


python之函数
定义一个函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法
#!/usr/bin/python3 # 计算面积函数
def area(width, height):
return width * height
函数名的本质
函数名本质上就是函数的内存地址
1)函数名可以被引用
def func(): print('in func') f = func print(f)
2)函数名可以被当作容器类型的元素
def f1(): print('f1') def f2(): print('f2') def f3(): print('f3') l = [f1,f2,f3] d = {'f1':f1,'f2':f2,'f3':f3} #调用 l[0]() d['f2']()
3)函数名可以当作函数的参数和返回值,可以视为一个普通的变量,进行使用
def func(): print('in func') def foo(): print('in foo') return foo res=func() res() print(res) 输出结果: in func in foo <function func.<locals>.foo at 0x03803540> 上面的函数,是有两个,第一个func的函数返回的是foo的内存地址即foo的函数,当调用func函数时,返回值返回的内存地址赋值给res,当在res的后面加上()时,等同于调用了foo的函数。
函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
#!/usr/bin/python3 #
定义函数
def printme( str ): "打印任何传入的字符串"
print (str) return # 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
调用函数的规则:
1.函数名()
函数名后面+圆括号就是函数的调用。
2.参数:
圆括号用来接收参数。
若传入多个参数:
应按先位置传值,再按关键字传值
具体的传入顺序应按照函数定义的参数情况而定
3.返回值
如果函数有返回值,还应该定义“变量”接收返回值
如果返回值有多个,也可以用多个变量来接收,变量数应和返回值数目一致
无返回值的情况:
函数名()
有返回值的情况:
变量 = 函数名()
多个变量接收多返回值:
变量1,变量2,... = 函数名()
注意:return返回值的奇妙用法
1、没有返回值
- 不写return的情况下,会默认返回一个None:
- 只写return,后面不写其他内容,也会返回None
2、有返回值
1)返回一个值,只需在return后面写上要返回的内容即可。注意:return和返回值之间要有空格,可以返回任意数据类型的值
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen() print('str_len : %s'%str_len)
2)返回任意多个、任意数据类型的值
def ret_demo1(): '''返回多个值''' return 1,2,3,4 def ret_demo2(): '''返回多个任意类型的值''' return 1,['a','b'],3,4 ret1 = ret_demo1() print(ret1) ret2 = ret_demo2() print(ret2)
#序列解压一 >>> a,b,c,d = (1,2,3,4) >>> a 1 >>> b 2 >>> c 3 >>> d 4 #序列解压二 >>> a,_,_,d=(1,2,3,4) >>> a 1 >>> d 4 >>> a,*_=(1,2,3,4) >>> *_,d=(1,2,3,4) >>> a 1 >>> d 4 #也适用于字符串、列表、字典、集合 >>> a,b = {'name':'eva','age':18} >>> a 'name' >>> b 'age'
强调:
只写return,后面不写其他内容,也会返回None,既然没有要返回的值,完全可以不写return,为什么还要写个return呢?这里我们要说一下return的其他用法,就是一旦遇到return,结束整个函数。
参数传递

在 python 中,类型属于对象,变量是没有类型的:
#函数定义 def mylen(s1): """计算s1的长度""" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen("hello world") print('str_len : %s'%str_len)
我们告诉mylen函数要计算的字符串是谁,这个过程就叫做 传递参数,简称传参,我们调用函数时传递的这个“hello world”和定义函数时的s1就是参数。
实际参数
调用函数时传入的值,被称为实际参数
形式参数
定义函数时定义的需要传入的变量,被称为形式参数
我们调用函数时传递的这个“hello world”被称为实际参数,因为这个是实际的要交给函数的内容,简称实参。
定义函数时的s1,只是一个变量的名字,被称为形式参数,因为在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
强调:
传递一个参数
传递多个参数
参数可以传递多个,多个参数之间用逗号分割。
参数
以下是调用函数时可使用的正式参数类型:
- 位置参数
位置传值
def mymax(x,y):
调用mymax()函数时,按照位置一一的传入相应位置的值
调用时mymax(1,2),如果少写一个参数,就会报错如mymax(1),因为形参的位置是两位,所以传入的时候也是两个数值。
关键字传值
def mymax(x,y):
调用mymax()函数时,按照关键字的传值方式,mymax(y=2,x=1),需要强调的是当使用关键字传值的时候,无需注意顺序也没什么大的关系。
因为是对应着关键字,一一的传入的。
强调:
如果位置传值和关键字传值混用的话,位置参数必须放在关键字参数的前面。
- 关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
- 默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值。
#!/usr/bin/python3 #可写函数说明 def printinfo( name, age = 35 ): "打印任何传入的字符串" print ("名字: ", name) print ("年龄: ", age) return #调用printinfo函数 printinfo( age=50, name="runoob" ) print ("------------------------") printinfo( name="runoob" )
强调:
默认参数虽然默认写了固定的数值,但是它也是一个可变的参数,按照需要可以进行传入其他的值
- 不定长参数(动态参数、可变长参数)
可变长指的是实参值的个数不固定,而实参有按位置和按关键字两种形式定义,针对这两种形式的可变长,形参对应有两种解决方案来完整地存放它们,分别是*args,**kwargs。
在定义函数时,如果需要进行传参,但是传入的参数数量是变化的,就需要进行如下操作:
def func(x,y,*args,**kwargs)在定义阶段时,定义传入的参数使用,*args,**kwargs
func(1,2,3,4,5,a=1,b=2)函数调用阶段,
输出结果如下
1
2
(3, 4, 5)
{'a': 1, 'b': 2}
按照输出结果,可以理解为,如果已经定义了形参,传入的实参先按照位置参数传入和关键字参数传入的方式进行相应值得传入,其他余下的实参就需要对应*args,**kwargs进行相应传值操作。*args将会接收剩余的位置传参余下的值,并以元组的形式集合在一起,**kwargs将会接收剩余的关键字传参余下的值,并以字典的形式集合在一起。
===========*args===========
def foo(x,y,*args):
print(x,y)
print(args)
foo(1,2,3,4,5)
def foo(x,y,*args):
print(x,y)
print(args)
foo(1,2,*[3,4,5])
def foo(x,y,z):
print(x,y,z)
foo(*[1,2,3])
===========**kwargs===========
def foo(x,y,**kwargs):
print(x,y)
print(kwargs)
foo(1,y=2,a=1,b=2,c=3)
def foo(x,y,**kwargs):
print(x,y)
print(kwargs)
foo(1,y=2,**{'a':1,'b':2,'c':3})
def foo(x,y,z):
print(x,y,z)
foo(**{'z':1,'x':2,'y':3})
===========*args+**kwargs===========
def foo(x,y):
print(x,y)
def wrapper(*args,**kwargs):
print('====>')
foo(*args,**kwargs)
命名空间
名称空间说白了就是变量,函数名字存放的位置,名字呢又绑定了对应的函数的内存地址的关系,如果一个链条,函数所需要的信息都串在一起,各个部分存放在各自的范围内。
#名称空间:存放名字的地方,三种名称空间,(之前遗留的问题x=1,1存放于内存中,那名字x存放在哪里呢?名称空间正是存放名字x与1绑定关系的地方)
名称空间加载顺序:内置名称空间>>>全局名称空间>>>局部名称空间
名称空间查找顺序:局部名称空间>>>全局名称空间>>>内置名称空间
- 全局命名空间
- 局部命名空间
- 内置命名空间
强调:
在全局是无法查看到局部的,在局部是可以查看到全局的
max=1 def f1(): max=2 def f2(): max=3 print('max in f2:%s'%max ) f2() f1() print(max)
输出结果:
max in f2:3
1
命名空间:
一共有三种命名空间从大范围到小范围的顺序:内置命名空间、全局命名空间、局部命名空间
作用域(包括函数的作用域链):
小范围的可以用大范围的
但是大范围的不能用小范围的
范围从大到小(图)

在小范围内,如果要用一个变量,是当前这个小范围有的,就用自己的
如果在小范围内没有,就用上一级的,上一级没有就用上上一级的,以此类推。
如果都没有,报错
作用域
1.作用域即范围 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效 局部范围(局部名称空间属于该范围):临时存活,局部有效 2.作用域关系是在函数定义阶段就已经固定的,与函数的调用位置无关 3.查看作用域:globals(),locals() LEGB 代表名字查找顺序: locals -> enclosing function -> globals -> __builtins__ locals 是函数内的名字空间,包括局部变量和形参 enclosing 外部嵌套函数的名字空间(闭包中常见) globals 全局变量,函数定义所在模块的名字空间 builtins 内置模块的名字空间
函数的嵌套
1)函数的嵌套调用
def max2(x,y):
m = x if x>y else y
return m
def max4(a,b,c,d):
res1 = max2(a,b)
res2 = max2(res1,c)
res3 = max2(res2,d)
return res3
# max4(23,-7,31,11)
2)函数的嵌套定义
实例1:
def f1(): print("in f1") def f2(): print("in f2") f2() f1()
实例2:
def f1():
def f2():
def f3():
print("in f3")
print("in f2")
f3()
print("in f1")
f2()
f1()
3)函数的作用域链
实例1
def f1():
a = 1
def f2():
print(a)
f2()
f1()
实例2
def f1():
a = 1
def f2():
def f3():
print(a)
f3()
f2()
f1()
实例3
def f1():
a = 1
def f2():
a = 2
f2()
print('a in f1 : ',a)
f1()强调:global与nonlocal关键字
global关键字
实例:
x = 99
def func():
global x#语句告诉Python在func的本地作用域内,要使用全局作用域中的变量x
x = 100
print(x)
func()
输出:
100
上述程序中的global x语句告诉Python在func的本地作用域内,要使用全局作用域中的变量x,因此在下面的x = 88语句中,
Python不会再在本地作用域中新建一个变量,而是直接引用全局作用域中的变量x,这样程序最后输出88也就不难理解了。
nonlocal关键字
def func(): count = 1 def foo(): nonlocal count#告诉python在foo函数内对变量count进行修改,count=1,就会被赋值为下面的12 count = 12 foo() print(count) func() #输出12 上面的程序中,在foo函数中使用了nonlocal关键字,就会告诉Python在foo函数中使用嵌套作用域中的变量count,
因此对变量count进行修改时,会直接影响到嵌套作用域中的count变量,程序最后也就输出12了.
注意:使用global关键字修饰的变量之前可以并不存在,而使用nonlocal关键字修饰的变量在嵌套作用域中必须已经存在。
闭包函数
什么是闭包函数?
闭包就是能够读取其他函数内部变量的函数,在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数
#闭包函数的实例 # outer是外部函数 a和b都是外函数的临时变量 def outer( a ): b = 10 # inner是内函数 def inner(): #在内函数中 用到了外函数的临时变量 print(a+b) # 外函数的返回值是内函数的引用 return inner if __name__ == '__main__': # 在这里我们调用外函数传入参数5 #此时外函数两个临时变量 a是5 b是10 ,并创建了内函数,然后把内函数的引用返回存给了demo # 外函数结束的时候发现内部函数将会用到自己的临时变量,这两个临时变量就不会释放,会绑定给这个内部函数。 # 我们调用内部函数,看一看内部函数是不是能使用外部函数的临时变量 # demo存了外函数的返回值,也就是inner函数的引用,这里相当于执行inner函数 demo1 = outer(5) demo2() # 15 demo2 = outer(7) demo2()#17
#闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域
from urllib.request import urlopen
def index(url):
#url=www.baidu.com如果把url写在这里的话,就把网址写死了,不能随意的捕获其他网址,由于作用域链的作用,
内部函数会向本层函数外寻找变量url,我们
可以把uel写在定义的函数()括号内。
def get():
return urlopen(url).read()
return get
baidu=index('http://www.baidu.com')
print(baidu().decode('utf-8'))
装饰器
装饰器就是闭包函数的一种应用场景 为了更好的了解装饰器,我们先了解下为什么要有装饰器?现实的开发环境要求,我们需要遵循一个开发的准则:开放封闭原则 对修改封闭 对扩展开放 1)什么是装饰器? 装饰他人的器具,本身可以是任意可调用对象,被装饰者也可以是任意可调用对象。 强调装饰器的原则: 1 不修改被装饰对象的源代码 2 不修改被装饰对象的调用方式,是因为面向的用户不管开发对源代码做了任何的修改,任然会保持自己原有的方式,进行程序的执行, 如果修改了用户的使用方式,则会造成很多的隐患,很多人会因为这一举动,而放弃使用程序。 装饰器的目标:在遵循1和2的前提下,为被装饰对象添加上新功能 2)装饰器的使用 无参装饰器 import time#导入的时间模块用于记录时间的需求 def timmer(func): def wrapper(*args,**kwargs): start_time=time.time() res=func(*args,**kwargs) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return res return wrapper @timmer def foo(): time.sleep(3) print('from foo') foo() 有参装饰器 用户登录认证: def auth(driver='file'): def auth2(func): def wrapper(*args,**kwargs): name=input("user: ") pwd=input("pwd: ") if driver == 'file': if name == 'joke' and pwd == '123': print('login successful') res=func(*args,**kwargs) return res elif driver == 'ldap': print('ldap') return wrapper return auth2 @auth(driver='file') def foo(name): print(name) foo('joke') 装饰器模板 def outter(func): def wrapper(*args,**kwargs): #在调用函数前加功能 res=func(*args,**kwargs) #调用被装饰的\也就是最原始的那个函数 #在调用函数后加功能 return res return wrapper 注意: 1.需要注意的是装饰器最多有三层 2.解释装饰器时@语法的时候是”自下而上运行“ 3.执行装饰器时装饰器内的那个wrapper函数时的是”自上而下“ 语法糖 什么是语法糖? 使用了”@”语法糖后,就不需要额外代码来给”被装饰函数”重新赋值了, 其实”@装饰器函数”的本质就是”被装饰函数 = 装饰器函数(被装饰函数#原始的被装饰函数的内存地址)”。 为什么用语法糖? 使用语法糖让代码简化,不需要重复在调用装饰器时,进行重复的赋值操作。 使用语法糖方式把装饰器函数名使用@装饰器名方式,放在被装饰函数的正上方,单独一行
多个装饰器装饰同一个函数
def wrapper1(func):
def inner():
print('wrapper1 ,before func')
func()
print('wrapper1 ,after func')
return inner
def wrapper2(func):
def inner():
print('wrapper2 ,before func')
func()
print('wrapper2 ,after func')
return inner
@wrapper2
@wrapper1
def f():
print('in f')
f()
迭代器
在了解Python的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list,set,dict comprehension)众多概念参杂在一起,难免让初学者一头雾水,我将用一篇文章试图将这些概念以及它们之间的关系捋清楚。

容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用in, not in关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特例,并不是所有的元素都放在内存,比如迭代器和生成器对象)在Python中,常见的容器对象有:
- list, deque, ….
- set, frozensets, ….
- dict, defaultdict, OrderedDict, Counter, ….
- tuple, namedtuple, …
- str
容器比较容易理解,因为你就可以把它看作是一个盒子、一栋房子、一个柜子,里面可以塞任何东西。从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器,比如 list,set,tuples都是容器对象。
可迭代对象(iterable)
刚才说过,很多容器都是可迭代对象,此外还有更多的对象同样也是可迭代对象,比如处于打开状态的files,sockets等等。但凡是可以返回一个迭代器的对象都可称之为可迭代对象。
>>> x = [1, 2, 3] >>> y = iter(x) >>> z = iter(x) >>> next(y) 1 >>> next(y) 2 >>> next(z) 1 >>> type(x) <class 'list'> >>> type(y) <class 'list_iterator'> 这里x是一个可迭代对象,可迭代对象和容器一样是一种通俗的叫法,并不是指某种具体的数据类型,list是可迭代对象,dict是可迭代对象,
set也是可迭代对象。y和z是两个独立的迭代器,迭代器内部持有一个状态,该状态用于记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。
迭代器有一种具体的迭代器类型,比如list_iterator,set_iterator。可迭代对象实现了__iter__方法,该方法返回一个迭代器对象。
运行代码:
x=[1,2,3]
for eleme in x:
..........
执行的过程可以参见下图
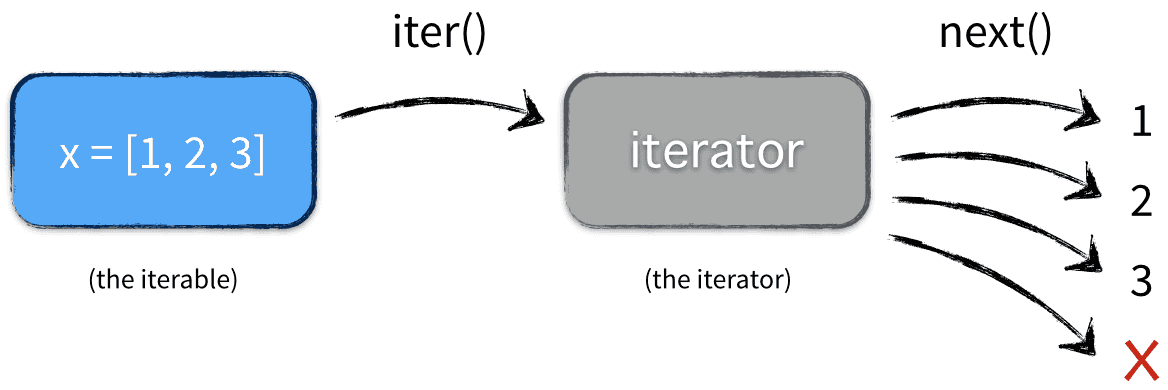
那什么是迭代器呢?
迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值。
它是一个带状态的对象,能在调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常,至于它们到底是如何实现的这并不重要。
from itertools import cycle colors = cycle(['red', 'white', 'blue']) print(next(colors))#第一次 print(next(colors))#第二次 print(next(colors))#第三次 第一次取值red后,colors列表‘结果’剩下 'white', 'blue'] 第二次取值white后,colors列表‘结果’剩下 ['blue'] 第三次取值blue后,colors列表的值已经取完 由于导入了 itertools模块,重复循环取值,第四次取值将又会重新开始进行取值。
每次调用next()方法的时候做两件事:
- 为下一次调用
next()方法修改状态 - 为当前这次调用生成返回结果
迭代器就像一个懒加载的工厂,等到有人需要的时候才给它生成值返回,没调用的时候就处于休眠状态等待下一次调用。
什么是可迭代对象?
可迭代对象指的是内置有__iter__方法的对象,即obj.__iter__,如下
'hello'.__iter__
(1,2,3).__iter__
[1,2,3].__iter__
{'a':1}.__iter__
{'a','b'}.__iter__
open('a.txt').__iter__
什么是迭代器对象?
可迭代对象执行obj.__iter__()得到的结果就是迭代器对象
而迭代器对象指的是即内置有__iter__又内置有__next__方法的对象
文件类型是迭代器对象
open('a.txt').__iter__()
open('a.txt').__next__()
注意: 迭代器对象一定是可迭代对象,而可迭代对象不一定是迭代器对象
迭代器对象的使用
dic={'a':1,'b':2,'c':3}
iter_dic=dic.__iter__() #得到迭代器对象,迭代器对象即有__iter__又有__next__,但是:迭代器.__iter__()得到的仍然是迭代器本身
iter_dic.__iter__() is iter_dic #True
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
print(iter_dic.__next__()) #等同于next(iter_dic)
# print(iter_dic.__next__()) #抛出异常StopIteration,或者说结束标志
#有了迭代器,我们就可以不依赖索引迭代取值了
iter_dic=dic.__iter__()
while 1:
try:
k=next(iter_dic)
print(dic[k])
except StopIteration:
break
#基于for循环,我们可以完全不再依赖索引去取值了
dic={'a':1,'b':2,'c':3}
for k in dic:
print(dic[k])
#for循环的工作原理
#1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic
#2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码
#3: 重复过程2,直到捕捉到异常StopIteration,结束循环
迭代器的特点
#优点: - 提供一种统一的、不依赖于索引的迭代方式 - 惰性计算,节省内存 #缺点: - 无法获取长度(只有在next完毕才知道到底有几个值) - 一次性的,只能往后走,不能往前退
生成器
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,
只需要一个yiled关键字。 生成器一定是迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。 def func(): print('====>first') yield 1 print('====>second') yield 2 print('====>third') yield 3 print('====>end') g=func() print(g) next(g) next(g) next(g) 输出结果 <generator object func at 0x01CAD420> ====>first ====>second ====>third
生成器
凡是函数体内存在yied关键,调用函数体不会执行函数体代码,会得到一个返回值,该返回值就是生成器对象
需要提示的是,生成器是一个特殊的迭代器
next的功能就是为了触发函数体的执行
yied可以让函数暂停在本次循环的位置,当再有next调用触发时,就会继续本次调用的位置继续往下执行,如此循环往复。
实例:生成器对象
def func():
print('first')
yield 1#1是自己定义的yied返回值
g=func()
print(g)
输出结果:
<generator object func at 0x004CE2A0>
实例:生成器对象调用
def func():
print('first')
yield 1#1是自己定义的yied返回值
print('second')
yield 2
print('third')
yield 3
g=func() #这里是一行代码都没有运行,如果想要触发生成器,就需要调用next的方法,g呢是一个函数,
# 也将会触发g函数体内的代码执行,
res1=next(g)#会触发函数的执行,直到碰到一个yied停下来,并且将yied后的值当作本次next的结果返回
# 迭代器调用next会返回一个值,可以将值赋值给一个变量res,res只是第一次迭代返回的值
# 过程:
#1.next防止调用
# 2.g函数体内代码执行,遇到第一个yied停止,并返回结果
res2=next(g)#第二次# 迭代,返回res2
自定义一个跟内置的range函数一样的生成器
def my_range(start,stop,step):
while start < stop:
yield start
start +=step
取值方式1,使用迭代器,next触发函数运行,一个个的取出,要多少取多少,不会浪费内存空间,
再大的数字也不会担心内存溢出,但是for循环取值的话,是一次性取出范围内所有的值,如果超过容器最大的范围
会造成内存溢出
g=my_range(1,10,1)
res1=next(g)
print(res1)
res2=next(g)
print(res2)
res3=next(g)
print(res3)
res4=next(g)
print(res4)
取值方式2,使用for循环
for i in my_range(1,100000000,1):
print(i)
列表,每个元素都存在列表里
g1=[x*x for x in range(10)]
print(g1)
生成器,是一个可以产生出列表元素的算法工具,在使用时,才能产生需要的列表元素。
使用方式:
1.直接使用next()进行调用,因为生成器本身就是一个迭代器,拥有__iter__和__next__内置方法
2.可以使用for循环把生成器内的元素遍历出来,for循环使用的就是__iter__和__next__同样的机制
g2 = (x*x for x in range(10))
print(g2)
输出对比
[p1, 1, 4, 9, 16, 25, 36, 49, 64, 81]
<generator object <genexpr> at 0x010EE2D0>
案例1
斐波那契数列:
def fib1(max):
n,a,b=p1,p1,1
while n < max:
print(b)
a,b=b,a+b
n = n + 1
return 'done'#函数的返回值,给出函数执行的最后的结果,可以不写,但是最好带上,以免产生不必要的麻烦
fib1(10)#调用函数,执行函数体内的代码
print(fib1.__name__)#函数名字
print(fib1)#函数的内存地址
改写成生成器的方式:
def fib2(max):
n,a,b=p1,p1,1
while n<max:
yield b
a,b=b,a+b
n = n + 1
return 'done'
f=fib2(10)#接收fib的生成器的返回值,yied的返回值定义的是b,下次next操作时是接着本次循环往后接续取值。
#第一次取值
res1=next(f)
print(res1)
#第二次取值
res2=next(f)
print(res2)
for i in fib2(6):
print(i)
案例2
def odd():
print('step 1')
yield 1 #第一次取值时,遇到yied中断,返回值为1
print('step 2')
yield(3) #第二次取值时,继续第一次中断的地方继续往下执行,
# 遇到第二个yied时中断,完成了第二次的取值,返回值3,依次进行
print('step 3')
yield(5)
o=odd()
next(o) #第一次
next(o) #第二次
next(o) #第三次
next(o)#第四次取值时因为超出了范围就报错
yied表达式形式的应用
x=yield #yied 的表达式形式
.send()#给yied传值
实例
针对yied表达式的使用,
第一步:
现使用next将函数停在yied的位置,
或者使用‘,send(None)’传一个none得值给yied,如果第一次没有传空值,就会有如下报错
def func(name):
print("%s往前跳"%name)
while True:
num=yield
print("%s往前跳了%s步"%(name,num))
f=func('joke')
输出结果
f.send(2)
f.send(2)
TypeError: can't send non-None value to a just-started generator
第二步:使用‘.send’给yied传值
第三步:使用next就可以使停在yied的位置的函数进行往下运行,while循环再次停在yied的位置
然后再‘.send’给yied传值,往复循环,就会源源不断的有值进去。
注:‘,send’本身就有next的功能,当传完值后,无需使用next,即可继续往下走
def func(name):
print("%s往前跳"%name)
while True:
num=yield
print("%s往前跳了%s步"%(name,num))
f=func('joke')
next(f)
f.send() #第一次传值,必须传空值none
f.send(2)
f.send(4)
总结:
1.yied只能在函数内使用
2.yied提供了一种自定义迭代器的解决方案
3.yied可以保存函数的暂停状态
4.yied与return
相同之处都可以返回值,值得类型和个数都没有限制
不同之处,yied可以返回多次值,return只能返回一次值
生成器表达式
l=[1,2,3,4]#列表生成式
l=(1,2,3,4)#生成器表达式,把[]换成()即可
实例
注:生成器对象在没有进行next调用时是没有进行yied执行的,即不使用不触发;不next不执行
生成器内部不存值,值是内部在每次调用时制造出来。
g=(i**2 for i in range(1,5) if i>3)
print(next(g))#停在第一次满足i>3后获得的i值处,i=4
print(next(g))#第二次进行yied操作,满足条件,停在i=5的地方
print(next(g))#第三次进行next操作的时候,已超过了范围内,就会报错,停止执行
注:为了不导致内存溢出,使用生成器
实例:
统计文件内的字符数
方式1
with open('今日内容','rt',encoding='utf-8') as f:
data=f.read()
print(len(data))
问题:所有文本的内容全部读取到内存,如果文件过大,将会导致内存不够使用,进而导致内存溢出
方式2
with open('今日内容','rt',encoding='utf-8') as f:
res=0
for line in f:
res +=len(line)
print(res)
问题:是没导致内存溢出,因为是一行一行的进行读取的,但是使用了for自己定义的循环,繁琐了很多
方式:3
with open('今日内容','rt',encoding='utf-8') as f:
print(sum(len(line) for line in f))
生成器表达式:(len(line) for line in f) #生成器对象
再使用sum内置函数求和sum()
面试关于生成器实例:
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test()
for n in [1,10]: #n=10
g=(add(n,i) for i in g)
分析:
第一次循环:
n=1,没有触发生成器对象的函数体代码,整个的函数的代码,将原封不动的传给g
g=(add(n,i) for i in test())
test中i=p1,1,2,3
n+i=10,11,12,13
g=(10,11,12,13)
第二次循环:
n=10时 next,触发了函数体里的代码
g=(add(n, i) for i in (add(n,i) for i in test()))
(add(n,i) for i in test())=(10,11,12,13)
n+i=20,21,22,23
g=(20,21,22,23)
print(n)
res=list(g)
迭代器1=(add(n,i) for i in test())
for i in 迭代器1: #i=next(迭代器1) i=11
add(n, i) #add(10,11)
A. res=[10,11,12,13]
B. res=[11,12,13,14]
C. res=[20,21,22,23]
D. res=[21,22,23,24]
答案:c
生成器在Python中是一个非常强大的编程结构,可以用更少地中间变量写流式代码,此外,相比其它容器对象它更能节省内存和CPU,当然它可以用更少的代码来实现相似的功能。
import time
def genrator_fun1():
a = 1
print('现在定义了a变量')
yield a
b = 2
print('现在又定义了b变量')
yield b
g1 = genrator_fun1()
print('g1 : ',g1) #打印g1可以发现g1就是一个生成器
print('-'*20) #我是华丽的分割线
print(next(g1))
time.sleep(1) #sleep一秒看清执行过程
print(next(g1))
输出结果
g1 : <generator object genrator_fun1 at 0x039846C0>
--------------------
现在定义了a变量
1
现在又定义了b变量
2
生成器有什么好处呢?就是不会一下子在内存中生成太多数据
def produce():
"""生产衣服"""
for i in range(2000000):
yield "生产了第%s件衣服"%i
product_g = produce()
print(product_g.__next__()) #要一件衣服
print(product_g.__next__()) #再要一件衣服
print(product_g.__next__()) #再要一件衣服
num = 0
for i in product_g: #要一批衣服,比如5件
print(i)
num +=1
if num == 5:
break
#到这里我们找工厂拿了8件衣服,我一共让我的生产函数(也就是produce生成器函数)生产2000000件衣服。
#剩下的还有很多衣服,我们可以一直拿,也可以放着等想拿的时候再拿
def produce():
"""生产衣服"""
for i in range(2000000):
yield "生产了第%s件衣服"%i
product_g = produce()
print(product_g.__next__()) #要一件衣服
print(product_g.__next__()) #再要一件衣服
输出结果
生产了第0件衣服
生产了第1件衣服
生成器本质也是一个迭代器,当我们一次次的索要产生的值时,,每次遇到yield就会停止一下,返回值和生成结果,再次索要下次的值时就会重复的进行相同的操作。
def produce():
"""生产衣服"""
for i in range(2000000):
yield "生产了第%s件衣服"%i
product_g = produce()
print(product_g.__next__()) #要一件衣服
# print(product_g.__next__()) #再要一件衣服
# print(product_g.__next__()) #再要一件衣服
# print(product_g.__next__()) #再要一件衣服
# print(product_g.__next__()) #再要一件衣服
# print(product_g.__next__()) #再要一件衣服
# print(product_g.__next__()) #再要一件衣服
num = 0
for i in product_g: #要一批衣服,比如5件
print(i)
num +=1
if num == 5:
break
输出结果
生产了第0件衣服
生产了第1件衣服
生产了第2件衣服
生产了第3件衣服
生产了第4件衣服
生产了第5件衣服
各种推导式
最简单的列表推导式和生成器表达式。但是除此之外,其实还有字典推导式、集合推导式等等。下面是一个以列表推导式为例的推导式详细格式,同样适用于其他推导式。 variable = [out_exp_res for out_exp in input_list if out_exp == 2] out_exp_res: 列表生成元素表达式,可以是有返回值的函数。 for out_exp in input_list: 迭代input_list将out_exp传入out_exp_res表达式中。 if out_exp == 2: 根据条件过滤哪些值可以。
三元表达式
三元表达式实现的效果就是:条件成立的情况下返回一个值,不成立的情况下返回另外一种值
语法格式:
条件成立情况下返回的值 if 条件 else 条件不成立情况下返回的值 #这一行代码就是一个三元表达式
自身就是一个返回值,可以使用res=三元表达式,进行返回值接收。
表达式 if 条件 else 表达式2
实例
name=input('your name: ').strip()
res="正确" if name == 'joke' else "错误"
print(res)
x=3 y=4res='x大于y'ifx > yelse'x小于y'#三元表达式
列表推导式
定义
列表生成式就是一个用来生成列表的特定语法形式的表达式。就是生成一个新的列表,以一种简便,快捷的方式实现
注
为了保持代码的简洁,一般情况下不建议进行2层或者更多的for循环嵌套。
应用场景
其实列表生成式也是Python中的一种“语法糖”,也就是说列表生成式应该是Python提供的一种生成列表
的简洁形式,应用列表生成式可以快速生成一个新的list。它最主要的应用场景是:根据已存在的可迭代
对象推导出一个新的list。
语法格式:
[exp for iter_var in iterable if_exp]
exp-》以表达式,或以最终实现需求的结果新式进行重新定义,目的是实现对循环出来的iter_var的值进行计算,然后生成新的列表
for iter_var in iterable-》是从iterable列表中循环遍历,每个值
if_exp-》是一个限定条件,如果新生成的list列表中过滤掉不想要的元素,需要写上过滤条件
如果存在过滤条件,每次遍历出值时,就会进行一次if条件的判定。
案例:
1.无过滤条件
list01 = [2*x+1 for x in range(3, 11)]
2.有过滤条件
L = [3, 7, 11, 14,19, 33, 26, 57, 99]
list02 = [x for x in L if x > 20]
#1、示例
egg_list=[]
for i in range(10):
egg_list.append('鸡蛋%s' %i)
egg_list=['鸡蛋%s' %i for i in range(10)]
#2、语法
[expression for item1 in iterable1 if condition1
for item2 in iterable2 if condition2
...
for itemN in iterableN if conditionN
]
类似于
res=[]
for item1 in iterable1:
if condition1:
for item2 in iterable2:
if condition2
...
for itemN in iterableN:
if conditionN:
res.append(expression)
例一:30以内所有能被3整除的数 multiples = [i for i in range(30) if i % 3 is 0] print(multiples) # Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27] 例二:30以内所有能被3整除的数的平方 def squared(x): return x*x multiples = [squared(i) for i in range(30) if i % 3 is 0] print(multiples) 例三:找到嵌套列表中名字含有两个‘e’的所有名字 names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] print([name_2 for name_1 in names for name_2 in name_1 if name_2.count('e') >= 2]) # 注意遍历顺序,这是实现的关键 输出结果 ['Jefferson', 'Wesley', 'Steven', 'Jennifer']
字典推导式
定义
字典生成式就是一个用来生成字典的特定语法形式的表达式。
语法格式
keys=[] values=[]
方式1
{k:v for k,v in zip(keys,values)} if 判定语句}
方式2 枚举函数形式
{k:vals[i] for i,k in enumerate(keys)if 判定语句}
keys-》所需键的列表
values-》所需值得列表
k-》是取出键时赋值的变量
v-》是取出值时赋值的变量
for k,v in -》使用for循环依次遍历出对应的 键-值
if 判定语句-》按照if条件进行过滤生成所需要的字典
实例
keys=['name','age','sex']
vals=['egon',18,'male']
1.无限定条件
dic={k:vals[i] for i,k in enumerate(keys)}
print(dic)
输出结果
{'name': 'egon', 'age': 18, 'sex': 'male'}
2.有限定条件
dic={k:vals[i] for i,k in enumerate(keys) if i > 0}
print(dic)
例一:将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
例二:合并大小写对应的value值,将k统一成小写
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
输出结果
{'a': 17, 'b': 34, 'z': 3}
集合推导式
例:计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])
枚举函数
enumerate() 函数:
定义
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
同时列出数据和数据下标,一般用在 for 循环当中。
语法格式
enumerate(sequence, [start=0])
sequence -》 一个序列、迭代器或其他支持迭代对象。
start -》 下标起始位置。
实例
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 小标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
生成器表达式
#列表推导式 l=[i**2 for i in range(1,6) if i > 3] print(l) # 生成器表达式 g=(i**2 for i in range(1,6) if i > 3) print(g) print(next(g)) print(next(g)) print(next(g)) 总结: 1.把列表解析的[]换成()得到的就是生成器表达式 2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存 生成器的特点: 1.延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。 #列表推导式 sum([i for i in range(100000000)])#内存占用大,机器容易卡死 #生成器表达式 sum(i for i in range(100000000))#几乎不占内存 2.提高代码可读性
题目:
1.自定义生成器实现range功能
def my_range(start, stop, step):
yield start
while start < stop:
start += step
2、文件shopping.txt内容如下
mac, 2000, 3
lenovo, 3000, 10
tesla, 1000000, 10
chicken, 200, 1
求总共花了多少钱?
total=0
with open('shopping.txt','r',encoding='utf-8') as f:
lines=f.readlines()#获取文本里所有的行信息,以字符串的形式,每行进行存储
for i in range(len(lines)):
line_list = lines[i].strip('\n').split(',')#循环出lines列表里的所有的元素,并使用除去和分割转化成line_list列表形式
total=total+ int(line_list[1])*int(line_list[2])
print(total)
输出结果:
10036200
打印出所有的商品信息,格式为
[{'name': 'xxx', 'price': '3333', 'count': 3}, ....]
keys=['name','price','count']
l=[]
with open('shopping.txt','r',encoding='utf-8') as f:
lines=f.readlines()#获取文本里所有的行信息,以字符串的形式,每行进行存储
for i in range(len(lines)):
line_list = lines[i].strip('\n').split(',')
dic={k:line_list[i] for i,k in enumerate(keys)}
l.append(dic)
print(l)
输出结果
[{'name': 'mac', 'price': '2000', 'count': '3'}, {'name': 'lenovo', 'price': '3000', 'count': '10'},
{'name': 'tesla', 'price': '1000000', 'count': '10'}, {'name': 'chicken', 'price': '200', 'count': '1'}]
求单价大于10000的商品信息,格式同上
keys=['name','price','count']
l=[]
with open('shopping.txt','r',encoding='utf-8') as f:
lines=f.readlines()#获取文本里所有的行信息,以字符串的形式,每行进行存储
for i in range(len(lines)):
line_list = lines[i].strip('\n').split(',')
if int(line_list[1]) > 10000:
dic={k:line_list[i] for i,k in enumerate(keys)}
l.append(dic)
print(l)
# 3、文件内容如下, 标题为: 姓名, 性别, 年纪, 薪资
# egon male 18 3000
# alex male 38 30000
# wupeiqi female 28 20000
# yuanhao female 28 10000
# 要求:
#1.从文件中取出每一条记录放入列表中
#2.列表的每个元素都是{'name': 'egon', 'sex': 'male', 'age': 18, 'salary': 3000}的形式
#3 根据1得到的列表,取出薪资最高的人的信息
#4 根据1得到的列表,取出最年轻的人的信息
#5 根据1得到的列表,将每个人的信息中的名字映射成首字母大写的形式
#6 根据1得到的列表,过滤掉名字以a开头的人的信息
test=[]
l=[]
keys=['name','sex','age','salary']
with open('user','r',encoding='utf-8') as f:
lines=f.readlines()
for i in range(len(lines)):
line_list=lines[i].strip('\n').split(' ')
# print(line_list)
# # 输出结果:
# ['egon', 'male', '18', '3000']
# ['alex', 'male', '38', '30000']
# ['wupeiqi', 'female', '28', '20000']
# ['yuanhao', 'female', '28', '10000']
dic={k:line_list[i] for i,k in enumerate(keys)}
l.append(dic)
# res1=max(l,key=lambda item:int(item['salary']))#打印出工资最多的人的信息
# print(res1)#打印出工资最多的人的信息
# res2=min(l,key=lambda item:int(item['age']))#
# print(res2)#打印年龄最小的人的信息
# res3=filter(lambda name:name.,for item in l)
# for item in l:
# test.append(item['name'])
res3 = filter(lambda name:str(name['name']).startswith('a'),l)
print(list(res3))#打印出过滤 首字母是a的人员信息
# print(l)
# 输出结果
# [{'name': 'egon', 'sex': 'male', 'age': '18', 'salary': '3000'},
# {'name': 'alex', 'sex': 'male', 'age': '38', 'salary': '30000'},
# {'name': 'wupeiqi', 'sex': 'female', 'age': '28', 'salary': '20000'},
# {'name': 'yuanhao', 'sex': 'female', 'age': '28', 'salary': '10000'}]
内置函数
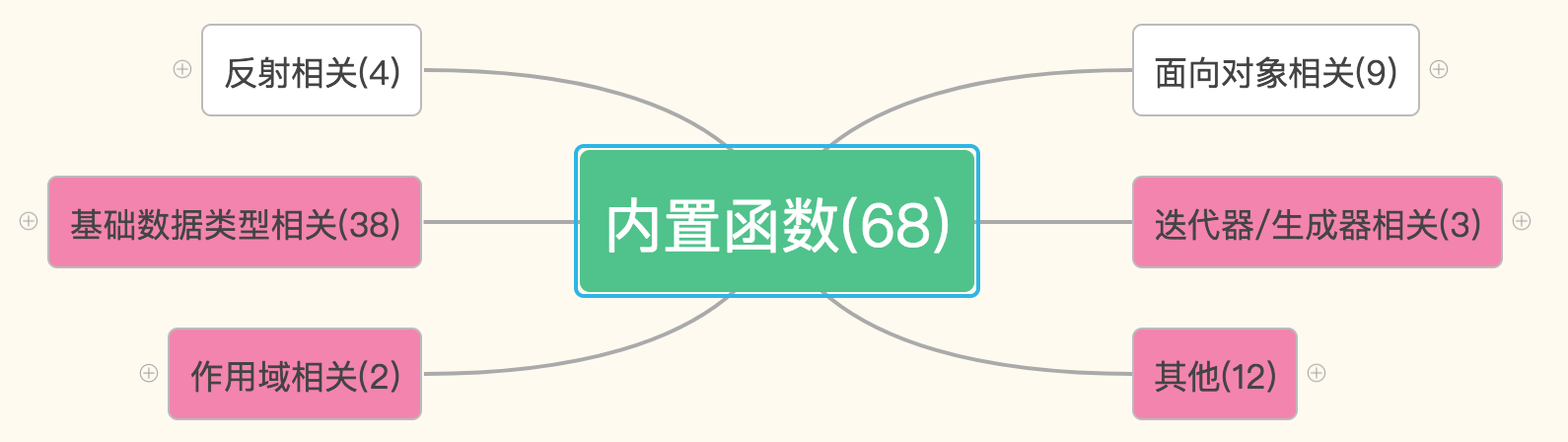
python版本3.6.2,现在python一共为我们提供了68个内置函数。它们就是python提供给你直接可以拿来使用的所有函数。
基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典


匿名函数
1 匿名函数 定义:即不再使用 def 语句这样标准的形式定义一个函数。python是使用lambda来创建匿名函数 lambda知识一个表达式,比def定义的函数简单很多 语法格式 lambda [arg1 [,arg2,.....argn]]:expression args---》变量 expression--》表达式 使用场景 1.使用匿名函数省去了定义函数的过程,快速方便 2.遇到不再重复使用的函数,就不需要按照def标准格式重新定义函数,直接使用lambda以一种行代码的形式 让代码更加精简。 3.lambda定义一些简单的函数,会更加易读 实例 def sum2(x,y): return x+y # print(lambda x,y:x+y) 输出结果 <function <lambda> at 0x02CC54F8> 输出的是lambda的内存地址,类似def定义的一个func的函数名,在func函数名前没加不加()时, 输出的就是函数的内存地址 # print((lambda x,y:x+y)(1,2)) 输出结果 3 #在匿名函数的外面加上了()代表在调用该函数,所以执行了函数内部的代码 2 为何要用: 用于仅仅临时使用一次的场景,没有重复使用的需求 def sum2(x,y): return x+y # lambda x,y:x+y#匿名函数 (lambda x,y:x+y)(1,2)#匿名函数 匿名函数与内置函数结合使用 # max,min,sorted,map,filter,reduce
re模块和正则表达式
正则表达式
定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
一说规则我已经知道你很晕了,现在就让我们先来看一些实际的应用。在线测试工具 http://tool.chinaz.com/regex/
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
正则 |
待匹配字符 |
匹配 |
说明 |
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符 |
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
字符:
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W |
匹配非字母或数字或下划线 |
| \D |
匹配非数字 |
| \S |
匹配非空白符 |
| a|b |
匹配字符a或字符b |
| () |
匹配括号内的表达式,也表示一个组 |
| [...] |
匹配字符组中的字符 |
| [^...] |
匹配除了字符组中字符的所有字符 |
量词:
量词 |
用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
. ^ $
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
* + ? { }
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李 李 李 |
惰性匹配 |
字符集[][^]
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李[杰莲英二棍子]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李莲英和李二棍子 |
李杰 |
表示匹配一个不是"和"的字符任意次 |
| [\d] | 456bdha3 |
4 |
表示匹配任意一个数字,匹配到4个结果 |
| [\d]+ | 456bdha3 |
456 |
表示匹配任意个数字,匹配到2个结果 |
分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部🈶️数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
|
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成'\\d',那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r'\d'这个概念,此时的正则是r'\\d'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \d | \d | False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配 |
| \\d | \d | True |
转义\之后变成\\,即可匹配 |
| "\\\\d" | '\\d' | True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\d' | r'\d' | True |
在字符串之前加r,让整个字符串不转义 |
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' |
<script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
re模块下的常用方法
import re 在python中导入re模块 查找方法: 1)re.findall #函数会在字符串内查找模式匹配,找到所有满足匹配信息的对象 ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] 2)re.search# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None,调用group会报错。 ret = re.search('a', 'eva egon yuan').group() print(ret) #结果 : 'a' 3)re.match是必须从头开始匹配,如果正则规则从头可以匹配上,通过调用group()方法得到匹配的字符串,如果字符串从头开始没有匹配上,则返回None,调用group会报错。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : 'a' 其他方法: re.split分割 ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] re.sub替换 ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) re.compile正则对象,如果同一条正则表达式重复的使用,就需要将此规则封装成一个正则对象,进行重复的调用。 obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 re.finditer#finditer返回一个存放匹配结果的迭代器 ret = re.finditer('\d', 'ds3sy4784a') print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果 特别说明: 一、分组() 1.无名分组 分组就是用一对圆括号“()”括起来的正则表达式,匹配出的内容就表示一个分组。 按照上面的分组匹配以后,我们就可以拿到我们想拿到的字串,但是如果我们正则表达式中括号比较多,那我们在拿我们想要的字串时,要去挨个数我们想要的字串时第几个括号,这样会很麻烦, 这个时候Python又引入了另一种分组,那就是命名分组,上面的叫无名分组。 2.命名分组 命名分组就是给具有默认分组编号的组另外再给一个别名。 命名分组的语法格式如下: (?P<name>正则表达式)#name是一个合法的标识符 如:提取字符串中的ip地址 >>> s = "ip='230.192.168.78',version='1.0.0'" >>> res=re.search(r"ip='(?P<ip>\d+\.\d+\.\d+\.\d+).*", s) >>> res.group('ip')#通过命名分组引用分组 '230.192.168.78' 二、向后引用 正则表达式中,放在圆括号“()”中的表示是一个组。然后你可以对整个组使用一些正则操作,例如重复操作符。 要注意的是,只有圆括号”()”才能用于形成组。”“用于定义字符集。”{}”用于定义重复操作。 当用”()”定义了一个正则表达式组后,正则引擎则会把被匹配的组按照顺序编号,存入缓存。这样我们想在后面对已经匹配过的内容进行引用时,就可以用”\数字”的方式或者是通过命名分组进行”(?P=name)“进行引用。\1表示引用第一个分组,\2引用第二个分组,以此类推,\n引用第n个组。而\0则引用整个被匹配的正则表达式本身。这些引用都必须是在正则表达式中才有效,用于匹配一些重复的字符串。 如: #通过命名分组进行后向引用 >>> re.search(r'(?P<name>go)\s+(?P=name)\s+(?P=name)', 'go go go').group('name') 'go' #通过默认分组编号进行后向引用 >>> re.search(r'(go)\s+\1\s+\1', 'go go go').group() 'go go go' 交换字符串的位置 >>> s = 'abc.xyz' >>> re.sub(r'(.*)\.(.*)', r'\2.\1', s) 'xyz.abc' 注意: 1 findall的优先级查询:(?: )中?: 是取消分组优先 import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com'] 2 split的优先级查询 import re ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
