
DOM10-1节点层次
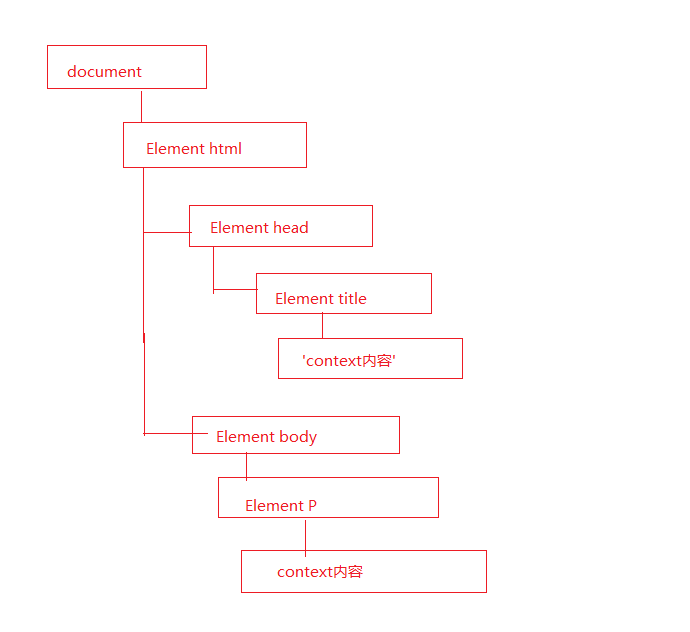
DOM(问的那个对象模型)是针对HTML和XML文档的API。DOM描绘了一个层次化的节点树,允许开发人员添加、移除和修改页面的一部分。
每个节点都拥有各自的特点、数据和方法,另外和其他节点也存在某种关系。
文档元素是文档的最外层元素,文档中的所有元素都包含在文档元素中,每个文档只有一个文档元素。
在HTML中文档元素始终是<html>
在XML中没有预定义的元素,因此任何元素都可能成为文档元素
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<p>内容</p>
</body>
</html>
NODE 类型
Dom定义了一个接口,该接口将由DOM中的所有节点类型实现
每个节点都有一个nodeType属性
12个类型用12个数值常量来表示
const unsigned short ELEMENT_NODE = 1; 元素节点 const unsigned short ATTRIBUTE_NODE = 2; 属性节点 const unsigned short TEXT_NODE = 3; 文本节点 const unsigned short CDATA_SECTION_NODE = 4; CDATA 区段 const unsigned short ENTITY_REFERENCE_NODE = 5; 实体引用元素 const unsigned short ENTITY_NODE = 6; 实体 const unsigned short PROCESSING_INSTRUCTION_NODE = 7; 表示处理指令 const unsigned short COMMENT_NODE = 8; 注释节点 const unsigned short DOCUMENT_NODE = 9; 最外层的Root element,包括所有其它节点 const unsigned short DOCUMENT_TYPE_NODE = 10; <!DOCTYPE………..> const unsigned short DOCUMENT_FRAGMENT_NODE = 11; 文档碎片节点 const unsigned short NOTATION_NODE = 12; DTD 中声明的符号节点
所以调用每一个节点的nodeType可以返回相应的节点的属性值
通过比较可以知道节点的类型
if (someNode.nodeType == Node.ElEMENT_NODE) { console.log('Node is an element'); }
但是IE没有公开Node类型的构造函数,所以上一种方法不支持IE
所以通用的做法是
if (someNode.nodeType == 1) { console.log('Node is an element'); }
1、nodeName和nodeValue属性
在使用这两个值之前先检测一下节点的类型
if (someNode.nodeType == 1) { var value = someNode.nodeName; }
如果是元素节点,就保存nodeName的值,nodeName中始终保存着元素的标签名,nodeValue中为null
每一个节点都有childNodes 属性,其中保存着NodeList对象,NodeList对象是类数组对象,用于保存一组有序的节点,此对象有length属性但是不是Array的实例
childNodes属性只能返回下一层的同级节点,但是不能返回所有子节点的个数
function convertToArray(nodes){ var array = null; try { /* array = Array.prototype.slice.call(nodes,0); */ array = [].slice.call(nodes,0);//兼容非IE类 } catch (ex) { array = []; /* 因为nodes是动态的,所以不能写为 for (var i=0 ;i<nodes.length ;i++ )会陷入死循环 */ for (var i=0,len=nodes.length;i<len ;i++ ) { array.push(nodes[i]); } } return array; }
每一个节点都有parentNode属性,该属性指向文档书中的父节点。
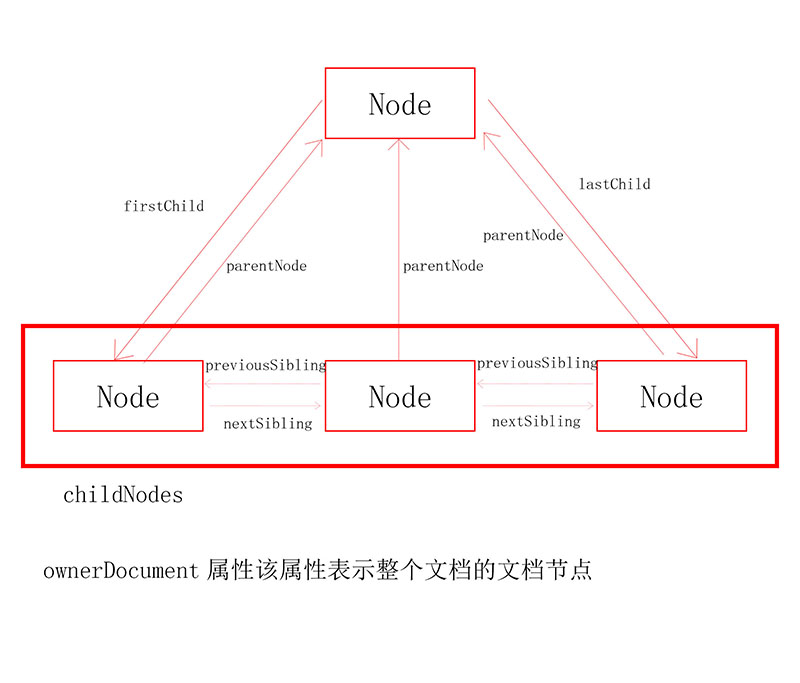
有三种方法可以判断当前节点是否有子节点。
- node.firstChild !== null
- node.childNodes.length > 0
- node.hasChildNodes()
3.节点操作
IE9以前不会把所有的空格作为一个节点,标准浏览器会把空格作为一个节点
因为关系指针都是只读的,所以DOM提供了一些操作节点的方法。
appendChild() 用于向childNodes列表的末尾添加一个节点。
childNodes和父节点和以前的最后一个节点关系指针都会发生相应的更新
<body>
<ul><li>klkx1</li><li>klkx2</li></ul>
<script>
var oUl = document.getElementsByTagName('ul')[0];
var oLi = document.createElement('li');
oLi.innerText = 'klkx3';
console.log(oUl.lastChild);
var s1 = oUl.appendChild(oLi);
console.log(s1);
console.log(oUl.lastChild);
</script>
</body>
如果要插入的节点是已经存在的节点,那结果就是该节点从原来的位置转移到新的位置,但是不会重新拷贝这个节点
<body>
<ul><li>klkx1</li><li>klkx2</li></ul><ul><li>klkx3</li><li>klkx4</li></ul>
<script>
var oUl1 = document.getElementsByTagName('ul')[0];
var oUl2 = document.getElementsByTagName('ul')[1];
setTimeout(function(){
var s1 = oUl1.appendChild( oUl2 );
console.log(s1);
},3000);
</script>
</body>
任何DOM节点也不能同时出现在文档的多个位置
<body>
<ul><li>klkx1</li><li>klkx2</li></ul>
<script>
var oUl1 = document.getElementsByTagName('ul')[0];
setTimeout(function(){
var s1 = oUl1.appendChild( oUl1.firstChild );
console.log(s1);
},3000);
console.log(oUl1);
</script>
</body>
insertbefore()方法:
returnNode/*返回插入的节点*/ = parentNode/*插入的父级节点*/.insertbefore(newNode/*要插入的节点*/,null/*坐标节点*/);
如果null,则插入到最后的位置
插入到坐标节点的前辈前边
<body>
<ul><li>klkx1</li><li>klkx2</li></ul>
<script>
var oUl1 = document.getElementsByTagName('ul')[0];
var aLi = oUl1.getElementsByTagName('li');
var oLi = document.createElement('li');
oLi.innerText = 'klkx3';
setTimeout(function(){
var s1 = oUl1.insertBefore( oLi,oUl1.lastChild );
console.log(s1);
},3000);
console.log(oUl1);
</script>
</body>
replaceChild()替换一个节点
returnNode/*返回替换的节点*/ = parentNode/*操作的父级节点*/.replaceChild(newNode/*新节点*/,oldNode/*要替换节点*/);
如果节点已经存在,存在的的节点会替换老节点的位置
<body>
<ul><li>klkx1</li><li>klkx2</li></ul><ul><li>klkx3</li><li>klkx4</li></ul>
<script>
var oUl1 = document.getElementsByTagName('ul')[0];
var oUl2 = document.getElementsByTagName('ul')[1];
var aLi = oUl1.getElementsByTagName('li');
setTimeout(function(){
var s1 = oUl1.replaceChild( oUl2,aLi[1] );
console.log(s1);
},3000);
console.log(oUl1);
</script>
</body>
如果只想移除不想替换可以用removeChild()
这个方法接受一个参数,即要移除的节点,被移除的节点将被称为返回值
虽然在文档中还有这些节点存在,但是没有这些节点的位置
上边的几个方法都是操作的某个节点的子节点,必须先取得子节点的父节点,如果在不支持子节点上调用,会出现错误
cloneNode()
方法:node.cloneNode(Boolean)
参数可以是
true 复制整个节点和属性和子孙节点
false 只复制当前节点不复制属性
但是复制的节点没有所属关系,只能通过appendChild()和insertBefore()和replaceChild()进行后续的操作
<body>
<div><div>klkx1<div>klkx2</div></div></div>
<script>
var oDiv = document.getElementsByTagName('div')[0];
var s1 = oDiv.childNodes[0].cloneNode(true);
console.log(s1.childNodes.length);//2
var s2 = oDiv.childNodes[0].cloneNode(false);
console.log(s2.childNodes.length);//0
</script>
</body>
normalize() 函数作用处理文档树中的文本节点
10.1.2Document类型
在浏览器中,document对象是HTMLDocument的一个实例,表示整个HTML页面
document对象也是window对象的一个属性
document不用使用,appendChild()、removeChild()、replaceChild()方法
因为文档类型是只读的而且它只能有一个元素子节点
2、文档信息
document对象包含title属性,可以更改title的标题内容
document.URL 取得完整的url
document.domain 取得域名 //只有domain是可以设置的
document.referrer 取得来源页面的URL
没明白的地方
3、查找元素
dom的一些方法:
getElementById('') 如果有多个相同的ID只返回文档中第一次出现的元素(IE7以下返回null,IE8不区分ID大小写)
IE7以下name特性与给定的ID如果相同,则name也会被返回,所以尽量避免Id和name名字一样
getElementsByTagName(); 返回该元素子集中相同的标签包括零或多个元素的集合NodeList动态集合
可以使用[]和item()方法访问集合对象中的元素,
集合对象还有一个方法:namedItem(),使用这个方法可以通过元素的name特性取得集合中的项,每一个浏览器的表现不一样,返回值不一样
namedItem()实例:
<body>
<ul>
<li name='klkx'>1</li>
<li name='klkx1'>2</li>
<li name='klkx'>3</li>
<li name='klkx3'>4</li>
</ul>
<script>
var oUl = document.getElementsByTagName('ul')[0];
var aLi = oUl.getElementsByTagName('li');
/*
集合对象.namedItem('名字');
只返回第一个name属性匹配正确的对象
*/
console.log(aLi.namedItem('klkx') === aLi[0]);//true
</script>
</body>
document有一个forms属性,返回form标签的HtmlCollection对象集合
document.forms 表单集合
document.images 图片集合
document.links 链接结合
返回HTMLCollection 支持按名称访问项
document.forms['name'或者数字]
document.images['name'或者数字]
document.links['name'或者数字]
如果是数字后台会自动调用item()函数,参数为数字
如果是字符串后台会调用namedItem()函数,参数为字符串
如果想要取得文档中的所有元素,可以啊传入‘*’通配符。返回的集合会按照元素出现的顺序进行排列;
传入的参数,最好区分大小写
getElementsByName() 这个方法只有HTMLDocument类型才有此方法,这个方法返回带有给定name特性的所有元素
最常用的getElementsByName()方法的情况是取得单选按钮,为了确保所发送给浏览器的值正确无误,所有单选按钮必须有相同的name特性
4、特殊集合
document.anchors 包含所有带name特性的<a>元素结合
document.applets 包含文档中所有的<applet>元素(不再使用)
documents.forms 包含所有的<forms>元素的集合
document.images 包含所有<img>元素集合
5、DOM一致性检测
var hasXmlDom = document.implementation.hasFeature('XML','1.0');
6、文档写入
document对象的功能,输出流写入到网页中,接受一个字符串参数。
write() 会原样输出
writeln() 会在原样的基础上加上一个\n
open() 打开网页的输出流
close() 关闭网页的输出流
如果页面用到write(),则open和close就不需要使用,在严格模式下,不支持文档写入。
实例:
当在document的<script>内写入标签时:
<script> document.write("<script src='xxx.js'>"+"<\/script>"); </script>
如果字符串</script>被直接写入会出现错误,他会和前边的<script>直接匹配出现错误;
所以要在斜杠前边插入一个\反斜杠转义一下
document.write()在页面输出内容,但是如果在整个页面输入完内容以后,在写入会重写整个页面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号