基于FATE联邦学习的隐私计算实践
FATE 是一个工业级联邦学习框架,所谓联邦学习指的就是可以联合多方的数据,共同构建一个模型;
与传统数据使用方式相比,它不需要聚合各方数据搭建 数据仓库,联邦学习在联合计算建模的过程中,多方机构之间的数据是不会进行共享的,实现数据的 可用不可见。本文主要分享隐私计算平台 FATE的相关概念,以及基于 Docker 的单机部署。
隐私计算
隐私计算 是指在保护数据本身不对外泄露的前提下实现数据分析计算的技术集合,实现数据的 可用不可见 的目的;在充分保护数据和隐私安全的前提下,实现数据价值的转化和释放。
隐私计算并不是近期凭空被创造出来的一项新型技术,它是随着社会应用需求不断演变而形成的一套融合多种学科的技术体系框架。从20世纪70年代起,相关的技术理论就已经被相继提出,例如多方安全计算、同态加密、零知识证明等都是基于密码学理论的关键技术。隐私计算发展历程如下:
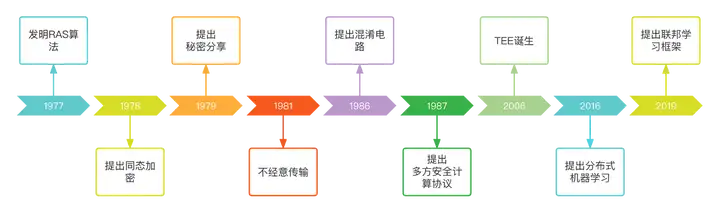
图灵奖得主姚期智院士在1982年提出的 百万富翁 问题:
假设有两个百万富翁,都想比较谁更富有,但是他们都想保护自己的 隐私 不愿意让对方或者任何第三方知道自己真正拥有多少钱。如何在保护双方隐私的情况下,计算出谁更有钱呢?
此问题开创了安全多方计算领域,在如今以区块链为先导的一系列可信架构中,多方计算问题是建立机器信任的关键技术之一。
目前实现隐私计算的主流技术主要分为三大方向:第一类是以 多方安全计算 为代表的基于密码学的隐私计算技术;第二类是以 联邦学习 为代表的人工智能与隐私保护技术融合衍生的技术;第三类是以 可信执行环境 为代表的基于可信硬件的隐私计算技术。
不同技术往往可以 组合 使用,在保证原始数据安全和隐私性的同时,完成对数据的计算和分析任务。
联邦学习
在联邦学习当中主要有两种模式:
横向联邦
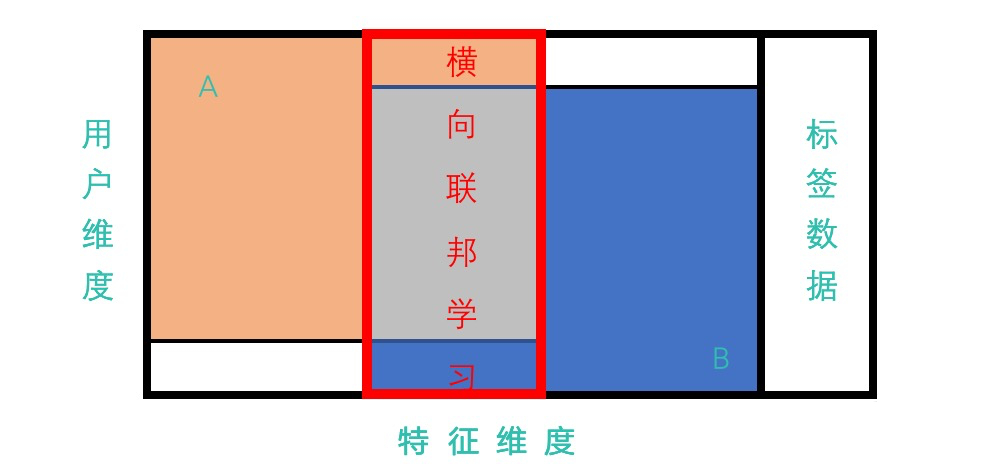
指的是在联合的多方当中,特征 是相同的,但是 用户 不一样;那么通过联合呢,就可以在训练模型时 扩展样本数量;
例如:有两家不同地区银行(北京与广州)由于银行间的业务相似,所以数据的特征(字段)大概率是相同的;但是它们的用户群体分别来自北京与广州的居住人口,用户的交集相对较小;这种场景就比较适合使用 横向联邦 用于增加模型训练的用户数据 扩展数据量。
纵向联邦
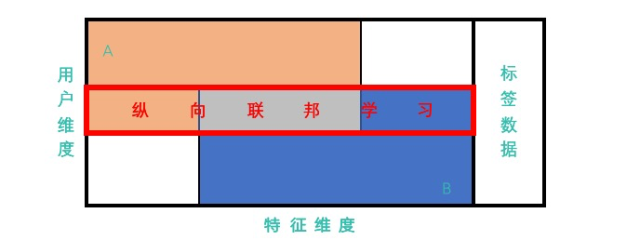
指的是在联合的多方当中,各方的 用户 重叠较多,但是它们的 特征 是不一样的,那么通过联合呢,就可以在训练模型时 扩展特征维度;
例如:同一地区的商场与银行,它们的用户群体很有可能包含该地的大部分居民,用户的交集可能较大;由于银行记录的都是用户的收支行为与信用评级,而商场则保有用户的购买历史,因此它们的用户特征交集较小;这种场景就比较适合使用 纵向联邦 用于增加模型训练的特征数量 扩展模型能力。
FATE
FATE (Federated AI Technology Enabler)是微众银行人工智能团队自研的全球首个联邦学习工业级开源框架,它提供一种基于数据隐私保护的安全计算框架,为机器学习、深度学习、迁移学习算法提供强有力的安全计算支持。并内置保护线性模型,树模型以及神经网络在内的多种机器学习算法。
github地址:https://github.com/FederatedAI/FATE
在 Fate 里面存在以下三种角色:
Guest
为数据的应用方,指的是在实际的建模场景中有业务需求去应用这些数据;并且在纵向算法中,Guest 往往是有标签 y 的一方。
Host
为数据的提供方,通常它只是一个合作的机构负责提供数据来辅助 guest 完成这个建模,只是帮助提升训练效果。
Arbiter
为第三方协作者,用来辅助多方完成联合建模的,不提供数据主要是负责发放公钥,加解密,还有聚合模型等功能。
部署
安装镜像
拉取腾讯云容器镜像:
docker pull federatedai/standalone_fate:${version}
docker tag ccr.ccs.tencentyun.com/federatedai/standalone_fate:${version} federatedai/standalone_fate:${version}
启动容器
执行以下命令启动:
docker run -d --name standalone_fate -p 8080:8080 federatedai/standalone_fate:${version}; 测试
Fate 里面自带了测试任务;
首先执行以下命令,进入 Fate 的容器中:
docker exec -it $(docker ps -aqf "name=standalone_fate") bash
执行以下命令,启动 toy 测试:
flow test toy -gid 10000 -hid 10000
成功后显示以下内容:
success to calculate secure_sum, it is 2000.0图形化界面
FATE Board 是 Fate 里面负责可视化的服务组件,在单机版容器中已经集成了该服务,可以通过 8080 端口访问:
进入容器
执行以下命令,进入 Fate 的容器中:
docker exec -it $(docker ps -aqf "name=standalone_fate") bash

可以看到其中有一个 examples 的目录,里面包含各种算法的测试样例,以及测试的数据。
进入到 examples 后,创建一个 my_test 的目录:
cd examples
mkdir my_test
注意:后面所有的操作都默认在该目录下执行。
上传数据
第一步需要准备好训练要用的数据,我们可以通过 csv文件 把数据上传到 Fate 里面;
自带的测试数据都在容器里的 /data/projects/fate/examples/data 目录中:
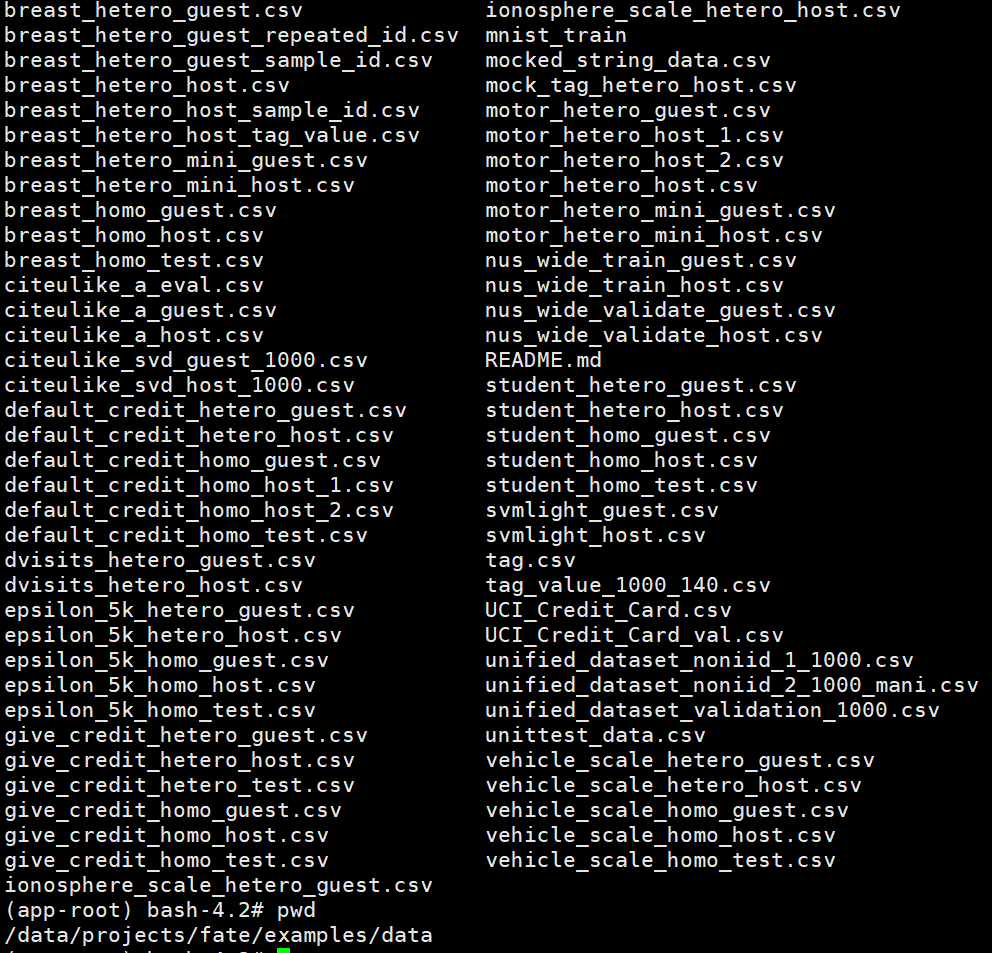
可以看到每种算法都分别提供了 guest 和 host 两方的数据。
准备guest方配置
在 my_test 目录下,执行以下命令:
vi upload_hetero_guest.json
内容如下:
{
"file": "/data/projects/fate/examples/data/breast_hetero_guest.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "experiment",
"table_name": "breast_hetero_guest"
}
- file:数据文件的路径
- head:数据文件是否包含表头
- partition:用于存储数据的分区数
- work_mode:工作模式,0为单机版,1为集群版
- namespace:命名空间
- table_name:数据表名
准备host方配置
在 my_test 目录下,执行以下命令:
vi upload_hetero_host.json
内容如下:
{
"file": "/data/projects/fate/examples/data/breast_hetero_host.csv",
"head": 1,
"partition": 10,
"work_mode": 0,
"namespace": "experiment",
"table_name": "breast_hetero_host"
}
注意文件名与表名是和guest方不一样的。
执行上传
执行以下两个命令,分别上传 guest 和 host 方的数据:
flow data upload -c upload_hetero_guest.json
flow data upload -c upload_hetero_host.json
通过 -c 来指定配置文件。
成功后返回上传任务的相关信息:
{
"data": {
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202205070640371260700&role=local&party_id=0",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202205070640371260700/job_dsl.json",
"job_id": "202205070640371260700",
"logs_directory": "/data/projects/fate/fateflow/logs/202205070640371260700",
"message": "success",
"model_info": {
"model_id": "local-0#model",
"model_version": "202205070640371260700"
},
"namespace": "experiment",
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202205070640371260700/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202205070640371260700/local/0/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070640371260700/job_runtime_conf.json",
"table_name": "breast_hetero_guest",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070640371260700/train_runtime_conf.json"
},
"jobId": "202205070640371260700",
"retcode": 0,
"retmsg": "success"
} 检查数据
执行以下命令,查看表的相关信息:
flow table info -t breast_hetero_guest -n experiment
执行后返回:
{
"data": {
"address": {
"home": null,
"name": "breast_hetero_guest",
"namespace": "experiment",
"storage_type": "LMDB"
},
"count": 569,
"exist": 1,
"namespace": "experiment",
"partition": 10,
"schema": {
"header": "y,x0,x1,x2,x3,x4,x5,x6,x7,x8,x9",
"sid": "id"
},
"table_name": "breast_hetero_guest"
},
"retcode": 0,
"retmsg": "success"
} 模型训练
接下来我们就开始进行建模任务,需要准备两个配置文件,流程配置文件 dsl 和参数配置文件 conf。
准备dsl文件
执行以下命令:
cp /data/projects/fate/examples/dsl/v2/hetero_logistic_regression/hetero_lr_normal_dsl.json /data/projects/fate/examples/my_test/
直接把 Fate 自带的纵向逻辑回归算法样例,复制到我们的
my_test目录下。
Fate 把各种算法实现了组件化,dsl 文件主要配置整个建模流程是由哪些 component 组成的:
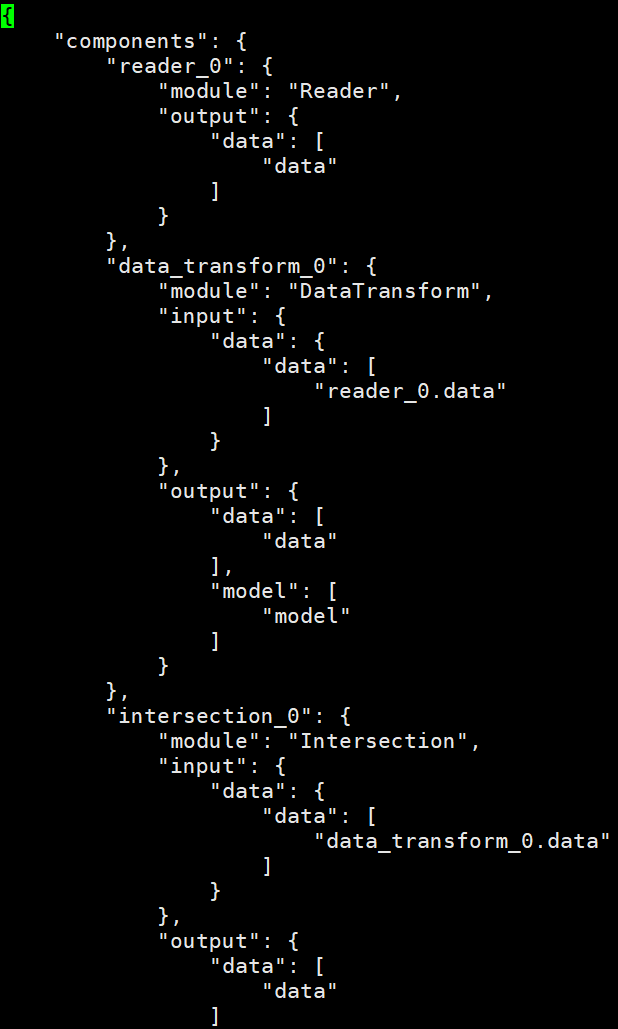
比如第一个模块 Reader 就是用于读取刚刚上传的训练数据,然后是 DataTransform 模块,把训练数据转换为实例对象,一般所有的建模流程都需要有前面这两个模块;
总的来说配置一个 component 需要以下内容:
- module:模型组件,Fate 当前支持 37 个模型组件
- input:
- date:数据输入
- module:模型输入
- output:
- date:数据输出
- module:模型输出
module 是定义这个组件的类型,当前 Fate 已经自带 37 个组件可以使用,当然我们也可以自己开发新增算法组件进去;
input 和 output 就是分别设置组件的输入输出,两个同时都支持两种类型,分别是数据和模型输入输出。
详细的配置说明可参考官方文档:https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/dsl_conf/dsl_conf_v2_setting_guide.zh.md
准备conf文件
执行以下命令:
cp /data/projects/fate/examples/dsl/v2/hetero_logistic_regression/hetero_lr_normal_conf.json /data/projects/fate/examples/my_test/
直接把 Fate 自带的纵向逻辑回归算法样例,复制到我们的
my_test目录下。
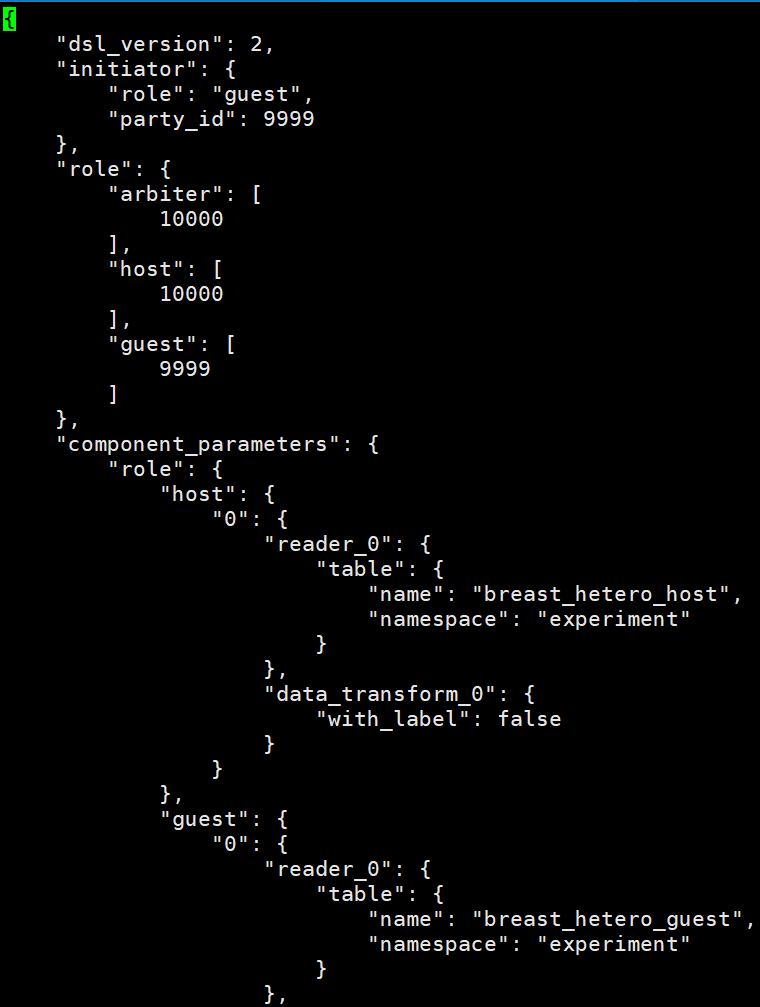
从上图可以看到在 component_parameters 元素下,配置 Reader 组件所读取的表名。
该配置主要是配置以下内容:
- DSL的版本
- 各个参与方的角色以及 party_id
- 组件运行参数
关于组件清单以及每一个组件的详细配置参数可参考官方文档:https://fate.readthedocs.io/en/latest/zh/federatedml_component/
提交任务
执行以下命令:
flow job submit -d hetero_lr_normal_dsl.json -c hetero_lr_normal_conf.json
通过 -d 和 -c 来分别指定 dsl 和 conf 配置文件。
成功后返回训练任务的相关信息:
{
"data": {
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202205070226373055640&role=guest&party_id=9999",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202205070226373055640/job_dsl.json",
"job_id": "202205070226373055640",
"logs_directory": "/data/projects/fate/fateflow/logs/202205070226373055640",
"message": "success",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070226373055640"
},
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202205070226373055640/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202205070226373055640/guest/9999/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070226373055640/job_runtime_conf.json",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070226373055640/train_runtime_conf.json"
},
"jobId": "202205070226373055640",
"retcode": 0,
"retmsg": "success"
}
其中有几个属性需要关注:
- board_url:这个地址是可以查看任务情况的 FATE Board 地址。
- job_id:任务的唯一关键字,可以在 FATE Board 上通过这个 ID 查看任务的详情。
- logs_directory:是日志的路径,可以通过这个地址查看任务的各种日志信息。
- model_info:里面有 model_id 和 model_version 这两个信息会在执行预测任务时需要用到,预测之前需要指定基于哪个模型来执行预测任务,而这两个信息就是模型的唯一关键字。
可视化
任务概览
通过上面返回信息中 board_url 的地址,在浏览器访问即可进入任务的概览页面:
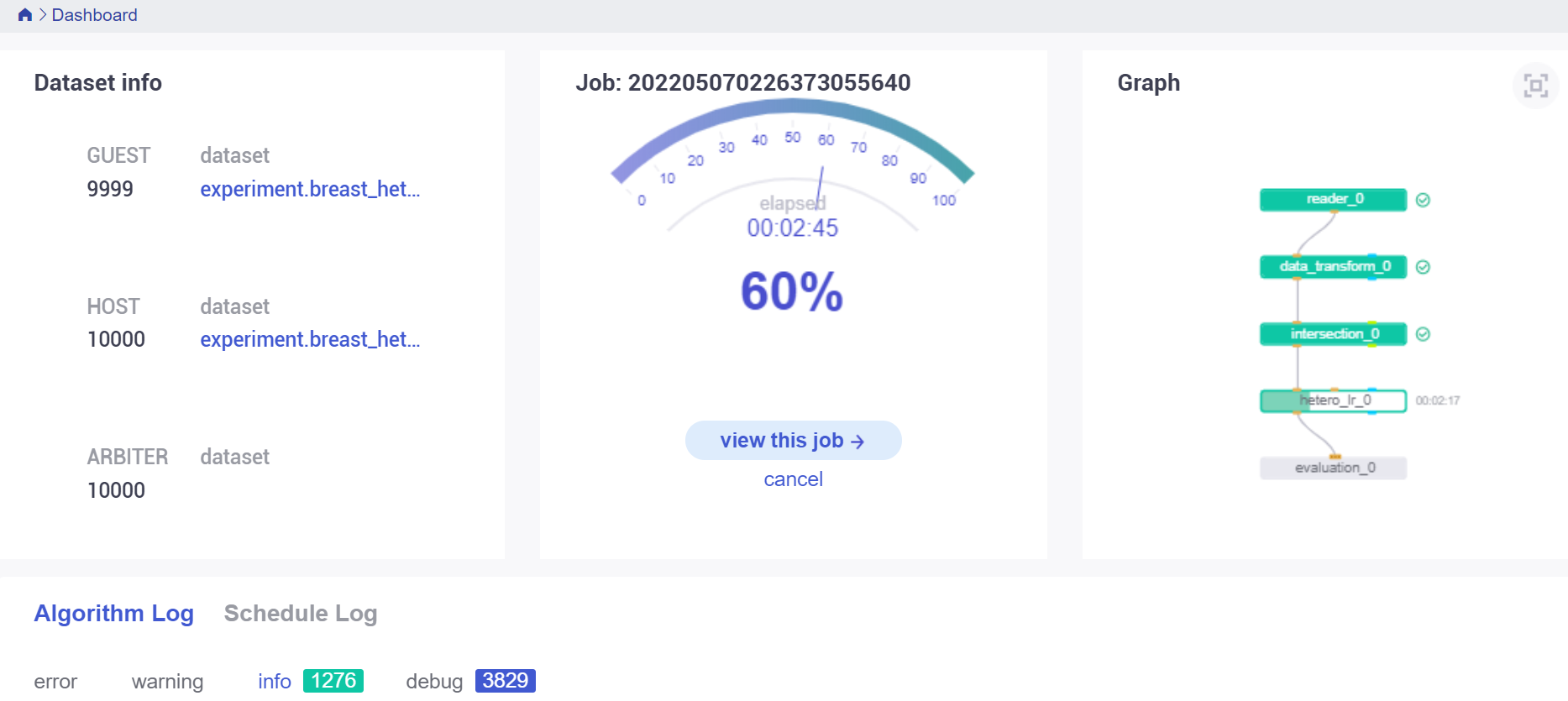
左边 Dataset info 是各个参与方的信息,中间呢是任务的运行情况显示运行的进度条以及耗时,右边是整个任务流程的组件 DAG 图,下方是任务日志信息。
组件输出
点击中间的 view this job 按钮,进入任务的详细信息:

DAG 图中的每个组件都是可以点击的,选中 hetero_lr_0 组件,点击右下角的 view the outputs 按钮,进入 逻辑回归 组件的输出页面:
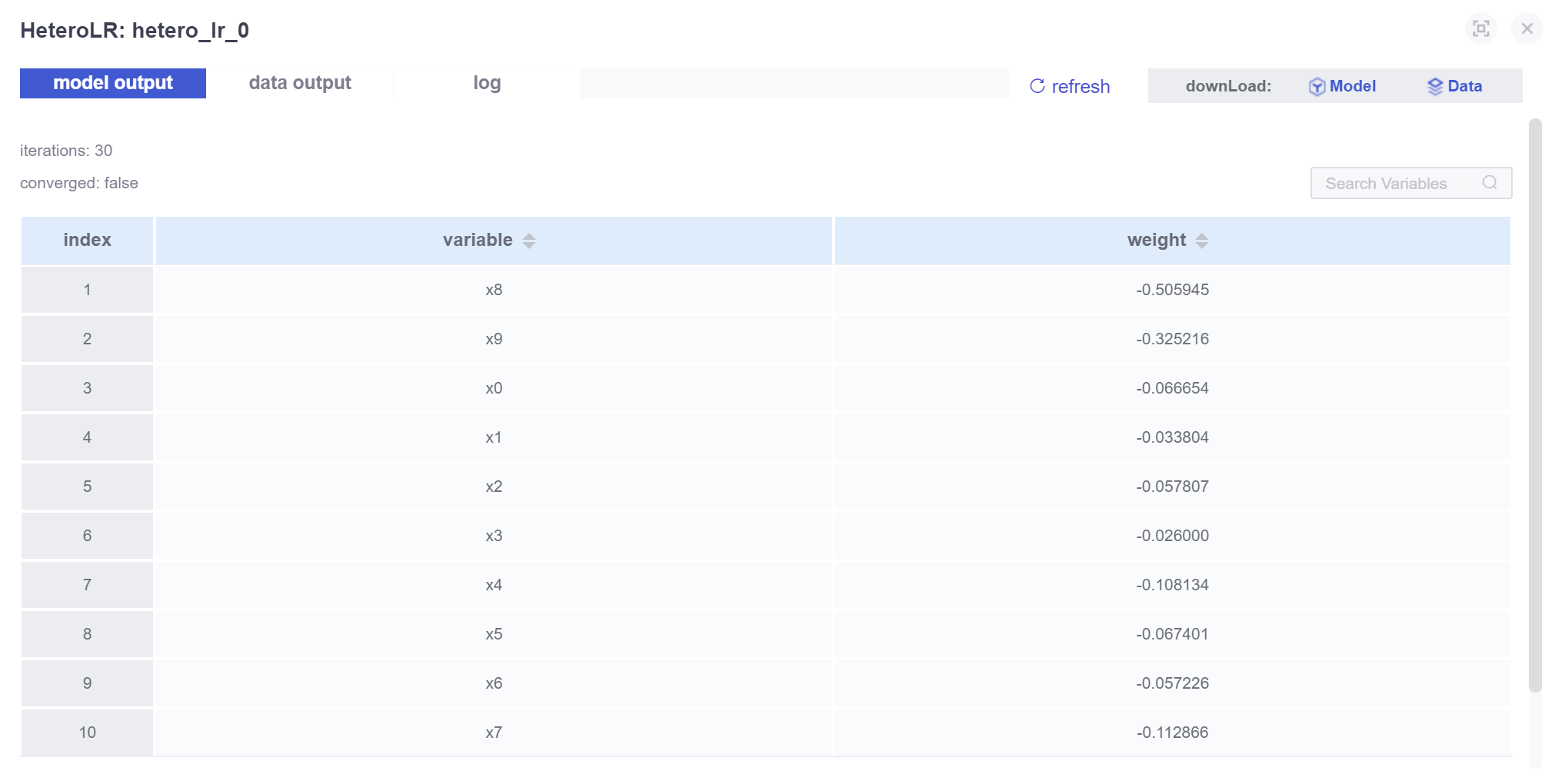
左上角有三个 TAG 分别为:
- model output:模型输出,是算法组件的训练结果。
- data output:数据输出,每个组件数据处理后的输出,用于下游组件的输入。
- log:该组件的运行日志。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号