生产力跟不上生产的速度时,就会出现很多问题,如何针对问题进行处理,制定什么样的计划,如何解决就是需要思考的难点?
IT运维,指的是对已经搭建好的网络,软件,硬件进行维护。运维领域也是细分的,有硬件运维和软件运维
- 硬件运维主要包括对基础设施的运维,比如机房的设备,主机的硬盘,内存这些物理设备的维护
- 软件运维主要包括系统运维和应用运维,系统运维主要包括对OS,数据库,中间件的监控和维护,这些系统介于设备和应用之间,应用运维主要是对线上业务系统的运维
这里讨论的主要是软件运维的自动化,包括系统运维和应用运维的自动化
- 日常工作繁琐
日常运维工作是比较繁琐的,研发同学会经常需要到服务器上查日志,重启应用,或者是说今天上线某个产品,需要部署下环境。这些琐事是传统运维的大部分工作
- 应用运行环境不统一
在部署某应用后,应用不能访问,就会听到开发人员说,在我的环境运行很好的,怎么部署到测试环境后,就不能用了,因为各类环境的类库不统一
还有一种极端情况,运维人员习惯不同,可能凭自己的习惯来安装部署软件,每种服务器上运行软件的目录不统一
-
运维及部署效率低下
想想运维人员需要登陆到服务器上执行命令,部署程序,不仅效率很低,并且非常容易出现人为的错误,一旦手工出错,追溯问题将会非常不容易
-
无用报警信息过多
经常会收到很多报警信息,多数是无用的报警信息,造成运维人员经常屏蔽报警信
另外如果应用的访问速度出了问题,总是需要从系统、网络、应用、数据库等一步步的查找原因 -
资产管理和应用管理混乱
资产管理,服务管理经常记录在excel、文本文件或者wiki中,不便于管理,老员工因为比较熟,不注重这些文档的维护,只有靠每次有新员工入职时,资产才能够更正一次
针对传统运维的痛点,我们可以知道自动化运维需要支持哪些功能
运维自动化最重要的就是标准化一切
- OS的选择统一化,同一个项目使用同样的OS系统部署其所需要的各类软件
- 软件安装标准化,例如JAVA虚拟机,php,nginx,mysql等各类应用需要的软件版本,安装目录,数据存放目录,日志存放目录等
- 应用包目录统一标准化,及应用命名标准化
- 启动脚本统一目录和名字,需要变化的部分通过参数传递
- 配置文件标准化,需要变化的部分通过参数传递
- 日志输出,日志目录,日志名字标准化
- 应用生成的数据要实现统一的目录存放
- 主机/虚拟机命名标准化,虚拟机管理使用标准化模板
- 使用docker比较容易实现软件运行环境的标准化
CMDB是所有运维工具的数据基础
- 用户管理,记录测试,开发,运维人员的用户表
- 业务线管理,需要记录业务的详情
- 项目管理,指定此项目用属于哪条业务线,以及项目详情
- 应用管理,指定此应用的开发人员,属于哪个项目,和代码地址,部署目录,部署集群,依赖的应用,软件等信息
- 主机管理,包括云主机,物理机,主机属于哪个集群,运行着哪些软件,主机管理员,连接哪些网络设备,云主机的资源池,存储等相关信息
- 主机变更管理,主机的一些信息变更,例如管理员,所属集群等信息更改,连接的网络变更等
- 网络设备管理,主要记录网络设备的详细信息,及网络设备连接的上级设备
- IP管理,IP属于哪个主机,哪个网段, 是否被占用等
- Agent实现方式
Agent方式,可以将服务器上面的Agent程序作定时任务,定时将资产信息提交到指定API录入数据库
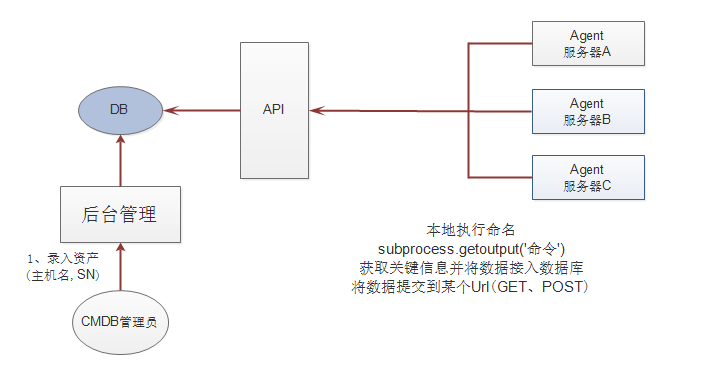
其本质上就是在各个服务器上执行
subprocess.getoutput()命令,然后将每台机器上执行的结果,返回给主机API,然后主机API收到这些数据之后,放入到数据库中,最终通过web界面展现给用户
优点:速度快
缺点:需要为每台服务器部署一个Agent程序
- ssh实现方式 (基于Paramiko模块)
中控机通过Paramiko(py模块)登录到各个服务器上,然后执行命令的方式去获取各个服务器上的信息
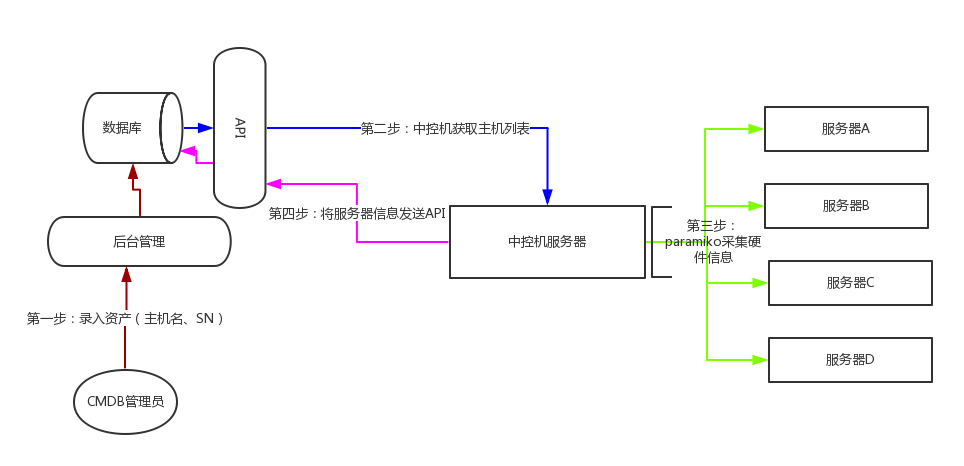
优点:无Agent 缺点:速度慢
如果在服务器较少的情况下,可应用此方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='c1.salt.com', port=22, username='root', password='123')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df')
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
|
- saltstack方式
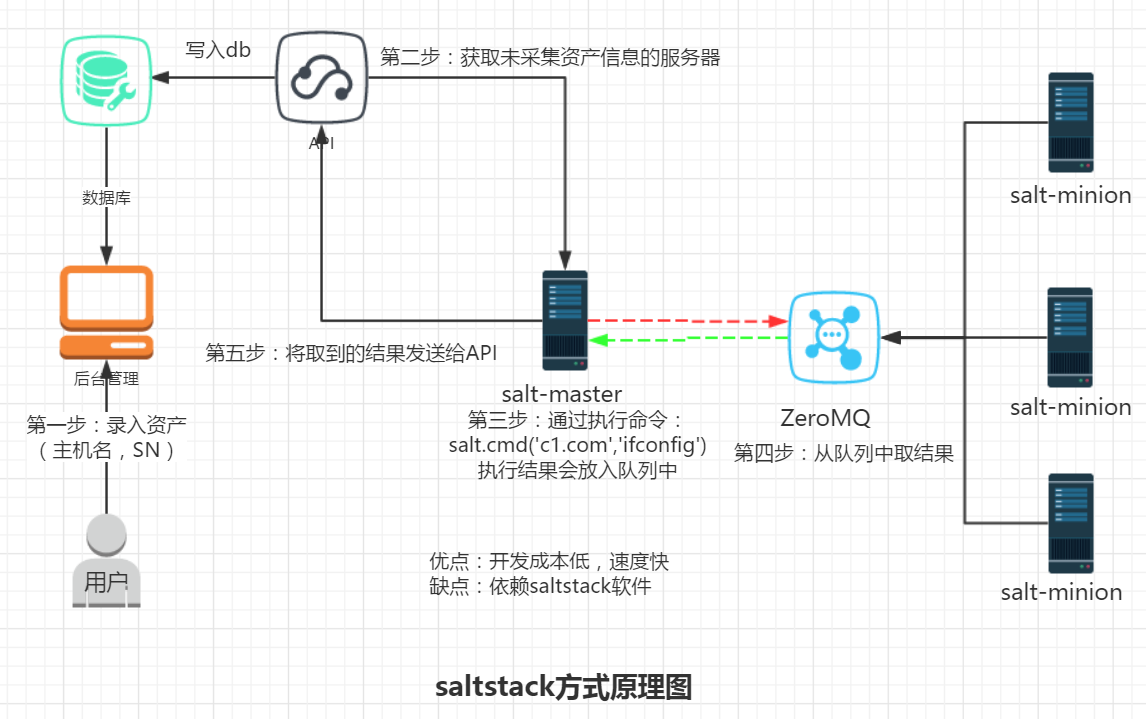
此方案本质上和第二种方案大致是差不多的流程,中控机发送命令给服务器执行。服务器将结果放入另一个队列中,中控机获取将服务信息发送到API进而录入数据库。
优点:快,开发成本低 缺点:依赖于第三方工具
salstack的安装和配置
1.安装和配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
master端:
"""
1. 安装salt-master
yum install salt-master
2. 修改配置文件:/etc/salt/master
interface: 0.0.0.0 # 表示Master的IP
3. 启动
service salt-master start
"""
slave端:
"""
1. 安装salt-minion
yum install salt-minion
2. 修改配置文件 /etc/salt/minion
master: 10.211.55.4 # master的地址
或
master:
- 10.211.55.4
- 10.211.55.5
random_master: True
id: c2.salt.com # 客户端在salt-master中显示的唯一ID
3. 启动
service salt-minion start
"""
|
2.授权
|
1
2
3
4
5
6
|
"""
salt-key -L # 查看已授权和未授权的slave
salt-key -a salve_id # 接受指定id的salve
salt-key -r salve_id # 拒绝指定id的salve
salt-key -d salve_id # 删除指定id的salve
"""
|
3.执行命令
在master服务器上对salve进行远程操作
|
1
|
salt 'c2.salt.com' cmd.run 'ifconfig'
|
基于API的方式
|
1
2
3
|
import salt.client
local = salt.client.LocalClient()
result = local.cmd('c2.salt.com', 'cmd.run', ['ifconfig'])
|
参考安装:
http://www.cnblogs.com/tim1blog/p/9987313.html
https://www.jianshu.com/p/84de3e012753
- Puppet(ruby语言开发)(了解)
每隔30分钟,通过RPC消息队列将执行的结果返回给用户
以上时自动化的整体的需求分析和思路梳理,最终的落地和执行,需要整个开发team共同努力,相关的code,就需要自行动手搞起来了,加油小伙伴们.
注:文章如有疑问或错误之处,请留言评论指出,必将学习之.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号