[Flink] Flink 版本特性的演进
目录
- Flink 1.15 新特性
- 流批一体的进一步完善
- 改进运维体验
- Flink SQL 的进阶
- 与云服务的交互操作性提升
- 响应式缩放和自适应调度器
- 自适应批调度器
- 跨源节点的 Watermark 对齐
- SQL 版本升级
- 基于 Changelog 的状态存储
- 可重复的清理
- CAST / 类型系统增强
- 云环境互操作性
- Elasticsearch Sink
- 各模块摆脱 Scala 依赖
- Scala-free 的 Flink : 不再支持 Scala 2.11 编译,默认使用 2.12 构建
- PyFlink 的改进
- Flink 1.14 新特性
- 混合有界和无界流
- 批执行模式支持 DataStream API 和 SQL/Table API 的混合使用
- 统一的 Source 和 Sink API 更新
- 细粒度资源管理
- 缓冲区去膨胀
- 性能与效率的优化
- Table / SQL / Python API 的改进
- 告别旧版 SQL 引擎和 Mesos 支持
- Flink 1.13 新特性
- 被动扩缩容:让流处理应用管理更简单
- SQL/Table API增强:提升数据处理能力
- 资源调度优化:提升作业执行效率
- 性能分析工具:助力问题诊断与优化
- 机器学习库移动到单独的工程(flink-ml)
- PyFlink 的改进: Python DataStream API 和 Table API 更接近 Java/Scala API 的功能
- Web UI 的改进: 可展示导致作业失败的最后几次异常
- 状态后端和检查点存储的分离
- 对齐检查点的支持重新调整作业并行度:在从对齐检查点恢复时,现在可以更改作业的并行度
- X 参考文献
Flink 1.15 新特性
Apache Flink 1.15 版本带来了一系列新特性和改进,以下是一些主要的更新:
这些是 Flink 1.15 版本的一些主要新特性和改进,旨在提升用户体验、性能和云原生环境下的互操作性。
流批一体的进一步完善
- Flink 1.15 版本中流批一体更加完善,支持部分作业完成后的 Checkpoint 操作,以及在批模式下支持 Window table-valued 函数,使其在流批混合的场景下更加易用 。
改进运维体验
包括:
- 明确 Checkpoint 和 Savepoint 在不同作业之间的所属权,简化 Checkpoint 和 Savepoint 生命周期管理;
- 更加无缝支持完整的自动伸缩;
- 通过 Watermark 对齐来消除多个数据源速率不同带来的问题等 。
Flink SQL 的进阶
- 包括能够在不丢失状态的情况下升级 SQL 作业;
- 添加了对 JSON 相关函数的支持来简化数据的输入与输出操作 。
与云服务的交互操作性提升
- 1.15 版本进一步提升了与云服务的交互操作性,并且添加了更多的 Sink 连接器与数据格式 。
响应式缩放和自适应调度器
- 改进了 Reactive 模式的指标,并为自适应调度器添加了异常历史记录。自适应调度器可以根据资源情况在执行前决定资源的并行度 。
自适应批调度器
- 引入了一个新的自适应批处理调度器,可以自动根据每个节点需要处理的数据量的大小自动决定批处理作业中各节点的并行度 。
跨源节点的 Watermark 对齐
- 引入了 Watermark 对齐的能力,基于新的 Source 接口来实现的数据源节点可以启用 Watermark 对齐功能,用户可以定义对齐组,如果其中某个源节点与其它节点相比 Watermark 领先过多,用户可以暂停从该节点中消费数据 。
SQL 版本升级
- 在 1.15 中,社区首先通过保持拓扑不变的方式使相同的查询在升级 Flink 版本后仍然可以启动和执行。
- SQL 升级的核心是 JSON 计划,可以让 SQL 计划以结构化数据的方式被导入和导出 。
基于 Changelog 的状态存储
- 引入了 MVP 特性:基于 Changelog 的状态存储。这一新的状态存储旨在支持更短、更可以预测的 Checkpoint 间隔 。
可重复的清理
- 在以前的 Flink 版本中,Flink 在作业结束时只尝试清理一次与作业相关的残留数据,这可能会导致在发生错误时无法完成清理。在这个版本中,Flink 将尝试重复运行清理以避免残留数据 。
CAST / 类型系统增强
- 在 Flink 1.15 中,失败的 CAST 的默认行为已从返回 null 更改为返回错误,从而使它更符合 SQL 标准 。
云环境互操作性
- 新增了写入 Google Cloud Storage 的支持,并且整理了 Flink 生态中的连接器并把精力放在支持 AWS 相关的生态上 。
Elasticsearch Sink
- 基于最新的 Sink API 来实现的 Elasticsearch Sink,可以提供异步输出与端到端一致性的能力 。
各模块摆脱 Scala 依赖
- Flink 1.15 中有几个变化,当从早期版本升级时需要更新依赖项名称,主要包括从非Scala模块中选择退出Scala依赖项和重新组织表模块。下面是依赖项更改的快速检查表:
https://github.com/apache/flink/blob/release-1.12.6/docs/release-notes/flink-1.12.md
https://github.com/apache/flink/blob/release-1.15.4/docs/content.zh/release-notes/flink-1.15.md 【推荐】
flink-cep
flink-clients
flink-connector-elasticsearch-base
flink-connector-elasticsearch6
flink-connector-elasticsearch7
flink-connector-gcp-pubsub
flink-connector-hbase-1.4
flink-connector-hbase-2.2
flink-connector-hbase-base
flink-connector-jdbc
flink-connector-kafka
flink-connector-kinesis
flink-connector-nifi
flink-connector-pulsar
flink-connector-rabbitmq
flink-container
flink-dstl-dfs
flink-gelly
flink-hadoop-bulk
flink-kubernetes
flink-runtime-web
flink-sql-connector-elasticsearch6
flink-sql-connector-elasticsearch7
flink-sql-connector-hbase-1.4
flink-sql-connector-hbase-2.2
flink-sql-connector-kafka
flink-sql-connector-kinesis
flink-sql-connector-rabbitmq
flink-state-processor-api
flink-statebackend-rocksdb
flink-streaming-java
flink-test-utils
flink-yarn
flink-table-api-java-bridge
flink-table-runtime
flink-sql-client
flink-orc
flink-orc-nohive
flink-parquet
错误示范
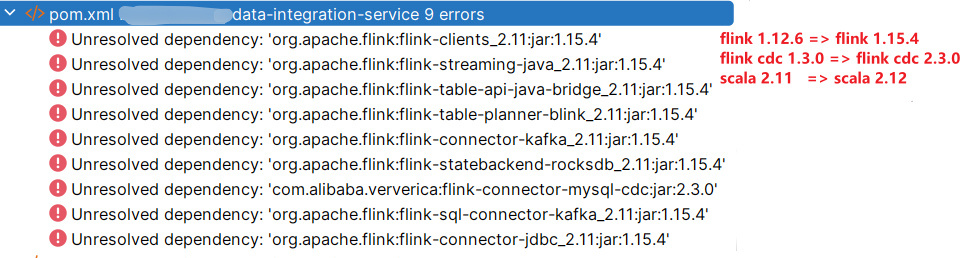
flink sql job
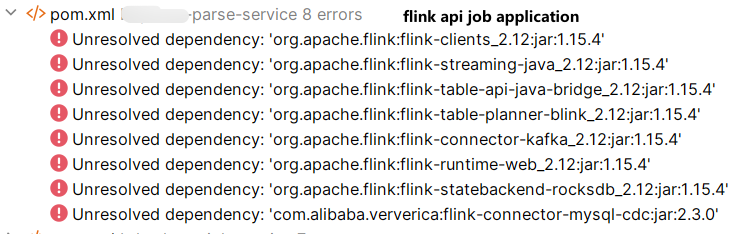
flink api job
Scala-free 的 Flink : 不再支持 Scala 2.11 编译,默认使用 2.12 构建
- 从 Flink 1.15 开始,Flink 已经不再支持使用 Scala 2.11 编译,默认使用 2.12 来构建 。
PyFlink 的改进
- 引入了一种 “线程” 模式的新执行模式,用户自定义的函数将在 JVM 中作为线程执行,而不是在单独的 Python 进程中执行,这可以显著提高性能 。
Flink 1.14 新特性
Apache Flink 1.14 版本引入了多项新特性和改进,以下是一些主要的更新:
这些是 Flink 1.14 版本的一些主要新特性和改进。如果你计划升级到 Flink 1.14 版本,建议仔细阅读发布说明,以了解可能需要考虑的配置、行为或依赖项的变化。
混合有界和无界流
- Flink 1.14 支持在同一个应用中混合使用有界流和无界流。这意味着可以对部分运行、部分结束的应用进行 Checkpoint,例如一些算子已经处理到了有界输入数据流的末端。此外,当有界流到达末端时,会触发最终 Checkpoint,以确保所有计算结果顺利提交到 Sink。
批执行模式支持 DataStream API 和 SQL/Table API 的混合使用
- 之前,批执行模式只支持单独使用 DataStream API 或 SQL/Table API,而在 Flink 1.14 中,可以在同一应用中混合使用这两种 API。
统一的 Source 和 Sink API 更新
- Flink 开始围绕统一的 API 整合连接器生态,并添加了新的混合 Source,它可以在多个存储系统间过渡,例如先从 Amazon S3 读取数据,然后无缝切换到 Apache Kafka。
细粒度资源管理
- 这是一项新的高级功能,用于提高大型共享集群的资源利用率。通过 Slot Sharing Group,用户可以影响子任务在 Slot 上的分布,并且 TaskManager 上的 Slot 可以动态改变大小,以适应不同算子的资源需求。
缓冲区去膨胀
- 这是 Flink 中的一项新技术,可以最小化 Checkpoint 的延迟和开销。它通过自动调整网络内存的用量,在确保高吞吐的同时最小化缓冲区中的数据量。
性能与效率的优化
- Flink 1.14 版本在性能和效率方面进行了优化,包括大规模作业调度的优化和细粒度资源管理,以提高资源利用率。
Table / SQL / Python API 的改进
- Flink 1.14 增强了对 SQL API 的支持,包括 Window Table-Valued Function 支持更多算子与窗口类型,以及全新的代码生成器,解决了代码超长的问题。同时,Python API 也得到了改进,包括链接 Python 函数以提高性能,以及支持环回调试模式。
告别旧版 SQL 引擎和 Mesos 支持
- Flink 1.14 移除了旧版 SQL 引擎和对 Apache Mesos 的集成,以简化代码库并移除过时的接口。
Flink 1.13 新特性
Apache Flink,作为流处理领域的佼佼者,一直致力于提供高效、低延迟、高吞吐量的数据处理能力。随着Flink 1.13的发布,一系列新特性的引入,使得大数据处理变得更加简单、自然和高效。本文将围绕Flink 1.13的几大核心新特性进行解析,并探讨其在实际应用中的价值。
被动扩缩容:让流处理应用管理更简单
- Flink 1.13引入的被动扩缩容功能,是本次更新的一大亮点。这一功能使得流处理作业的扩缩容变得像其他应用一样简单自然。用户只需修改作业的并行度,Flink就能自动调整资源分配,无需手动干预。这一特性对于长时间运行的流处理应用尤为重要,因为它能够显著降低运维成本,提高资源利用率。
不需要知道它运行在 K8s、EKS、Yarn 等之上,也不需要尝试获取特定数量的工作节点;相反,它只是使用给定的工作节点数量。这种模式下,应用的并行度会根据工作节点的数量进行调整
- 在实际应用中,被动扩缩容功能可以帮助企业根据业务需求动态调整资源,避免资源浪费或不足。
例如,在电商大促期间,流量激增,企业可以通过增加作业并行度来快速扩容,以满足数据处理需求;而在流量低谷期,则可以通过减少并行度来释放资源,降低成本。
SQL/Table API增强:提升数据处理能力
Flink 1.13在SQL/Table API方面也进行了多项增强,包括提高 DataStream API与Table API/SQL的互操作能力、优化SQL时间函数、增强Hive查询语法兼容性等。这些改进使得Flink在处理复杂数据查询时更加灵活和高效。
- DataStream API与Table API/SQL互操作能力:用户可以在DataStream和Table API/SQL之间无缝切换,实现更加灵活的数据处理流程。
- 优化SQL时间函数:支持更丰富的时间函数,如current_timestamp返回UTC+0时间,以及timestamp_ltz类型的时间戳,使得时间处理更加准确。
- 增强Hive查询语法兼容性:支持更多Hive查询语法,使得Flink能够更好地与Hive集成,实现数据共享和查询。
资源调度优化:提升作业执行效率
Flink 1.13在资源调度方面也进行了多项优化,包括新增被动资源管理模式与自适应调度模式、优化大规模作业调度以及批执行模式下网络Shuffle的性能等。这些优化使得Flink在处理大规模数据时更加高效和稳定。
- 被动资源管理模式与自适应调度模式:结合云原生的自动伸缩技术,Flink能够更好地利用云环境下的弹性计算资源,实现作业的灵活伸缩。
- 优化大规模作业调度:通过改进作业调度算法和策略,Flink能够更有效地分配和管理资源,提高作业执行效率。
- 批执行模式下网络Shuffle性能优化:针对批处理作业的特点,Flink优化了网络Shuffle的性能,减少了数据传输延迟和开销。
性能分析工具:助力问题诊断与优化
Flink 1.13还引入了一系列性能分析工具,帮助用户更好地理解和优化作业性能。这些工具包括用于识别瓶颈节点的负载和反压可视化、分析算子热点代码的CPU火焰图以及分析State Backend状态的State访问性能指标等。
- 负载和反压可视化:通过颜色和数值在UI上展示作业的繁忙程度和反压情况,帮助用户快速定位性能瓶颈。
- CPU火焰图:在Web UI中展示CPU火焰图,帮助用户分析哪些代码是性能热点,从而进行针对性优化。
- State访问性能指标:提供State Backend状态的访问性能指标,帮助用户了解状态存储的性能瓶颈,并进行相应的优化。
状态后端的变更:现在可以在从保存点恢复时更改 Flink 应用的状态后端,这意味着应用程序的状态不再锁定在初始启动时使用的状态后端
机器学习库移动到单独的工程(flink-ml)
- 为了加速 Flink 机器学习工作的发展,相关的工作已经移动到新的 flink-ml 仓库下
PyFlink 的改进: Python DataStream API 和 Table API 更接近 Java/Scala API 的功能
Flink 1.13 使 Python DataStream API 和 Table API 更接近 Java/Scala API 的功能,包括在 Python DataStream API 中添加了状态操作和用户自定义窗口的支持
Web UI 的改进: 可展示导致作业失败的最后几次异常
- Flink Web UI 现在可以展示导致作业失败的最后几次异常,这有助于调试导致后续失败的根失败原因
状态后端和检查点存储的分离
- 在 Flink 1.13 中,检查点配置被提取到自己的接口 CheckpointStorage 中
对齐检查点的支持重新调整作业并行度:在从对齐检查点恢复时,现在可以更改作业的并行度
结语
Apache Flink 1.13的发布,标志着Flink在大数据处理领域又迈出了坚实的一步。通过引入被动扩缩容、SQL/Table API增强、资源调度优化以及性能分析工具等一系列新特性,Flink不仅提升了自身的数据处理能力,还降低了用户的运维成本和学习门槛。相信在未来的大数据处理领域,Flink将继续发挥重要作用,为企业创造更多价值。
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen/p/18500748
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· autohue.js:让你的图片和背景融为一体,绝了!
2023-10-24 [Docker] Docker Compose 基础教程(概念/基础操作)