
Deep Learning with Python 读书笔记(七)使用深度学习算法解决问题的通用框架
我们在这篇随笔中讨论一下使用深度学习的方法来解决问题的通用框架,这个框架适合绝大多数的问题,当然不排除个别的特例,如用深度学习算法编写围棋对弈的算法、编写金融市场的交易算法、对服装流行趋势的预测等等。但是对于绝大多数的分类问题、回归问题、图像语音识别问题,这个框架仍然对我们有着很好的指导作用。要理解和很好的使用这个框架,你必须有个清晰的问题描述、对模型进行评估的标准、必要的特征工程方法(feature engineering)和防止过度拟合的应对策略。
1. 问题描述和数据采集:
首先你要清楚地描述手中的问题:你的输入数据是什么?你要预测什么?要知道你必须先有训练数据,然后才能进行学习和预测。比如,你首先要有人们对一部电影的评论数据,才能训练你的模型,让它对其他电影评论进行分类 - 正面还是负面。在这一步,训练数据的获得就是最大的限制因素。
另外,你手中的问题是什么性质的问题?是二元分类还是多元分类?是标量、矢量还是张量回归?是聚类分析还是强化式学习?搞清楚这个问题是你选择模型结构和损失函数的必要条件。同时你还要知道你手中的数据不一定能保证你会得出你所期待的预测结果,因为如果你的训练数据中根本没有足够的输入-输出数据的关联信息,你的模型是没有办法捕捉到它的。例如你有某只股票价格近期变动的数据,你是没有办法预测接下来的股价变动情况的,因为股票的历史数据本身就没有包含跟股价未来变化的任何关联信息。
有一种目前不好解决的问题被称作‘非稳定问题’,如前面提到的对服装流行趋势的预测问题。假如我们有8月份一个月的流行服饰数据,然后你想得到12月份的流行趋势分析。这里的一个主要问题是人们购买服装的行为根据季节的变化而变化,因为人们在几个月内购买服装的行为是一个非稳定问题,因为这种购买行为随着时间会改变。因此一个比较好的办法是使用近来的数据不断的对模型进行重训练,或者得到时间跨度更大的数据,使得这个问题变成一个‘稳定性问题’,但是不要忘了,这时候时间已经是模型输入数据的一部分了。记住,机器学习只能学习输入数据中包含的规律和模式,在预测的时候发现并使用它们。因此,我们的一个重要假设是利用过去的数据来预测未来,但是这个假设有时候是不成立的。
2. 选好对模型进行评估的标准:
我们知道要控制一件事情,必须先能观察这件事情。要想获得成功,必须先知道成功是什么 – 准确率?客户的低流失率?明确了这个你才能去有针对性的选择损失函数和你的模型要不断优化的对象。这一切一定要和你的目标相符,也就是你最终的商业目标。
如果你的问题是一个均衡的分类问题,也就是几种分类的概率大致均等,这时候准确率和ROC AUC就是通常的衡量标准;对于非均衡的分类问题,你可以使用precision和recall作为衡量标准;对于多标签的分类问题,你可以考虑使用mean average precision;也有很多时候,你需要定义自己的衡量标准,这种情况也经常发生。因此了解不同的问题已经相对应的成功衡量标准也是非常重要的事情。
3. 确定模型评估的方法:
一旦你确定了问题,明确了目标,接下来你要知道如何对模型进行评估的方法。我们之前讨论过3种常用的评估方法:
4. 准备好所需的数据:
当前面的3步确定好了,你就可以大致开始模型训练过程了。但是在你把数据输入给模型之前,你要保证输入数据的格式可以被模型所接受。现在让我们拿一个多层神经网络为例进行说明:
首先你的数据需要变成张量形式;
然后把里面所有的数值转到一个标准的区间里,比如[0,1]或[-1, 1];
如需要,对数据进行特征工程处理。
5. 制作一个优于随机平均概率的预测模型:
在这个阶段,你的目标应该是先建一个简单的模型,而且只要求这个模型稍微好过随机的猜测。不要小看这个能力,优于随机猜测的预测能力有个好听的名字,叫statistical power,也就是说你的起点应该是一个拥有statistical power的模型。以MNIST识别手写数字的模型为例,如果它识别每个0-9的手写数字的准确率都高过10%的话,那么这个模型就拥有这个statistical power。
让一个模型至少拥有这个能力不是一件总可以实现的事情。如果你发现在尝试了多个不同的模型之后,你的模型还是没有比随机猜测的结果好多少,那说明你的输入数据可能有问题,可能根本没有你所需要的关联信息,前面我们也提到过这点。如果你碰上这种情况,你可能需要重新从第一步开始。
现在假设你的模型比随机猜测的结果要好,接着你要考虑下面3个问题:
- 模型最后一层的激活函数:这一层会对模型输出值做出限定,如二元分类问题的输出层使用的是sigmoid激活函数。关于常用的激活函数选择可以参看下表
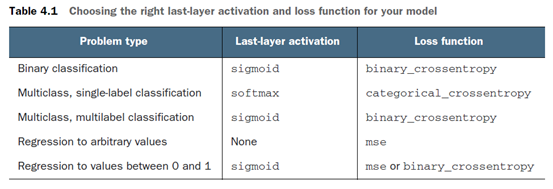
- 损失函数:这个根据你手中的问题性质来决定,如二元分类可以用binary crossentropy;如果是回归问题,你可以用mse等等。
- 优化器:选择哪个优化器?learning rate是多少?如果你没有特别的考虑,可以使用rmsprop优化器和它的默认设置参数。
6. 确保你的模型会过度拟合:
当你的模型至少拥有statistical power之后,接下来的问就是它是否拥有很好的预测能力?是否有足够的层数和模型参数,让它很好地模型化手中的问题?例如在识别手写数字的问题上,你只有一个隐蔽层,而且它只有2个单元,这个模型应该拥有statistical power,但是它对手写数字的识别能力不会太好。我们前面说过,机器学习的一个核心问题是解决优化和过度拟合的平衡问题,因此最理想的模型就是恰好在二者间的最佳平衡点上。要想找到这个平衡点,我们就要先跨过它,然后才知道它在哪里,所以我们就要先看到模型从哪里开始过度拟合。使用的手段如下:
- 增加模型的层数
- 增加每一层的单元数
- 多次训练并观察输出结果的不同
一旦发现了开始过度拟合的点,你就可以对模型进行正则化,并微调模型的参数,从而让你的模型接近你所期待的性能。
7. 模型正则化(regularization )和调整模型的超参数(hyperparameter):
这一步最花费时间,你要不断的修改、训练、评估你的模型,直到模型已经不能继续优化。你可以尝试的方法包括:使用Dropout方法、尝试不同的模型结构、增加或减少层数、调整模型的超参数(如每层的单元数、学习率等)、使用L1或L2正则化、增加或减少数据特征。
这里需要重复一点,每次你根据评估的反馈结果对模型进行调整的时候,你的模型会保留一些评估数据集种的某些信息。如果你多次使用评估数据对模型进行修改,那么你的模型很可能会针对评估数据过拟合。这样的化,你的评估过程反而对优化起了反作用。如果是这样,你需要考虑使用一种不同的评估方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号