CentOS7安装Hive
写在前面
必须要先保证hadoop是正常启动的,hadoop安装配置见《CentOS7安装Hadoop集群》
软件下载
自行下载需要的版本,这里附上apache-hive-3.1.2-bin.tar.gz百度云下载链接
解压缩
tar xzvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
解压缩后名字太长,可以改个名字
创建环境变量
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
刷新环境变量
source /etc/profile
Hive配置原数据到mysql
- 拷贝/上传mysql的jdbc驱动到hive的lib目录下,提供
mysql-connector-java-5.1.27-bin.jar百度云下载地址 - 配置Metastore到mysql
在$HIVE_HOME/conf目录下创建hive-site.xml文件,并写入下列配置
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL,指定编码格式以支持中文 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:33066/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>your_passwd</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<!--
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
-->
<!--hiveserver2的高可用参数,开启此参数可以提高hiveserver2的启动速度 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
</configuration>
修改hive-env.sh.template,放开 export HADOOP_HEAPSIZE配置
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HEAPSIZE=1024
默认不放开,默认使用256M
修改hive-log4j2.properties.template中日志路径
cp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
#修改以下配置项
property.hive.log.dir=/opt/module/hive/logs
Mysql增加metastore库
名称与上面jdbc中的配置一致
mysql环境安装/进入见《CentOS7安装Mysql-5.7.30》
这里需要配置下mysql的root用户远程可登录,或者重新新建一个账号
update mysql.user set host="%" where user="root";
flush privileges;
create database metastore;
初始化Hive元数据
/opt/module/hive/bin/schematool -initSchema -dbType mysql -verbose
这里会跳一堆脚本,提示
schemaTool completed则表示成功
修改部分表的编码格式以支持中文
默认是Latin1格式
use metastore;
#修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
#修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改视图
alter table TBLS modify column `VIEW_EXPANDED_TEXT` mediumtext character set utf8;
alter table TBLS modify column `VIEW_ORIGINAL_TEXT` mediumtext character set utf8;
启动hive
# 启动客户端,客户端用DBeaver,界面友好点
/opt/module/hive/bin/hive
# 启动服务端,默认端口10000
nohup hive --service hiveserver2 &
# 启动服务端,不输出日志
nohup hive --service hiveserver2 > /dev/null 2>&1 &
必须要保证hadoop正常启动中
提供DBeaver破解教程,有能力请支持正版
查看数据库
hive> show databases;
OK
default
Time taken: 1.377 seconds, Fetched: 1 row(s)
hive>
建表及插入数据
CREATE TABLE `test_user`(
`id` string COMMENT '编号',
`name` string COMMENT '姓名',
`province_id` string COMMENT '省份ID',
`province_name` string COMMENT '省份名称')
COMMENT '用户表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
insert into table test_user values('1','zhangsan','001','北京');
插入数据可以在yarn( http://hadoop103:8088 )上看到任务,跑完后即可在hive中查到这个记录,数据存在HDFS(http://hadoop102:9870)
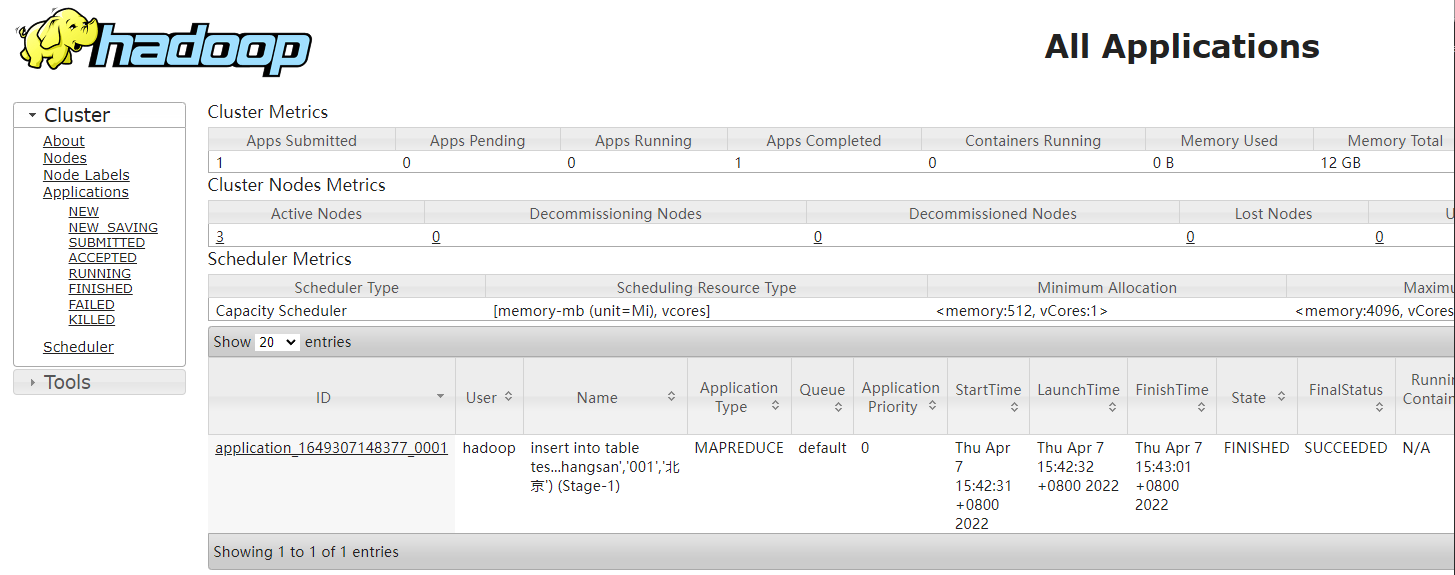
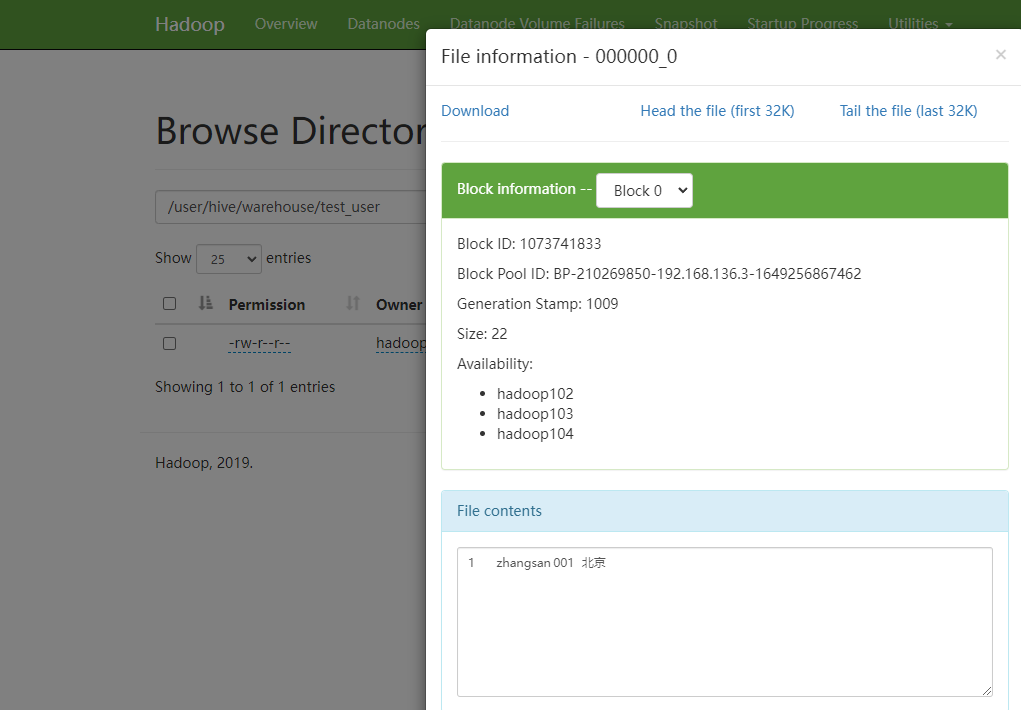
检查中文显示是否正常
desc test_user;

写在后面
默认引擎是MapReduce,建议替换为Spark,速度和提示感觉好很多,测试样本4.5K万,前者跑不出来,后者很轻松,配置方法详细见《替换Hive引擎为Spark》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号