
内容:
1. 开启进程的两种方式(*****)
2. 进程对象的join方法(*****)
3. 进程之间内存空间隔离(*****)
4. 进程对象其他相关的属性或方法
5. 僵尸进程与孤儿进程
6. 守护进程
7. 互斥锁
1. 开启进程的两种方式(*****)
2. 进程对象的join方法(*****)
3. 进程之间内存空间隔离(*****)
4. 进程对象其他相关的属性或方法
5. 僵尸进程与孤儿进程
6. 守护进程
7. 互斥锁
进程的理论:
1 什么是进程
进程指的是一个正在进行/运行的程序,进程是用来描述程序执行过程的虚拟概念
进程vs程序
程序:一堆代码
进程:程序的执行的过程
进程的概念起源于操作系统,进程是操作系统最核心的概念,操作系统其它所有的概念都是围绕进程来
操作系统理论:
1. 操作系统是什么?
操作系统是一个协调\管理\控制计算机硬件资源与应用软件资源的一段控制程序
有两大功能:
1. 将复杂的硬件操作封装成简单的接口给应用程序或者用户去使用
2. 将多个进程对硬件的竞争变得有序
操作系统发展史
并发: 多个任务看起来是同时运行的
串行:一个任务完完整整地运行完毕,才能运行下一个任务
多道技术:(复用=>共享/共用)
1. 空间上的复用:多个任务复用内存空间
2. 时间上的复用:多个任务复用cpu的时间
1. 一个任务占用cpu时间过长会被操作系统强行剥夺走cpu的执行权限:比起串行执行反而会降低效率
2. 一个任务遇到io操作也会被操作系统强行剥夺走cpu的执行权限:比起串行执行可以提升效率
Windows系统:子进程不仅完全copy父进程的数据,还有会造一些新的数据
Linux系统:子进程和父进程的初始状态数据是完全相同
一旦进程运行起来,子进程和父进程之间内存之间互相隔离,互不影响
应用程序发起开启子进程的请求,操作系统开启子进程,在操作系统眼中.
所有的进程地位都是相同的
进程指的是一个正在进行/运行的程序,进程是用来描述程序执行过程的虚拟概念
进程vs程序
程序:一堆代码
进程:程序的执行的过程
进程的概念起源于操作系统,进程是操作系统最核心的概念,操作系统其它所有的概念都是围绕进程来
操作系统理论:
1. 操作系统是什么?
操作系统是一个协调\管理\控制计算机硬件资源与应用软件资源的一段控制程序
有两大功能:
1. 将复杂的硬件操作封装成简单的接口给应用程序或者用户去使用
2. 将多个进程对硬件的竞争变得有序
操作系统发展史
并发: 多个任务看起来是同时运行的
串行:一个任务完完整整地运行完毕,才能运行下一个任务
多道技术:(复用=>共享/共用)
1. 空间上的复用:多个任务复用内存空间
2. 时间上的复用:多个任务复用cpu的时间
1. 一个任务占用cpu时间过长会被操作系统强行剥夺走cpu的执行权限:比起串行执行反而会降低效率
2. 一个任务遇到io操作也会被操作系统强行剥夺走cpu的执行权限:比起串行执行可以提升效率
Windows系统:子进程不仅完全copy父进程的数据,还有会造一些新的数据
Linux系统:子进程和父进程的初始状态数据是完全相同
一旦进程运行起来,子进程和父进程之间内存之间互相隔离,互不影响
应用程序发起开启子进程的请求,操作系统开启子进程,在操作系统眼中.
所有的进程地位都是相同的
进程的三种状态:
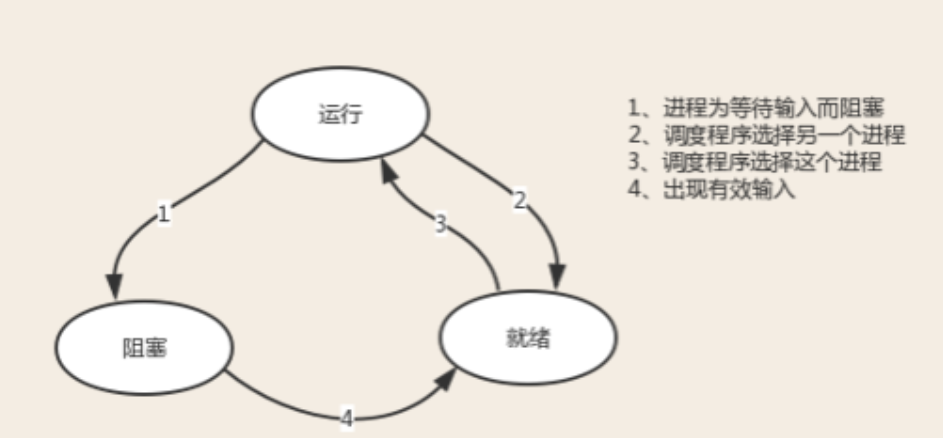
运行态:程序申请到cpu执行权限
阻塞态:执行IO操作时
就绪态:占用cpu时间过长,被操作系统收回或者被其它优先级更高的进程
将cpu抢走
阻塞态只能先进入就绪态,就绪态可以随时进入运行态
我们只能控制阻塞态
程序的效率想要更高,尽量避免IO操作
阻塞态:执行IO操作时
就绪态:占用cpu时间过长,被操作系统收回或者被其它优先级更高的进程
将cpu抢走
阻塞态只能先进入就绪态,就绪态可以随时进入运行态
我们只能控制阻塞态
程序的效率想要更高,尽量避免IO操作
开启子进程:
有两种方法,开启进程,
①使用Process包直接产生进程实例。
②使用类的继承,添加绑定方法,进行进程类的实例化
开启子进程的方式一:
导入Process模块,通过process类实例化出一个对象,调用run
方法开启子进程
from multiprocessing import Process
import time
def task(name):
print('%s is running' %name)
time.sleep(3)
print('%s is done' %name)
# 在windows系统上,开启子进程的操作必须放到if __name__ == '__main__'的子代码中
if __name__ == '__main__':
p=Process(target=task,args=('egon',))
#Process(target=task,kwargs={'name':'egon'})
p.start() # 只是向操作系统发送了一个开启子进程的信号
print('主')
结果:
主
egon is running
egon is done
开启子进程的方式二:
重写Process类的run方法,调用重写的Myprocess类实例化出一个对象,通过对象调用run方法开启子进程
from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
print('%s is running' %self.name)
time.sleep(3)
print('%s is done' %self.name)
if __name__ == '__main__':
p=Myprocess('egon')
p.start() # 只是向操作系统发送了一个开启子进程的信号
print('主')
结果:
主
egon is running
egon is done
开启子进程的方式一:
导入Process模块,通过process类实例化出一个对象,调用run
方法开启子进程
from multiprocessing import Process
import time
def task(name):
print('%s is running' %name)
time.sleep(3)
print('%s is done' %name)
# 在windows系统上,开启子进程的操作必须放到if __name__ == '__main__'的子代码中
if __name__ == '__main__':
p=Process(target=task,args=('egon',))
#Process(target=task,kwargs={'name':'egon'})
p.start() # 只是向操作系统发送了一个开启子进程的信号
print('主')
结果:
主
egon is running
egon is done
开启子进程的方式二:
重写Process类的run方法,调用重写的Myprocess类实例化出一个对象,通过对象调用run方法开启子进程
from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
print('%s is running' %self.name)
time.sleep(3)
print('%s is done' %self.name)
if __name__ == '__main__':
p=Myprocess('egon')
p.start() # 只是向操作系统发送了一个开启子进程的信号
print('主')
结果:
主
egon is running
egon is done
进程对象的join方法:
join:让主进程在原地等待,等待子进程运行完毕,不会影响子进程的执行
例:
from multiprocessing import Process
import time
def task(name,i):
print(' %s is running' %name)
time.sleep(i)
print('%s is done' %name)
if __name__ == '__main__':
start_time=time.time()
l=[]
for i in range(1,4):
obj=Process(target=task,args=('peanut%s'%i,i))
l.append(obj)
obj.start()
for p in l:
p.join()#遇到join就返回执行子进程代码,直到都执行完毕后,再最后执行join下代码
print(time.time()-start_time)
print('master')
运行结果:
peanut1 is running
peanut3 is running
peanut2 is running
peanut1 is done
peanut2 is done
peanut3 is done
3.507101058959961
master
例:
from multiprocessing import Process
import time
def task(name,i):
print(' %s is running' %name)
time.sleep(i)
print('%s is done' %name)
if __name__ == '__main__':
start_time=time.time()
l=[]
for i in range(1,4):
obj=Process(target=task,args=('peanut%s'%i,i))
l.append(obj)
obj.start()
for p in l:
p.join()#遇到join就返回执行子进程代码,直到都执行完毕后,再最后执行join下代码
print(time.time()-start_time)
print('master')
运行结果:
peanut1 is running
peanut3 is running
peanut2 is running
peanut1 is done
peanut2 is done
peanut3 is done
3.507101058959961
master
进程之间内存空间互相隔离:
验证方法:定义一个全局变量,在子进程中通过global方法修改变量的值,
在子进程和父进程中输出变量的值来验证
from multiprocessing import Process
n=111
def task():
global n
n=1
print('son:',n)
if __name__ == '__main__':
p=Process(target=task)
p.start()
p.join()
print(n)
输出结果:
son: 1
111
在子进程和父进程中输出变量的值来验证
from multiprocessing import Process
n=111
def task():
global n
n=1
print('son:',n)
if __name__ == '__main__':
p=Process(target=task)
p.start()
p.join()
print(n)
输出结果:
son: 1
111
进程对象其它相关的属性或方法
1.导入current_process模块,调用其下的pid属性,得到进程的pid号
from multiprocessing import Process,current_process
import time
def task():
print('%s is running' %current_process().pid)
time.sleep(3)
print('%s is done' %current_process().pid)
if __name__ == '__main__':
p=Process(target=task)
p.start()
print('主',current_process().pid)
结果:
主 5808
9040 is running
9040 is done
2.导入os模块,调用其下的getpid和getppid方法,得到子进程及其父进程的
pid号
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is run 爹是:%s' %(os.getpid(),os.getppid()))
time.sleep(30)
print('%s is done 爹是:%s' %(os.getpid(),os.getppid()))
if __name__ == '__main__':
p=Process(target=task)
p.start()
print('主:%s 主他爹:%s' %(os.getpid(),os.getppid()))
结果:
主:12848 主他爹:9208
13284 is run 爹是:12848
13284 is done 爹是:12848
3.Process模块下有terminate方法,用于杀死子进程
is_alive方法 判断子进程存活状态(返回True/False)
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is run 爹是:%s' %(os.getpid(),os.getppid()))
time.sleep(3)
print(
from multiprocessing import Process,current_process
import time
def task():
print('%s is running' %current_process().pid)
time.sleep(3)
print('%s is done' %current_process().pid)
if __name__ == '__main__':
p=Process(target=task)
p.start()
print('主',current_process().pid)
结果:
主 5808
9040 is running
9040 is done
2.导入os模块,调用其下的getpid和getppid方法,得到子进程及其父进程的
pid号
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is run 爹是:%s' %(os.getpid(),os.getppid()))
time.sleep(30)
print('%s is done 爹是:%s' %(os.getpid(),os.getppid()))
if __name__ == '__main__':
p=Process(target=task)
p.start()
print('主:%s 主他爹:%s' %(os.getpid(),os.getppid()))
结果:
主:12848 主他爹:9208
13284 is run 爹是:12848
13284 is done 爹是:12848
3.Process模块下有terminate方法,用于杀死子进程
is_alive方法 判断子进程存活状态(返回True/False)
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is run 爹是:%s' %(os.getpid(),os.getppid()))
time.sleep(3)
print(