《一些特殊的数论函数求和问题》阅读随笔

好至少它教会了我如何把质数求和转化成积分的渐进 对着 微就行了 然后直接
18.3k……阿巴阿巴
目录
引言
这玩意挺常见的。而且你会发现有些做法能套在很多题上。咱选几个做法聊聊。
首先我讲讲拓展埃式筛求前缀和,然后再聊聊素数和,最后给你讲讲怎么用面积拟合函数。
反正不要钱,多少看一点~
基础知识
定义 (数论函数):一个函数 被称为数论函数,当且仅当其定义域为正整数集,陪域为复数集。
定义 (积性函数):一个函数 被称为积性函数,当且仅当 。
引理 (数论分块):给定正整数 ,对于任意正整数 , 的取值只有 种。
证明:当 时 的取值有 个,而当 时 ,因此 的取值有 个。
定理 (素数定理):令 为不大于 的素数个数。有 。
证明略。
积性函数求和
你发现这种题很常见。16 年任之洲同样写了积性函数求和的几种方法,并得到了一种适用范围更广的方法,又称“洲阁筛法”。事实上其更概括性的名称为“扩展埃式筛”。
但是这种筛法也有不足。首先是这个做法从 优化到 的过程中很多部分较难理解,初学者很难上手,其次是这个做法常数比较大,代码实现较复杂。但扩展埃式筛并不只有这一种做法。实际上,存在一种实现难度更低且在小范围数据下表现更好的做法。它与洲阁筛的思想类似,但理解较为容易。由于该算法由 使用后才开始普及,其也被称为 筛。
本文中讨论的扩展埃式筛即 筛。
什么是 筛?
时间复杂度
对于质数部分的计算,复杂度证明和洲阁筛完全相同。考虑每个 只会在枚举不超过 的质数时产生贡献。由定理 1.1,复杂度渐进地是
考虑首先将分母变成渐进的 ,然后只需要对分子积分,而这个处理是平凡的。可以写出
然后考虑统计答案部分。
定义 :对正整数 ,我们定义 为 最大的质因子, 为 最小的质因子, 为 的可重质因子个数。并令 。
如果我们直接按 的转移式 dp,空间复杂度 ,时间复杂度按质数部分的分析能得到 。
如果直接暴力计算呢?在小数据的测试下,该算法似乎比 更优秀一些。我们尝试分析该算法的复杂度。
考虑计算 时的递归。我们的时间复杂度就是进入递归的次数,即 被累加入答案的次数。对于从一个值开始的递归,我们不妨假设累加入的所有质数 处的贡献,实际上产生于 处,那我们将这次递归对复杂度的贡献计入 。 显然是 。由于每个函数值只统计一次更新,因此每次的 不同。同时 都会出现,因此该算法的复杂度就是 的 的个数。
引理 :对于给定的实常数 ,我们令 ,则 ,其中 为 Dickman 函数。
引理 :对于任意 , 随 增大而迅速衰减,。
查阅此处内容可以获得关于这两个引理的信息。
定理 :令 ,则对于任意 ,。
证明:
不妨取 。由引理知 。而 ,且 ,于是有 。
定理 :。
证明:
我们取前 个质数。令 表示第 个质数,最大质因子不超过 的(小于 的)数的个数不超过 。而其他 不超过 ,因此 。
由定理 ,。
所以这玩意是 的,但是实际跑出来的效果比较快?为啥?
引理 :
证明:
进行初等积分。
其中 为对数积分函数。由经典结论可知当 时 。然后证完。
考虑 。任何发现 没了的情况考虑 。
为容易理解,这里的推导和论文里有些许不同。
定理 :当 时,满足 的 至多有 个。
证明:
当 时,我们枚举每个 ,至多有 个满足条件的数,因此这部分贡献了 的复杂度。
打表可得,在 时,对于 的质数 ,满足 的数 的数量 。只有 个质数,因此这部分的复杂度也是 。
这就证明了定理。
因此我们能发现,这样执行的复杂度是 的。
素数的 次幂前缀和
先前的算法涉及到对素数处取值求前缀和的操作。复杂度是 。然而有时我们需要的只是 。这时我们存在更优的做法。下面复杂度的推导中不包括求 次幂的影响。
定义 (前缀和函数):对正整数 ,定义 为素数的 次幂前缀和函数,即 。特别的, 即为素数计数函数 。
定义 (部分筛函数):对正整数 ,定义部分筛函数 。当 时 。
定义 (特定筛函数):对正整数 ,定义特定筛函数 。
当 时,可以枚举质因子得到 。
则 。
由于 , 可以直接筛出来。我们现在只需要考虑 和 的计算。
关于
考虑 。 能贡献 ,当且仅当 ,且 。枚举 后计算 的贡献即可。
复杂度 。
关于
引理 :
显然。
定理 :
就是把引理 多用了几次。
不难(?)导出 。
首先朴素计算 的贡献,然后只需要考虑 的贡献。奇妙结论:
这式子可以建出递归对应的二叉树得到。
换元。令 。,也就导出了
阈值法。
可以朴素求解。我们计算出所有 ,随后枚举 统计。
由引理 ,有效状态是 的。
。
如果 不是素数,则由于 ,,这样的 不存在。
因此我们只需要考虑 为质数的情况。也就是说下面的讨论中 。
改变求和式为
,则根据定义有 。
改变求和式为
我们可以枚举 ,求 的贡献。筛出质数 次方和计算。复杂度 。
直接拿定义冲
于是问题来到了维护这边。
枚举 ,他能贡献的 满足 ,这里使用树状数组维护。数论分块维护 得到 的贡献。在树状数组上查询的次数是 的。
于是问题来到了复杂度这边。
首先是修改。
定理 :对于任意 , 以内恰有 个质因子且最小质因子不小于 的数的个数是 的。
证明:
即为定理 。
归纳法。假设 的所有情况都成立,现在证明 时同样成立。
进行初等积分:
感想:积分是用来分析的,不是用来创人的。
用渐进擦除了 ,把 前的负号提了出去。
归纳成立。
upd: 这个似乎是错的,因为积分出了问题,实际上应当趋于 。
我们在树状数组上进行操作的时候需要保证 的最小质因子不小于 。有用的 只有 种。乘入树状数组的复杂度后为 。
然后是查询。
定理 :。
证明:
进行初等积分:
这个挺好理解。
然后带入 可知询问次数是 的。带上树状数组就是 。
到这里分析完了计算 的所有情况,总时间复杂度总结一下就是 ,取 得到后半部分复杂度是 ,总复杂度还是 。
优化
可以发现复杂度瓶颈在 的查询部分。
于是问题又来到了维护这边。
抄式子:
我们进一步利用那个定理。分别考虑 是否为质数:
如果 是质数,若 ,则对所有满足条件的 来说 都有贡献。因此枚举 ,将质数部分统计完即可。复杂度 。
有 ,且存在 需要使得 ,则 。此时由定理 可知询问次数为 ,这部分不会影响复杂度。
因此喜提 的总复杂度。
指路【模板】Meissel–Lehmer 算法。
指路 OI Wiki。
最大的收获是重学积分(
约数函数前缀和
题面
定义 为 的约数个数,给定正整数 ,求 。
朴素转化
考虑转化
问题转化为拟合 下方的整点数。咋拟合呢?想到
和 序列
《具体数学里面应该有。》
不不不我还会说几句的
定义 ( 序列):将分母不超过 的 的最简分数从小到大排成一个序列,我们称它为 阶 序列。如果存在一个 序列使得 连续出现,则我们称这两个数字为 。
引理 :任意 是 ,当且仅当 。
证明:自己查。
在本文中,若 是 ,则称 也是 。容易发现引理 在此情况下仍然成立。
定义 ():见此处。

利用 切割曲线
每次用一条直线切割,统计直线下方的整点数。初始化就是经过 且斜率为 的直线。
得到一条直线后计算整点数可以直接用皮克定理,不展开。

坐标系的转换
考虑计算 。由于曲线在 和 上方,考虑令 分别为 轴。某个方向 相当于是向这个方向走到下一个接触到的整点。
定义有 ,因此对于 ,其在原坐标系下就是
由上,有 。由于 与 是 ,有 。因此 是整数。施于 得到 也是整数。
自然想到找 的对应。不妨令 ,则 。于是 。
曲线即为 。由于 ,该曲线上 与 一一对应。设 。我们能发现 在第一象限内都是形似 的凹函数。可以求导证明。
计算整点数
我们仍然找一条切凹函数且斜率为 的直线,统计它下方的整点数。我们设切点为 ,原系坐标是 ,新系坐标是 。随后找到两个整点 使得这两点在 坐标上极小地夹住 。形式化地,,。这两点显然存在且不同。
过 作切线的平行线 分别交 轴于 、交 轴与 。并设 ,,作 平行 交曲线于 。然后把折线 左下方(被染上橙色的区域,包括边界)的整点统计入答案。这段图形整体上斜率为 ,带换到 坐标系下斜率为 ,而通过 二分可以得到 是 ,这样可以接着切割了。
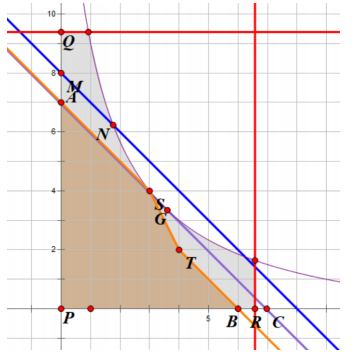
我们断言,任何未被统计的点,要么出现在 上方,要么出现在 右侧。因此可以递归 求解。
为啥这里是 不是 ?
时间复杂度
据说这个算法可以被证到 ,但是论文中只证到 。但总而言之,现在能够证明的是该算法的复杂度为 。
一篇论文中给出了一种 的做法:A Successive Approximation Algorithm for Computing the Divisor Summatory Function, Richard Sladkey, 2012。
论文里代码的实现
不保证正确性,代码效率低下
namespace calc {
int n;
double C1 = 4000, C2 = 10;
int delta(int i) { return i * (i + 1) / 2; }
int SR(int w, int h, int a1, int b1, int c1, int a2, int b2, int c2) {
int s = 0, a3 = a1 + a2, b3 = b1 + b2;
auto H = [&](int u, int v) {
return (b2 * (u + c1) - b1 * (v + c2)) * (a1 * (v + c2) - a2 * (u + c1));
};
auto U_tan = [&] {
return (int)(sqrtl( (a1 * b2 + b1 * a2 + 2 * a1 * b1) * (a1 * b2 + b1 * a2 + 2 * a1 * b1) * n / (a3 * b3) ) ) - c1;
};
auto V_floor = [&](int u) {
return (int)(((a1 * b2 + a2 * b1) * (u + c1) - ceil(sqrtl((u + c1) * (u + c1) - 4 * a1 * b1 * n))) / (2 * a1 * b1) - c2);
};
auto U_floor = [&](int v) {
return (int)(((a1 * b2 + a2 * b1) * (v + c2) - ceil(sqrtl((v + c2) * (v + c2) - 4 * a2 * b2 * n))) / (2 * a2 * b2) - c2);
};
auto SI = [&](int i_max, int p1, int p2, int q, int r) {
int s = 0, A = p1 * p1 - 2 * r * n, B = p1 * q, C = 2 * p1 - 1;
rep(i, 1, i_max - 1) {
C += 2, A += C, B += q;
s += (B - floor(sqrtl(A))) / r;
} return s - (i_max - 1) * p2;
};
auto SW = [&]() {
return SI(w, c1, c2, a1 * b2 + a2 * b1, 2 * a1 * b1);
};
auto SH = [&]() {
return SI(h, c2, c1, a1 * b2 + a2 * b1, 2 * a2 * b2);
};
if (h > 0 and H(w, 1) <= n) {
s = s + w, c2 ++, h --;
}
if (w > 0 and H(1, h) <= n) {
s = s + h, c1 ++, w --;
}
if (w <= C2) return s + SW();
if (h <= C2) return s + SH();
int u4 = U_tan(), v4 = V_floor(u4), u5 = u4 + 1, v5 = V_floor(u5);
int v6 = u4 + v4, u7 = u5 + v5;
auto SN = [&]() {
return delta(v6 - 1) - delta(v6 - u5) + delta(u7 - u5);
};
s += SN();
s += SR(u4, h - v6, a1, b1, c1, a3, b3, c1 + c2 + v6);
s += SR(w - u7, v5, a3, b3, c1 + c2 + u7, a2, b2, c2);
return s;
}
int calc() {
int x_min, x_max, y_min;
x_max = floor(sqrtl(n));
y_min = n / x_max;
x_min = min(x_max, ceil(C1 * pow(2 * n, 1. / 3)));
lll s = 0;
int a2 = 1, x2 = x_max, y2 = y_min, c2 = a2 * x2 + y2;
while (true) {
int a1 = a2 + 1;
int x4 = floor(sqrtl(n / a1)), y4 = n / x4, c4 = a1 * x4 + y4;
int x5 = x4 + 1, y5 = n / x5, c5 = a1 * x5 + y5;
if (x4 < x_min) break;
auto SM = [&]() {
return delta(c4 - c2 - x_min) - delta(c4 - c2 - x5) + delta(c5 - c2 - x5);
};
s = s + SM();
s = s + SR(a1 * x2 + y2 - c5, a2 * x5 + y5 - c2, a1, 1, c5, a2, 1, c2);
a2 = a1, x2 = x4, y2 = y4, c2 = c4;
}
auto SQ = [&](int x1, int x2) {
int s = 0, x = x2, bet = n / (x + 1), eps = n % (x + 1), delt = n / x - bet, gam = bet - x * delt;
while (x >= x1) {
eps += gam;
if (eps >= x) {
delt ++, gam -= x, eps -= x;
if (eps >= x) {
delt ++, gam -= x, eps -= x;
if (eps >= x) break;
}
} else if (eps < 0) {
delt --, gam += x, eps += x;
}
gam += 2 * delt, bet += delt, s += bet, x --;
}
eps = n % (x + 1), delt = n / x - bet, gam = bet - x * delt;
while (x >= x1) {
eps = eps + gam;
int delt2 = eps / x;
delt += delt2, eps -= x * delt2;
gam = gam + 2 * delt - x * delt2, bet += delt, s += bet, x --;
}
while (x >= x1) {
s += n / x, x --;
}
return s;
};
auto S1 = [&]() {
return SQ(1, x_min - 1);
};
auto S2 = [&]() {
return (x_max - x_min + 1) * y_min + delta(x_max - x_min);
};
auto S3 = [&]() {
int ret = 0;
rep(x, x_min, x2 - 1)
ret += (n / x) - (a2 * (x2 - x) + y2);
return ret;
};
s = s + S1() + S2() + S3();
return 2 * s - x_max * x_max;
}
}
int paper(int n) {
calc::n = n;
return calc::calc();
}
优化
我们发现,我们其实没有必要费时费力地切割原面积。其实问题可以转化为从 这个点开始拟合 的下半部分。我们需要拟合的面积是下图中红色虚线下方的阴影部分:
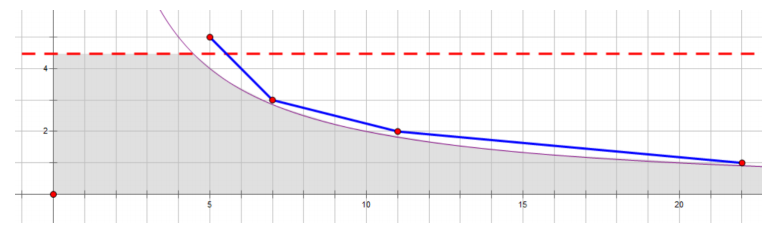
假设我们现在拟合到了 ,我们要选择一个不在阴影内且在当前点右侧的点 ,满足 最大且 最小的点,并将 到 的线段加入折线,在这过程中加入折线下整点数。
我们可以维护一棵 为初始值的 。每次拿出栈顶分数 ,从 移动到 (我们也可以将分数看作一个向量)。就这么一直移动直到再走一步会进入阴影中。然后把栈首弹出。接着对新的栈首执行上述操作直到栈首 不行,第二个元素 行的时候。
这时我们将栈首弹出,开始二分最接近斜率。
我们在 上走,设当前 ,考虑当 加入 时是否会进入阴影。
如果不会进入则 入栈,,接着二分。如果会进入,讨论一下。如果加入后斜率 ,那再怎么加都没用了,可以直接退出了。反之就令 。
栈的用处就是回溯到第一个合法位置。
然后复杂度和先前那个做法的证法类似,是 。
在 SPOJ 说他无法给出一个证明,灵感来源 PE540 的讨论区也无法给出。
但是他推测这个曲线的凸包上有 种斜率(每个形如 的区间上有 种。
所以他推测这种算法的时间复杂度有界 。
为了保证复杂度,当前点的 时停止迭代,开始朴素做法。
拓展
这里除了凸性外没有用到 的任何性质,也就是说这个做法可以自然推广到其他奇怪的凹曲线内部整点计数。
以下是博客签名,与正文无关。
请按如下方式引用此页:
本文作者 joke3579,原文链接:https://www.cnblogs.com/joke3579/p/paperessay221204.html。
遵循 CC BY-NC-SA 4.0 协议。
请读者尽量不要在评论区发布与博客内文完全无关的评论,视情况可能删除。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)