
ConcurrentHashMap
版权声明:本文为博主原创文章,未经博主允许不得转载。http://www.cnblogs.com/jokermo/
高并发下的HashMap
1.ReHash
rehash是HashMap扩容时的一个步骤,Hashmap的长度有限,不断插入数据,当hashmap达到一定饱和时,hash冲突概率会提高。这时候hashmap就需要进行扩容,也就是Resize。
影响发生Resize的因素有两个:
1.Capacity
HashMap的当前长度。HashMap的长度是2的幂。
2.LoadFactor
HashMap负载因子,默认值为0.75f。
衡量HashMap是否进行Resize的条件如下:
HashMap.Size >= Capacity * LoadFactor
ReHash的Java代码如下:
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } }
.Hashmap的Resize包含扩容和ReHash两个步骤,ReHash在并发的情况下可能会形成链表环。所以HashMap不能用于多线程
多线程之ConcurrentHashMap
ConcurrentHashMap可以说是一个二级哈希表。在一个总的哈希表中,有若干个子哈希表。子哈希表可以称为segment,ConcurrentHashMap结构如下:
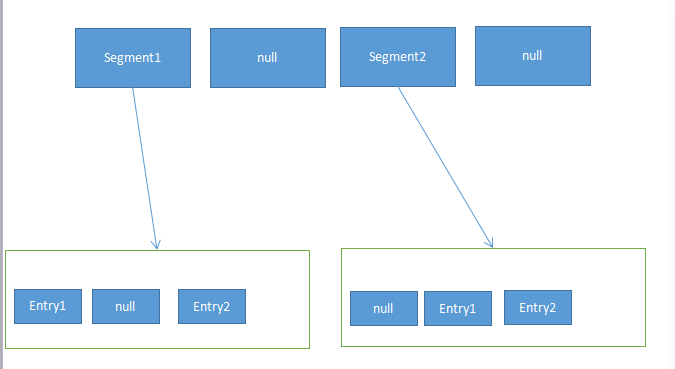
此时的 ConcurrentHashMap采用了锁分段技术,每个segment的读写操作高度自治,segment之间互不影响。
ConcurrentHashMap高并发读写操作有三种情况:
- 同一segment并发写入
- 不同segment的并发写入
- 同一segment一读一写
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
ConcurrentHashMap的读写过程:
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
size方法
ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号