python重拾基础第三天
本节内容
- 函数基本语法及特性
- 参数与局部变量
- 返回值
- 嵌套函数
- 递归
- 匿名函数
- 函数式编程介绍
- 高阶函数
- 内置函数
1. 函数基本语法及特性
背景提要
现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
上面的代码实现了功能,但存在2个问题
- 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
- 如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义
def sayhi():#函数名
print("Hello, I'm nobody!")
sayhi() #调用函数
可以带参数
#下面这段代码
a,b = 5,8
c = a**b
print(c)
#改成用函数写
def calc(x,y):
res = x**y
return res #返回函数执行结果
c = calc(a,b) #结果赋值给c变量
print(c)
2. 函数参数与局部变量
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
默认参数
看下面代码
def stu_register(name,age,country,course):
print("----注册学生信息------")
print("姓名:",name)
print("age:",age)
print("国籍:",country)
print("课程:",course)
stu_register("王山炮",22,"CN","python_devops")
stu_register("张叫春",21,"CN","linux")
stu_register("刘老根",25,"CN","linux")
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
def stu_register(name,age,course,country="CN"):
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
stu_register(age=22,name='alex',course="python",)
非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式
print(name,age,args)
stu_register("Alex",22)
#输出
#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python")
#输出
# Jack 32 ('CN', 'Python')
还可以有一个**kwargs
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式
print(name,age,args,kwargs)
stu_register("Alex",22)
#输出
#Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")
#输出
# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
局部变量
name = "Alex Li"
def change_name(name):
print("before change:",name)
name = "金角大王,一个有Tesla的男人"
print("after change", name)
change_name(name)
print("在外面看看name改了么?",name)
输出
before change: Alex Li after change 金角大王,一个有Tesla的男人 在外面看看name改了么? Alex Li
全局与局部变量
3. 返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
#!/usr/bin/env python
#_*_coding:utf-8_*_
def func():
b = [1,2,3]
return b #可以是任何数据类型
ret = func() #有返回值,就需要用变量来接收
print(ret)
嵌套函数
看上面的标题的意思是,函数还能套函数?of course
name = "Alex"
def change_name():
name = "Alex2"
def change_name2():
name = "Alex3"
print("第3层打印",name)
change_name2() #调用内层函数
print("第2层打印",name)
change_name()
print("最外层打印",name)
此时,在最外层调用change_name2()会出现什么效果?
没错, 出错了, 为什么呢?
4. 递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n):
print(n)
if int(n/2) ==0:
return n
return calc(int(n/2))
calc(10)
输出:
10
5
2
1
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
递归函数实际应用案例,二分查找
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
print(dataset)
if len(dataset) >1:
mid = int(len(dataset)/2)
if dataset[mid] == find_num: #find it
print("找到数字",dataset[mid])
elif dataset[mid] > find_num :# 找的数在mid左面
print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else:# 找的数在mid右面
print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])
return binary_search(dataset[mid+1:],find_num)
else:
if dataset[0] == find_num: #find it
print("找到数字啦",dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
binary_search(data,66)
5. 匿名函数
匿名函数就是不需要显式的指定函数
calc(函数名) = lambda n(参数) : n*n(参数怎么处理,并且返回值)
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下


# filter 第一个参数,判断函数,第二个参数,可迭代对象 # filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。 # 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。 # 语法:filter(function, iterable) filter返回迭代器 def is_odd(n): return n % 2 == 1 newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(newlist) # <filter object at 0x102079b00> for i in newlist: print(i) # 13579 # 匿名函数写法 print(list(filter(lambda x:x%2==1,[1,2,3])))
# map() 会根据提供的函数对指定序列做映射。第一个是函数,第二个是可迭代对象,第三个一样。。。 # 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 # 语法 map(function, iterable, ...) def square(x,Y) : # 计算平方,如果参数多个,那么是相对位置 return x ** 2,Y ** 2 print(map(square, [1,2,3,4,5])) # 计算列表各个元素的平方,返回迭代器 for i in map(square, [1,2,3,4,5],[6,7,8]): print(i) ''' (1, 36) (4, 49) (9, 64) ''' # 匿名函数写法 print(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数 # 提供了两个列表,对相同位置的列表数据进行相加 map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
6. 函数式编程介绍
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell, 好了,我只会这么多了。。。
7. 高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)
8. 内置函数

内置函数的魅力 https://www.cnblogs.com/jokerbj/p/7282093.html
本节作业
有以下员工信息表
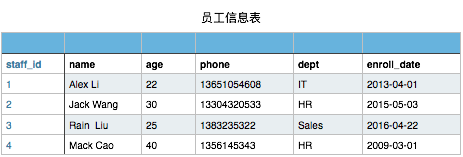
当然此表你在文件存储时可以这样表示
1,Alex Li,22,13651054608,IT,2013-04-01
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
相同函数名执行过程
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
def f1(a1,a2): # 1
return a1 + a2
def f1(a3,a4): # 2
return a3 * a4 # 4
ret = f1(8,8) # 3 #5
print(ret) # 6
# 开始f1的空间包含指向为a1 + a2,后来变为了a3 * a4,在实参传递的时候,你也会发现给的是a3,a4赋值
发送小邮件程序
# !/usr/bin/env python
# _*_coding:utf-8_*_
# Author:Joker
def sendmail():
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
msg = MIMEText('我正在通过PY给你发送邮件,别再睡了。','plain','utf-8') # 创建一个文本类型
msg['From'] = formataddr(['joker','jokerbj@126.com']) # 二元祖,发件人,发件地址
msg['Subject'] = "亲爱的POPPY君"
server = smtplib.SMTP('smtp.126.com',25)
server.login('jokerbj@126.com','授权登录密码') # SMTP第三方授权登录密码
server.sendmail('jokerbj@126.com',['对方邮件地址@qq.com',],msg.as_string())
server.quit()
return 1
ret = sendmail()
if ret:
print('email send success!')
本文来自博客园,作者:liqianlong,转载请注明原文链接:https://www.cnblogs.com/liqianlong/p/9475546.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号