Python的正则表达式与JSON
Python的正则表达式需要导入re模块
菜鸟教程:http://www.runoob.com/python/python-reg-expressions.html
官方文档:https://docs.python.org/3.6/library/re.html
一译中文:https://yiyibooks.cn/xx/python_352/library/re.html
常用正则表达式:https://www.cnblogs.com/Akeke/p/6649589.html
===========================================================
1.方法
findall(pattern, string, flags=0):
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
flags:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
flags可以指定多个 例:re.I | re.S 两者是且的关系
sub(pattern, repl, string, count=0, flags=0):检索和替换
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
repl可以为函数 很强大 例:
import re s = 'A8C3721D86' def convert(value): matched = value.group() #拿到具体的值 if int(matched) >= 6: return '9' else: return '0' r = re.sub('\d',convert,s) print(r) ---------------------------------------------------------------- A9C0900D99
#group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
match(pattern, string, flags=0):re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
search(pattern, string, flags=0): re.search 扫描整个字符串并返回第一个成功的匹配。
2.元字符
\d :匹配一个数字字符
\D:匹配一个非数字字符
\w:匹配字母数字及下划线 ,字母:单词字符(\的只能匹配a-z A-Z 0-9 _)
\W:匹配非字母数字及下划线,(&,\n,\r等都算作非字母数字及下划线)
\s:匹配任意空白字符,等价于 [\t\n\r\f].(制表符都算作空白字符 \n,\t,\r等)
\S:匹配任意非空字符
[...]:用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k'
import re s = 'abc,acc,adc,aec,afc,ahc' r = re.findall('a[cf]c',s) print(r) ---------- ['acc', 'afc']
[^...]:不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符
数量词
re{n}:让前面的re表达式匹配多次,例:
import re s = 'python 11111java678php' r = re.findall('[a-z]{3}',s) print(r) -------------------------------------------------- ['pyt', 'hon', 'jav', 'php']
re{ n, m}:匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式(够多则使用m值)
import re s = 'python 11111java678php' r = re.findall('[a-z]{3,6}',s) print(r) ----------------------------------------------------- ['python', 'java', 'php']
re{ n, m}?:可以转换为非贪婪方式(使用n值)
re*:匹配0个或多个的表达式。(*前面的字符)
import re s = 'pytho0python1pythonn2' r = re.findall('python*',s) print(r) ------------------------------------------------- ['pytho', 'python', 'pythonn']
re+:匹配1个或多个的表达式。
re?:匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式(有一个也匹配,忽略后面多的re)
import re s = 'pytho0python1pythonn2' r = re.findall('python?',s) print(r) ---------------------------------------------- ['pytho', 'python', 'python']
. :匹配任意字符,除了换行符\n,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
边界匹配
^:匹配字符串的开头
$:匹配字符串的末尾
import re qq = '10000000001' r = re.findall('\d{4,8}',qq) print("\d{4,8} : " + str(r)) r2 = re.findall('^\d{4,8}',qq) print('^\d{4,8}: '+str(r2)) r3 = re.findall('\d{4,8}$',qq) print('\d{4,8}$: '+ str(r3)) r4 = re.findall('^\d{4,8}$',qq) #匹配整个字符串 print('^\d{4,8}$: '+ str(r4)) r5 = re.findall('^000',qq) #^匹配字符串开头,则开头必须000 ;$同理 print('^000: '+ str(r5)) ----------------------------------------------------------------------------- \d{4,8} : ['10000000'] ^\d{4,8}: ['10000000'] \d{4,8}$: ['00000001'] ^\d{4,8}$: [] ^000: []
组
(re):匹配括号内的表达式,也表示一个组
import re qq = 'PythonPythonPythonPythonPythonPythonPython' r = re.findall('(Python){3}',qq) print(r) ------------------------------------------------------------------------ ['Python', 'Python']
========================================================================
JSON
导入json模块
反序列化过程
import json json_str = '{"name":"zhangsan","age":18}' #这里的json 中的字符串类型必须用"" ,因为里面用了"",所以外面需要用'' student = json.loads(json_str) print(type(student)) print(student) ----------------------------------------------------------------------- <class 'dict'> {'name': 'zhangsan', 'age': 18}
import json json_str = '[{"name":"zhangsan","age":18},{"name":"lisi","age":19}]' student = json.loads(json_str) print(type(student)) print(student) -------------------------------------------------------------------- <class 'list'> [{'name': 'zhangsan', 'age': 18}, {'name': 'lisi', 'age': 19}]
序列化过程
import json student = [{'name':'zhangsan','age':18,'flag':False},{'name':'lisi','age':18,'flag':True}] json_str = json.dumps(student) print(type(json_str)) print(json_str) ----------------------------------------------------------------------------- <class 'str'> [{"name": "zhangsan", "age": 18, "flag": false}, {"name": "lisi", "age": 18, "flag": true}]
JSON中的数据类型和python中的对应关系:
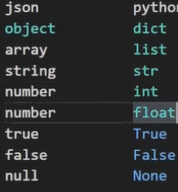
JSON对象:
JSON:
JSON字符串:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号