【Redis】Redis 持久化之 RDB 与 AOF 详解
Redis 持久化
我们知道Redis的数据是全部存储在内存中的,如果机器突然GG,那么数据就会全部丢失,因此需要有持久化机制来保证数据不会因为宕机而丢失。Redis 为我们提供了两种持久化方案,一种是基于快照,另外一种是基于 AOF 日志。接下来就来了解一下这两种方案。
操作系统与磁盘
首先我们需要知道 Redis 数据库在持久化中扮演了什么样的角色,为此我们先来了解数据从 Redis 中到磁盘的这一过程:
- 客户端向数据库发起 write 指令(数据在客户端的内存中);
- 数据库收到 write 指令和对应的写数据(数据在服务端内存中);
- 数据库调用将数据写入磁盘的系统调用函数(数据在系统内核缓冲区);
- 操作系统将写入缓冲区中的数据写到磁盘控制器中(数据在磁盘缓冲区中);
- 磁盘控制器将磁盘缓冲区中的数据写入磁盘的物理介质中(数据真正写入磁盘中)。
上面只是简要介绍了一下过程,毕竟真实的缓存级别只会比这更多。不过我们可以从上面了解到,数据库在持久化的过程中主要应该去实现步骤3,也就是将原本在内存中的数据持久化到操作系统的内核缓冲区中。至于下面的两步,则是操作系统需要关心的事,数据库无能为力。数据库通常仅在必要的时候会去调用将数据从内存写入磁盘的系统调用。
持久化方案
对于上面我们所述的持久化过程,Redis 提供了以下几种不同的持久化方案:
- 利用 RDB 持久化在指定的时间间隔生成数据集的时间点快照(point-in-time );
- 利用 AOF 持久化将服务器收到的所有写操作命令记录下来,并在服务器重新启动的时候,利用这些命令来恢复数据集。AOF 的命令使用的是与 Redis 本身协议的命令一致,通过追加的方式将数据写入备份文件中,同时当备份文件过大时,Redis 也能对备份文件进行重压缩。
- 如果仅希望数据只在数据库运行时存在,那么还可以完全禁用掉持久化机制;
- Redis还可以同时使用 AOF 持久化和 RDB 持久化。在这种情况下,当 AOF 重启时,会优先使用 AOF 文件去恢复原始数据。因为 AOF 中保存的数据通常比 RDB 中保存的数据更加完整。
接下来就重点讲解 RDB 持久化方案与 AOF 持久化方案之间的异同。
RDB 持久化
RDB(Redis Database) 通过快照的形式将数据保存到磁盘中。所谓快照,可以理解为在某一时间点将数据集拍照并保存下来。Redis 通过这种方式可以在指定的时间间隔或者执行特定命令时将当前系统中的数据保存备份,以二进制的形式写入磁盘中,默认文件名为dump.rdb。
RDB 的触发有三种机制,执行save命令;执行bgsave命令;在redis.config中配置自动化。
save 触发
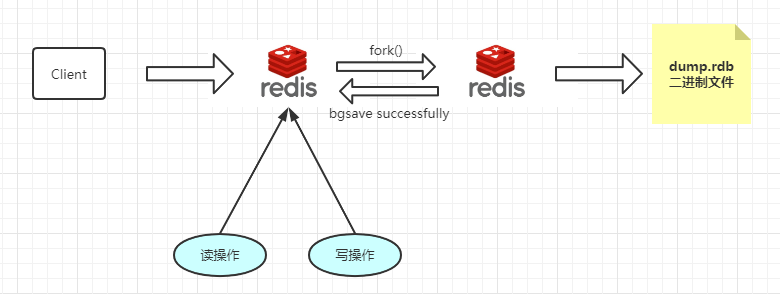
Redis是单线程程序,这个线程要同时负责多个客户端套接字的并发读写操作和内存结构的逻辑读写。而save命令会阻塞当前的Redis服务器,在执行该命令期间,Redis无法处理其他的命令,直到整个RDB过程完成为止,用一张图描述以下:

当这条指令执行完毕,将RDB文件保存下来后,才能继续去响应请求。这种方式用于新机器上数据的备份还好,如果用在生产上,那么简直是灾难,数据量过于庞大,阻塞的时间点过长。这种方式并不可取。
bgsave 触发
为了不阻塞线上的业务,那么Redis就必须一边持久化,一边响应客户端的请求。所以在执行bgsave时可以通过fork一个子进程,然后通过这个子进程来处理接下来所有的保存工作,父进程就可以继续响应请求而无需去关心I/O操作。
redis.config 配置
上述两种方式都需要我们在客户端中去执行save或者bgsave命令,在生产情况下我们更多地需要是自动化的触发机制,那么Redis就提供了这种机制,我们可以在redus.config中对持久化进行配置:
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
像上述这样在redis.config中进行配置,如save 900 1 是指在 900 秒内,如果有一个或一个以上的修改操作,那么就自动进行一次自动化备份;save 300 10同样意味着在 300 秒内如果有十次或以上的修改操作,那么就进行数据备份,依次类推。
如果你不想进行数据持久化,只希望数据只在数据库运行时存在于内存中,那么你可以通过 save ""禁止掉数据持久化。
这里再介绍几个在配置文件中与 RDB 持久化相关的系数:
stop-writes-on-bgsave-error:默认值为yes,即当最后一次 RDB 持久化保存文件失败后,拒绝接收数据。这样做的好处是可以让用户意识到数据并没有被成功地持久化,避免后续更严重的业务问题的发生;rdbcompression:默认值为yes,即代表将存储到磁盘中的快照进行压缩处理;rdbchecksum:默认值为yes,在快照存储完成后,我们还可以通过CRC64算法来对数据进行校验,这会提升一定的性能消耗;dbfilename:默认值为dump.rdb,即将快照存储命名为dump.rdb;dir:设置快照的存储路径。
COW机制
先前提到了Redis为了不阻塞线上业务,所以需要一边持久化一边响应客户端的请求,因此fork出一个子进程来处理这些保存工作。那么具体这个fork出来的子进程是如何做到使得Redis可以一边做持久化操作,一边做响应工作呢?这就涉及到COW (Copy On Write)机制,那我们具体讲解以下这个COW机制。
Redis在持久化的时候会去调用glibc的函数fork出一个子进程,快照持久化完成交由子进程来处理,父进程继续响应客户端的请求。而在子进程刚刚产生时,它其实使用的是父进程中的代码段和数据段。所以fork之后,kernel会将父进程中所有的内存页的权限都设置为read-only,然后子进程的地址空间指向父进程的地址空间。当父进程写内存时,CPU硬件检测到内存页是read-only的,就会触发页异常中断(page-fault),陷入 kernel 的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。而此时子进程相应的数据还是没有发生变化,依旧是进程产生时那一瞬间的数据,故而子进程可以安心地遍历数据,进行序列化写入磁盘了。
随着父进程修改操作的持续进行,越来越多的共享页面将会被分离出来,内存就会持续增长,但是也不会超过原有数据内存的两倍大小(Redis实例里的冷数据占的比例往往是比较高的,所以很少出现所有页面都被分离的情况)。
COW机制的好处很明显:首先可以减少分配和复制时带来的瞬时延迟,还可以减少不必要的资源分配。但是缺点也很明显:如果父进程接收到大量的写操作,那么将会产生大量的分页错误(页异常中断page-fault)。
RDB的优劣
相信通过上面内容的讲解,对于RDB持久化以该有一个大致的了解,那么接下来简单总结下RDB的优势以及它的劣势:
优势:
- RDB 是一个非常紧凑(compact)的文件(保存二进制数据),它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本;
- RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心;
- RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是
fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作; - RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势:
- 如果业务上需要尽量避免在服务器故障时丢失数据,那么 RDB 并不适合。 虽然 Redis 允许在设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 由于 RDB 文件需要保存整个数据集的状态, 所以这个过程并不快,可能会至少 5 分钟才能完成一次 RDB 文件保存。 在这种情况下, 一旦发生故障停机, 就可能会丢失好几分钟的数据。
- 每次保存 RDB 的时候,Redis 都要
fork()出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时,fork()可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行fork(),但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 持久化
The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log in the background when it gets too big.
RDB 持久化是全量备份,比较耗时,所以Redis就提供了一种更为高效地AOF(Append Only-file)持久化方案,简单描述它的工作原理:AOF日志存储的是Redis服务器指令序列,AOF只记录对内存进行修改的指令记录。
在服务器从新启动时,Redis就会利用 AOF 日志中记录的这些操作从新构建原始数据集。
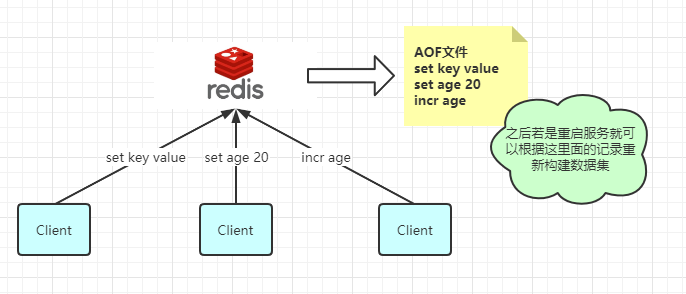
Redis会在收到客户端修改指令后,进行参数修改、逻辑处理,如果没有问题,就立即将该指令文本存储到 AOF 日志中,也就是说,先执行指令才将日志存盘。这点不同于 leveldb、hbase等存储引擎,它们都是先存储日志再做逻辑处理。
AOF 的触发配置
AOF也有不同的触发方案,这里简要描述以下三种触发方案:
- always:每次发生数据修改就会立即记录到磁盘文件中,这种方案的完整性好但是IO开销很大,性能较差;
- everysec:在每一秒中进行同步,速度有所提升。但是如果在一秒内宕机的话可能失去这一秒内的数据;
- no:默认配置,即不使用 AOF 持久化方案。
可以在redis.config中进行配置,appendonly no改换为yes,再通过注释或解注释appendfsync配置需要的方案:
############################## APPEND ONLY MODE ###############################
# By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information.
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# ... 省略
# appendfsync always
appendfsync everysec
# appendfsync no
AOF 重写机制
随着Redis的运行,AOF的日志会越来越长,如果实例宕机重启,那么重放整个AOF将会变得十分耗时,而在日志记录中,又有很多无意义的记录,比如我现在将一个数据 incr 一千次,那么就不需要去记录这1000次修改,只需要记录最后的值即可。所以就需要进行 AOF 重写。
Redis 提供了bgrewriteaof指令用于对AOF日志进行重写,该指令运行时会开辟一个子进程对内存进行遍历,然后将其转换为一系列的 Redis 的操作指令,再序列化到一个日志文件中。完成后再替换原有的AOF文件,至此完成。
同样的也可以在redis.config中对重写机制的触发进行配置:
通过将no-appendfsync-on-rewrite设置为yes,开启重写机制;auto-aof-rewrite-percentage 100意为比上次从写后文件大小增长了100%再次触发重写;
auto-aof-rewrite-min-size 64mb意为当文件至少要达到64mb才会触发制动重写。
# ... 省略
no-appendfsync-on-rewrite no
# Automatic rewrite of the append only file.
# ... 省略
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
重写也是会耗费资源的,所以当磁盘空间足够的时候,这里可以将 64mb 调整更大写,降低重写的频率,达到优化效果。
fsync 函数
再将AOF配置为appendfsync everysec之后,Redis在处理一条命令后,并不直接立即调用write将数据写入 AOF 文件,而是先将数据写入AOF buffer(server.aof_buf)。调用write和命令处理是分开的,Redis只在每次进入epoll_wait之前做 write 操作。
/* Write the append only file buffer on disk.
*
* Since we are required to write the AOF before replying to the client,
* and the only way the client socket can get a write is entering when the
* the event loop, we accumulate all the AOF writes in a memory
* buffer and write it on disk using this function just before entering
* the event loop again.
*
* About the 'force' argument:
*
* When the fsync policy is set to 'everysec' we may delay the flush if there
* is still an fsync() going on in the background thread, since for instance
* on Linux write(2) will be blocked by the background fsync anyway.
* When this happens we remember that there is some aof buffer to be
* flushed ASAP, and will try to do that in the serverCron() function.
*
* However if force is set to 1 we'll write regardless of the background
* fsync. */
#define AOF_WRITE_LOG_ERROR_RATE 30 /* Seconds between errors logging. */
void flushAppendOnlyFile(int force) {
// aofWrite 调用 write 将AOF buffer写入到AOF文件,处理了ENTR,其它没什么
ssize_t nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
/* Handle the AOF write error. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* We can't recover when the fsync policy is ALWAYS since the
* reply for the client is already in the output buffers, and we
* have the contract with the user that on acknowledged write data
* is synced on disk. */
serverLog(LL_WARNING,"Can't recover from AOF write error when the AOF fsync policy is 'always'. Exiting...");
exit(1);
} else {
return; /* We'll try again on the next call... */
} else {
/* Successful write(2). If AOF was in error state, restore the
* OK state and log the event. */
}
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
// redis_fsync是一个宏,Linux实际为fdatasync,其它为fsync
// 所以最好不要将redis.conf中的appendfsync设置为always,这极影响性能
redis_fsync(server.aof_fd); /* Let's try to get this data on the disk */
}
else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC && server.unixtime > server.aof_last_fsync)) {
// 如果已在sync状态,则不再重复
// BIO线程会间隔设置sync_in_progress
// if (server.aof_fsync == AOF_FSYNC_EVERYSEC)
// sync_in_progress = bioPendingJobsOfType(BIO_AOF_FSYNC) != 0;
if (!sync_in_progress)
// everysec性能并不那么糟糕,因为它:后台方式执行fsync。
// Redis并不是严格意义上的单线程,实际上它创建一组BIO线程,专门处理阻塞和慢操作
// 这些操作就包括FSYNC,另外还有关闭文件和内存的free两个操作。
// 不像always,EVERYSEC模式并不立即调用fsync,
// 而是将这个操作丢给了BIO线程异步执行,
// BIO线程在进程启动时被创建,两者间通过bio_jobs和bio_pending两个
// 全局对象交互,其中主线程负责写,BIO线程负责消费。
aof_background_fsync(server.aof_fd);
server.aof_last_fsync = server.unixtime;
}
}
Redis另外的两种策略,一个是永不调用 fsync,让操作系统来决定合适同步磁盘,这样做很不安全;另一个是来一个指令就调用 fsync 一次,这种导致结果非常慢。这两种策略在生产环境中基本都不会使用,了解一下即可。
AOF 的优劣
- AOF 持久化的默认策略为每秒钟
fsync一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多也只会丢失掉一秒钟内的数据; - AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行
seek, 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等),redis-check-aof工具也可以轻易地修复这种问题。 - Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的
fsync策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒fsync的性能依然非常高, 而关闭fsync可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。 - AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。
混合持久化
重启 Redis 时,如果使用 RDB 来恢复内存状态,会丢失大量数据。而如果只使用 AOF 日志重放,那么效率又太过于低下。Redis 4.0 提供了混合持久化方案,将 RDB 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自 RDB 持久化开始到持久化结束这段时间发生的增量 AOF 日志,通常这部分日志很小。

于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志,就可以完全替代之前的 AOF 全量重放,重启效率因此得到大幅提升。
参考文章
- 【Redis Persistence】;
- 【Redis persistence demystified】;
- 【Redis的appendfsync参数详解】;
- 《Redis深度历险 核心原理与应用实践》;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号