
实习第二周周报
这周主要学习了集合,IO,多线程
一、集合
1.集合主要继承图(核心卷1)
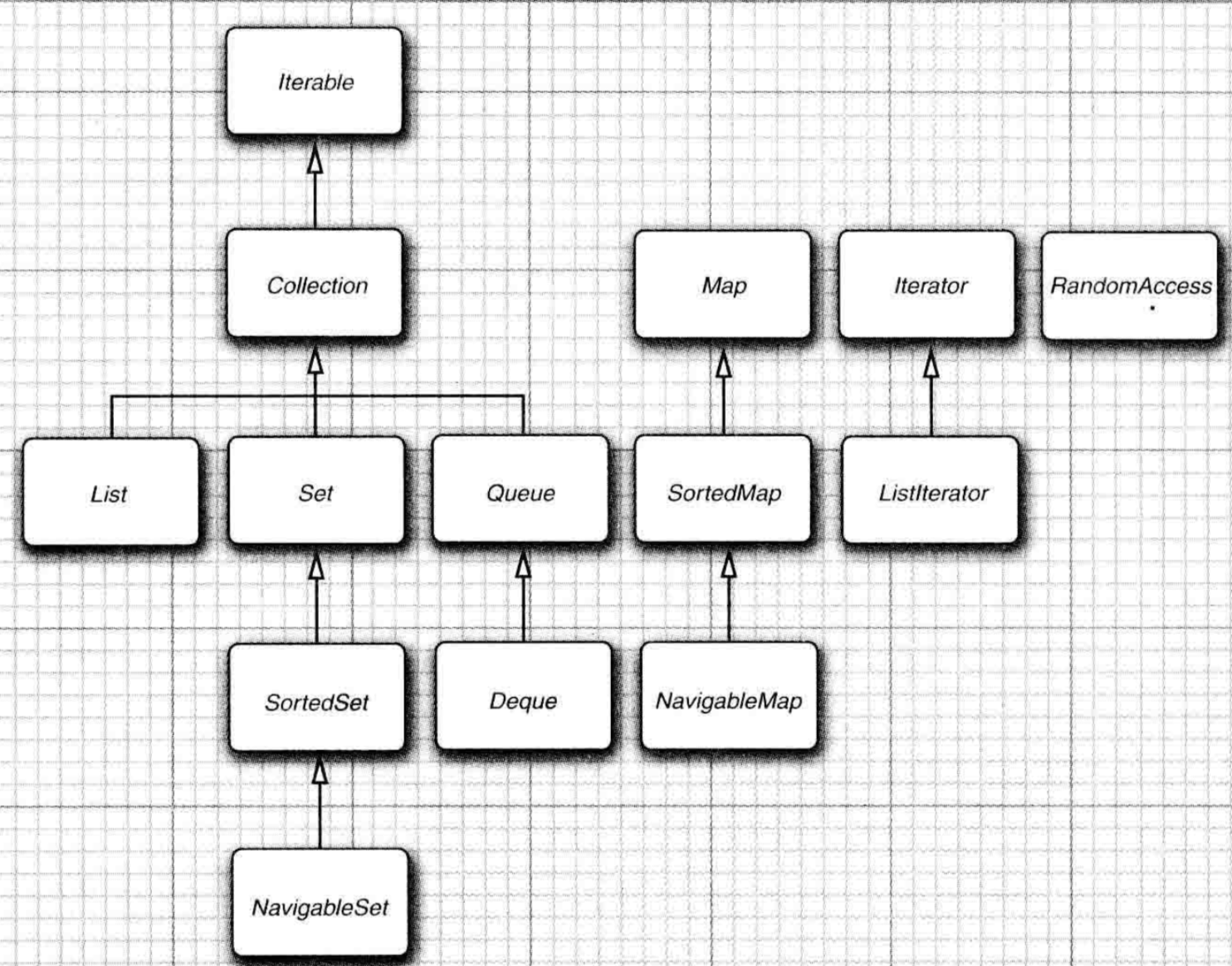
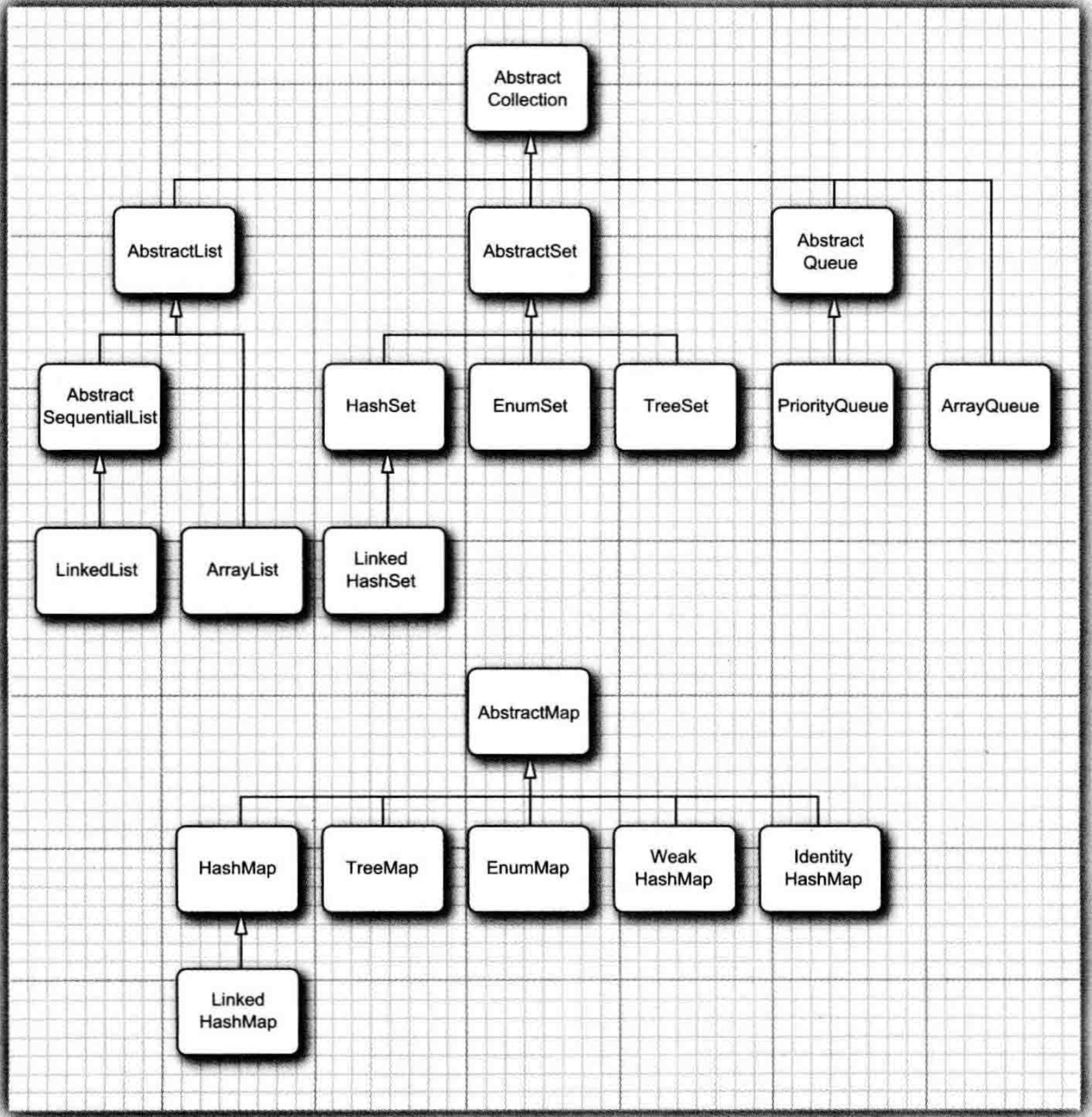
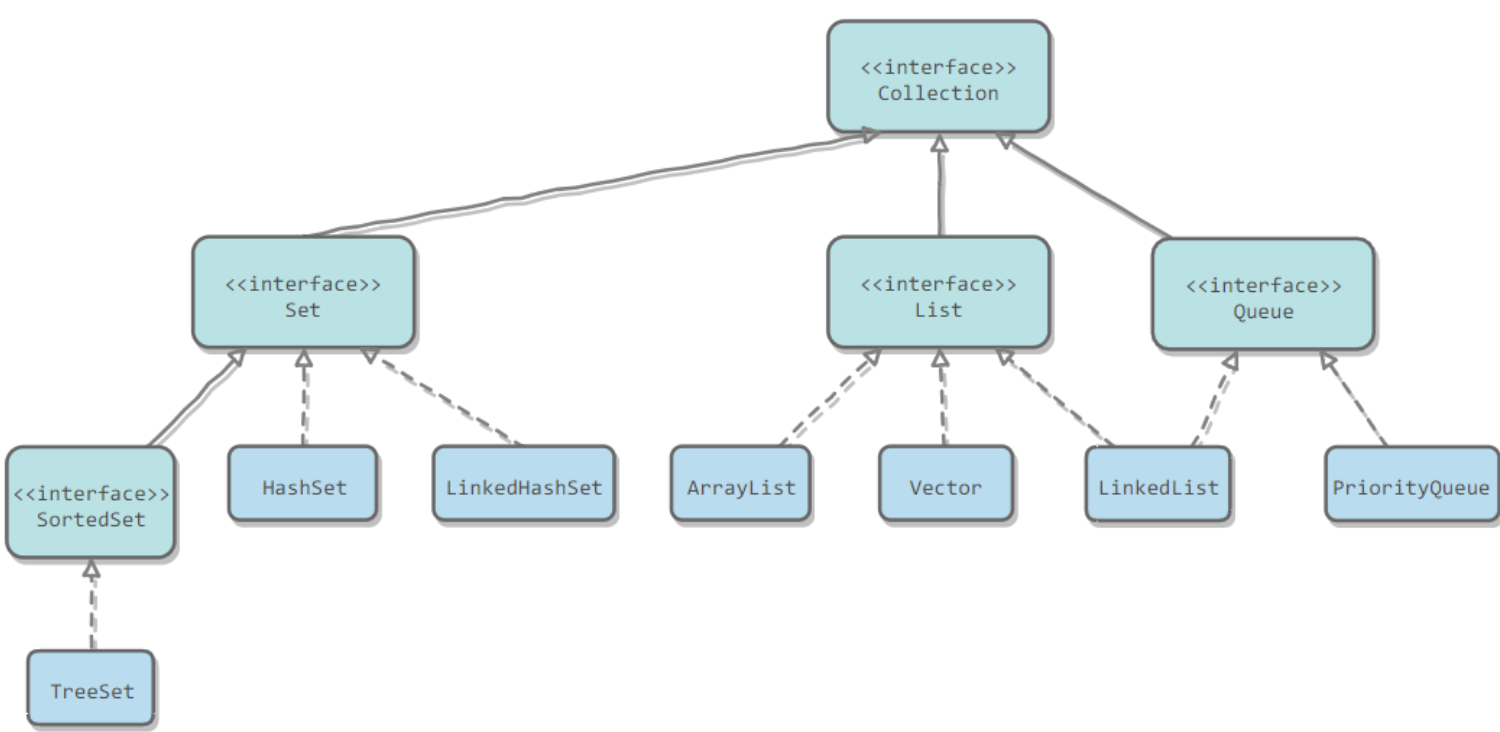
2.ArrayList
arrayList是非同步的基于动态数组实现,在arrayList的类中描述到在集合在进行size、isEmpty、get、set、iterator、listIterator操作时,会发生fail-fast机制,因为在这些操作会checkForComodification()检查modCount和exceptmodCount的预期值是否相等,但在多线程时会产生类似读写不一致的现象的事情,从而发生fail-fast的事情。(并发下用JUC下的CopyOnWrite可以避免这种错误)
在扩容时,每次会扩大到原来的1.5倍,并用Arrays.copyOf()将旧数组复制到新数组,耗费很大,所以如果在已知需要多少容量时在创建时指定容量大小,减少扩容的次数。
3.LinkedList
linkedList是基于双向链表实现,所以他在删除和插入元素时会更快,但查询元素时就会通过遍历的方式,同样也会发生fail-fast
4.Vector和CopyOnWriteArrayList
他们都是同步方法,vector是早期的方法通过synchronize进行同步操作,verctor每次扩容时是原来的2倍,
verctor并不被推崇,如果想要同步方法,可以用如下方法代替
List<String> list = new ArrayList<>(); List<String> synList = Collections.synchronizedList(list); 也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
CopyOnWriteArrayList是JUC下的类,他进行了读写分离:写操作在一个复制的数组上进行,读操作还在原来的数组上进行。写操作需要加锁,并在写完后需要将原始数组指向新数组。所以CopyOnWriteArrayList适合读多写少的场景,但是他缺点也很明显:①。读写两个数组,内存占用多 ②。读写分离,导致每次读操作不一定是最新的。所以他不适合内存敏感和实时性要求很高的场景
5.HashMap
hashmap底层采用数组加链表的方式进行存储,链表采用的头插法,在进行hash时将key的hashcode与自己>>>16进行亦或操作,HashMap的初始大小和扩容都是以2的次方来进行的,在确定的桶的位置时通过(legth-1)&hash,的方式来减少hash冲突,在进行扩容时同样通过将旧数组重新放入到新数组的操作,同样很费事
二、并发
1.多线程与多进程的区别:
①、每个进程有自己的一整套变量,进程间共享数据 ②、共享变量使得线程间通信比进程间容易 ③、线程更加轻量级 ④、线程共享使得不安全
2.线程状态
-
- New(新创建)
- Runbale(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Time Waiting(计时等待)
- Terminated(被终止)
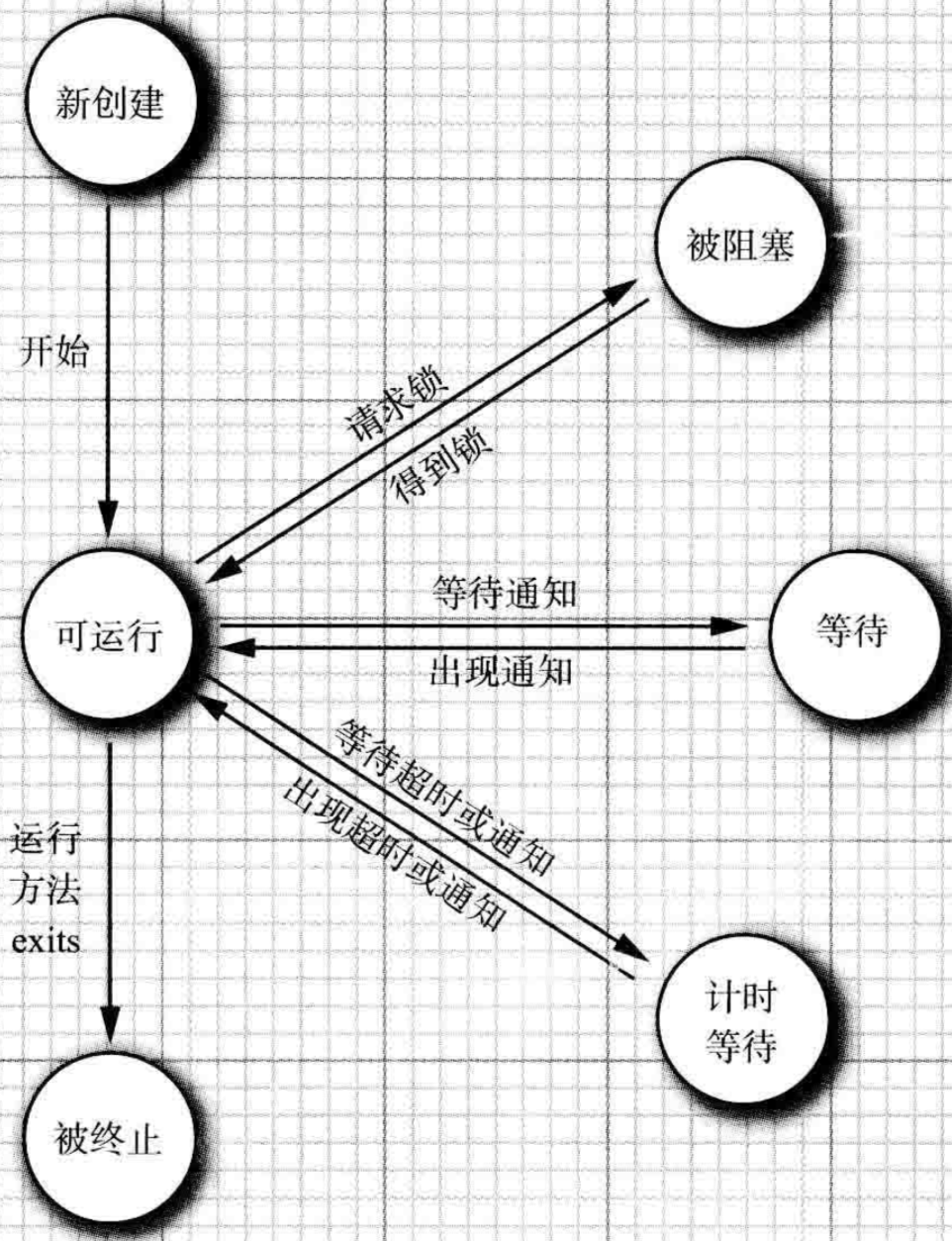
- New(新创建)
- Runbale(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Time Waiting(计时等待)
- Terminated(被终止)
2.1 New状态
当用new操作创建一个线程后,该线程还没有运行,此时状态为New,程序还没有运行线程中的代码,在运行之前还有一些基础工作要做
2.2 Runable
一旦调用start方法,线程处于Runable状态,一个可运行的线程可能正在运行也可能没有运行,这取决于操作系统给线程分配的时间
2.3 Blocked和Waiting
当线程处于Blocked和Waiting时,他暂时不活动。他不运行任何代码且消耗最少的资源,直到线程调度器重新激活它,细节取决于他是怎样到达非活动状态的
当一个线程试图获取一个内部的对象锁(而不是JUC库中的锁),而该锁被其他线程持有,则该线程进入阻塞状态,当其他线程释放该锁,并且线程调度器允许本线程持有他的时候,该线程进入非阻塞状态,
当线程等待另一个线程通知调度器一个条件时,他自己进入等待状态。在调用Object.wait()或Thred.join(),或者是等待JUC库中Lock或Condition时,就会出现这种情况
有几个方法(thread.sleep,object.wait thread.join, lock.tryLock ,Condition.await)有一个计时参数,调用他们导致线程进入计时等待状态。这一状态将一直保持到超时期满或者接收到适当的通知,
3.线程优先级
每一个线程有一个优先级,默认一个线程继承他父线程的优先级。可以用setPriority提高或降低一个线程的优先级,线程优先级是高度依赖系统的,所以不要将程序构建为功能依赖于优先级的程序。
4.synchronize
synchronize分为对象锁和类锁。当synchronize作用在非静态方法和代码块时,此时是对象锁,他会对同一个对象进行锁,在此情况下这个类中的synchronize方法都将进行同步操作,而非synchronize方法可以并行访问;
当synchronize作用在静态方法和synchronize(类名.class){}进行类锁,此时此类的所有对象都会进行同步。
5.中断线程
在java的早期版本中,还有一个stop方法,其他线程可以调用它终止线程,但是,这个方法已经被弃用了,因为他的强制停止是非常错误的,在进行操作时会发生各种结果。
现在没有可以强制停止线程的方法,但使用interrupt可以用来请求中断线程,他并不会立即停止线程,并且停不停止由线程本身说了算,他只算是类似提个建议,我们可以通过interrupted()进行判断,从而手动停止线程
6.wait和notify和notifyAll()
他们为object的方法,调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。wait和释放锁,而sleep不会。
在JUC下condition类下的的await() signal() signalAll()与上面类似,await可以指定等待条件也就更加灵活
三、IO
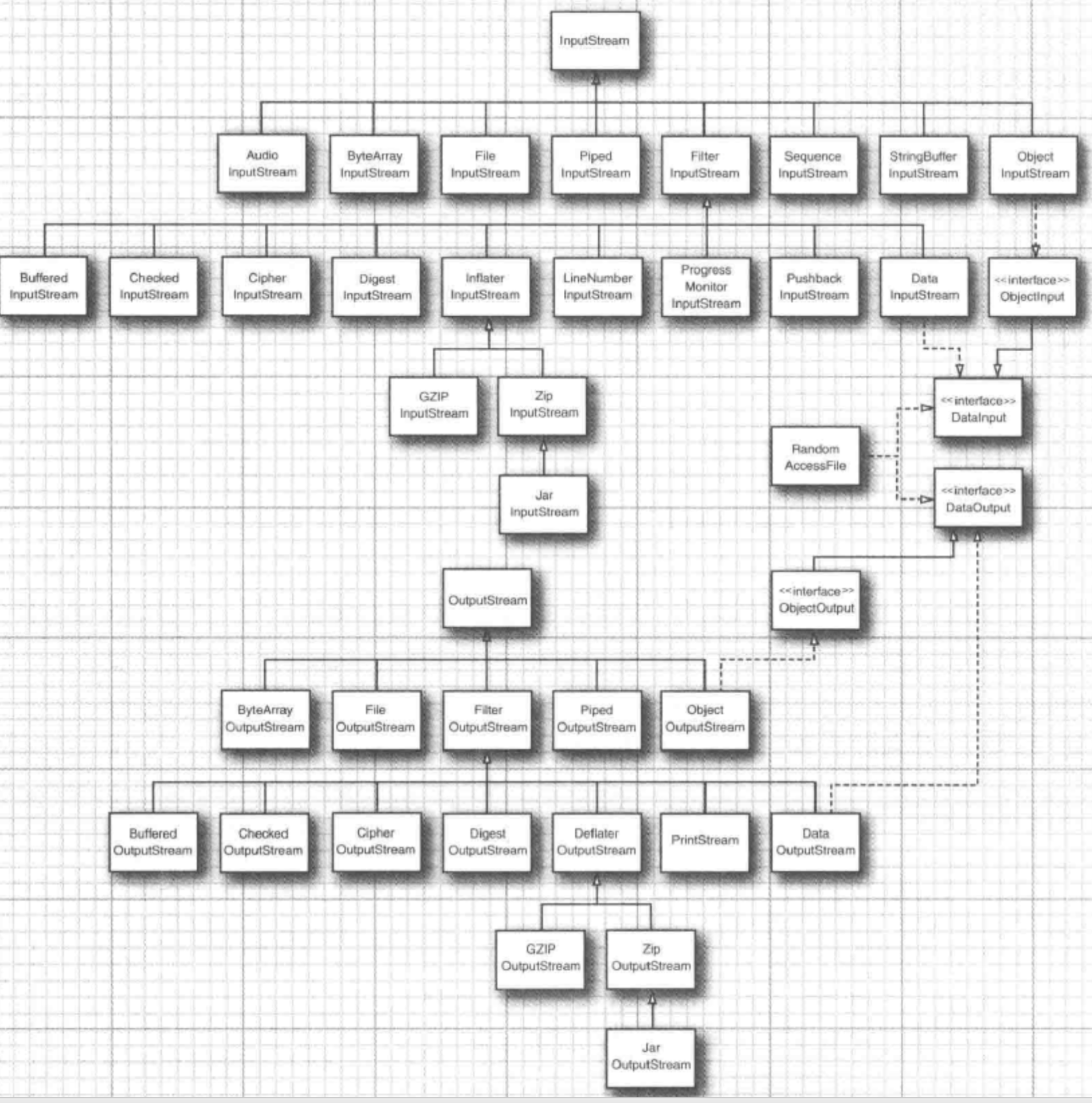
1.字节流和字符流
InputStream和outputstream是字节流,Reader和Writer是字符流,一个字符占用两个字节,所以在涉及中文时,应该采用字符流
2.装饰者模式
在io中使用的装饰者模式,通过封装多重接口来达到不同目的,这种方法更加灵活但也导致了javaio操作非常繁琐不像其他语言那样的方便使用
3.序列化
为了让对象在网络间进行传输,需要将他进行序列化转换为字节序列,通过实现Serializable接口,他可以实现轻量级持久性,在需要时进行反序列化转换为对象
4.常用实例
3.1 文件读取写入--复制
public static void copyFile(String src, String dist) throws IOException { FileInputStream in = new FileInputStream(src); FileOutputStream out = new FileOutputStream(dist); byte[] buffer = new byte[20 * 1024]; int cnt; // read() 最多读取 buffer.length 个字节 // 返回的是实际读取的个数 // 返回 -1 的时候表示读到文件尾 while ((cnt = in.read(buffer, 0, buffer.length)) != -1) { out.write(buffer, 0, cnt); } in.close(); out.close(); }
3.2 标准输入流的使用(在system.in封装过滤器)
BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); String readRecv = br.readLine();
