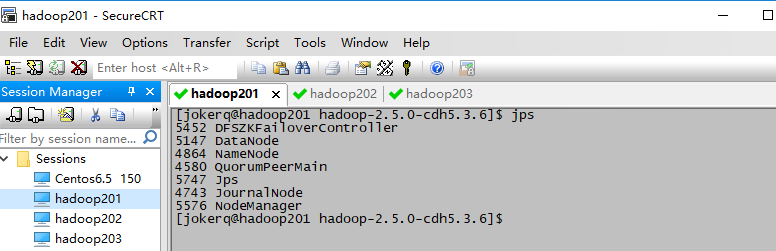
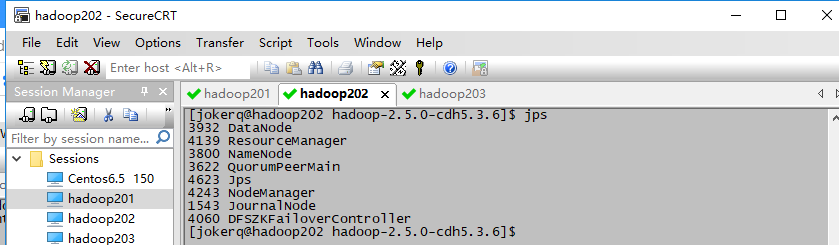
hadoop在zookeeper上的高可用HA
(参考文章:https://www.linuxprobe.com/hadoop-high-available.html)
一、技术背景
影响HDFS集群不可用主要包括以下两种情况:一是NameNode机器宕机,将导致集群不可用,重启NameNode之后才可使用;
二是计划内的NameNode节点软件或硬件升级,导致集群在短时间内不可用。
为了解决上述问题,Hadoop给出了HDFS的高可用HA方案:HDFS通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,比如处理来自客户端的RPC请求,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
二、HA架构
一个典型的HA集群,NameNode会被配置在两台独立的机器上,在任何时间上,一个NameNode处于活动状态,而另一个NameNode处于备份状态,活动状态的NameNode会响应集群中所有的客户端,备份状态的NameNode只是作为一个副本,保证在必要的时候提供一个快速的转移。
为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。当Active Node上更新了namespace,它将记录修改日志发送给JNS的多数派。Standby noes将会从JNS中读取这些edits,并持续关注它们对日志的变更。Standby Node将日志变更应用在自己的namespace中,当failover发生时,Standby将会在提升自己为Active之前,确保能够从JNS中读取所有的edits,即在failover发生之前Standy持有的namespace应该与Active保持完全同步。
为了支持快速failover,Standby node持有集群中blocks的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个Namenode的地址,同时和它们都建立心跳链接,并把block位置发送给它们。
任何时刻,只有一个Active NameNode是非常重要的,否则将会导致集群操作的混乱,那么两个NameNode将会分别有两种不同的数据状态,可能会导致数据丢失,或者状态异常,这种情况通常称为“split-brain”(脑裂,三节点通讯阻断,即集群中不同的Datanodes却看到了两个Active NameNodes)。对于JNS而言,任何时候只允许一个NameNode作为writer;在failover期间,原来的Standby Node将会接管Active的所有职能,并负责向JNS写入日志记录,这就阻止了其他NameNode基于处于Active状态的问题。

基于QJM的HDFS HA方案如上图所示,其处理流程为:集群启动后一个NameNode处于Active状态,并提供服务,处理客户端和DataNode的请求,并把editlog写到本地和share editlog(这里是QJM)中。另外一个NameNode处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与Active节点的状态同步。为了实现Standby在Active挂掉后迅速提供服务,需要DataNode同时向两个NameNode汇报,使得Stadnby保存block to DataNode信息,因为NameNode启动中最费时的工作是处理所有DataNode的blockreport。为了实现热备,增加FailoverController和Zookeeper,FailoverController与Zookeeper通信,通过Zookeeper选举机制,FailoverController通过RPC让NameNode转换为Active或Standby。
三、HDFS自动故障转移
HDFS的自动故障转移主要由Zookeeper和ZKFC两个组件组成。
Zookeeper集群作用主要有:一是故障监控。每个NameNode将会和Zookeeper建立一个持久session,如果NameNode失效,那么此session将会过期失效,此后Zookeeper将会通知另一个Namenode,然后触发Failover;二是NameNode选举。ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
ZKFC是一个Zookeeper的客户端,它主要用来监测和管理NameNodes的状态,每个NameNode机器上都会运行一个ZKFC程序,它的职责主要有:一是健康监控。ZKFC间歇性的ping NameNode,得到NameNode返回状态,如果NameNode失效或者不健康,那么ZKFS将会标记其为不健康;二是Zookeeper会话管理。当本地NaneNode运行良好时,ZKFC将会持有一个Zookeeper session,如果本地NameNode为Active,它同时也持有一个“排他锁”znode,如果session过期,那么次lock所对应的znode也将被删除;三是选举。当集群中其中一个NameNode宕机,Zookeeper会自动将另一个激活。
四、集群规划改变
存储:
1.当editlog发生改变,则直接写入JournalNode,以用来分享给其他NameNode
2.
 ======》》》
======》》》
五、配置
1.在配置了hadoop分布式非高可用(https://www.cnblogs.com/jokerq/p/9678033.html) 和 zookeeper分布式(https://www.cnblogs.com/jokerq/p/10025986.html)的情况下
2.启动zookeeper (
bin/zkServer.sh start
查看状态:
bin/zkServer.sh status
)
3.修改hadoop
一、NameNode的HA
2.1修改core-site.xml
<configuration> <!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址,hdfs://后为主机名或者ip地址和端口号 --> <!-- 修改为 为集群取个名字 --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hdpdata</value> </property>
<!-- 故障转移需要的zookeeper集群设置一下-->
<property>
<name>ha.zookeeper.quorum</name>
<value>jokerq1:2181,jokerq2:2181,jokerq3:2181</value>
</property>
</configuration>
2.2修改hdfs-site.xml
<configuration>
<!-- 指定数据冗余份数,备份数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 完全分布式集群名称,和core-site集群名称必须一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>jokerq1:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>jokerq2:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>jokerq1:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>jokerq2:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://jokerq1:8485;jokerq2:8485;jokerq3:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hdpdata/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 故障自动转移设置为true --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
</configuration>
3.更新其他集群文件
(未开启zookeeper需要开启
.启动zookeeper (
bin/zkServer.sh start
查看状态:
bin/zkServer.sh status
)
)
*.初始化HA在zookeeper上的状态(在hadoopp集群未启动前刚开始配置时执行,在1中执行)
bin/hdfs zkfc -formatZK
4.在各个JournalNode节点上,输入以下命令启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
5.在[nn1]上(jokerq1),对其进行格式化,并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
6.在[nn2]上(jokerq2),同步nn1的元数据信息,并启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
7.手动把nn1(jokerq1)设置为active
bin/hdfs haadmin -transitionToActive nn1
当交给zookeeper之后 需要zookeeper来启动
sbin/start-dfs.sh (???未启动datanode,初始化了多次导致version不一致)
注:在nn1的namenode挂掉之后 可以手动复制7将nn1改为nn2并在nn2手动激活
也可以配置故障自动转移
在hdfs-site中添加
<!-- 故障自动转移设置为true -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site中添加
<!-- 故障转移需要的zookeeper集群设置一下--> <property> <name>ha.zookeeper.quorum</name> <value>jokerq1:2181,jokerq2:2181,jokerq3:2181</value> </property>
8.查看服务状态
bin/hdfs haadmin -getServiceState nn1
三、ResourceManager的HA
3.1修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 任务历史服务-->
<property>
<name>yarn.log.server.url</name>
<value>http://jokerq1:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!--resourcemanager是否支持高可用HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明resourcemanager集群的名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>jokerq2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>jokerq3</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>jokerq1:2181,jokerq2:2181,jokerq3:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
3.2完成后远程拷贝给其他服务器
scp etc/hadoop/yarn-site.xml jokerq3:/home/hadoop/apps/hadoop-2.5.0/etc/hadoop/
3.3通过jps查看每个服务器的zookeeper服务QuorumPeerMain已经运行,没有运行则开启,
3.4在z02中执行
sbin/start-yarn.sh
3.5 在z03中执行:
sbin/yarn-daemon.sh start resourcemanager
3.6查看服务状态
bin/yarn rmadmin -getServiceState rm1
3.7测试
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/ /output/
开启JobHistoryServer
mr-jobhistory-daemon.sh start historyserver