[数据库] 浅谈mysql的serverId/serverUuid
0 序
- 版本
本文围绕 mysql 5.7.38 版本开展讨论
- 情景1:
- MYSQL数据库的主从复制架构:1主1从
- MYSQL数据库的binlog应用情况:存在多个基于binlog同步机制的FlinkCdcJob,从MYSQL中增量同步数据
- 某一天,FlinkCdcJob报如下错误:
ConnectException: A slave with the same server_uuid/server_id as this slave has connected to the master; the first event '' at 4, the last event read from './mysql-bin.152542' at 1380734, the last byte read from './mysql-bin.152542' at 1380734. Error code: 1236; SQLSTATE: HY000.
【翻译】ConnectException:与该从服务器具有相同server_uuid/server_id的从服务器已连接到主服务器;第一个事件
''在第 4 行,最后一个事件在'./mysql-bin.152542'文件的1380734处读取,从'./mysql-bin.mysql-bin.152542 '文件读取的最后一个字节在1380734。错误码:1236;SQLSTATE: HY000。
【特别说明】基于binlog同步机制的FlinkCdcJob应用程序,本质上也是1个MySQL Slave
【问题原因】出现这种错误是 作业里使用的
server id和其他Flink CDC MYSQL Connector作业或其他同步工具使用的server id冲突了,server id需要全局唯一,server id是一个int类型整数。 在 CDC 2.x 版本中,source的每个并发都需要一个server id,建议合理规划好server id,比如作业的 source 设置成了4个并发,可以配置 'serverid' = '5001-5004', 这样每个 source task 就不会冲突了。from : flink cdc connectors faq
- 情景2:
- 当我们搭建MySQL集群时,自然需要完成数据库的主从同步来保证数据一致性。
- 而主从同步的实现方式也分很多种:一主一从、一主多从、链式主从、多主多从。可根据你的需要来进行设置。
- 但只要你需要主从同步,就一定要注意server-id的配置,否则会出现主从复制异常。
- 在控制数据库数据复制和日志管理中,有2个重要的配置:
server-id和server-uuid
它们会影响二进制日志文件记录和全局事务标识。
1 server-id 概述
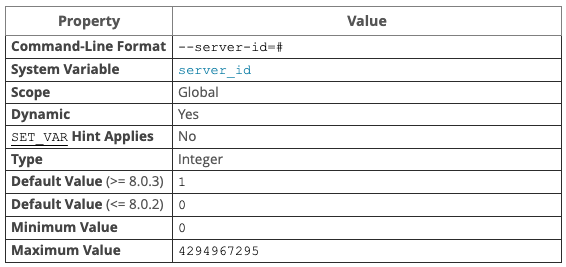
server-id的查看与配置
-
当你使用主从拓扑时,一定要对所有MySQL实例都分别指定一个独特的互不相同的
server-id。 -
默认值为
0,当server-id=0时,对于主机来说依然会记录二进制日志,但会拒绝所有的从机连接;对于从机来说则会拒绝连接其它实例。 -
MySQL实例的
server-id是一个全局变量,可以直接查看:
mysql> show variables like '%server_id%';
+---------------+-----------+
| Variable_name | Value |
+---------------+-----------+
| server_id | 171562767 |
+---------------+-----------+
1 row in set (0.00 sec)
-- 查询当前 MYSQL 实例节点 的 serverId
select @@server_id -- eg: 171562767
mysql> show variables like '%server%id%';
server_id 4198984507
server_id_bits 32
server_uuid c5df5b9e-3d7d-11ed-accf-fa163e42a616
server-id的配置/修改。
我们可以在线直接修改全局变量
server-id,但不会立即生效,所以修改后记得重启服务。
而重启后又会重新读取系统配置文件配置,导致刚才的修改失效,因此建议修改配置文件后重启服务而不是在线修改。
# my.cnf
[mysqld]
#replication
log-bin=mysql-bin
server-id=171562767
sync_binlog=1
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
server-id的用途与影响分析 = 为什么 serverId 不能重复?
server-id用于标识数据库实例,防止在链式主从、多主多从拓扑中导致SQL语句的无限循环:
- 标记
binlog event的源实例- 过滤主库
binlog,当发现server-id相同时,跳过该event执行,避免无限循环执行。- 如果设置了
replicate-same-server-id=1,则:执行所有event,但有可能导致无限循环执行SQL语句。
我们用两个例子来说明server-id为什么不要重复:
- 当主库和备库是
server-id重复时:
由于默认情况
replicate-same-server-id=0,因此备库会跳过所有主库同步的数据,导致主从数据的不一致。
- 当两个备库
server-id重复时:
会导致从库跟主库的连接时断时连,产生大量异常。
根据MySQL的设计,主库和从库通过事件机制进行连接和同步,当新的连接到来时,如果发现server-id相同,主库会断开之前的连接并重新注册新连接。
当A库连接上主库时,此时B库连接到来,会断开A库连接,A库再进行重连,周而复始导致大量异常信息。
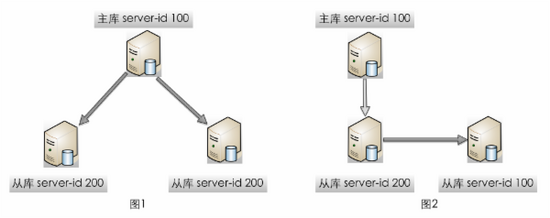
生成server-id的规则 x4
既然server-id不能相同,而当我们有10个实例时,怎么保证每个都不同呢?有几种常用的方法:
- 随机数
- 时间戳
- IP地址+端口
- 在管理中心集中分配,生成自增ID
上面的这些方法都可以,但是注意不要超过了最大值2^32-1,同时值最好>2。
推荐采用的方法是:IP地址后两位+本机MySQL实例序号
但如果是通过docker来进行管理多实例时,这个怎么生成大家可以想下有没有什么优美的解决方案。
2 server-uuid 概述
生成

- MySQL服务会自动创建并生成server-uuid配置:
- 读取${data_dir}/auto.cnf文件中的UUID
- 如果不存在,自动创建文件和生成新的UUID并读取
shell> cat ~/mysql/data/auto.cnf
[auto]
server-uuid=fd5d03bc-cfde-11e9-ae59-48d539355108
查看
- 查验方式
mysql> show variables like '%server%id%';
server_id 4198984507
server_id_bits 32
server_uuid c5df5b9e-3d7d-11ed-accf-fa163e42a616
- 这个
auto.cnf配置风格类似于my.cnf,但这个文件只包含一个auto配置块和一行server-uuid配置。它是自动创建的,因此不要修改它的内容。 - 在主从拓扑中,主从可以知道互相的UUID,在主机上使用
show slave hosts,在从机上使用show slave status查看Master_UUID字段。 server-uuid参数并不能取代server-id,他们有不同的作用。当主从同步时,如果主从实例的server-uuid相同会报错退出,不过我们可以通过设置replicate-same-server-id=1来避免报错(但不推荐)。
server-uuid 与 gtid 的关系 : gtid = {server-uuid}:{transaction-id}
3 补充:MYSQL主从复制场景
show variables like '%server%id%' | 在主库、从库中查看
- 查询样例:
server_id 4198984507
server_id_bits 32
server_uuid c5df5b9e-3d7d-11ed-accf-fa163e42a616
show slave hosts | 在主库查看
show slave hosts
- 显示当前配置为复制从服务器(slave)的主机信息(包含了所有配置为复制从服务器的主机信息)
- 通常用于快速检查和验证哪些服务器被配置为复制数据,以及它们的网络连接状态
- 在MySQL 5.7及更高版本中使用的,而在更早的版本中,可能需要使用
SHOW SLAVE STATUS;命令来获取类似的信息
- 查询样例:
mysql> show slave hosts
| Server_id | Host | Port | Master_id | ------------------------------------ |
|---|---|---|---|---|
| 166523813 | 3306 | 1306176980 | a8bdde3e-8008-11ed-83c4-fa163e5eb848 |
没有主从复制架构的MYSQL实例,查询结果为空
show slave status | 在主库查看
- 查询样例:







X 参考文献
- 如何生成唯一的server Id,server_id为何不能重复? - 博客园
- mysql中的server_id到底有什么用?详解mysql配置中的server_id - CSDN 【推荐】
- [数据库] MYSQL之binlog权限概述 - 博客园/千千寰宇 【推荐】
- SHOW SLAVE HOSTS命令在MySQL中用于显示当前配置为从节点(slave)的主机信息 - CSDN
- 双slave的server_uuid相同问题 - CSDN 【推荐】
MySQL 5.6 用 128 位的 server_uuid 代替了原本的 32 位 server_id 的大部分功能。
原因很简单,server_id 依赖于 my.cnf 的手工配置,有可能产生冲突 —— 而自动产生 128 位 uuid 的算法可以保证所有的 MySQL uuid 都不会冲突。
在首次启动时 MySQL 会调用 generate_server_uuid() 自动生成一个 server_uuid,并且保存到 auto.cnf 文件 —— 这个文件目前存在的唯一目的就是保存 server_uuid。
在 MySQL 再次启动时会读取 auto.cnf 文件,继续使用上次生成的 server_uuid。
使用 SHOW 命令可以查看 MySQL 实例当前使用的 server_uuid:SHOW GLOBAL VARIABLES LIKE 'server_uuid';
它是一个 MySQL 5.6 global variables
全局唯一的 server_uuid 的一个好处是:
可以解决由 server_id 配置冲突带来的 MySQL 主备复制的异常终止
在 MySQL 5.6,Slave 向 Master 申请 binlog 时,会首先发送自己的 server_uuid,Master 用 Slave 发送的 server_uuid 代替 server_id (MySQL 5.6 之前的方式)作为 kill_zombie_dump_threads 的参数,终止冲突或者僵死的 BINLOG_DUMP 线程。

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号