
字符串编码
上午搞点轻松的东西
1 字符编码
概念解释:
编码的概念:按照何种规则将字符存储在计算机中(比如'a'这个字符用什么表示 :121或者88)称为编码
解码的概念:将编码好的字符解析成其原本要表示的字符(比如将121解析成'a')
字符集的概念:系统所支持的所有抽象字符的集合,包括各个国家的文字标点图形符号数字
字符编码:通俗来说就是编码过程所使用的规则(可以理解为加密的秘钥或者对应关系)。 是一套法则,使用该法则可以对某一套自然语言(不限类别,可以是任意想要表达的东西) 与 其他东西的一个特定集合进行配对。参照战争中的电报密码可以理解。官方点说法为:字符编码是定义在字符集上的映射规则
对字符编码是信息处理的基本技术之一,人类使用符号表达信息,但计算机只能根据 元器件的不同状态的组合进行存储信息(0-1状态),元器件不同的状态的组合能代表数字,所以字符编码就是把人类的符号转换成计算机可以接受的数字系统的数字(称为数字代码),即所有的(面向计算机的)字符编码的最终目的都是将人类的语言转换成 0-1 组合
字符集和字符编码的关系:字符集=字库表+编码字符集+字符编码
字库表:“所有可读或者可显示字符的数据库(怎么理解自己看着办,反正不是很重要),字库决定了整个字符集能展现的所有字符的范围“
编码字符集:简称字符集。就是编码好的字符的集合
字节:最早使用 8bit 作为一个字节(1byte),一个字节最多能表示的整数是255(11111111),两个字节最多能表示的整数是65535(11111111 11111111),还可以有更多字节以此类推
常见的编码和字符集(字符集):
ASCII: 》》》既是编码,又是字符集《《《 老美发明出来的,一个字节,最早只有127个字符被编码,大小写英文字母,数字跟一些符号
GB2312 :》》》既是编码,又是字符集《《《 中文,两个字节,不兼容小于127的英文字符,完全不占用0-127(【129-255】【129-255】)
GBK 编码:完美兼容GB2312+ASCII,两个字节, 当 首位小于127时判定为英文字符,第二位不判定(ASCII一位编码),首位大于127时判定中文,读取第二位。共收录汉字21003个,符号883个,提供1894个造字位
ANSI(本地字符集):与本机语言设置有关,中文机的ANSI就是GBK,日文机的ANSI就是jis。就是因为这个东西跨国交流时文本编码通常会造成很大的麻烦
Unicode 字符集(统一码,万国码):解决国际化问题,全世界通用码表。容量 2^32(40亿+)(4个字节),常用的字符通常在前65535个里,与ASCII不兼容(通常来说字符只用到了最低两位,所以简单表示的时候可以将高位的0无视掉,PS:传输时可能更快,因为节省了三个字节)
注意:Unicode只是一个字符集,并不是具体的编码格式,只是负责分配编号(可以理解为工作就是将其他编码已经编好的完成字符 进行再处理 比如给大家都在高位补0凑够4个字节?)
本质上讲,Unicode字符集是用来统一编码,防止解码后出现乱码导致沟通出现问题,出发点是好的,但是如果文本基本全都是英文的情况下使用Unicode字符集会比AscII字符集多占用一倍的空间(参照字节长度),传输和存储上显然不划算,因此出现了UTF-8以及UTF-16编码。
UTF-8编码:专门用来简化Unicode,不是定长的哦,定长就没有意义了,因为Unicode是个4字节的字符集,不定哪个字符多长,而要做到简化就必须取最简,就不能规定长度。UTF-8把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,个别极其生僻的字符被编码成4-6个字节。
(每)一个字节的前1-3个bit 是描述部分,后面的是实际序号部分:
--一个字节的第一位为0,表示当前字符为单字节字符,占用一个字节空间,0之后的7个bit代表在Unicode中的编码序号
--一个字节以110开头,代表当前字符为双字节字符,占用两个字节空间,110之后的 5个bit 加上 后一个字节的除10外的6个bit 代表Unicode中的序号,且第二个字节一定以10开头
--一个字节以1110开头,代表当前字符为三字节字符,占用三个字节的空间,110之后的 5个bit 加上 后两个字节除10外的6+6个bit 代表Unicode中的序号,且第二第三个字节一定以10开头
--一个字节以10开头,代表当前字节为多字节字符的第二个字符,10之后的6个bit 和 之前的一部分 代表Unicode中的序号

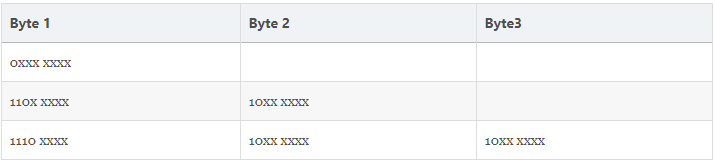

- 3个字节的UTF-8十六进制编码一定是以
E开头的 - 2个字节的UTF-8十六进制编码一定是以
C或D开头的 - 1个字节的UTF-8十六进制编码一定是以比
8小的数字开头的
附上字符集和编码对应关系
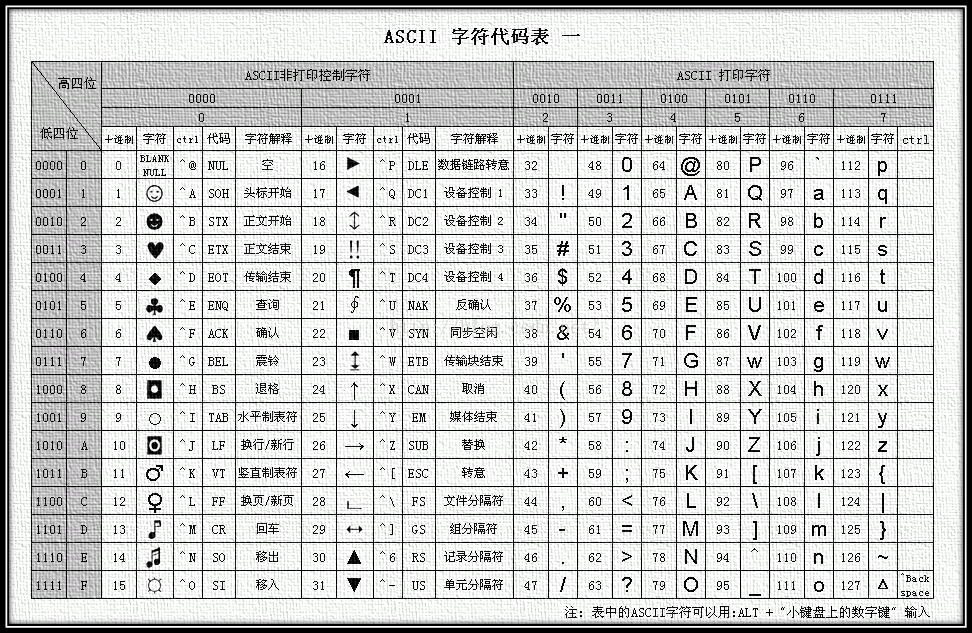
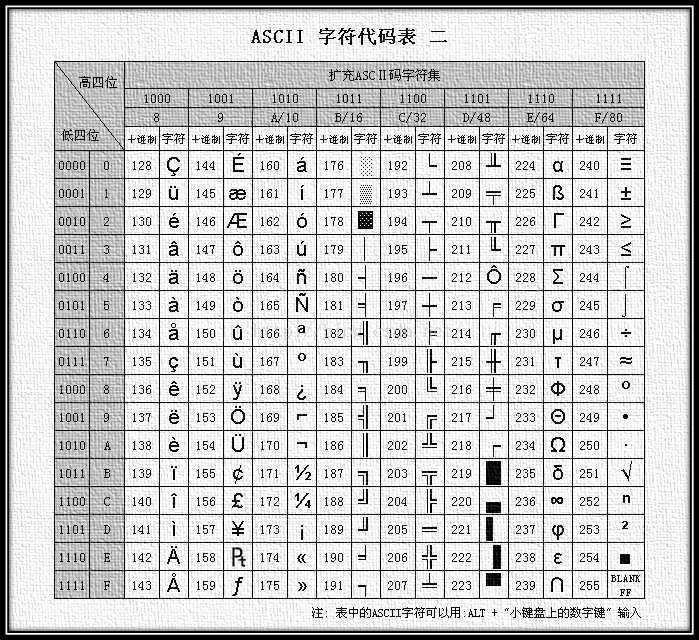

小结:计算机内存中统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候就转换成UTF-8编码。使用文本编辑工具打开时会将UTF-8字符转换成Unicode字符写入内存,保存时再转换一下,总之确保内存中的字符一定是Unicode字符集中的字符,硬盘中的字符一定是占空间少的字符。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号