Deep Learning with Python 读书笔记(二)机器学习历史回顾
虽然深度学习在近几年取得了不小的成功,也得到了业界的广泛关注,但是深度学习并不是机器学习中唯一最好的解决问题的方法。在我们深入学习深度学习之前,简单的了解机器学习中其他的方法非常必要,这样帮助我们避免把所有机器学习问题都尝试用深度学习算法去解决的错误想法。
1. 概率模型
简单的说,概率模型就是把统计学的知识用来解决数据分析问题的应用。这是一种最早出现的机器学习形式,直到今天还在业界被广泛使用,如贝叶斯算法就是一个例子。另外一个例子是逻辑回归(logistic regression),用来解决分类问题。
2. 早期的神经网络
神经网络的一些核心想法早在上世纪50年代就已经出现,但是真正的实现却经历了几十年的过程,其中的一个主要原因是人们没有一个很好的训练大型神经网络的方法。直到80年代中期,几位科学家几乎同时发现了反向传播(Back propagation)算法,使得训练一连串的参数调整操作成为可能,其中使用的优化算法就是我们现在知道的梯度下降(Gradient descent)算法。
这种神经网络的第一次大显身手是1990年用在美国邮政系统里识别手写邮编号码的应用,这个应用就是使用了贝尔实验室的Yann LeCun开发的LeNet。
3. 核方法(Kernel Methods)
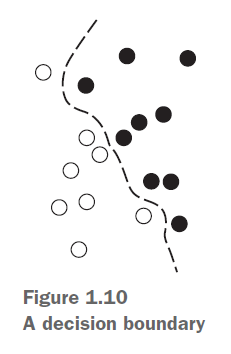
虽然早期的神经网络在90年代初获得了不小的成功,但是随着机器学习中一个崭新方法的出现,神经网络很快又在行业内销声匿迹了,这种崭新的方法就是核方法,其中一个最知名的算法就是支持向量机(SVM或Support Vector Machine)。支持向量机是通过找到数据间最好的决策边界(Decision Boundary)来解决分类问题。
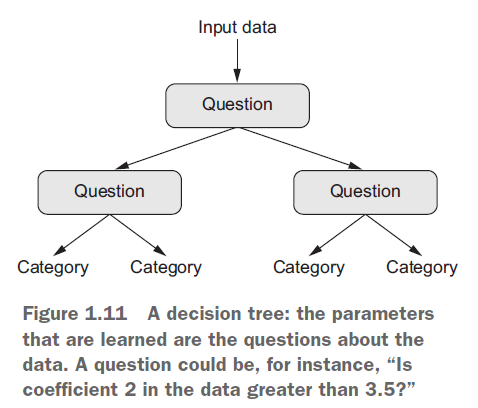
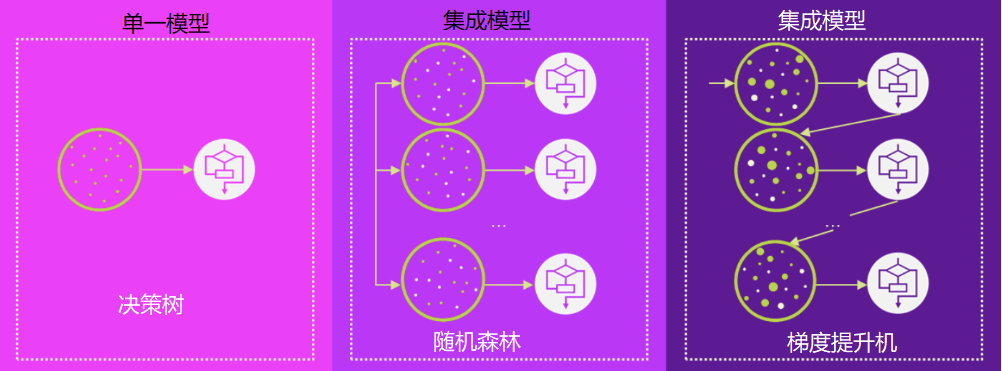
4. 决策树、随机森林、梯度提升机(Decision Tree,Random Forests,Gradient Boosting Machine)
决策树看起来好像一个流程图,可以让我们方便的对输入数据进行分类或根据输入数据去预测相应的输出数据(见下图)。决策树在2000年开始引起研究人员的关注,但是到了2010年左右,继续关注决策树的研究人员越来越少,更多人的注意力逐渐转到了核方法上面。
随机森林建立在决策树的基础上,它通过把多个互不关联的决策树集合在一起,通过一种类似“投票表决”的方式,来获得准确的预测结果。实践表明,这种集合算法的结果往往优于单个决策树算法得出的结果。在2010年起步的机器学习竞赛平台Kaggle上,随机森林一直独占鳌头,直到2014年左右才被梯度提升机算法胜出。
梯度提升机(Gradient Boosting Machine)和随机森林一样,也是一种集成方法(Ensemble Method)。集成方法就是把多个机器学习模型放到一起,让“大家的智慧胜出其中任何一个模型的智慧”,从而提高预测的准确度。但是和随机森林不同的是,梯度提升机是依次根据前面模型的预测结果和预期结果之间的差距来对目前模型进行优化,而随机森林的所有参与模型都是互不相关的,它的最终预测结果只是所有参与模型的预测结果平均值或者它们投票表决来决定的最终结果。所以,梯度提升机的准确度往往好过随机森林的准确度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号