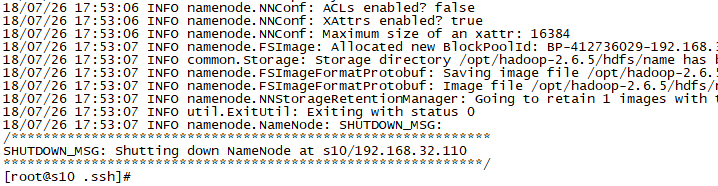
hadoop namenode -format
运行结果如下:
5. 启动Hadoop集群环境
start-dfs.sh
start-yarn.sh
在四台主机上分别输入 jps 命令,查看集群状态,内容如下:
[root@s10 hadoop]# jps
28417 Jps
28163 ResourceManager
27907 NameNode
[root@s11 hadoop]# jps
27083 Jps
26875 DataNode
26972 NodeManager
[root@s12 hadoop]# jps
27095 Jps
26887 DataNode
26984 NodeManager
[root@s13 hadoop]# jps
26882 Jps
26826 SecondaryNameNode
符合集群预期结果
s10:名称结点
s11、s12:数据结点
s13:辅助名称结点
6.验证
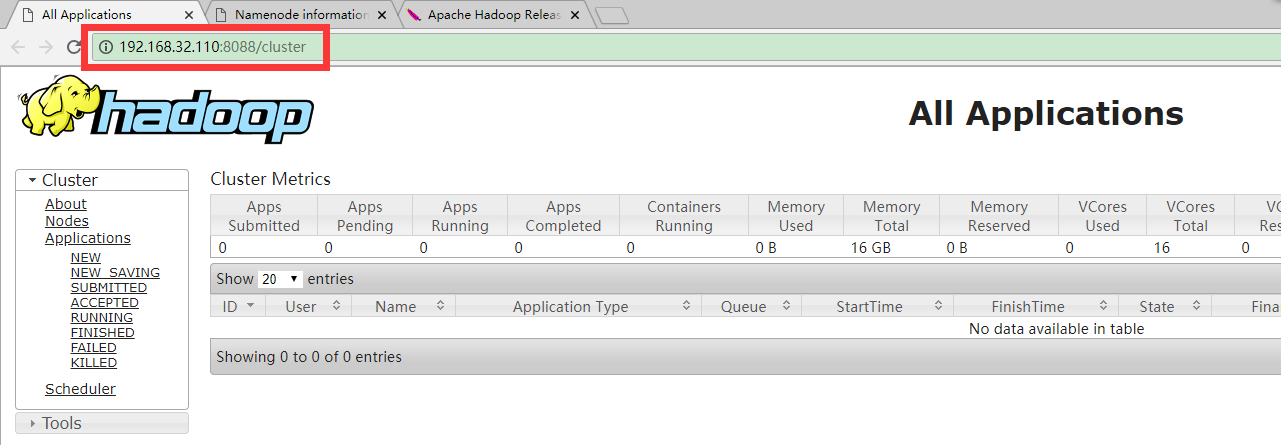
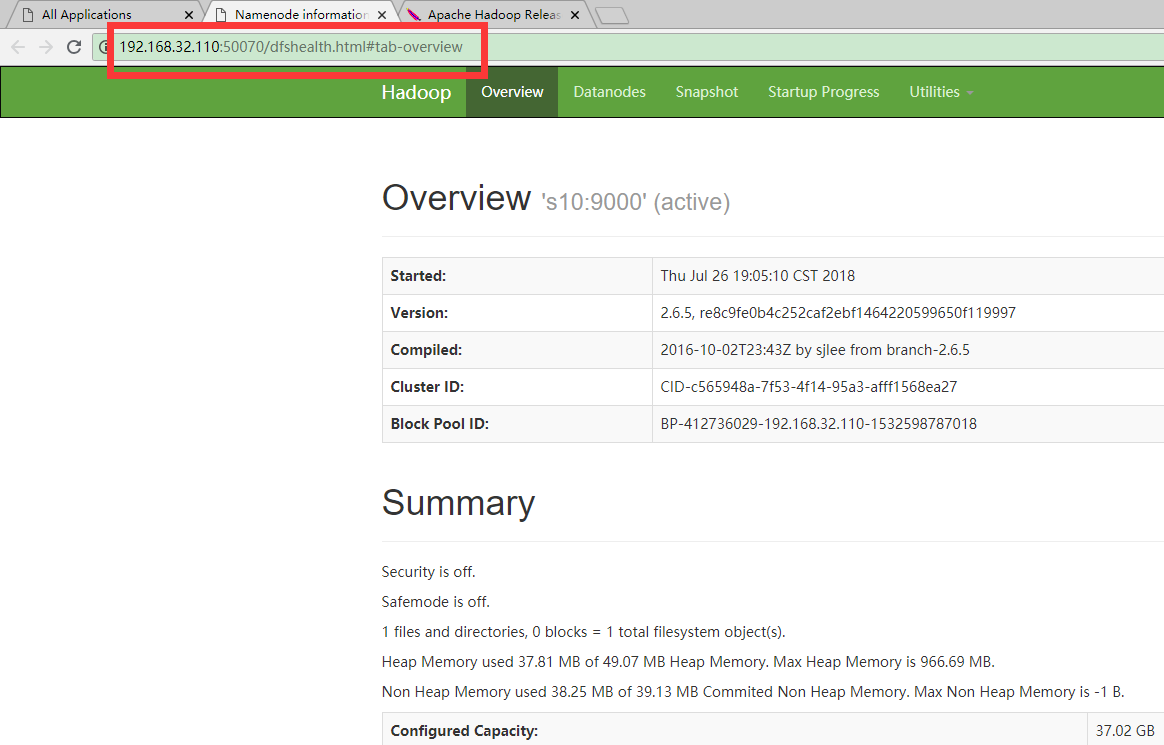
浏览器输入地址:
http://192.168.32.110:8088
http://192.168.32.110:50070
这里的IP是主机s10的IP
效果截图如下,地址自动跳转
Hadoop完全分布式集群环境搭建
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号