Redis知识梳理(2)当我们谈到string的时候,我们在谈什么?
数据结构
Redis中的string数据类型的数据结构类似Java中的ArrayList,是一个字符数组。
扩容机制
当字符串大小 > 1MB的时候,每次扩容都会扩容一倍。当字符串大小 < 1MB的时候,每次扩容就扩容1MB。Redis约定Redis中的String大小最大为512MB
计数器
如果Redis中的String存储的值的类型是num,那么可以使其自增。但是自增的最大值为Long.MAX_VALUE
可修改性
Redis你给的字符串是可修改的,换而言之,他不是每次赋值或者修改都是重新建一个String对象在内容中。
源码分析
struct SDS<T> {
T capacity; // 数组的容量
T len; // 数组的长度
byte flags; // 数组的特殊标志位
byte[] content; // 数组的内容
}
创建字符串的时候,初始化的数组容量和数组的长度是一样的长的。
存储方式
redis中String又两种存储方式:
- embstr
- raw
(如果希望查看redis中的String使用了那种存储方式可以通过debug object keyName的方式来进行查询)
redis1.cluster.oilchem.local:0>set test77 01234567890123456789012345678901234567891234
"OK"
redis1.cluster.oilchem.local:0>debug object test77
"Value at:0x7f2dadae5240 refcount:1 encoding:embstr serializedlength:22 lru:13329039 lru_seconds_idle:1"
redis1.cluster.oilchem.local:0>set test77 012345678901234567890123456789012345678912345
"OK"
redis1.cluster.oilchem.local:0>debug object test77
"Value at:0x7f2d98961060 refcount:1 encoding:raw serializedlength:23 lru:13328992 lru_seconds_idle:2"
根据上面的例子可以看出,当字符串的内容长度超过44之后,string 的存储方式会从embstr转换为raw。但是为什么分界值是44呢?
为了解释这种现象,需要先了解一下Redis对象的定义
struct RedisObject {
int4 type; // 4bit 对象的类型
int4 encoding; // 4bit 对象的存储形式
int24 lru; // 24bit LRU信息
int32 refcount; // 4bytes 引用计数器,其为0时,对象被回收
void *prt; // 8bytes 64-system 指针,指向对象内容存储位置
} robj; // 其总大小是为16 bytes
接着你来看一下SDS结构体的大小,存储字符串比较小的时候,SDS对象头结构大小为3字节
struct SDS{
int8 capacity; // 8bit 数组的容量
int8 len; // 8bit 数组长度
int8 flags; // 8bit 特殊标志位
byte[] content;
} // 其总大小为 3byte
这意味着分配一个字符串的最小空间占用为 16bytes + 3bytes = 19bytes
Redis认为一个字符串总体超出了64字节为一个大字符串,不适合使用embstr,那当内存分配了64字节空间的时候,字符串的最大长度为:
64bytes - 19bytes = 45bytes;
但SDS结构体中content中的字符串是以字节null结尾的字符串,所以embstr的最大能容纳的字符串长度为
64bytes - 19bytes - 1bytes = 44bytes;
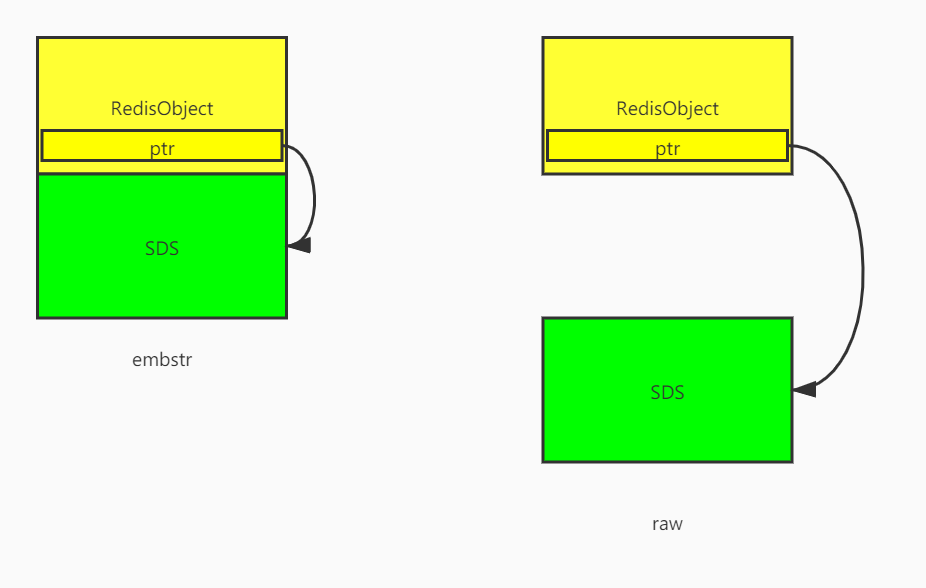
embstr和raw在内存上的区别
embstr,它将RedisObject对象头结构和SDS对象连续存储在一起的,使用malloc方法一次分配:
raw的存储形式不一样,它想需要使用两次malloc方法,两个对象头在内存地址上一般是不连续:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号