替换Hive引擎为Spark
写在前面
- 必须要先保证hadoop是正常启动的,hadoop安装配置见《CentOS7安装Hadoop集群》
- HIVE是正常的,Hive安装配置见《CentOS7安装Hive》
- Spark是正常的,Spark安装配置见《CentOS7安装Spark集群(yarn模式)》
其它配置
- HDFS创建以下路径,用于存储相关jar包
hadoop fs -mkdir /Spark/spark-jars
- 解压缩
spark-3.0.0-bin-without-hadoop.tgz并上传到上面目录,提供百度云下载地址
tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tg
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /Spark/spark-jars
- 修改
hive-site.xml,增加如下内容
<!--Spark依赖位置 -->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/Spark/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive连接Spark超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
<property>
<name>spark.master</name>
<value>yarn</value>
</property>
<property>
<name>spark.home</name>
<value>/opt/module/spark</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://hadoop102:8020/Spark/spark-eventLog</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>4</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>4</value>
</property>
测试
出现这样的页面即算配置成功
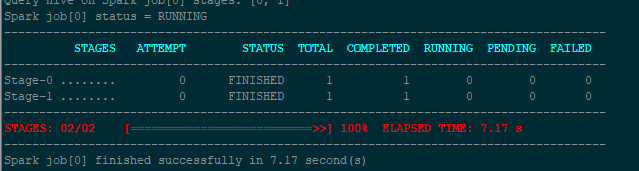
注意点:
Hive on Spark会一直占用yarn的队列资源,为的是不多次加载上面spark-jar下的依赖,具体表现为
-
yarn任务卡在10%
![image]()
-
spark 任务挂在incompleted
![image]()
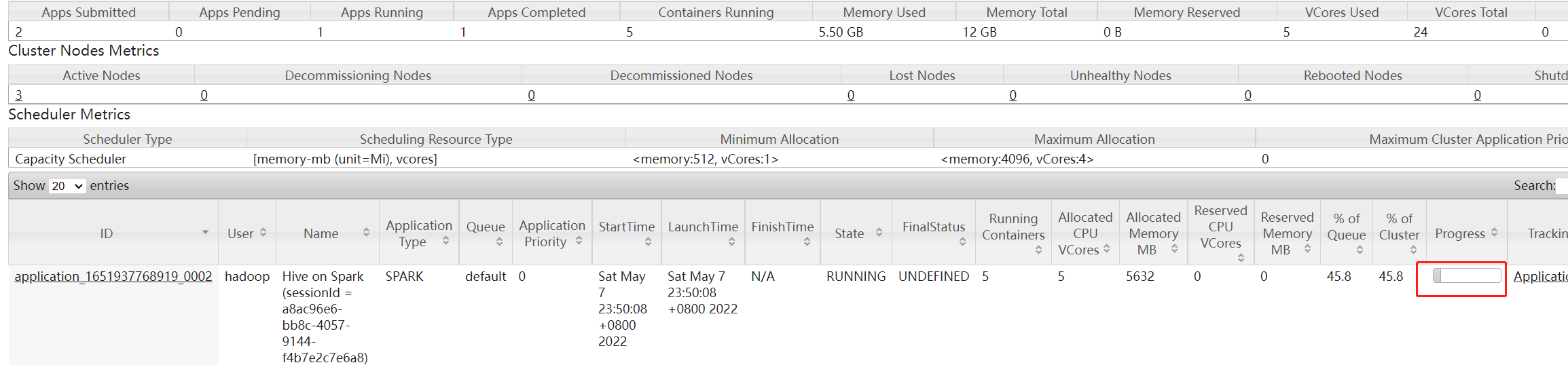

退出hive即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号