MapReduce执行jar练习
1、用程序生成输入文件1.txt和2.txt
生成程序源码如下:
https://www.cnblogs.com/jonban/p/10555364.html
2. 上传文件到hdfs文件系统
创建输入文件目录
hdfs dfs -mkdir -p /hadoop/input
上传文件到输入目录
hdfs dfs -put 1.txt /hadoop/input/
hdfs dfs -put 2.txt /hadoop/input/
如下图:
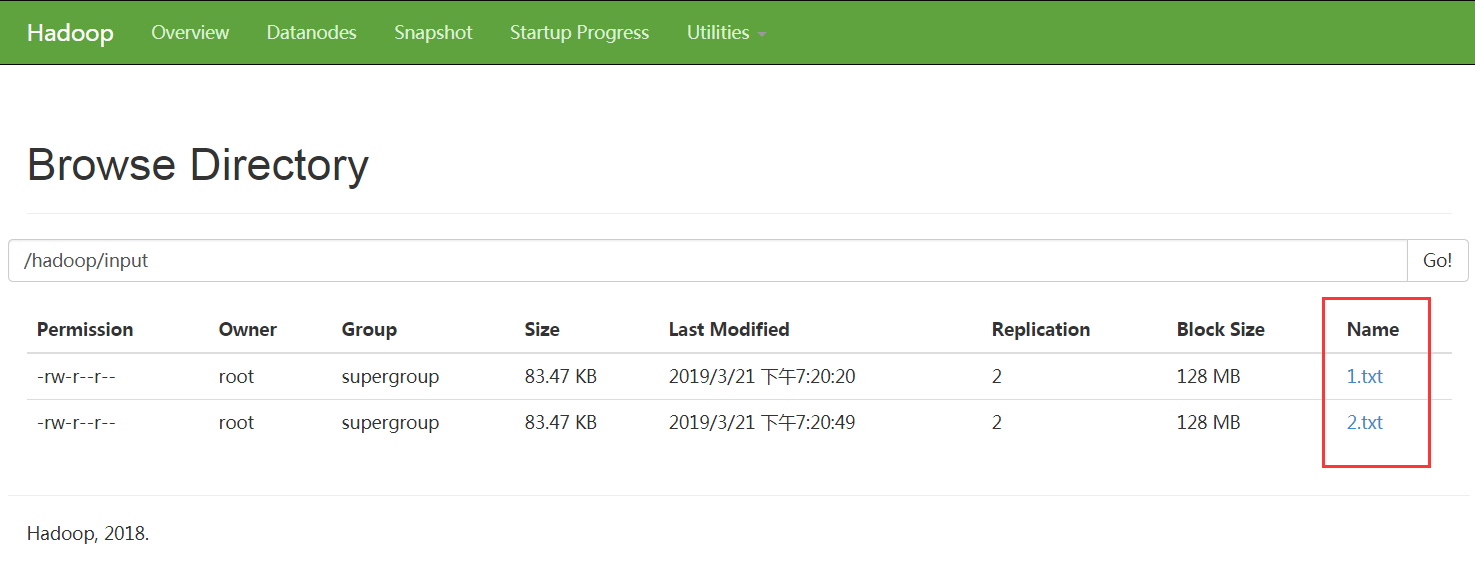
3. 打包并上传MapReduce程序jar
源码如下:
https://www.cnblogs.com/jonban/p/10555826.html
打包为hadoop.jar并上传到集群上,执行命令
hadoop jar hadoop.jar /hadoop/input/ /hadoop/output
如下图:
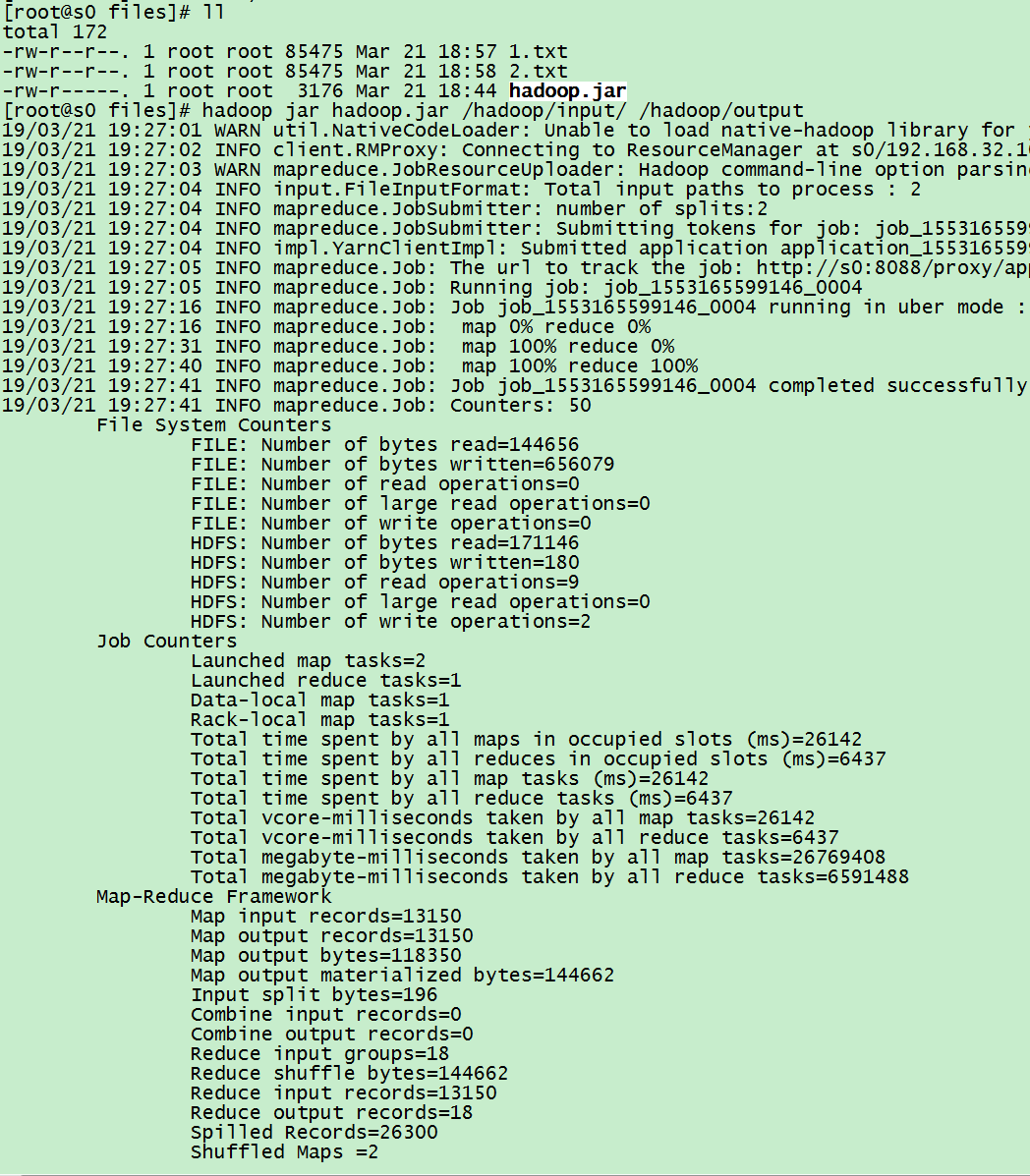
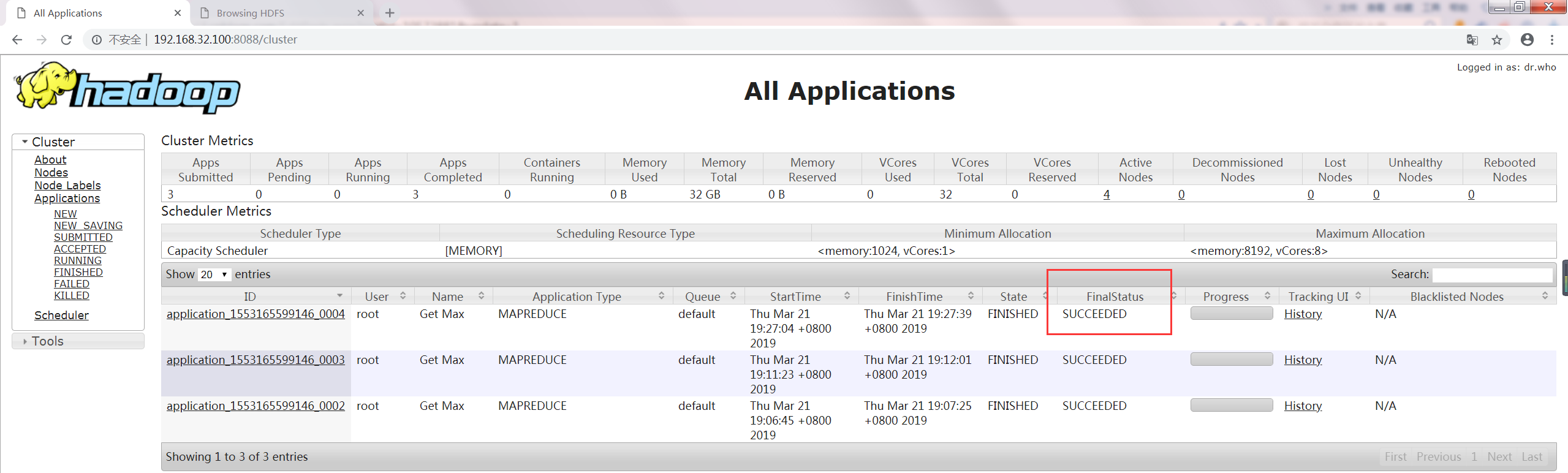
查看输出结果,如下图:
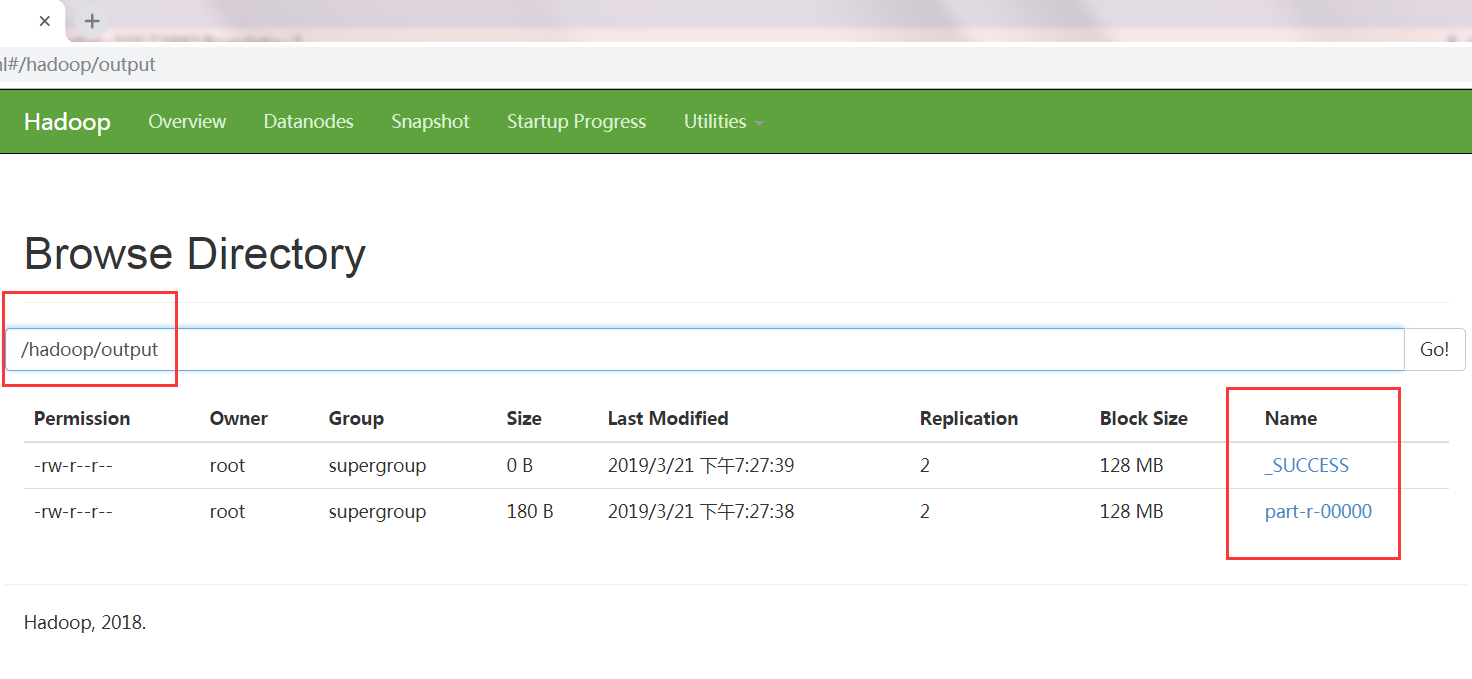
查看输出内容:
hdfs dfs -cat /hadoop/output/part-r-00000
输出结果如下:
2000 9997 2001 9993 2002 9997 2003 9994 2004 9995 2005 9983 2006 9978 2007 9990 2008 9968 2009 9987 2010 9996 2011 9986 2012 9997 2013 9987 2014 9999 2015 9997 2016 9995 2017 9998
输出结果正确!
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号