

python字符串
Python 3 之后的版本里,字符串使用Unicode编码,即支持多语言。
对于单个字符的编码,Python提供ord ( ) 函数获取字符的整数表示 , chr()函数把编码转换成对应的字符
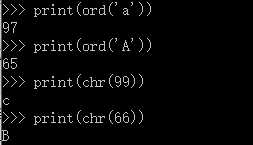
知道字符的整数编码还可以用十六进制写(反人类)
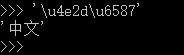
Python字符串类型是str,内存中以Unicode表示,一个字符对应若干个字节,传输或保存的时候需要把 str 变成 bytes ,对于bytes类型的数据用前缀 b 跟单引号或双引号字符串。
举例: x=b'ABC'
(稍微)详解:‘ABC’ 是 str,占用字节大于1,b'ABC'的'ABC'占用1个字节
以Unicode表示的str 通过 encode()方法可以编码为指定的bytes,但是需要遵循编码规定,ASCII编码不能转中文,会报错的哦。 bytes中,无法显示的ASCII字符会以 \x## 表示

反之,decode()可以把bytes变成str
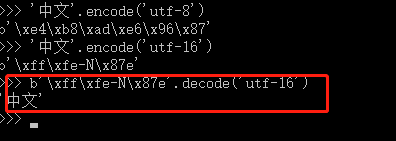
记得前缀 b 才是表示bytes
如果bytes包含无法解码的字节,decode()方法会报错


如果已知bytes中只有一小部分字节无效,可以传入 errors='ignore' 忽略错误字节

计算str 有多少字符,可以使用 len()函数 注意:是字符数,ABC就是三个,'中文'就是两个,字面意思
计算bytes有多少字符,也可以使用 len()函数,这时就是计算字节数的时候了



可以看出来,utf-8下英文字符及特殊符号是占一个字节的,中文就是三个字节 (包括中文特殊符号,……是6个,¥3个)
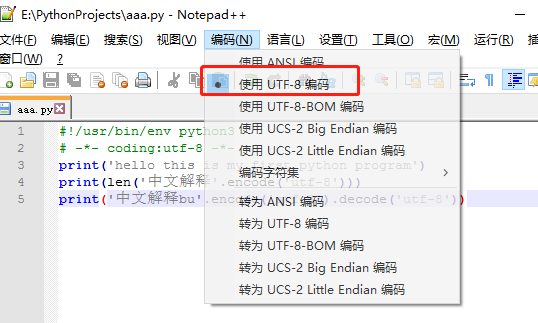
Python源代码都是文本文件,编码过程要坚持使用utf-8编码,保存时务必声明保存为utf-8编码才行。当解释器读取到源代码时,会按照开头的声明进行解码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-

第一行注释为了告诉Linux\OS X系统,这是一个可执行的Python程序,但由于Windows不能直接运行.py文件所以会自动忽略
第二行告诉python解释器,按照utf-8 编码读取源代码,否则中文可能会乱码
注意:声明解释编码为utf-8并不意味着.py 文件一定是utf-8编码,一定确定文本编辑器正在使用的是utf-8 without BOM编码(中文直接叫utf-8编码),这样保存的中文解释器解释后才会是保存进去的中文
格式化字符串
有固定模板,需要动态填充某些不一样的东西,需要用到格式化。举例:短信 尊敬的XXX用户您好,余额为XXX元,该充钱了。XX年XX月XX日
%运算符 %s使用字符串替换,%d用整数替换, 有几个 %? 占位符后面就跟几个变量,顺序要对好,不然会报错
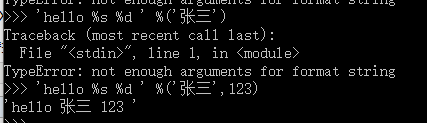
只有一个 %? 时可以不用带括号 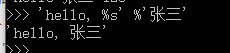
格式化整数和浮点数还可以制定是否补0 和整数与小数的位数: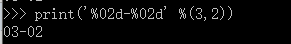
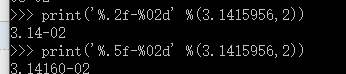
不同的是,整数补0要在%后跟一个0,至于能不能补两个,至少目前看来这种格式化的方式并不能:
在不确定要补什么东西的时候,%s是最好的选择,可以把任何类型数据转换成字符串: 注意布尔类型哈,会被转成“True”而不是0或者1
注意布尔类型哈,会被转成“True”而不是0或者1
同样,需要注意转义,用%放在转需要转义的字符前(一般指“%”):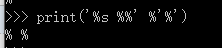
另一种格式化的方式:format() 占位符为 {0} 、 {1} 、{2} 


 浙公网安备 33010602011771号
浙公网安备 33010602011771号