
CentOS7安装Spark集群(yarn模式)
写在前面
Spark-yarn安装需要首先安装:
- Zookeeper,安装教程见《CentOS7安装Zookeeper集群》
- Hadoop,安装教程见《CentOS7安装Hadoop集群》
- 部署模式还有Local模式、standalone模式,自行研究
部署说明
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这
种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主
要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是
和其他专业的资源调度框架集成会更靠谱一些。在国内工作中,Yarn 使用的非常多。
软件下载
自行下载所需版本,提供spark-3.0.0-bin-hadoop3.2.tgz百度网盘下载地址
解压缩
tar xzvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
安装目录个人喜好,解压缩文件可以改个名
spark-yarn
修改hadoop配置文件yarn-site.xml
Hadoop,安装教程见《CentOS7安装Hadoop集群》,教程中已配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk1.8.0_212
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
JAVA_HOME配置过就不用再配置了,配置方法见《CentOS7配置jdk1.8环境》
确定hadoop和yarn集群已启动
jpsall
脚本见《“尚硅谷”的jpsall脚本》
结果正常如下,为433的架构

尝试提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
参数解释:以yarn模式运行spark-examples_2.12-3.0.0.jar包中的org.apache.spark.examples.SparkPi的方法,传参为10
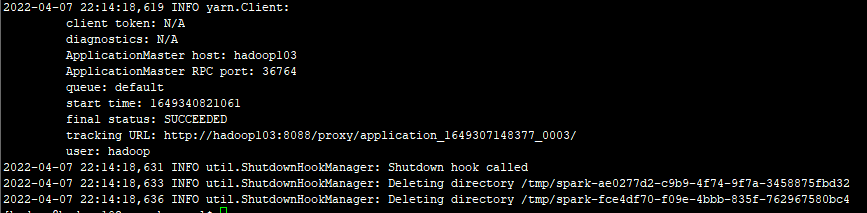
查看 http://hadoop103:8088 页面,点击Histroy,则可以查看历史页面(持久化需要配置历史服务器)
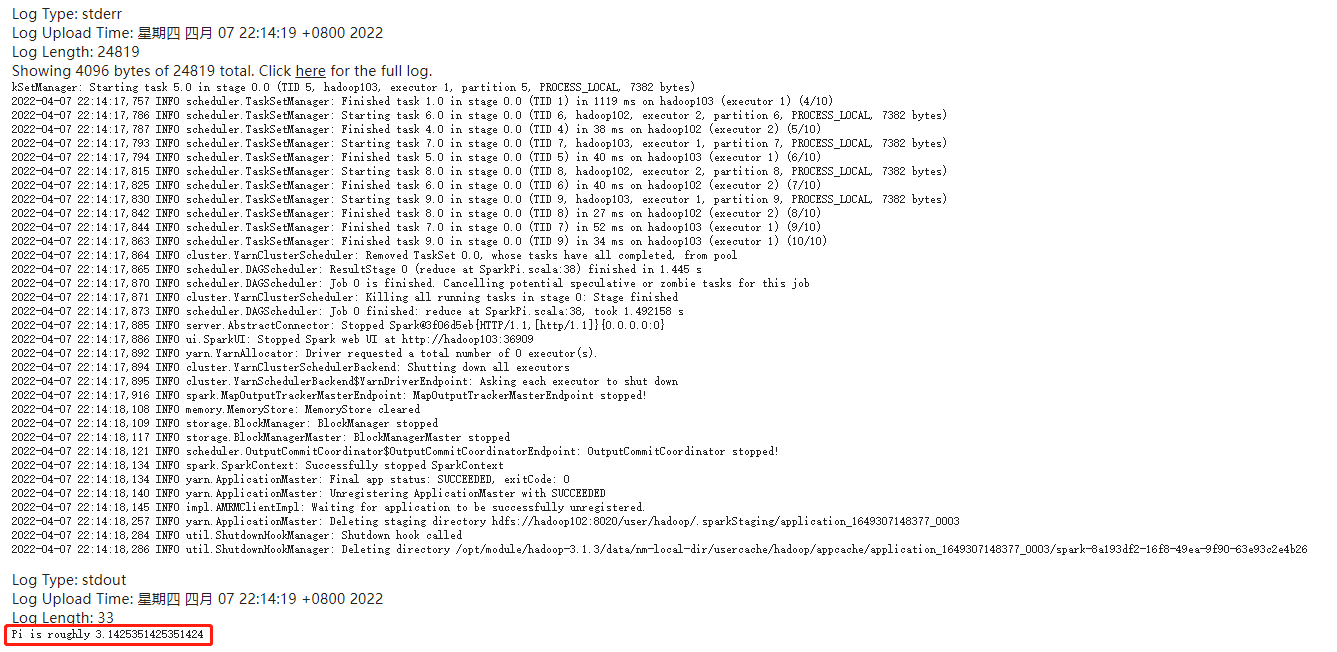
配置历史服务器
- 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
- 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
#这里对应hadoop里面配置的core-site.xml中fs.defaultFS节点
spark.eventLog.dir hdfs://hadoop102:8020//Spark/spark-eventLog
还可以指定一些其它配置,例如
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
spark.executor.cores 4
spark.executor.memory 1g
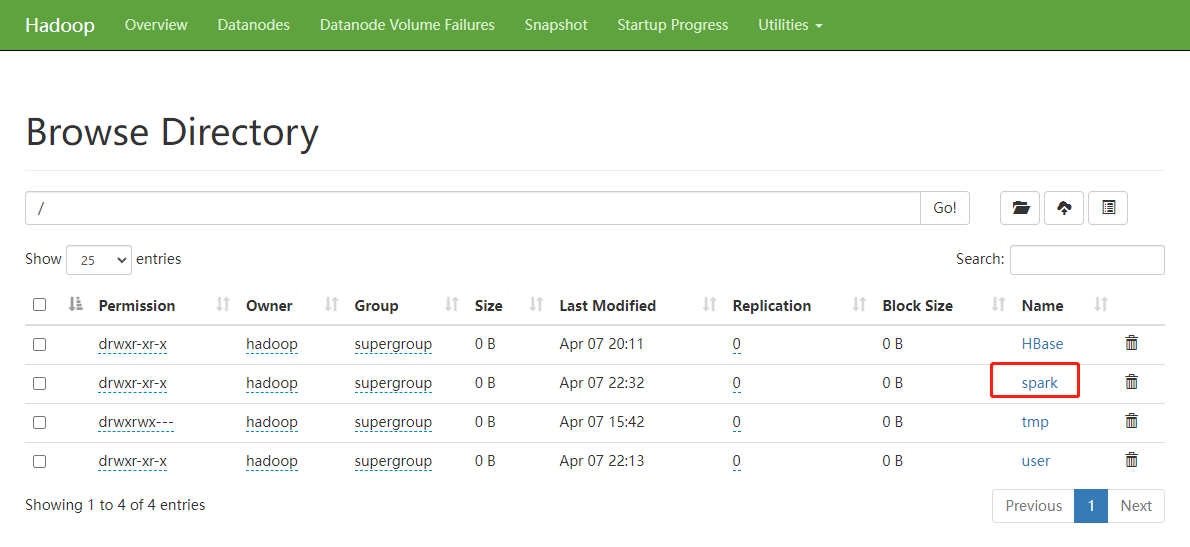
注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在。
hadoop fs -mkdir /Spark/spark-eventLog
见hdfs ui界面
- 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/Spark/spark-eventLog
-Dspark.history.retainedApplications=30"
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
注意:spark.history.fs.logDirectory 必须和 spark.eventLog.dir一致,不然历史服务不生效
- 修改 spark-defaults.conf
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
- 启动历史服务
sbin/start-history-server.sh
- 重新提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
参数解释:以yarn模式运行spark-examples_2.12-3.0.0.jar包中的org.apache.spark.examples.SparkPi的方法,传参为10,模式为客户端模式,可以对比下
查询history页面 http://hadoop102:18080
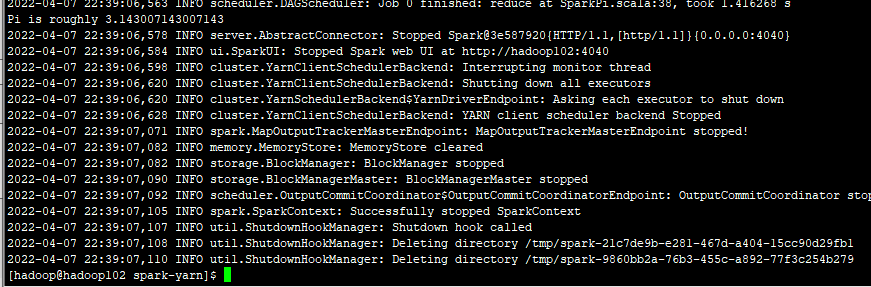

一些踩过的坑
- Spark提交任务到Yarn,不论是Yarn-Clinet还是Yarn-cluster模式,都是Accept但是不执行
网上遇到的无非就是内存问题还有一些杂七杂八的问题,我遇到的是因为Yarn的ResourceManager服务端口号被我改了(默认8030,因为和StarRocks的StarRocksFE冲突),在yarn-site.xml里面配置yarn.resourcemanager.scheduler.address为固定的地址就行了,按照我的教程《CentOS7安装Hadoop集群》,改为${yarn.resourcemanager.hostname}:8034


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律