
简单谈下FPGA是如何实现硬件加速的
CNN神经网络算法刚出来的时候,就采用了FPGA作为物理机来实现,为何会率先采用FPGA作为算法加速器而非通用CPU,本文谈谈个人的理解。
首先明确FPGA与通用CPU的区别,CPU里设置流水线结构,而FPGA则是采用自定制的并行结构。就比如CPU最经典的5级流水线结构,一条指令的操作过程可以拆分为取指、译码、执行、访存、写回五个独立的子指令,通过流水线架构,使5条流水线分别执行上述5个独立指令,从而确保在每个时钟周期内执行一条指令。而FPGA则是一片白纸,用户可以自己需求增加同倍硬件资源,且增加的硬件资源可在同一时钟下进行并行运算,实现处理能力的成本增长。
以一个简单的c程序为例,
for(i=0;i<10;i++) x[i] = a[i] + b[i];
for循环下的加法运算,如果采用上述5级流水线架构的CPU,执行完一次 x=a+b运算需要一个时钟周期(5级流水线完成5条子指令),那么整个算法执行完成需要10个硬件周期。而使用FPGA来做上述运算,一般地,FPGA会直接把上述算法直接复制十份,就如下图所示
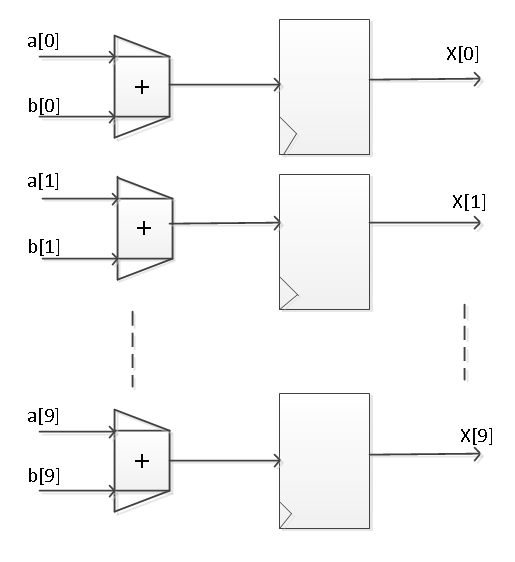
因为之前说过FPGA就是一张白纸,用户可以自己按需求使用它的硬件资源,如果采用上图所示的方法,则FPGA实现上述算法只需要一个硬件时钟周期。即计算时间对比5级流水架构的CPU缩减至其1/10。
当然,根据用户需要,可以采用5倍,2倍的硬件资源来做这部分的算法,而将多出来的硬件资源用于更加核心的算法部分。

