Go并发编程实践
概述
基础理论
Do not communicate by sharing memory; instead, share memory by communicating.
简单来说所谓并发编程是指在一个处理器上“同时”处理多个任务;宏观上并发是指在一段时间内,有多个程序在同时运行;在微观上 并发是指在同一时刻只能有一条指令执行,但多个程序指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个程序快速交替的执行。
在许多环境中,实现对共享变量的正确访问使得并发编程变得困难。Go鼓励通过共享值在通道上传递,实际上没有被单独的执行线程主动共享。在任何给定时刻只有一个线程可以访问该值,因此在数据竞争在设计上是不会发生的。单线程程序不需要同步原语,也不需要同步。如果通信是同步器,则仍然不需要其他同步。例如,Unix管道就非常适合这个模型;尽管Go的并发方法起源于Hoare的通信顺序进程(CSP),但也可以被视为Unix管道的类型安全泛化。
并发原语
在操作系统中,往往设计一些完成特定功能的、不可中断的过程,这些不可中断的过程称为原语。并发原语就是在编程语言设计之初以及后续的扩展过程中,专门为并发设计而开发的关键词或代码片段或一部分功能,进而能够为该语言实现并发提供更好的支持。
- Go官方提供并发原语:goroutine、sync包下的Mutex、RWMutex、Once、WaitGroup、Cond、channel、Pool、Context、Timer、atomic等等。
- 扩展并发原语:Semaphore、SingleFlight、CyclicBarrier、ReentrantLock等等。
协程-Goroutine
在Go语言中,每一个并发的执行单元叫作一个goroutine,它是一个轻量级的执行线程,被称为协程,有别于线程、进程程等。协程以简单的模型运行,在同一地址空间中与其他运行协程并发执行的函数;只需要分配堆栈空间。堆栈开始时很小因此开销很低,并按需分配实现堆空间申请和释放。线程被多路复用到多个操作系统线程上,所以如果一个线程阻塞了,比如在等待I/O时,其他线程会继续运行。Goroutines设计隐藏了线程创建和管理的许多复杂性。在Go语言开启协程非常简单,在函数或方法调用前加上go关键字,例如有一个函数调用f(s),这种调用它的方式是同步,而在程序中使用go f(s)调用,则会新开协程将与调用协程并发执行。
package main
import (
"fmt"
"time"
)
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
func main() {
f("direct")
go f("goroutine")
go func(msg string) {
fmt.Println(msg)
}("going")
time.Sleep(time.Second)
fmt.Println("done")
}通道-Channel
Channels是一种编程结构,允许在代码的不同部分之间移动数据,通常来自不同的 goroutine。与映射一样,Channels通道也使用make分配,返回对底层数据结构的引用。如果提供了一个可选的整数参数则可设置通道的缓冲区大小。对于非缓冲通道或同步通道,默认值为零。无缓冲通道将通信(值的交换)与同步结合起来,保证两个计算(例程)处于已知状态。
通道是连接并发程序的管道,可以从一个运行协程向通道发送值,并从另一个运行协程接收这些值。默认情况下,通道是无缓冲的,这意味着只有当有相应的接收(<- chan)准备接收发送的值时,通道才会接受发送(chan <-)。缓冲通道接受有限数量的值,而没有相应的接收器接收这些值。还可以使用通道来同步跨程序的执行,使用阻塞接收来等待程序完成,而需要等待多个协程完成时可能更多会使用WaitGroup,后面再介绍;当使用通道作为函数参数时,可以指定通道是只发送还是接收值,也叫做定向通道,其增加了程序的类型安全性。
package main
import (
"fmt"
"time"
)
func worker(done chan bool) {
fmt.Print("working...")
time.Sleep(time.Second)
fmt.Println("done")
done <- true
}
func ping(pings chan<- string, msg string) {
pings <- msg
}
func pong(pings <-chan string, pongs chan<- string) {
msg := <-pings
pongs <- msg
}
func main() {
messages := make(chan string)
go func() { messages <- "ping" }()
msg := <-messages
fmt.Println(msg)
messagesBuf := make(chan string, 2)
messagesBuf <- "buffered"
messagesBuf <- "channel"
fmt.Println(<-messagesBuf)
fmt.Println(<-messagesBuf)
done := make(chan bool)
go worker(done)
<-done
pings := make(chan string, 1)
pongs := make(chan string, 1)
ping(pings, "passed message")
pong(pings, pongs)
fmt.Println(<-pongs)
}多路复用-Select
-
select是一种go可以处理多个通道之间的机制,看起来和switch语句很相似,但是select其实和IO机制中的select一样,多路复用通道,随机选取一个进行执行,如果说通道(channel)实现了多个goroutine之间的同步或者通信,那么select则实现了多个通道(channel)的同步或者通信,并且select具有阻塞的特性。
-
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。
-
select 随机执行一个可运行的 case,如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的。
-
当有多个通道等待接收信息时,可以使用该select语句,并且希望在其中任何一个通道首先完成时执行一个动作。Go的select允许等待多个通道操作,将gooutine和channel与select结合是Go的一个强大功能。
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string)
c2 := make(chan string)
go func() {
time.Sleep(1 * time.Second)
c1 <- "one"
}()
go func() {
time.Sleep(2 * time.Second)
c2 <- "two"
}()
for i := 0; i < 2; i++ {
select {
case msg1 := <-c1:
fmt.Println("received", msg1)
case msg2 := <-c2:
fmt.Println("received", msg2)
}
}
}通道使用
超时-Timeout
对于连接到外部资源或需要限制执行时间的程序来说超时非常重要。在Go 通道和select中实现超时是简单且优雅的。
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan string, 1)
go func() {
time.Sleep(2 * time.Second)
c1 <- "result 1"
}()
select {
case res := <-c1:
fmt.Println(res)
case <-time.After(1 * time.Second):
fmt.Println("timeout 1")
}
c2 := make(chan string, 1)
go func() {
time.Sleep(2 * time.Second)
c2 <- "result 2"
}()
select {
case res := <-c2:
fmt.Println(res)
case <-time.After(3 * time.Second):
fmt.Println("timeout 2")
}
}非阻塞通道操作
通道上的基本发送和接收阻塞,但可以使用带有默认子句的select来实现非阻塞发送、接收,甚至非阻塞多路选择。无阻塞的接收如果消息上有一个可用的值,那么select将使用该值的<-messages情况;如果没有可用的值则立即采用默认情况。非阻塞发送的工作原理类似这里不能将msg发送到消息通道,因为该通道没有缓冲区,也没有接收器,因此选择默认情况。可以在默认子句之上使用多种情况来实现多路非阻塞选择,对消息和信号进行非阻塞接收。
package main
import "fmt"
func main() {
messages := make(chan string)
signals := make(chan bool)
select {
case msg := <-messages:
fmt.Println("received message", msg)
default:
fmt.Println("no message received")
}
msg := "hi"
select {
case messages <- msg:
fmt.Println("sent message", msg)
default:
fmt.Println("no message sent")
}
select {
case msg := <-messages:
fmt.Println("received message", msg)
case sig := <-signals:
fmt.Println("received signal", sig)
default:
fmt.Println("no activity")
}
}关闭通道
关闭通道表示不再在该通道上发送任何值,可用于完成通信发送给信道的接收器。
package main
import "fmt"
func main() {
jobs := make(chan int, 5)
done := make(chan bool)
go func() {
for {
j, more := <-jobs
if more {
fmt.Println("received job", j)
} else {
fmt.Println("received all jobs")
done <- true
return
}
}
}()
for j := 1; j <= 3; j++ {
jobs <- j
fmt.Println("sent job", j)
}
close(jobs)
fmt.Println("sent all jobs")
<-done
}通道迭代
在这里可以使用该range语法迭代从通道接收的值。
package main
import "fmt"
func main() {
queue := make(chan string, 2)
queue <- "one"
queue <- "two"
close(queue)
for elem := range queue {
fmt.Println(elem)
}
}定时器-TimerAndTicker
经常实际项目有不少需求需要使用在将来的某个时间点执行Go代码,或者在某个时间间隔重复执行;Go内置的定时器就能很简单实现这个功能。GO标准库中的定时器主要有两种,一种为Timer定时器,一种为Ticker定时器。Timer计时器使用一次后,就失效了,需要Reset()才能再次生效,而Ticker计时器会一直生效。在一个GO进程中,其中的所有计时器都是由一个运行着 timerproc() 函数的 goroutine 来保护。它使用时间堆(最小堆)的算法来保护所有的 Timer,其底层的数据结构基于数组的最小堆,堆顶的元素是间隔超时最近的 Timer,这个 goroutine 会定期 wake up,读取堆顶的 Timer,执行对应的 f 函数或者 sendtime()函数,而后将其从堆顶移除。Timer数据结构如下:
package main
import (
"fmt"
"time"
)
func main() {
timer1 := time.NewTimer(2 * time.Second)
<-timer1.C
fmt.Println("Timer 1 fired")
timer2 := time.NewTimer(time.Second)
go func() {
<-timer2.C
fmt.Println("Timer 2 fired")
}()
stop2 := timer2.Stop()
if stop2 {
fmt.Println("Timer 2 stopped")
}
time.Sleep(2 * time.Second)
ticker := time.NewTicker(500 * time.Millisecond)
done := make(chan bool)
go func() {
for {
select {
case <-done:
return
case t := <-ticker.C:
fmt.Println("Tick at", t)
}
}
}()
time.Sleep(1600 * time.Millisecond)
ticker.Stop()
done <- true
fmt.Println("Ticker stopped")
}速率限制是控制资源利用和保持服务质量的重要机制。Go优雅地支持用 goroutines、channels和tickers来实现限制速率。
package main
import (
"fmt"
"time"
)
func main() {
requests := make(chan int, 5)
for i := 1; i <= 5; i++ {
requests <- i
}
close(requests)
limiter := time.Tick(200 * time.Millisecond)
for req := range requests {
<-limiter
fmt.Println("request", req, time.Now())
}
burstyLimiter := make(chan time.Time, 3)
for i := 0; i < 3; i++ {
burstyLimiter <- time.Now()
}
go func() {
for t := range time.Tick(200 * time.Millisecond) {
burstyLimiter <- t
}
}()
burstyRequests := make(chan int, 5)
for i := 1; i <= 5; i++ {
burstyRequests <- i
}
close(burstyRequests)
for req := range burstyRequests {
<-burstyLimiter
fmt.Println("request", req, time.Now())
}
}工作池-Worker Pools
工作池是一种常用的并发设计模式,它利用一组固定数量的 goroutine 来处理一组任务。任务可以被异步地添加到工作池中,等待可用的 worker goroutine 来处理。当没有更多的任务需要处理时,worker goroutine 将会保持空闲状态,等待新的任务到来。 在 Go 中,我们可以使用通道和 Goroutine 来实现这种模式
package main
import (
"fmt"
"time"
)
func worker(id int, jobs <-chan int, results chan<- int) {
for j := range jobs {
fmt.Println("worker", id, "started job", j)
time.Sleep(time.Second)
fmt.Println("worker", id, "finished job", j)
results <- j * 2
}
}
func main() {
const numJobs = 5
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs)
for a := 1; a <= numJobs; a++ {
<-results
}
}等待组-WaitGroup
在Go语言中,sync包下的WaitGroup结构体对象用于等待一组线程的结束;WaitGroup是go并发中最常用的工具,可以通过WaitGroup来表达这一组协程的任务是否完成,以决定是否继续往下走,或者取任务结果。
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int) {
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1)
i := i
go func() {
defer wg.Done()
worker(i)
}()
}
wg.Wait()
}原子操作-Atomic
- 定义:原子操作即是进行过程中不能被中断的操作;也就是说,针对某个值的原子操作在被进行的过程当中,CPU绝不会再去进行其它的针对该值的操作。为了实现这样的严谨性,原子操作仅会由一个独立的CPU指令代表和完成。只有这样才能够在并发环境下保证原子操作的绝对安全。
- Go支持操作类型:int32、int64、uint32、uint64、uintptr和unsafe.Pointer类型。
- Go原子操作:
- 增或减:被用于进行增或减的原子操作(以下简称原子增/减操作)的函数名称都以“Add”为前缀,并后跟针对的具体类型的名称。例如,实现针对uint32类型的原子增/减操作的函数的名称为AddUint32。事实上,sync/atomic包中的所有函数的命名都遵循此规则。
- 比较并交换:Compare And Swap,简称CAS。在sync/atomic包中,这类原子操作由名称以“CompareAndSwap”为前缀的若干个函数代表。
- 载入:为了原子的读取某个值,sync/atomic代码包同样为我们提供了一系列的函数。这些函数的名称都以“Load”为前缀,意为载入。
- 存储:与读取操作相对应的是写入操作。而sync/atomic包也提供了与原子的值载入函数相对应的原子的值存储函数。这些函数的名称均以“Store”为前缀。
- 交换:在sync/atomic代码包中还存在着一类函数。它们的功能与前文所讲的CAS操作和原子载入操作都有些类似。这样的功能可以被称为原子交换操作。这类函数的名称都以“Swap”为前缀。
Go语言提供的原子操作都是非侵入式的。它们由标准库代码包sync/atomic中的众多函数代表。可以通过调用这些函数对几种简单的类型的值进行原子操作。Go中管理状态的主要机制是通过通道进行通信,下面演示使用sync/atomic包来处理由多个线程例程访问的原子计数器。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var ops uint64
var wg sync.WaitGroup
for i := 0; i < 50; i++ {
wg.Add(1)
go func() {
for c := 0; c < 1000; c++ {
atomic.AddUint64(&ops, 1)
}
wg.Done()
}()
}
wg.Wait()
fmt.Println("ops:", ops)
}互斥锁-Mutex
Go sync包提供了两种锁类型:互斥锁sync.Mutex 和 读写互斥锁sync.RWMutex,都属于悲观锁。Mutex是互斥锁,当一个 goroutine 获得了锁后,其他 goroutine 不能获取锁(只能存在一个写或读,不能同时读和写)。应用于多个线程同时访问临界区],为保证数据的安全,锁住一些共享资源, 以防止并发访问这些共享数据时可能导致的数据不一致问题。state表示锁的状态,有锁定、被唤醒、饥饿模式等,并且是用state的二进制位来标识的,不同模式下会有不同的处理方式。sema表示信号量,mutex阻塞队列的定位是通过这个变量来实现的,从而实现goroutine的阻塞和唤醒。锁的实现一般会依赖于原子操作、信号量,通过atomic 包中的一些原子操作来实现锁的锁定,通过信号量来实现线程的阻塞与唤醒。
package main
import (
"fmt"
"sync"
)
type Container struct {
mu sync.Mutex
counters map[string]int
}
func (c *Container) inc(name string) {
c.mu.Lock()
defer c.mu.Unlock()
c.counters[name]++
}
func main() {
c := Container{
counters: map[string]int{"a": 0, "b": 0},
}
var wg sync.WaitGroup
doIncrement := func(name string, n int) {
for i := 0; i < n; i++ {
c.inc(name)
}
wg.Done()
}
wg.Add(3)
go doIncrement("a", 10000)
go doIncrement("a", 10000)
go doIncrement("b", 10000)
wg.Wait()
fmt.Println(c.counters)
}

读写互斥锁-RWMutex
读写互斥锁RWMutex,是对Mutex的一个扩展,当一个 goroutine 获得了读锁后,其他 goroutine可以获取读锁,但不能获取写锁;当一个 goroutine 获得了写锁后,其他 goroutine既不能获取读锁也不能获取写锁(只能存在一个写或多个读,可以同时读)。常用于读多于写的情况(既保证线程安全,又保证性能不太差)。数据结构如下:
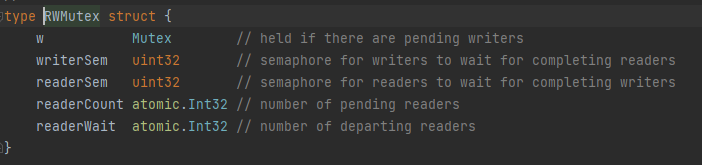
- 读写锁区分读者和写者,而互斥锁不区分。
- 互斥锁同一时间只允许一个线程访问该对象,无论读写;读写锁同一时间内只允许一个写者,但是允许多个读者同时读对象
package main
import (
"fmt"
"sync"
"time"
)
type Counter struct {
value int
rwMutex sync.RWMutex
}
func (c *Counter) GetValue() int {
c.rwMutex.RLock()
defer c.rwMutex.RUnlock()
return c.value
}
func (c *Counter) Increment() {
c.rwMutex.Lock()
defer c.rwMutex.Unlock()
c.value++
}
func main() {
counter := Counter{value: 0}
// 读操作
for i := 0; i < 10; i++ {
go func() {
for {
fmt.Println("Value: ", counter.GetValue())
time.Sleep(time.Millisecond)
}
}()
}
// 写操作
for {
counter.Increment()
time.Sleep(time.Second)
}
}
有状态协程
在前面的例子中,我们使用了带有互斥锁的显式锁来同步跨多个线程对共享状态的访问。而另一种选择是使用程序和通道的内置同步特性来实现相同的结果。这种基于通道的方法符合Go的思想,即通过通信共享内存,并使每个数据块由一个线程程序拥有。
package main
import (
"fmt"
"math/rand"
"sync/atomic"
"time"
)
type readOp struct {
key int
resp chan int
}
type writeOp struct {
key int
val int
resp chan bool
}
func main() {
var readOps uint64
var writeOps uint64
reads := make(chan readOp)
writes := make(chan writeOp)
go func() {
var state = make(map[int]int)
for {
select {
case read := <-reads:
read.resp <- state[read.key]
case write := <-writes:
state[write.key] = write.val
write.resp <- true
}
}
}()
for r := 0; r < 100; r++ {
go func() {
for {
read := readOp{
key: rand.Intn(5),
resp: make(chan int)}
reads <- read
<-read.resp
atomic.AddUint64(&readOps, 1)
time.Sleep(time.Millisecond)
}
}()
}
for w := 0; w < 10; w++ {
go func() {
for {
write := writeOp{
key: rand.Intn(5),
val: rand.Intn(100),
resp: make(chan bool)}
writes <- write
<-write.resp
atomic.AddUint64(&writeOps, 1)
time.Sleep(time.Millisecond)
}
}()
}
time.Sleep(time.Second)
readOpsFinal := atomic.LoadUint64(&readOps)
fmt.Println("readOps:", readOpsFinal)
writeOpsFinal := atomic.LoadUint64(&writeOps)
fmt.Println("writeOps:", writeOpsFinal)
}
单执行-Once
Once 是 Go 内置库 sync 中一个比较简单的并发原语;顾名思义,它的作用就是执行那些只需要执行一次的动作。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}Once 最典型的使用场景就是单例对象的初始化,类似思想如在 MySQL 或者 Redis 这种频繁访问数据的场景中,建立连接的代价远远高于数据读写的代价,因此我们会用单例模式来实现一次建立连接,多次访问数据,从而提升服务性能。
package main
import (
"net"
"sync"
"time"
)
// 使用互斥锁保证线程(goroutine)安全
var connMu sync.Mutex
var conn net.Conn
func getConn() net.Conn {
connMu.Lock()
defer connMu.Unlock()
// 返回已创建好的连接
if conn != nil {
return conn
}
// 创建连接
conn, _ = net.DialTimeout("tcp", "baidu.com:80", 10*time.Second)
return conn
}
// 使用连接
func main() {
conn := getConn()
if conn == nil {
panic("conn is nil")
}
}
条件-Cond
Go 标准库提供 Cond 原语的目的是,为等待 / 通知场景下的并发问题提供支持。Cond通常应用于等待某个条件的一组goroutine,等条件变为true的时候,其中一个goroutine或者所有的goroutine都会被唤醒执行。开发实践中使用到Cond场景比较少,且Cond场景一般也能用Channel方式实现,所以更多人会选择使用Channel。
package main
import (
"fmt"
"sync"
"time"
)
var (
// 1. 定义一个互斥锁
mu sync.Mutex
cond *sync.Cond
count int
)
func init() {
// 2.将互斥锁和sync.Cond进行关联
cond = sync.NewCond(&mu)
}
func worker(id int) {
// 消费者
for {
// 3. 在需要等待的地方,获取互斥锁,调用Wait方法等待被通知
mu.Lock()
// 这里会不断循环判断 是否有待消费的任务
for count == 0 {
cond.Wait() // 等待任务
}
count--
fmt.Printf("worker %d: 处理了一个任务", id)
// 5. 最后释放锁
mu.Unlock()
}
}
func main() {
// 启动5个消费者
for i := 1; i <= 5; i++ {
go worker(i)
}
for {
// 生产者
time.Sleep(1 * time.Second)
mu.Lock()
count++
// 4. 在需要等待的地方,获取互斥锁,调用BroadCast/Singal方法进行通知
cond.Broadcast()
mu.Unlock()
}
}

上下文-Context
定义:Golang 的 Context 应用开发常用的并发控制工具,用于在程序中的 API 层或进程之间共享请求范围的数据、取消信号以及超时或截止日期。Context 又被称为上下文,与 WaitGroup 不同的是,context 对于派生 goroutine 有更强的控制力,可以管理多级的 goroutine。context包的核心原理,链式传递context,基于context构造新的context。下面是http的上下文示例:
package main
import (
"fmt"
"net/http"
"time"
)
func hello(w http.ResponseWriter, req *http.Request) {
ctx := req.Context()
fmt.Println("server: hello handler started")
defer fmt.Println("server: hello handler ended")
select {
case <-time.After(10 * time.Second):
fmt.Fprintf(w, "hello\n")
case <-ctx.Done():
err := ctx.Err()
fmt.Println("server:", err)
internalError := http.StatusInternalServerError
http.Error(w, err.Error(), internalError)
}
}
func main() {
http.HandleFunc("/hello", hello)
http.ListenAndServe(":8090", nil)
}
# 访问http的接口
curl http://localhost:8090/hello

信号-signal
信号是事件发生时对进程的通知机制。有时也称之为软件中断。信号与硬件中断的相似之处在于打断了程序执行的正常流程,大多数情况下,无法预测信号到达的精确时间。有时希望Go程序能够智能地处理Unix信号;例如希望服务器在接收到SIGTERM时优雅地关闭,或者希望命令行工具在接收到SIGINT时停止处理输入。Go程序无法捕获信号 SIGKILL 和 SIGSTOP (终止和暂停进程),因此 os/signal 包对这两个信号无效。
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
sigs := make(chan os.Signal, 1)
signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM)
done := make(chan bool, 1)
go func() {
sig := <-sigs
fmt.Println()
fmt.Println(sig)
done <- true
}()
fmt.Println("awaiting signal")
<-done
fmt.Println("exiting")
}

Pool
go提供的sync.Pool是为了对象的复用,如果某些对象的创建比较频繁,就把他们放入Pool中缓存起来以便使用,这样重复利用内存,减少GC的压力,Go同步包中,sync.Pool提供了保存和访问一组临时对象并复用它们的能力。
对于一些创建成本昂贵、频繁使用的临时对象,使用sync.Pool可以减少内存分配,降低GC压力。因为Go的gc算法是根据标记清除改进的三色标记法,如果频繁创建大量临时对象,势必给GC标记带来负担,CPU也很容易出现毛刺现象。当然需要注意的是:存储在Pool中的对象随时都可能在不被通知的情况下被移除。所以并不是所有频繁使用、创建昂贵的对象都适用,比如DB连接、线程池。
package main
import "sync"
type Person struct {
Age int
}
// 初始化pool
var personPool = sync.Pool{
New: func() interface{} {
return new(Person)
},
}
func main() {
// 获取一个实例
newPerson := personPool.Get().(*Person)
// 回收对象 以备其他协程使用
defer personPool.Put(newPerson)
newPerson.Age = 25
}
线程安全Map
Go中自己通过make创建的map不是线程安全的,Go为了解决这个问题,专门给我们提供了一个并发安全的map,这个并发安全的map不用通过make创建,拿来即可用,并且提供了一些不同于普通map的操作方法。
package main
import (
"fmt"
"sync"
)
// 创建一个sync包下的线程安全map对象
var myConcurrentMap = sync.Map{}
// 遍历数据用的
var myRangeMap = sync.Map{}
func main() {
//存储数据
myConcurrentMap.Store(1, "li_ming")
//取出数据
name, ok := myConcurrentMap.Load(1)
if !ok {
fmt.Println("不存在")
return
}
//打印值 li_ming
fmt.Println(name)
//该key有值,则ok为true,返回它原来存在的值,不做任何操作;该key无值,则执行添加操作,ok为false,返回新添加的值
name2, ok2 := myConcurrentMap.LoadOrStore(1, "xiao_hong")
//因为key=1存在,所以打印是 li_ming true
fmt.Println(name2, ok2)
name3, ok3 := myConcurrentMap.LoadOrStore(2, "xiao_hong")
//因为key=2不存在,所以打印是 xiao_hong false
fmt.Println(name3, ok3)
//标记删除值
myConcurrentMap.Delete(1)
//取出数据
//name4,ok4 := myConcurrentMap.Load(1)
//if(!ok4) {
// fmt.Println("name4=不存在")
// return
//}
//fmt.Println(name4)
//遍历数据
rangeFunc()
}
// 遍历
func rangeFunc() {
myRangeMap.Store(1, "xiao_ming")
myRangeMap.Store(2, "xiao_li")
myRangeMap.Store(3, "xiao_ke")
myRangeMap.Store(4, "xiao_lei")
myRangeMap.Range(func(k, v interface{}) bool {
fmt.Println("data_key_value = :", k, v)
//return true代表继续遍历下一个,return false代表结束遍历操作
return true
})
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号