
Q-learning算法介绍(1)
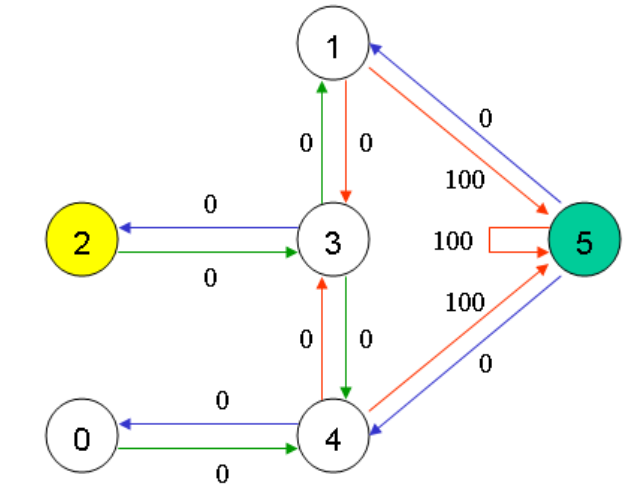
我们在这里使用一个简单的例子来介绍Q-learning的工作原理。下图是一个房间的俯视图,我们的智能体agent要通过非监督式学习来了解这个陌生的环境。图中的0到4分别对应一个房间,5对应的是建筑物周围的环境。如果房间之间有一个门,那么这2个房间就是直接相通的,否则就要通过其他房间相通。
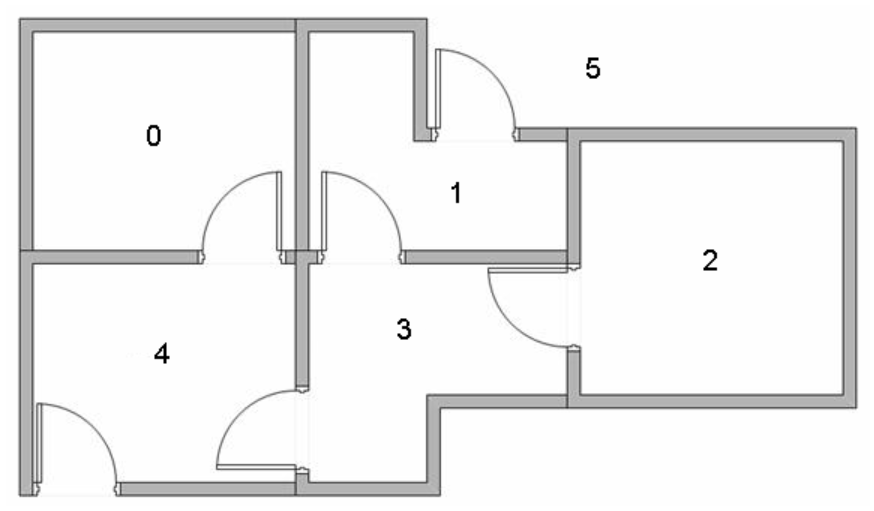
下面的这个示意图就表示房间的相通性。
在这个例子中,我们的任务是把智能体(agent)放到任何的一个房间中,然后让它通过自己学习从房间中走出来,到周围环境5中。
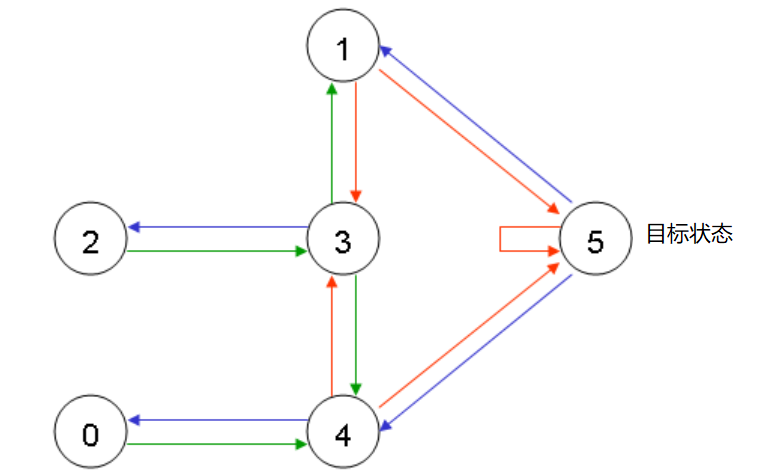
为了完成这个任务,我们要给每个门一个奖励值(reward)。我们的分配方法是这样的:
- 让智能体直接走到外部环境中(目标状态)5的门将有一个100的奖励值;
- 所有其他门的奖励值为0. (如下图所示)
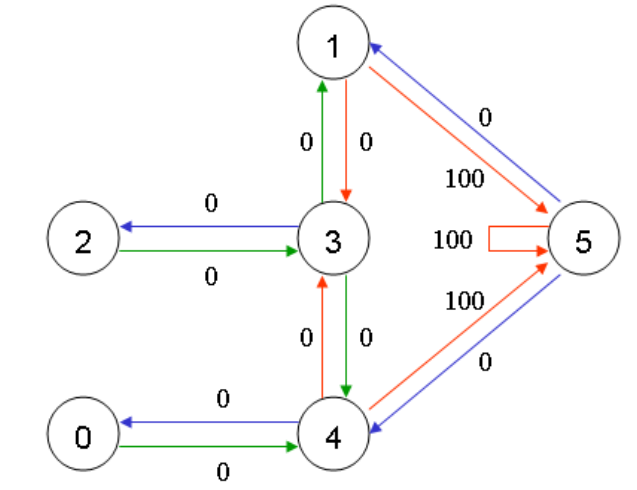
上图中显示,如果智能体停留在外面也可以获得100的奖励。我们知道Q-learning的最终目标是让智能体进入目标状态,同时获得最高的奖励。在我们的例子中,我们的智能体对这个环境一无所知,也不知道通过走哪几个门可以走到外部环境中,但是它可以通过实际经验进行学习。
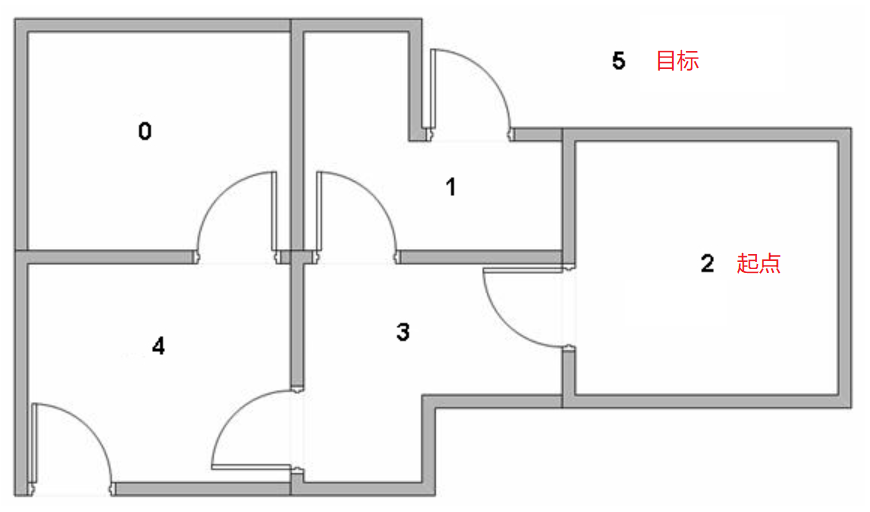
现在我们把智能体放到2号房间,让它通过学习走到外部环境5中。在加强式学习中,我们经常提到状态(state)和动作(action)这2个概念。所以,智能体在每个房间中就对应一个状态,而当它从一个房间到达另一个房间就对应一个动作。如下图所示:
如果把它转换成奖励矩阵R,R就是一个6x6的矩阵
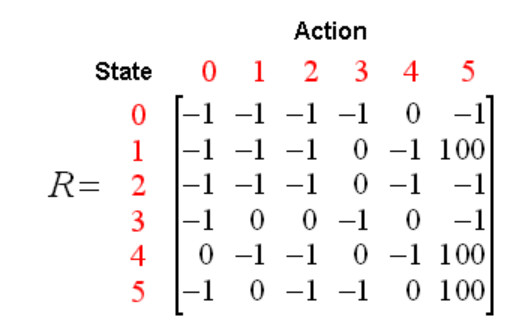
R矩阵中的-1代表从一个房间无法直接到达另一个对应的房间。现在,我们就可以开始创建我们的Q矩阵了,也可以称它为Q-table。这个Q-table中的信息就代表智能体在学习过程中不断获得的知识或经验。跟R矩阵类似,Q-table中的每一行对应一个状态,每一列对应一个动作。智能体在开始学习的时候,对环境一无所知,所以Q-table中的所有值都被初始化为0。在agent的学习过程中,这个Q-table会被不停的更新,更新的方法就是下面的公式:
Q(state, action) = R(state, action) + Gamma * Max[Q(next possible state1, action1), Q(next possible state2, action2), Q(next possible state3, action3), ... ]
其中Q(state, action)是Q-table中对应state和action的那个单元值,其更新的方法就是把它对应的R矩阵中的值 + 所有可能的下一个状态和其对应动作在Q-table中对应值中最大的那个 x 系数Gamma(我们后面再讨论这个Gamma系数)。这样我们的智能体就可以在没有老师的情况下自我学习,直到它进入目标状态。智能体的每一次完整的尝试(从任何开始状态进入目标状态)被称为一个迭代或回合(episode);而每一次迭代完成后,算法会开始新的一次迭代。Q-learning算法包括下面的步骤:
- 初始化Gamma值和R矩阵的所有值;
- 初始化Q-table中的所有值为0;
- 在每次迭代中:
- 随机选择一个起始状态;
- 如果智能体还没有进入目标状态,则继续
- 从当前状态下所有可能的动作中选择一个给出最大Q值的那对动作和状态(next state i,action i);
- 把当前的Q(state, action)值更新为R(state, action) + Gamma * 上面得到的最大Q(next state i,action i)值;
- 把上面对应的next state i变为现在的状态;
- 如果现在状态不是目标状态,则继续更新;否则就终止当前的迭代。
上面的算法让智能体从实践中学习,每一个迭代都是一次完整的训练。在每一次训练中,智能体都对环境(由R矩阵表示)进行一次探索学习,得到奖励,得到目标状态。而训练的目的则是提高智能体的智能(由Q-table表示),训练的次数越多,智能体的‘大脑’就越聪明。
下面我们就谈谈这个Gamma系数:Gamma是一个介于0到1之间的一个值,Gamma越接近0,智能体越是会考虑寻找最短最快的路径;如果Gamma接近1,智能体则会更多的考虑未来比较高的奖励(路径长度不是首要考虑因素)。
当这个Q-table建好之后,智能体只需要比较所有从开始状态到目标状态的路径,从中选择出最大奖励值的那个,算法步骤如下:
- 把起始状态设为当前状态;
- 从当前状态下,从Q-table中找出给出最大Q值的动作;
- 然后把当前状态改为由上面动作进入的那个状态;
- 进行重复2和3,直到智能体进入目标状态;
上面算法的结果就会给出从开始状态到达目标状态的动作序列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号