[数据管理] 数据治理/大数据平台-开源软件与框架篇
目录
- 1 序:数据治理体系
- 2 最新一代数据治理开源软件
- 2.0 一站式数据开发集成平台
- WeBank : DataSphere Studio : 982 fork / 2.9k star | Since : Nov 24, 2019
- [闭源] Alibaba : DataWorks(一站式大数据开发治理平台)
- [闭源] Huawei : Data Arts Studio(数据治理中心)
- 2.1 元数据
- Open Metadata : 753 fork / 3.7k star | Since : Aug 1, 2021 【推荐】
- Amundsen : 945 fork / 4.2k star | Since : Feb 3, 2019
- Marquez : 279 fork / 1.6k star | Since : Jul 1, 2018
- Data Hub : 2.6K fork / 9K star | Since : Nov 15, 2015
- Apache Atlas : 817 fork / 1.7k star | Since : Nov 16, 2014
- Dataedo [闭源]
- ERD Online [闭源]
- 2.2 数据集成
- Apache Flink CDC : 1.8k fork / 5.5k star | Since : 2020.07.05 【推荐】
- Apache Sea Tunnel : 1.5k fork / 7k star | Since : Jul 30, 2017 【推荐】
- Apache InLong(原 TubeMQ) : 508 fork / 1.3k star | Since : 2019
- Pentaho Kettle : 3.2k fork / 7.2k star | Since : Oct 6, 2013
- ChunJun(原Flink X) : 1.7k / 3.9k | Since : Apr 29, 2018
- DataX : 5.2k fork / 14.8k star
- Apache Flume : 1.6k fork / 2.5k star | Since : 2012 【推荐(日志采集/loT数据采集场景)】
- BitSail :328 fork / 1.6k star | Since : 2022.9.25 :高性能数据集成引擎 【活跃度大幅衰退/不建议】
- AiyByte //TODO
- CloudCanal //TODO
- Nifi //TODO
- 数据集成-数据采集-网络爬虫
- 其他 : Canal : 7.5 fork / 27.4k star | Since : Sep 21, 2014
- 其他: Apache Sqoop(Hadoop生态下数据导入/导出/迁移的离线集成工具):587 fork / 967 star | Since: 2009 【项目已废止/不看好】
- 2.3 数据开发
- Apache Flink 【推荐】
- Apache Spark 【推荐】
- Pentaho Kettle(传统ETL) 【推荐】
- Apache Stream Park : 980 fork / 3.8k star | Since : 2021.5.23【推荐(数据开发作业运管平台)】
- 2.4 数据质量
- Apache Griffin : 588 fork / 1.1k star | Since: 2016.12.07
- Qualitis : 300 fork / 683 star | Since:
- Apache Dolphin Scheduler : 4.5 fork / 12.4k star | Since: Feb 24, 2019 【推荐】
- Ataccama //TODO
- Great Expectations //TODO
- Deequ //TODO
- OpenRefine //TODO
- DataCleaner //TODO
- Open Data Quality (ODQ) //TODO
- 其他 //TODO
- 闭源版 : Data Quality Center(DQC阿里巴巴数据质量监控平台)
- 闭源版 : 美团 DataMan
- 闭源版 : BDP(京东大数据质量监控平台)
- 2.5 数据标准
- 2.6 数据模型 /数据建模
- 2.7 数据资产
- 2.8 数据服务
- 2.9 数据分析与可视化
- [闭源] BI类 : Microsoft : Power BI + Copilot 【推荐】
- [闭源] BI类:Tableau 【推荐】
- BI类:Superset : 13.1k fork / 60.6k star | Since: 2015.6.28 【推荐】
- BI类:Metabase : 5k fork / 37.3k star | Since: 2015.2.1
- BI类:DataEase : 3k fork / 16.3k star | Since: 2010.3.11 【推荐】
- BI类:SmartChart : 111 fork / 607 star | Since : 2020.11.29
- BI类:Redash : 4.3k fork / 25.4k star | Since : 2013.10.20 【推荐】
- BI类:Grafana : 11.8k fork / 61.6k star | Since: 2013.12.1 【推荐(IT监控观测系统)】
- BI类:Kibana【推荐(ELK日志系统)】
- 基础组件类:ECharts : 19.6 fork / 59.7k star | Since : 2013.05.26 【推荐】
- 基础组件类:D3.js : 22.9 fork / 108k star | Since: 2011 【推荐】
- 基础组件类:Three.js : 35.2 fork / 101k star | Since : 2010.5.21
- 基础组件:ArcGIS API for JavaScript
- 2.10 调度系统 & 工作流系统
- X 参考文献
数据治理可以有效保障数据建设过程在一个合理高效的监管体系下进行,最终提供高质量、安全、流程可追溯的业务数据。
1 序:数据治理体系
企业数据治理体系包括元数据管理、主数据管理、数据资产管理、数据质量管理、数据安全及数据标准等内容。
2 最新一代数据治理开源软件
2.0 一站式数据开发集成平台
WeBank : DataSphere Studio : 982 fork / 2.9k star | Since : Nov 24, 2019
- DataSphere Studio
- https://github.com/WeBankFinTech/DataSphereStudio
DataSphere Studio(简称 DSS)是微众银行自研的数据应用开发管理集成框架。
基于插拔式的集成框架设计,及计算中间件 Linkis ,可轻松接入上层各种数据应用系统,让数据开发变得简洁又易用。在统一的 UI 下,DataSphere Studio 以工作流式的图形化拖拽开发体验,将满足从数据交换、脱敏清洗、分析挖掘、质量检测、可视化展现、定时调度到数据输出应用等,数据应用开发全流程场景需求。DSS 通过插拔式的集成框架设计,让用户可以根据需要,简单快速替换 DSS 已集成的各种功能组件,或新增功能组件。借助于 Linkis 计算中间件的连接、复用与简化能力,DSS 天生便具备了金融级高并发、高可用、多租户隔离和资源管控等执行与调度能力。
-
主要编程语言:Java / Scala
-
社区活跃情况

[闭源] Alibaba : DataWorks(一站式大数据开发治理平台)
- 简介
- Slogan : 覆盖大数据全生命周期,释放企业的数据生产力
阿里云DataWorks基于阿里云MaxCompute/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
作为阿里巴巴数据中台的建设者,DataWorks从2009年起不断沉淀阿里巴巴大数据建设方法论,同时与数万名政务/金融/零售/互联网/能源/制造等客户携手,助力产业数字化升级。
- URL
[闭源] Huawei : Data Arts Studio(数据治理中心)
- 简介
- Slogan : 一站式数据全生命周期管理工具平台,库仓湖智全流程治理,释放数据价值
- URL
2.1 元数据
Open Metadata : 753 fork / 3.7k star | Since : Aug 1, 2021 【推荐】
- Open Metadata | 元数据管理
- https://open-metadata.org/
- https://github.com/open-metadata/OpenMetadata
Open-Metadata 是元数据的开放标准,为端到端元数据管理解决方案提供了基础能力。提供数据发现、数据治理、数据协同、数据质量和可观测性的所有必要组件。


-
主要编程语言 : TypeScript / Java / Python
-
社区活跃情况

Commits
Amundsen : 945 fork / 4.2k star | Since : Feb 3, 2019
- Amundsen | 数据发现、元数据引擎
-
主要编程语言: Python / TypeScript
-
社区活跃情况

Commits
Marquez : 279 fork / 1.6k star | Since : Jul 1, 2018
- Marquez
- https://marquezproject.ai/
- https://github.com/MarquezProject/marquez
Marquez 是一款WeWork发布并开源的元数据服务,用于数据生态系统元数据的收集、汇总及可视化。它维护着数据集的消费和生产,为作业运行时和数据集访问频率提供全局可见性,提供集中的数据集生命周期管理等。

-
主要编程语言:Java / TypeScript
-
社区活跃度

Commits
Data Hub : 2.6K fork / 9K star | Since : Nov 15, 2015
- Data Hub |
DataHub 是由Linkedin开源的,官方Slogan:The Metadata Platform for the Modern Data Stack - 为现代数据栈而生的元数据平台。
目的就是为了解决多种多样数据生态系统的元数据管理问题
它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。
-
主要编程语言:Java / Python / TypeScript
-
社区活跃情况:

Commits
Apache Atlas : 817 fork / 1.7k star | Since : Nov 16, 2014
- Apache Atlas | 元数据、数据血缘
Apache Atlas是Apache Hadoop的数据和元数据治理的框架,是Hortonworks 公司联合其他厂商与用户于2015年发起数据治理倡议,2015年5月5日进入Apache孵化,2017年6月21日成为Apache顶级项目。
是为解决Hadoop生态系统的元数据治理问题而产生的开源项目。它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心登能力。
-
主要编程语言 : Java / JavaScript
-
社区活跃度

Commits
Dataedo [闭源]
- Dataedo | 数据字典、元数据管理
Dataedo是一个开源的数据字典和元数据管理工具。它可以帮助用户创建和维护数据字典,并对数据进行元数据建模和文档化。


ERD Online [闭源]
- ERD Online
ERD(Entity-Relationship Diagram) Online是全球第一个开源、免费在线数据建模、元数据管理平台(口号)。提供简单易用的元数据设计、关系图设计、SQL查询等功能,辅以版本、导入、导出、数据源、SQL解析、审计、团队协作等功能、方便我们快速、安全的管理数据库中的元数据。


2.2 数据集成
在大数据开发工作中,数据集成工具是数据工程的首要环节,一个好的数据集成系统从可用性、架构扩展性、底层引擎选型、数据源支持能力等方面都需要一定的考量。
-
Apache Flink CDC
-
Apache Sea Tunnel: 下一代高性能、分布式、海量数据集成框架
-
Apache InLong: 一站式、全场景的海量数据集成框架
-
Chunjun:基于Flink的批流统一的数据同步工具
-
BitSail : 高性能数据集成引擎
-
AirByte:开源的数据移动基础设施
-
CloudCanal : 数据同步、迁移工具
-
Flume :开源分布式、高可靠的流式日志采集系统
-
Canal:数据库增量日志解析、采集工具
-
Nifi:一个易于使用、功能强大且可靠的系统,用于处理和分发数据
-
DataX:异构数据源离线同步工具
-
...
-
推荐文献
Apache Flink CDC : 1.8k fork / 5.5k star | Since : 2020.07.05 【推荐】

- 简介
Flink CDC(Change Data Capture)是基于Apache Flink的一个库,用于捕获并处理数据库的变更数据。它可以实时监控数据库的增删改操作,并输出到Flink进行处理。注:
CDC:是一种程序思想,理念,不涉及某一门具体的技术
Flink CDC是一个流数据集成工具,旨在为用户提供更强大的 API。
它允许用户通过 YAML 优雅地描述他们的 ETL 管道逻辑,并帮助用户自动生成自定义的 Flink 运算符并提交作业。
Flink CDC 优先优化任务提交流程,并提供增强功能,例如模式演变、数据转换、完整数据库同步和一次性语义。
Flink CDC 与 Apache Flink 深度集成并由其提供支持,可提供:
✅ 端到端数据集成框架
✅ 数据集成用户可使用 API 轻松创建作业
✅ Source / Sink 中的多表支持
✅ 同步整个数据库
✅ 模式演化能力

Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的
上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
-
大数据生态位

-
发展历程
- 2020年7月,Flink CDC发布1.0版本。
- 2021年中旬,Flink CDC发布2.0版本。
- 截止目前,最新发布版本: Flink CDC 3.2 版本。 | 截止: 2024.7.11

Flink CDC 1.x只能说是一个比较有趣的小玩具,还不具备大规模商业盈利的价值。

在
Flink CDC 2.x版本中,Flink CDC 引入了 Netfix DBLog 中的无锁算法,彻底解决了全增量切换上业务停滞的问题,同时得益于 FLIP-27 对 Flink Source API 的重构,Flink CDC 也基于 FLIP-27 升级到了新的框架设计,至此,Flink CDC 被大规模公司使用并投入到生产中。

近期,Flink CDC 发布了全新的 3.0 版本,并宣布捐赠回 Flink 主项目。
在新的 3.0 版本中,Flink CDC 对于接口和架构上做了很大的升级和调整,对于整体项目的定位也从之前的Flink Source Connector转变为了Data Integration Engine。
未来将与SeaTunnel、DataX、Chunjun(原 Flink X)等一系列老牌数据集成项目同台竞技,让我们拭目以待。
- 使用场景
实时数据同步
实时数据分析
- 优点
实时性强
结合了Flink的强大处理能力
- 对比:
Jdbc Connectorsvs.Flink CDC Connectors
JDBC Connectors连接器,确实可以读取外部的 数据库。比如:MySQL、Oracle、SqlServer等。
但是,JDBC连数据库,只是周期的、瞬时的操作,没办法持续监听数据库的数据变化。
Flink CDC Connectors,可以实现数据库的变更捕获,能够持续不断地把变更数据同步到下游的系统中。
-
社区活跃情况

-
URL
- https://ververica.github.io/flink-cdc-connectors/ | 原官网,已废止
- https://github.com/ververica/flink-cdc-connectors | 原Github官网,已废止
- https://github.com/apache/flink-cdc | 现Github官网
- https://nightlies.apache.org/flink/flink-cdc-docs-stable | 现Github官网
- https://issues.apache.org/jira/projects/FLINK/issues/ | issues
- https://nightlies.apache.org/flink/flink-cdc-docs-master/docs/get-started/introduction/ | document
- https://nightlies.apache.org/flink/flink-cdc-docs-master/docs/developer-guide/understand-flink-cdc-api/
- https://nightlies.apache.org/flink/flink-cdc-docs-release-3.1/
- https://nightlies.apache.org/flink/flink-cdc-docs-master/zh/docs/developer-guide/contribute-to-flink-cdc/ | 向 Flink CDC 提交贡献
- 第三方文档
- 大数据之flinkCDC - CSDN
- 【Flink CDC】Flink CDC 的概览和使用 - CCSDN
Apache Sea Tunnel : 1.5k fork / 7k star | Since : Jul 30, 2017 【推荐】
- Sea Tunnel

-
主要编程语言:Java
-
社区活跃情况

Apache InLong(原 TubeMQ) : 508 fork / 1.3k star | Since : 2019
- 简介
Apache InLong(应龙)是起源于腾讯的一站式的、海量数据集成框架,提供自动、安全、可靠和高性能的数据传输能力,方便业务构建基于流式的数据分析、建模和应用。
InLong项目原名TubeMQ,专注于高性能、低成本的消息队列服务。
为了进一步释放TubeMQ周边的生态能力,我们将项目升级为InLong,专注打造一站式海量数据集成框架。
Apache InLong依托 10 万亿级别的数据接入和处理能力,整合了数据采集、汇聚、存储、分拣数据处理全流程,拥有简单易用、灵活扩展、稳定可靠等特性。
该项目最初于 2019 年 11 月由腾讯大数据团队捐献到Apache孵化器,2022 年 6 月正式毕业成为 Apache 顶级项目。
目前InLong正广泛应用于广告、支付、社交、游戏、人工智能等各个行业领域,为多领域客户提供高效化便捷化服务。
-
大数据生态位

-
URL
-
主要编程语言: Java
-
社区活跃度

关注度

贡献情况
Pentaho Kettle : 3.2k fork / 7.2k star | Since : Oct 6, 2013
- Kettle (全名 : Pentaho Data Integration - Kettle)
-
主要编程语言:Java
-
社区活跃情况

ChunJun(原Flink X) : 1.7k / 3.9k | Since : Apr 29, 2018
- ChunJun(纯均)
- https://dtstack.github.io/chunjun/
- https://github.com/DTStack/chunjun
- https://www.dtstack.com/resources?src=dsyzh
ChunJun 是易用、稳定、高效的批流一体的数据集成框架。
该项目最早启动的初衷是为【袋鼠云】的核心业务一站式大数据基础软件 - 数栈 ,打造一款具有 “袋鼠特色 “的核心计算引擎,承载实时平台、离线平台、数据资产平台等多个应用的底层数据同步及计算任务。
ChunJun 基于 Flink 并采用插件式架构,将源数据库抽象成 Reader 插件,将目的数据库抽象成 Writer 插件。

- 核心特点
- 基于 json、sql 构建任务
- 支持多种异构数据源之间数据传输
- 支持断点续传、增量同步
- 支持任务脏数据存储管理
- 支持 Schema 同步
- 支持 RDBS 数据源实时采集

-
主要编程语言:Java
-
社区活跃情况

DataX : 5.2k fork / 14.8k star
- DataX => DataWorks (商业版)
- https://github.com/alibaba/DataX
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
- 主要编程语言:Java(97.6%)、Python (2.3%)
Apache Flume : 1.6k fork / 2.5k star | Since : 2012 【推荐(日志采集/loT数据采集场景)】
- 简介
Apache Flume是一种分布式、可靠且可用的服务,多用于高效收集、聚合和移动大量日志数据到集中式数据存储空间中。
它具有基于流数据流的简单而灵活的架构。
它具有可调整的可靠性机制和多种故障转移和恢复机制,具有稳健性和容错性。它使用简单的可扩展数据模型,允许在线分析应用程序。
- 使用场景
- 日志数据收集
- 数据聚合
- 架构/原理

- 核心角色:Agent
- 优点
- 高可靠性
- 良好的扩展性
- 缺点
- 主要针对日志数据
- 配置相对复杂
- URL
- https://flume.apache.org
- http://flume.apache.org/FlumeUserGuide.html | 文档
- http://archive.apache.org/dist/flume/https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz | 下载地址
- https://github.com/apache/logging-flume
- 第三方文档
- 社区活跃情况

BitSail :328 fork / 1.6k star | Since : 2022.9.25 :高性能数据集成引擎 【活跃度大幅衰退/不建议】
- 简介
BitSail是字节跳动开源的基于分布式架构的高性能数据集成引擎, 支持多种异构数据源间的数据同步,并提供离线、实时、全量、增量场景下的全域数据集成解决方案。
目前服务于字节内部几乎所有业务线,包括抖音、今日头条等,每天同步数百万亿数据
- 支持功能
- 全域数据集成解决方案, 覆盖离线、实时、增量场景
- 分布式以及云原生架构, 支持水平扩展
- 在准确性、稳定性、性能上,成熟度更好
- 丰富的基础功能,例如类型转换、脏数据处理、流控、数据湖集成、自动并发度推断等
- 完善的任务运行状态监控,例如流量、QPS、脏数据、延迟等
- 使用场景
- 异构数据源海量数据同步
- 流批一体数据处理能力
- 湖仓一体数据处理能力
- 高性能、高可靠的数据同步
- 分布式、云原生架构数据集成引擎
- 主要特点
- 简单易用,灵活配置
- 流批一体、湖仓一体架构,一套框架覆盖几乎所有数据同步场景
- 高性能、海量数据处理能力
- DDL自动同步
- 类型系统,不同数据源类型之间的转换
- 独立于引擎的读写接口,开发成本低
- 任务进度实时展示,正在开发中
- 任务状态实时监控

- URL
- 社区活跃情况

AiyByte //TODO
CloudCanal //TODO
Nifi //TODO
数据集成-数据采集-网络爬虫
其他 : Canal : 7.5 fork / 27.4k star | Since : Sep 21, 2014
- https://github.com/alibaba/canal
阿里巴巴 MySQL binlog 增量订阅&消费组件
-
主要编程语言:Java
-
社区活跃情况

其他: Apache Sqoop(Hadoop生态下数据导入/导出/迁移的离线集成工具):587 fork / 967 star | Since: 2009 【项目已废止/不看好】
Sqoop是一款开源的数据集成工具,用于在Hadoop和关系型数据库(如:mysql 、postgresql)之间高效地传输数据。
- 主要功能:它可以将数据从关系型数据库导入到Hadoop的HDFS中,也可以将数据从HDFS导出到关系型数据库。
- 发展历史:
- 起于2009 ,起初作为 Hadoop 的第三方模块。
- 后来为了方便部署和快速迭代,Sqoop独立出来作为apache 的项目;
- 但目前
Apache已终止Sqoop项目的维护了。(Apache Sqoop 已于 2021年6月 从 apache 社区退役 到 阁楼(Attic))
- 版本情况
其主要版本有:
Sqoop1和Sqoop2
- Sqoop1的最新稳定版本是
1.4.7- Sqoop2的最新版本是
1.99.7请注意,
1.99.7与1.4.7不兼容,且功能不完整,不适用于生产部署。总之,sqoop2版本不好用于生产
- URL
- https://sqoop.apache.org
- https://github.com/apache/sqoop
- https://archive.apache.org/dist/sqoop/ | 安装包
- 第三方文档
- 使用场景
- Hadoop数据导入、数据导出
- 数据迁移
- 优点
- 简单易用
- 支持多种关系型数据库
- 缺点
- 只限于Hadoop生态系统
- 不支持实时数据处理
- 社区活跃情况

2.3 数据开发
Apache Flink 【推荐】
- Apache Flink
Apache Spark 【推荐】
- Apache Spark
Pentaho Kettle(传统ETL) 【推荐】
- 参见本文: 数据集成-Pentaho Kettle
Apache Stream Park : 980 fork / 3.8k star | Since : 2021.5.23【推荐(数据开发作业运管平台)】
- 简介
Apache StreamPark™是一个流式应用程序开发框架,为使用 Apache Flink® 和 Apache Spark™ 开发流处理应用程序提供了开发框架,同时 StreamPark 还是一个专业的流式应用程序管理平台,其核心功能包括应用程序开发、调试、部署、运行等。
它大大简化了流式应用程序的开发和运行,使企业能够实时从数据中获得即时洞察。
- Slogan : Make stream processing easier! Easy-to-use streaming application development framework and operation platform.(使流处理更容易!易于使用的流媒体应用开发框架和操作平台。)

- 内部组成
streampark-core: 是开发过程中使用的框架,支持编码开发,规范配置文件,遵循约定优于配置原则,streampark-core提供开发时Runtime Content和一系列开箱即用的Connector,通过扩展DataStream相关方法、集成DataStream与Flink SQL API等方式简化繁琐的操作,让用户专注于业务逻辑,提升开发效率和开发者体验。streampark-console: 是一个全面的实时 Low Code 数据平台,可以更加便捷的管理 Flink 任务。它融合了众多最佳实践的经验,集成了项目编译、发布、参数配置、启动、savepoint、Flink SQL、监控等诸多功能,大大简化了 Flink 任务的日常操作和维护。最终目标是打造一站式大数据平台,能够提供流批融合、湖仓融合的解决方案。
-
社区活跃度

-
URL
2.4 数据质量

Apache Griffin : 588 fork / 1.1k star | Since: 2016.12.07


Dashboard

质量任务的开发运行流程
- 简介
- 自身定位: Big Data Quality Solution For Batch and Streaming
- 起源于eBay中国、开源的数据质量套件,专注于大数据场景下的数据质量实时监控和离线评估。
- Apache 顶级项目,是一个优秀并且完备的数据质量检查系统,
- 具有独立的UI、调度和内置规则,依赖于 Apache Livy 来提交 Spark 作业
- 一个独立的系统,较难无缝地接入到工作流当中来实现当出现严重数据质量问题时的阻断。【缺点】

- 系统关键构成
Griffin 基于微服务架构设计,采用了模块化的设计思想,使其易于扩展和维护。项目的关键组成部分包括:
- 数据质量度量:Griffin 提供了一套灵活的数据质量度量框架,支持自定义指标,以满足不同场景下的需求。
- 实时监控:项目集成了流处理引擎(如Flink或Spark Streaming),能够实时监控数据质量,快速发现并报警数据异常。
- 离线评估:对于大量历史数据,Griffin 可以进行批处理评估,提供详尽的数据质量报告。
- 可视化界面:通过Web UI,用户可以直观地查看数据质量状态,方便快捷地管理数据质量规则。
Griffin 系统主要分为:数据收集处理层(Data Collection&Processing Layer)、后端服务层(Backend Service Layer)和用户界面(User Interface)

- 系统架构
在
Griffin的架构中,主要分为Define、Measure和Analyze三个部分。

架构图
各部分的职责如下:
Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)Measure:主要负责执行统计任务,生成统计结果Analyze:主要负责保存与展示统计结果
基于以上功能,我们大数据平台计划引入Griffin作为数据质量解决方案,实现数据一致性检查、空值统计等功能

架构图
Griffin是属于模型驱动的方案,基于目标数据集合或者源数据集(基准数据),用户可以选择不同的数据质量维度来执行目标数据质量的验证。支持两种类型的数据源:
- batch数据:通过数据连接器从Hadoop平台收集数据
- streaming数据:可以连接到诸如Kafka之类的消息系统来做近似实时数据分析
- 使用步骤
要使用Apache Griffin支持的数据源,你需要做以下几步:
- 配置数据源的连接信息。
- 定义数据源查询,用于获取数据。
- 定义数据质量规则,用于比较实际数据和期望的标准。
- 配置监控策略,指定何时和如何执行数据质量检查。
- 执行数据质量检查并分析结果。
- 系统特点
- 度量:精确度、完整性、及时性、唯一性、有效性、一致性。
- 异常监测:利用预先设定的规则,检测出不符合预期的数据,提供不符合规则数据的下载。
- 异常告警:通过邮件或门户报告数据质量问题。
- 可视化监测:利用控制面板来展现数据质量的状态。
- 实时性:可以实时进行数据质量检测,能够及时发现问题。
- 可扩展性:可用于多个数据系统仓库的数据校验;基于微服务架构,易于添加新的度量标准或集成新的系统。
- 可伸缩性:工作在大数据量的环境中,目前运行的数据量约1.2PB(eBay环境)。
- 灵活性:支持多种数据源和计算引擎,适应不同的业务环境。
支持的数据源:hive、text文件、avro文件和实时数据源kafka、其他数据源(如Neo4j, Elasticsearch等,需要自定义插件支持)
- 全面性:涵盖实时/流式和批量两种数据处理模式,提供全面的数据质量解决方案。
- 易用性:提供图形化的用户界面,使得配置和监控数据质量变得简洁、易用;可以管理数据资产和数据质量规则;同时用户可以通过控制面板查看数据质量结果和自定义显示内容。
- 社区活跃:作为Apache孵化器项目,拥有活跃的开发者社区,持续改进和优化。
-
社区活跃情况

-
依赖组件
- JDK (1.8 or later versions)
- MySQL(version 5.6及以上)
- Hadoop (2.6.0 or later)
- Hive (version 2.x)
- Spark (version 2.2.1)
- Livy(livy-0.5.0-incubating)
- ElasticSearch (5.0 or later versions)
- 发展历程
Apache Griffin 于 2016 年 12 月 7 日被接受为 Apache 孵化器项目。
Apache Griffin 于 2018 年 11 月 21 日毕业成为 Apache 顶级项目。
-
主要编程语言: Scala 35% / Java 33 % / TypeScript 13.5% / ...
-
URL
Qualitis : 300 fork / 683 star | Since:
- 简介
- 微众银行开源的数据质量管理系统,专注于解决业务系统运行、数据中心建设及数据治理过程中的数据质量问题。
- 具备较丰富的内置规则,界面简洁容易使用
- 它提供了多种数据质量检测方法和自动生成报告的功能
- 依赖于 Linkis 作为执行Spark作业的引擎
- 如果想要实现无缝接入工作流需要依赖 DataSphere Studio,不够轻量级 (前置依赖、缺点)
Qualitis是一个数据质量管理平台,支持多种数据源的质量验证、通知和管理,用于解决数据处理过程中出现的各类数据质量问题。
Qualitis基于Spring Boot,向Linkis平台提交质量模型任务,提供数据质量模型构建、数据质量模型执行、数据质量验证、数据质量报告生成等功能。同时,Qualitis提供金融级资源隔离、管理、权限控制等企业级特性,保证在高并发、高性能、高可用场景下也能稳定运行。
- 特点

- 定义数据质量模型。支持以下数据质量模型:
1.单表模型。
2.多表模型。
3.自定义模型。
同时,Qualitis预置了多种数据质量校验模板,包括空值检查、空白检查、数字检查、枚举检查等常见检查,简化了数据质量模型定义。
- 数据质量模型调度。支持数据质量模型调度。
- 数据质量报告。支持生成数据质量报告。
- 日志管理 支持数据质量任务的管理。
- 异常数据管理。支持异常数据存储,可快速定位问题。
- 工作流。支持工作流,工作流需要借助DataSphereStudio。
- 管理员控制台
提供管理员控制台,同时支持人员管理、权限控制管理、权限控制管理、元数据管理等。
-
架构

-
URL
- 主要编程语言: Java 78.6% / Vue 17.2% / JavaScript 3.9%
Apache Dolphin Scheduler : 4.5 fork / 12.4k star | Since: Feb 24, 2019 【推荐】
- 参考文献
- 简介
自身定位: Apache DolphinScheduler是一个分布式和可扩展的开源工作流协调平台,具有强大的DAG可视化界面
- 社区活跃情况

- URL
Ataccama //TODO
- 虽然Ataccama并非完全开源,但它提供了一个包含AI驱动的数据管理功能的平台,适合需要高级数据治理和数据质量解决方案的场景。
Great Expectations //TODO
- 一个开源的数据测试框架,帮助验证数据集是否满足预期,支持在数据管道中嵌入质量检查,便于自动化数据质量保证。
Deequ //TODO
- 由亚马逊开源的数据质量库,基于Scala和Spark构建,用于定义数据质量规则并执行它们,适用于大数据环境。
OpenRefine //TODO
- 前身是Google Refine,是一个强大的数据清理和转换工具,适用于准备数据进行进一步的质量分析。
DataCleaner //TODO
- 提供数据质量分析、清洗和监测的开源平台,支持多种数据源,适合进行数据质量初步评估和持续监控。
Open Data Quality (ODQ) //TODO
- 提供数据质量规则引擎和工作流管理,支持数据清洗、标准化和质量评估,适合集成到现有的数据架构中。
其他 //TODO
Metadata.io (Amundsen)
- 虽偏重于元数据管理,但其提供的数据目录和质量指标功能有助于理解数据质量和促进数据治理。
Apache Nifi
- 虽然主要是一个数据集成工具,但其丰富的处理器和强大的数据路由、转换能力使其也能在数据质量流程中发挥作用。
闭源版 : Data Quality Center(DQC阿里巴巴数据质量监控平台)
- 系统架构图

(1)基于线上业务数据,进行数据采集
(2)基于监控规则库,执行SQL任务,进行计算处理
(3)基于用户规则,发送数据报警(短信、邮件)
- 系统流程图

(1)用户进行规则配置
(2)通过定时的调度任务触发检查任务执行
(3)基于任务配置,获取样本数据
(4)基于计算返回检验结果
(5)调度根据检验结果,决定是否阻断干预(强依赖、弱依赖)
闭源版 : 美团 DataMan
- 系统架构
DataMan系统建设总体方案基于美团的大数据技术平台。
自底向上包括:检测数据采集、质量集市处理层;质量规则引擎模型存储层;系统功能层及系统应用展示层等。
整个数据质量检核点基于技术性、业务性检测,形成完整的数据质量报告与问题跟踪机制,创建质量知识库,确保数据质量的完整性(Completeness)、正确性(Correctness)、当前性(Currency)、一致性(Consistency)。


- metric展示

闭源版 : BDP(京东大数据质量监控平台)
-
简介
京东数据质量监控系统(简称:数据质量系统) 是数据仓库、数据集市中表的数据变化进行监控。
数据质量系统根据用户设定采集项配置、规则项配置、预警规则设置(枚举值),对用户指定的表进行每日定时数据采集、计算,并与历史数据或维表进行比对验证。
最终将触发预警规则的异常数据以短信、邮件、App 等方式及时通知给用户。 -
系统架构图

关系型数据库mysql和非关系型数据库HBase作为数据源,进行监控
- 系统流程图

(1)数据监控
(2)运行日志
(3)数据报警
(4)规则配置
- 监控展示

2.5 数据标准
2.6 数据模型 /数据建模
2.7 数据资产
2.8 数据服务
2.9 数据分析与可视化

- 推荐文献
- 如何选择BI工具:Power BI向左、Tableau向右(上) - Zhihu | 2024.05
[闭源] BI类 : Microsoft : Power BI + Copilot 【推荐】

-
PowerBI vs Tableau : Power BI 借助 Microsoft 研发能力及生态圈、AI/Coiplot 两大利器,在现阶段已逐渐成为 BI 领域的扛把子。
-
Power BI 架构

from : 国内BI大神老金提供的 Power BI 架构
- 第1种:基于单机 Power BI Desktop + 共享文件夹
这种架构是最简单,而且免费,只需要到微软Power BI官网下载一个Power BI Desktop就可以开始你的数据分析之旅了
当然,免费的肯定也有很大局限性,比如无法通过浏览器和移动端查看报表,报表性能受本地电脑配置限制,所以比较适合个人玩玩。
- 第二种:基于混合云Power BI Pro + Power BI Pro + Premium或Embedded
对于一些像金融行业的企业由于政策问题,数据无法上云,并且报表使用人数很多,就比较适合这种架构。Power BI Pro就是微软Power BI账号,有了它,就可以编辑和发布报表,并且与他人分享、协作。
价格非常亲民,一年费用换算人民币也就780块钱大洋吧。
但是有一个10GB的限制,所以如果考虑到使用报表人数超过50人以上的话,Premium或者Embedded是比较适合的选择。
Power BI Premium是云上的资源,按照容量计价,对于用户群体庞大的企业而已可实现成本优化及性能提升,同时支持嵌入式分析。

另外对于一些独立开发商或者想将Power BI Service上的报表集成到其他应用中,就可以考虑Power BI Pro+ Embedded这种架构了,比如像下图这种效果:

上北智信集成Power BI 的Portal
- 第三种架构 基于云 Power BI + Azure Data Services
这种架构最能解放IT管理员,管理起来是最方便快捷的,所以有能力上云的伙伴可以考虑下,但是奈何目前很多企业上云的道路崎岖~
对于数据比较敏感的客户,如果放到云上还是不放心的话,就可以考虑最后一种架构。
- 第四种架构 基于本地的,Power BI Report Server
微软的产品名称经常取名非常奇葩、相像,对于Power BI Service /Power BI Report Server、SQL Server Reporting Service以前一直傻傻分不清楚,现在终于搞明白了。
Power BI Service:是Power BI云上的服务Power BI Report Server:是可以Power BI的本地服务器版本,即可以发布Power BI报表,也可以发布SSRS格式化报表Power BI Report Server和SQL Server Reporting Service相当于iPhoneX和 iPhone5 的关系。而且有个毛病,Power BI Report Server相较于Power BI Service每月更新一次的频率,版本更新可以说是相当慢。也可以看出Azure才是微软产品未来的趋势。

- URL
[闭源] BI类:Tableau 【推荐】

- URL
BI类:Superset : 13.1k fork / 60.6k star | Since: 2015.6.28 【推荐】
- Superset | 开源BI
由 Airbnb 贡献的轻量级BI产品;
数据源方面,Superset支持CSV、MySQL、Oracle、Redshift、Drill、Hive、Impala、Elasticsearch等27种数据源,并深度支持Druid。

- 优点:
- 开源且免费:Superset 是 Apache 基金会的开源项目,使用完全免费。
- 大厂出品:Airbnb 、Apache;大厂支持:...
- 编程语言:Python
- 支持多种数据源:可以连接各种数据库,包括关系型数据库和非关系型数据库。
- 功能丰富:提供了强大的数据探索和可视化功能,支持复杂的数据分析。
- 扩展性强:可以通过插件进行功能扩展和定制。

- 缺点
- 安装配置复杂/部署难度高:对初学者来说,安装和配置可能较为复杂。
- 学习曲线陡峭:需要一定的技术背景才能完全掌握其功能和使用方法。
- 文档缺乏
- 性能问题:在处理超大规模数据集时,可能会遇到性能瓶颈。
- 不支持Join问题:具有一定的局限性,目前每次只支持可视化一张表,还不支持join多表的情况。
Superset 里的表不支持 join,如果一个图表里的数据要从多个数据表里取,那只能通过建视图来实现。
Superset 在 0.11 版本之后加入 SQL Lab 功能,支持从 SQL 查询结果直接生成图表。可惜,由于这个功能与 Superset 的核心设计格格不入,所以实现得比较粗糙,没什么实用价值。
- 技术架构落后
Superset 的后端用 Python 开发、主要框架:Flask App Builder(简称 FAB) - SQLAlchemy。
SQLAlchemy 是非常成熟的数据库 ORM 解决方案,没毛病;但问题出在了 FAB 上。
注意,不要把这个开源组件与 Flask 混为一谈,FAB 是构架在 Flask 之上的一个应用开发框架,可以根据数据库的表结构,自动生成增删查改的前端界面,功能上类似 Django Admin。
如果Superset 的目标是成为一个优秀的开源商业分析平台,FAB 注定会成为绊脚石。
FAB 虽然在初期可能可以为开发节省一些写前端代码的时间,但从中长期来说,它严重限制了 Superset 界面的灵活性。
有资深网友吐槽过 Superset 里 Dasbhoard 的管理不方便,权限系统复杂,其实就是受制于 FAB。
另外,FAB 本身已处于半死状态,从 Github 上的记录看,从 2016 后就没什么更新了。
在前端,Superset 借助 FAB 来生成大部分管理界面,而图表或是 SQL 编辑器等对交互性要求很高的界面,则由 React + Redux 来实现。
这种混合的模式让前端代码显得有些乱,说到底还是 FAB 留下的祸根。
Web 服务器是一个标准的 WSGI 应用,存储层支持用任意的 SQL 数据库(只需 SQLAlchemy 支持),所以部署方面无论是高可用还是水平扩展都很方便。
API 接口方面,FAB 原生支持 RESTful API,可以对大部分对象做 CRUD 操作。
但认证方式不够灵活,只能通过 cookie,这对于脚本或是服务器端调用不太友好,所以有资深网友对 Superset 做的第一个扩展就是添加了 API Token 的认证方式。

- 核心概念
- 指标(Metric)、分组条件(Group)、过滤条件(Filter):对于数据分析人员来说,由于在 Superset 上他们不是直接写 SQL,而是通过选择指标(Metric), 分组条件(Group)和过滤条件(Filter)来画图表,所以在构建复杂查询时可能会有些不适应。
- 社区活跃度


-
主要编程语言:TypeScript 31.7% / Python 26.4% / Jupyter Notebook 30.9%
-
URL
BI类:Metabase : 5k fork / 37.3k star | Since: 2015.2.1
- Metabase
Slogan : The simplest, fastest way to get business intelligence and analytics to everyone in your company(对于你的公司,让每个人都能以最简单,最快速的方式来获得商业智能和分析)

- 优势
- 开源免费
- 易于使用:从不懂技术的数据分析师的视角入手,用户界面友好,非技术用户也能轻松上手。
- 文档丰富:目前开源BI产品中,拥有最完整 API 文档的项目。这使得开发者即使完全不会 Clojure,依然可以凭借丰富的 API 与文档完成许多二次开发。
- 易于部署:安装和配置过程相对简单,支持多种部署方式。部署方面,Metabase 提供了 Jar 文件,Mac 应用程序,Docker 镜像等方式可以让使用者在本地快速尝试该项目。而在生产环境中,它提供了如何在 AWS、Heroku、Kubernetes 上部署的详尽文档,可谓体贴入微。
- 实时查询:支持实时数据查询和分析。
- 缺点
- 高级功能有限:对高级数据分析需求支持不足,功能相对简单。
- 可视化选项有限:虽然支持多种图表类型,但可视化选项相对有限。
- 性能问题:在处理大规模数据集时可能会遇到性能瓶颈。
- 功能
- 支持的数据源:Postgres、MySQL、Druid、SQL Server、Redshift、MongoDB、Google BigQuery、SQLite、H2、Oracle、Vertica、Presto、Snowflake、Spark SQL等 15 种数据源。
- 数据准备方式:支持 SQL 查询、简单查询和自定义查询。
- 支持的图表类型:曲线、柱状、条形、饼图、面积图、组合图、地图、漏斗、散点、仪表盘等
- 邮件报警:可以使用已有查询配置数据阈值报警,发送邮件。
- 仪表板功能:支持参数传递、一键全屏、公开分享、iframe 嵌入、定时刷新
- 用户集成:LDAP、OAuth2(需做一点开发)
- 权限:支持按数据源或者报表文件夹分配权限给用户组。
- 代码质量高:Metabase >> Superset > Redash

- 惊喜特色
- 元数据自动维护同步,对数据的浏览和透视非常方便
- 支持模型配置,用于问问题的时候直接选择配置好的指标和条件
- 支持参数传递,查询和仪表板均可注入参数作为报表筛选项
- 支持自定义地图,中国地图省份地图这些地图可视化都不在话下了
- 支持查询嵌套查询、也就是说查询可以复用了
- 支持代码块复用
- 仪表板支持 Markdown 组件,仪表板可以嵌入自定义的文本、链接、图片啦。
- 全局检索,支持全局检索报表数据仪表板等。
- 缺点
- 性能问题:Metabase在处理大量数据和复杂查询时可能性能不足。
- 数据处理能力有限:Metabase可能不支持复杂的数据转换和预处理,需要在数据库层面进行。
- 插件和扩展能力有限:Metabase的插件机制有限,难以满足高级用户的自定义需求。
- 数据安全性和权限管理:Metabase在数据安全性和权限管理上可能缺乏足够的保护措施。
Q:设置行级别的权限?
A:商业版本支持库、表、行、列权限
- 技术架构
- 后端:Clojure (基于JVM、函数式编程语言)
- 前端:React + Redux (单页应用)
React + Redux 是目前最流行的前端开发框架之一,Metabase 的系统切分与模块化做得非常出色,所以在前端架构方面 Metabase 可以给满分。
- 主要编程语言:Clojure 50.4% / TypeScript 30.9% / JavaScript 17.9% / ...
- Clojure: Clojure是一种运行在Java平台上的 Lisp 语言,Lisp是一种以表达性和功能强大著称的编程语言,但人们通常认为它不太适合应用于一般情况,而Clojure的出现彻底改变了这一现状。如今,在任何具备 Java 虚拟机的地方,您都可以利用 Lisp 的强大功能。
- Clojure 是个神奇的语言 - V2Ex
- URL
- 社区活跃度

BI类:DataEase : 3k fork / 16.3k star | Since: 2010.3.11 【推荐】
- DataEase |
理念:人人可用的开源数据可视化分析工具。(数据大屏开发神器!人人可用,Power BI、帆软、Tableau 等商业 BI 工具的开源替代)
DataEase 是开源的数据可视化分析工具( BI 工具 ),帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。DataEase 支持丰富的数据源连接,能够通过拖拉拽方式快速制作图表,并可以方便的与他人分享。
- 优点:
- 开源开放:零门槛,线上快速获取和安装,按月迭代;
- 中文支持友好:中国人发起、主导的BI框架
- 编程语言:Java作为主要编程语言;
- 简单易用:极易上手,通过鼠标点击和拖拽即可完成分析;
- 全场景支持:多平台安装和多样化嵌入支持;
- 安全分享:支持多种数据分享方式,确保数据安全。
- 支持多端展示: 支持 PC 端、移动端及大屏;
- 报表功能强大:支持丰富的报表类型和灵活的报表设计、,尤其是模板市场。
- 缺点:
- 功能相对单一:主要侧重于报表功能,数据分析和探索功能较弱。
- 社区和生态较小:相比其他开源工具,社区规模较小,扩展性可能不足。
- 功能架构

- 数据源连接:DataEase支持多种数据源连接,包括数据仓库/数据湖、OLAP数据库、OLTP数据库、Excel数据文件、API等,使得用户能够方便地从各种数据源中获取和分析数据。
- 图表制作与展示:DataEase支持通过拖拉拽的方式快速制作图表,并且这些图表可以在PC端、移动端以及大屏上进行展示。此外,基于Apache ECharts,它还支持多种图表类型(如Apache ECharts/AntV),以及通过拖拉拽的方式快速制作仪表板。
- 数据引擎:DataEase的数据引擎支持直连模式和本地模式,基于Apache Doris/Kettle实现。这种设计使得DataEase能够在处理大数据量时实现秒级查询返回延时。
- 嵌入式分析:DataEase在嵌入式方面做了扩展,支持图表、仪表板、数据大屏、设计器等丰富的嵌入场景。这一功能使得DataEase能够嵌入到商业应用程序中,为应用软件提供或增强分析功能,从而提高业务决策效率,释放业务数据的价值。
- 安全分享:DataEase支持多种数据分享方式,确保数据安全。
- 版本更新与用户反馈:作为一个开源项目,DataEase按月发布新版本,快速获取用户反馈,以持续改进产品。

DataEase嵌入式分析架构设计

- DataEase 支持的数据源:
- OLTP 数据库: MySQL、Oracle、SQL Server、PostgreSQL、MariaDB、Db2、TiDB、MongoDB-BI 等;
- OLAP 数据库: ClickHouse、Apache Doris、Apache Impala、StarRocks 等;
- 数据仓库/数据湖: Amazon RedShift 等;
- 数据文件: Excel、CSV 等;
- API 数据源。
-
主要编程语言:Java 82% / Vue 17.6%
-
社区活跃度
主要在在2022年以后开始快速活跃起来

- URL

BI类:SmartChart : 111 fork / 607 star | Since : 2020.11.29
- 简介:
Slogan : 数据可视化,大屏, 支持Echarts,SQL,API,VUE,可用于Jupyter, 比pyecharts容易, 极低门槛,拿来即用,比拖拽方便,项目插件或独立平台皆可, 简单, 敏捷, 高效, 通用化, 高度可定制化,为你完全打通前后端, 图形数据联动, 筛选开发毫无压力, 数据缓存处理机制让报表快人一步。
- 优势
- 开源免费
- 对中国支持友好:中国人发起、主导
- 技术架构
- 后端:Python
- 前端:Echarts + ...
-
社区活跃度

-
URL
- 主要编程语言:Python 28.1% / HTML 、CSS
BI类:Redash : 4.3k fork / 25.4k star | Since : 2013.10.20 【推荐】
- 简介
Redash 旨在使任何人,无论其技术水平如何,都能利用大小数据的力量。
SQL 用户利用 Redash 来探索、查询、可视化和分享任何数据源的数据。
他们的工作反过来使他们组织中的任何人都能使用这些数据。
每天,世界各地成千上万的组织的数百万用户使用 Redash 来开发洞察力并做出数据驱动的决策
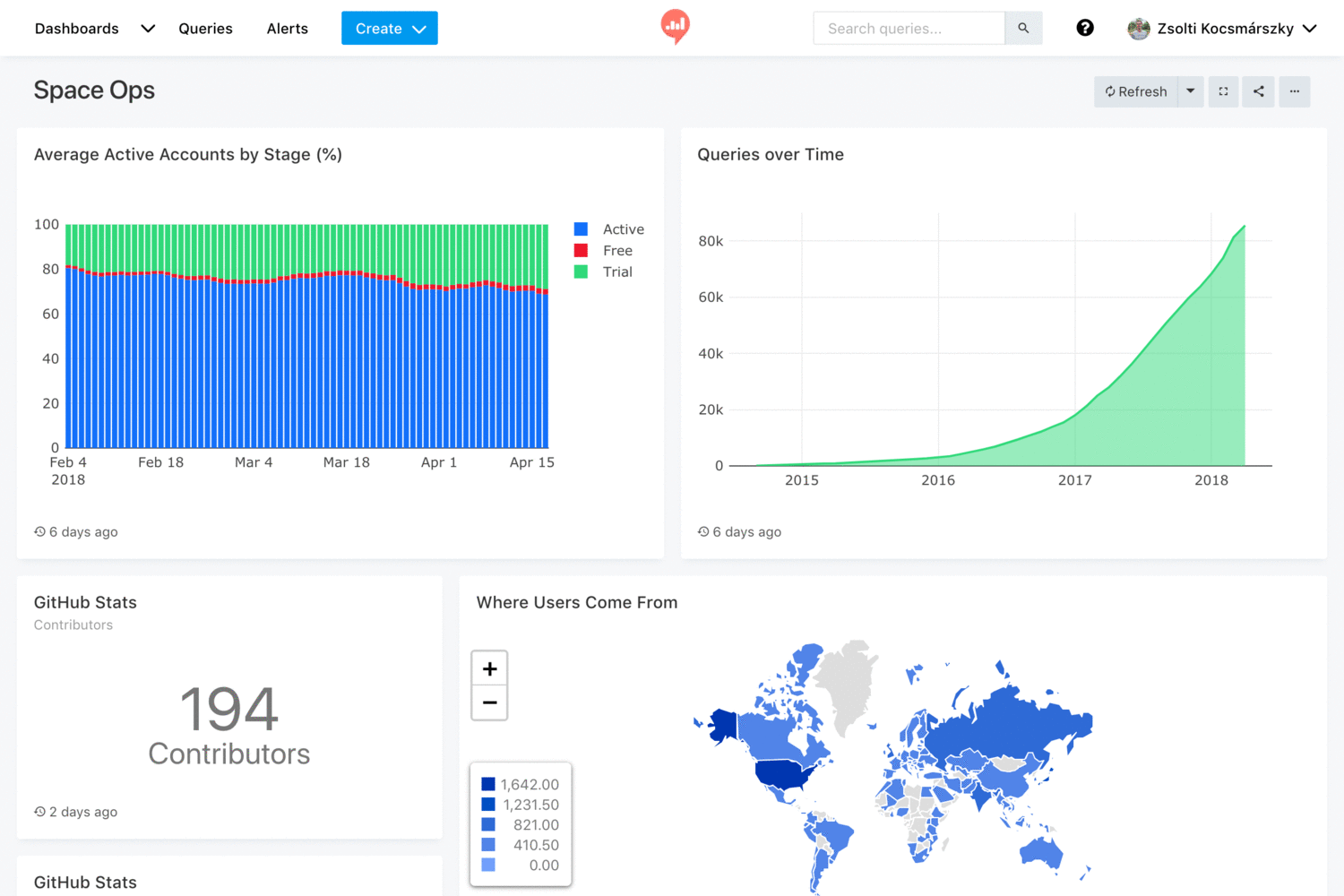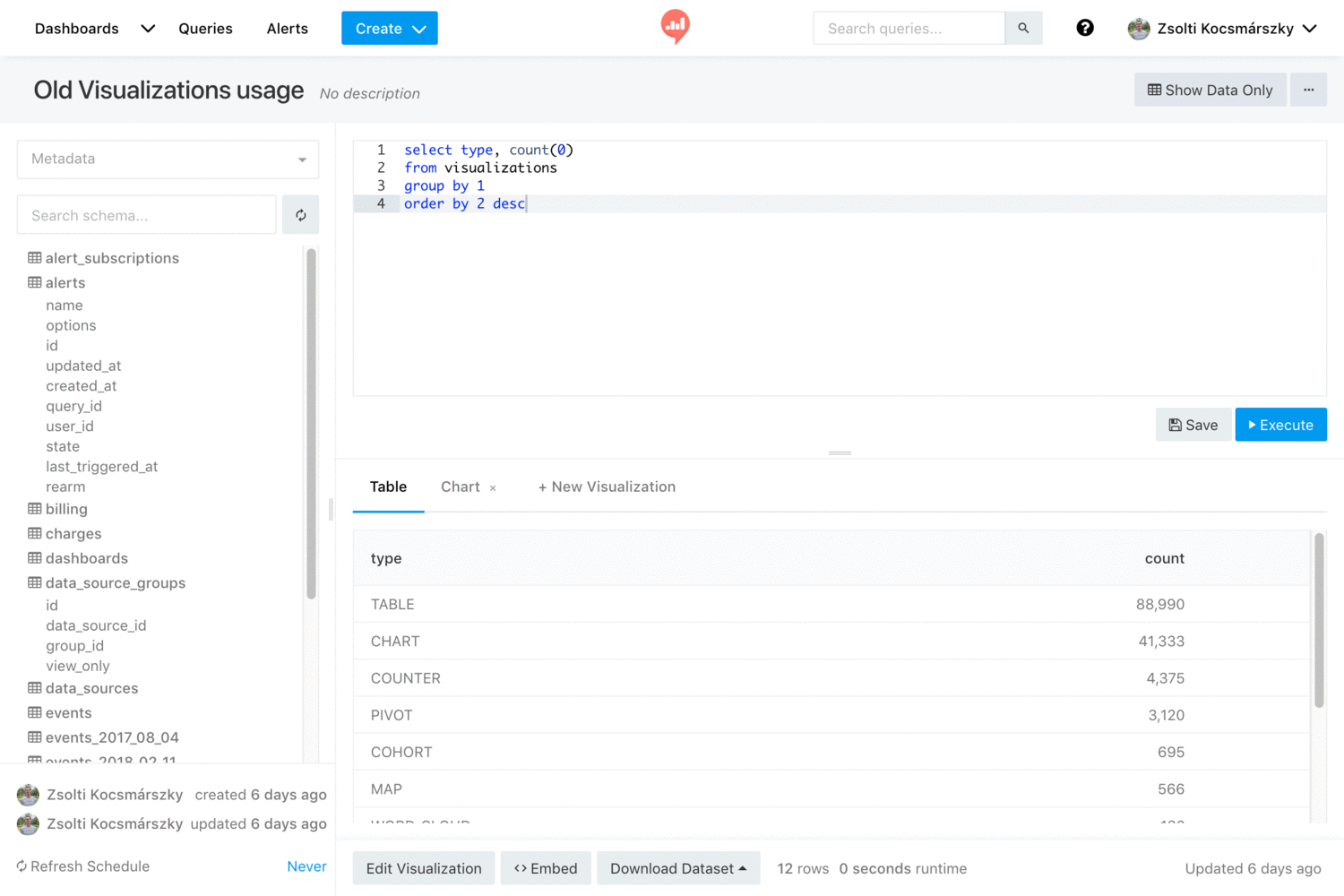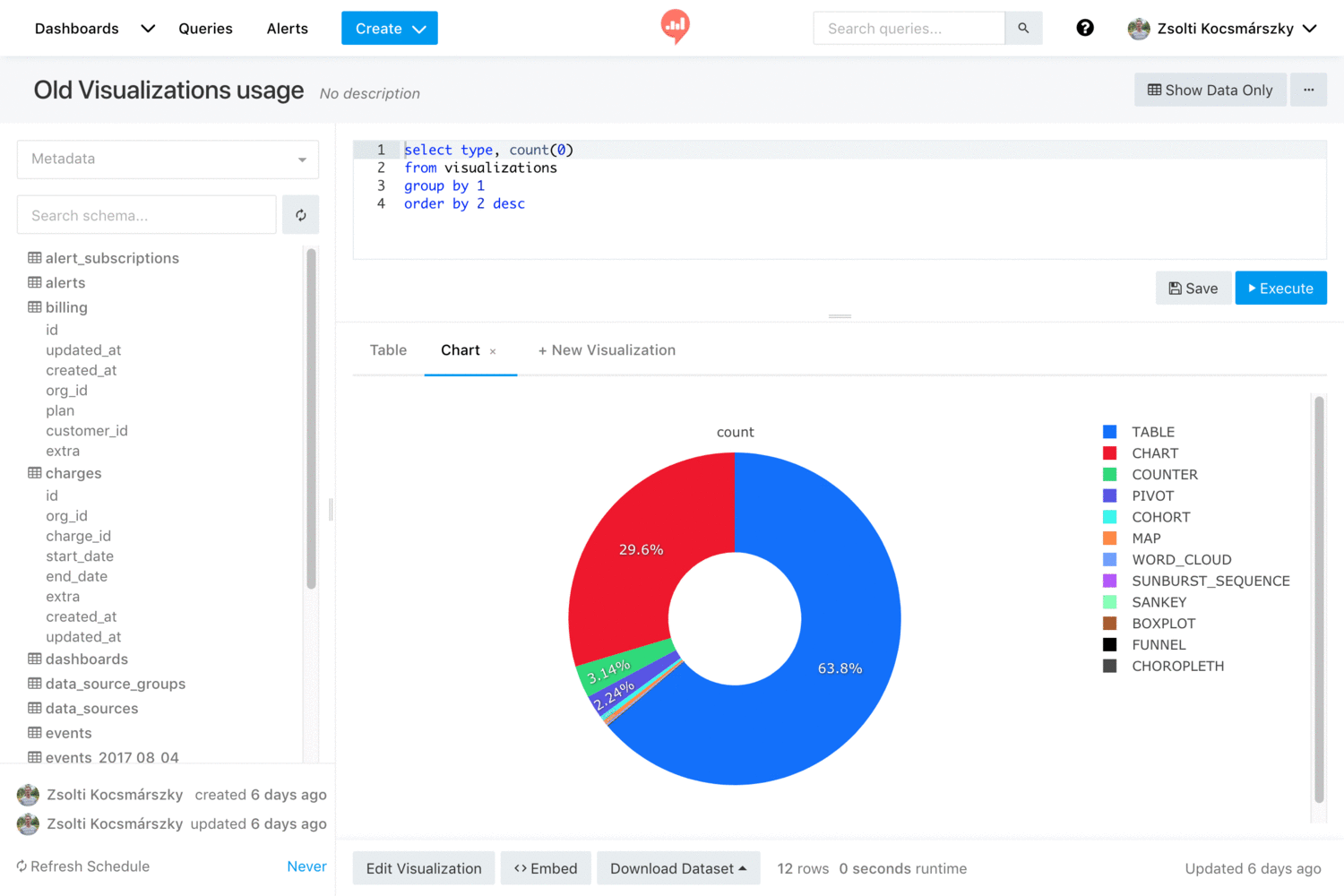
- 口号/Slogan
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data
以数据驱动你的公司。连接到任何数据源,轻松可视化,仪表板和共享您的数据。

- 缺点
- 用户界面相对简单:界面设计不够现代,用户体验可能不如商业产品。
- 性能问题:在处理大规模数据集时可能会遇到性能瓶颈。
- 功能有限:相比一些商业报表工具,功能和灵活性可能不足。
- 优点:
- 开源且免费:Redash 是一个开源工具,支持多种数据源,可以免费使用。
源代码:代码质量比Superset要好,但比Metabase差一些
- 支持多种数据源:包括 SQL 数据库、NoSQL 数据库和 API 数据源等。
- 查询编辑器强大:提供一个强大的 SQL 查询编辑器,可以帮助用户快速编写和运行查询。
- 可视化选项丰富:支持多种图表类型和可视化方式。
- 社区活跃:有一个活跃的开源社区,提供了丰富的插件和扩展。

- Query Snippet、Quer Paramerters
Redash有两个非常实用的功能,Query Snippet与Query Parameters。
Query Snippet很好地解决了查询片段的复用问题。做数据报表时经常要用到十分复杂的SQL语句,这些语句是肯定有一些片段是可以在多个Query中复用的。在Redash中我们可以将这些片段定义成Snippet,之后方便地复用。
Query Parameters可以为查询添加可定制参数,让这个图表变得更灵活。比如一个App的日活指标,我可能有时要按iOS/Android切分,有时要按地域切分,或是按新老用户切分。在Superset的Dashboard上我要做三个表图。Redash里我可以把Query的groupby做为一个参数,这样就可以在一张图上搞定。用的时候,运营人员可以图表上方的一个下拉框里选择切分的方式,非常直观好用。
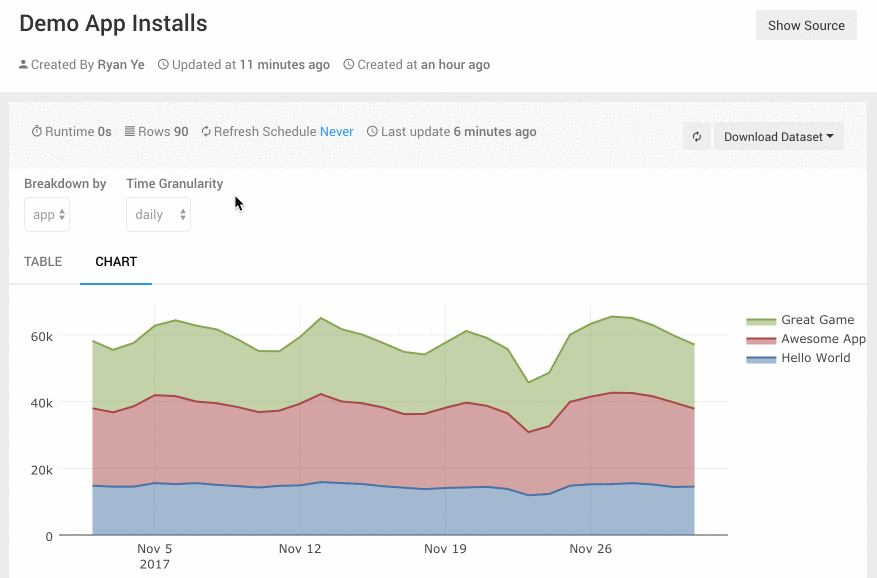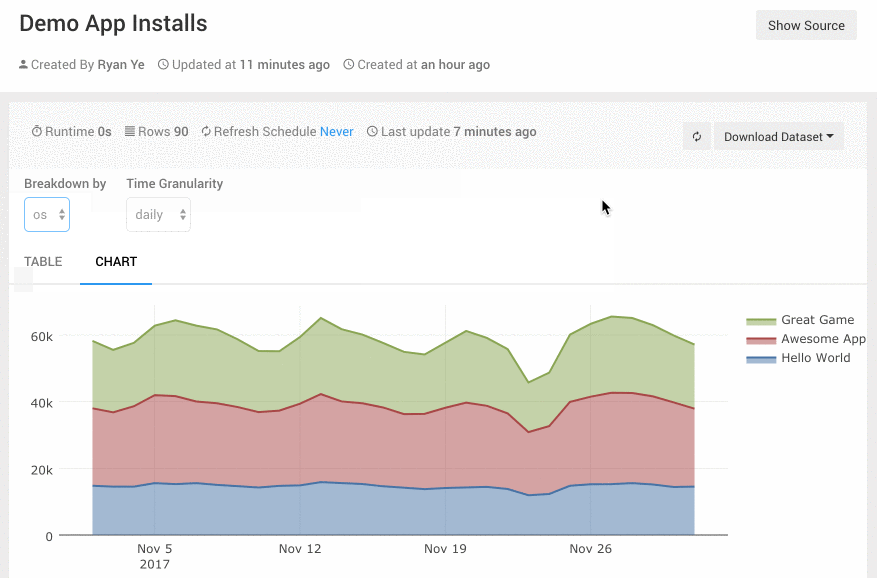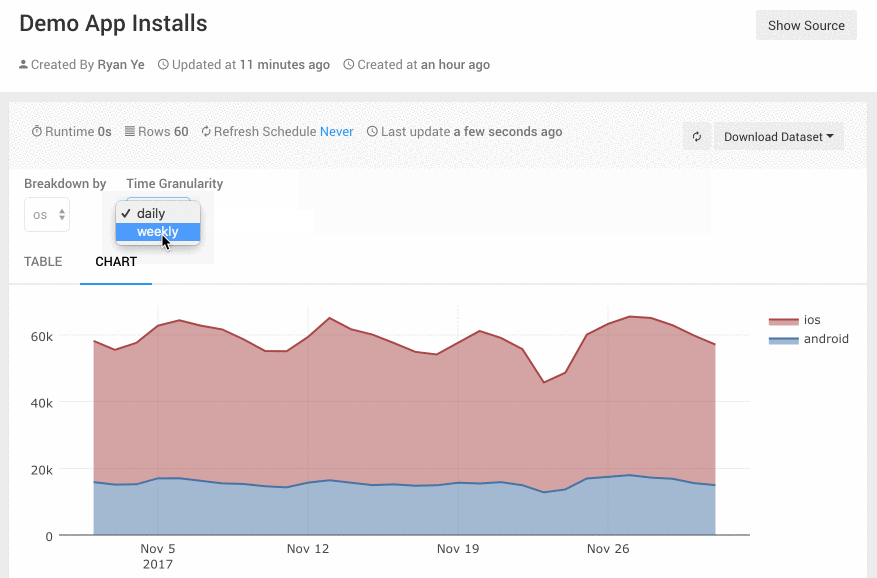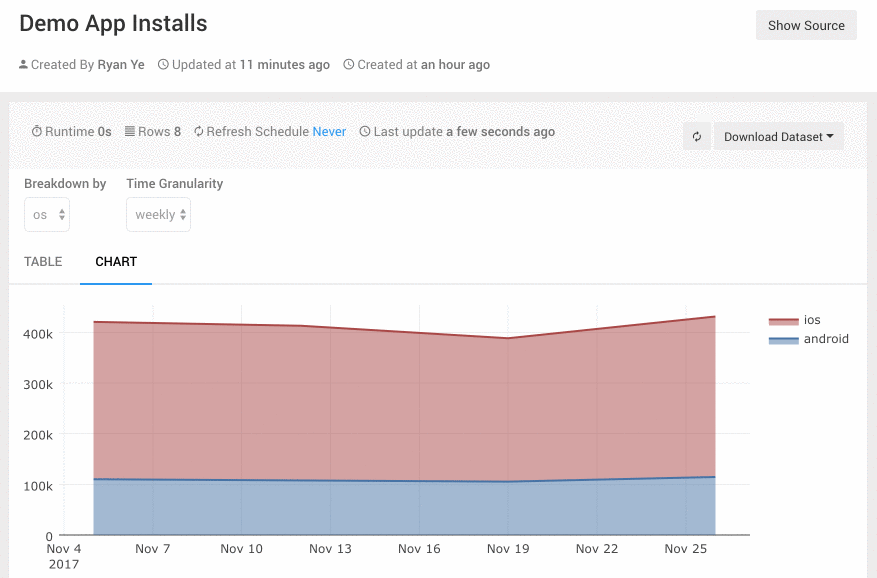
- 功能
- 基于浏览器的:浏览器中的所有内容,都带有可共享的 URL。
- 易用性:无需掌握复杂软件即可立即获得数据生产力。
- 查询编辑器:使用模式浏览器快速组成 SQL 和 NoSQL 查询并自动完成。
- 可视化和仪表板:通过拖放创建漂亮的可视化文件,并将它们组合成一个仪表板。
- 共享:通过共享可视化及其相关查询轻松进行协作,从而实现对报告和查询的同行审阅。
- 计划刷新:您定义的固定时间间隔自动更新图表和仪表盘。
- 警报:定义条件并在数据更改时立即收到警报。
- REST API:可以通过 REST API 使用 UI 进行的所有操作。
- 对数据源的广泛支持:可扩展的数据源 API,具有对一长串常见数据库和平台的本机支持。
Redash允许快速和方便地访问数十亿条记录,使用
Amzon Redshift处理和收集这些记录。
Redash支持查询多个数据库,包括:Redshift、Google BigQuery、PostgreSQL、MySQL、Graphite、Presto、Google电子表格、Cloudera Impala、Hive和自定义脚本。
-
架构

-
支持的数据源

-
内部组成/原理
Redash 由两部分组成:
- 查询编辑器:考虑JS Fiddle对SQL查询的影响。通过共享数据集和生成它的查询,以开放的方式在组织中共享数据的方式。这样,每个人都可以同行评审不仅是结果数据集,而且是生成它的过程。
- 可视化和仪表板:一旦您拥有一个数据集,您可以从中创建不同的可视化,然后将几个可视化组合到一个仪表板中。目前,ReaScript支持图表、枢轴表、同伙等等。
- Redash vs superset
如果说Superset是构建一个BI平台,那Redash目标就是更纯粹地做好数据查询结果的可视化。
Redash支持很多种数据源,除了最常用的SQL数据库,也支持MongoDB, Elasticsearch, Google Spreadsheet甚至是一个JSON文件。
Redash的官方文档里列出了它所支持的所有数据源。
它不需要像Superset那样在创建图表前先定义表和指标,而是可以非常直观地将一个SQL查询的结果可视化,这使得它上手很简易。
或者说Redash仅仅实现了Superset中SQL Lab的功能,但却把这个功能做到了极致。
- 社区活跃度

-
编程语言: Python 43.8% / JavaScript 31.5 % / TypeScript 16.8%
-
URL
BI类:Grafana : 11.8k fork / 61.6k star | Since: 2013.12.1 【推荐(IT监控观测系统)】
- Grafana
Slogan : The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.(开放、可组合的可观测性和数据可视化平台。从多个来源(如Prometheus、Loki、Elasticsearch、InfluxDB、Postgres等)可视化指标、日志和跟踪。)
Grafana 是一个开源的指标量监测和可视化工具,常用于展示基础设施的时序数据和应用 程序运行分析。
Grafana 主要用于对接时序数据库,分析展示监控数据。
- 优点:
- 界面友好:Grafana提供了直观和易于使用的用户界面,使用户能够轻松创建和定制各种仪表盘和图表。
- 多数据源支持:Grafana支持多种数据源,包括InfluxDB、Prometheus、Elasticsearch等,使用户能够从不同的数据源中获取数据,并将其可视化。
目前支持的数据源包括 InfluxDB、OpenTSDB、Elasticsearch、Graphite、Prometheus 等,
也支持 MySQL、MSSQL、PG 等关系数据库。
- 多种可视化选项:Grafana提供了丰富的可视化选项,包括折线图、柱状图、饼图等,用户可以根据自己的需求选择适合的图表类型。
- 插件生态系统:Grafana拥有丰富的插件生态系统,用户可以根据自己的需求安装和使用各种插件,扩展Grafana的功能。
- 跨平台支持:Grafana可以运行在多个操作系统上,包括Windows、Linux和MacOS,用户可以根据自己的需求选择适合的平台。
- 可视化/美观度:可视化效果好,简洁美观;
- 告警功能:4.0 版本及之后支持告警功能;
- 缺点:
- 学习曲线较陡:尽管Grafana具有友好的界面,但对于初学者来说,学习和掌握其各种功能可能需要一定的时间和精力。这意味着用户可能需要花费更多的学习成本来熟悉Grafana的功能和操作方式。
- 配置复杂:Grafana的配置相对复杂,需要一定的技术背景和经验来进行配置和定制。特别是在设置和管理数据源时,可能需要进行一些额外的配置和调整,这增加了使用的难度。
- 部署和维护成本较高:由于Grafana涉及到与其他数据源的集成和配置,所以在部署和维护Grafana时可能需要一些额外的成本和工作。这对于一些小型项目或个人用户来说,可能会构成一定的负担。
- 功能相对局限:尽管Grafana提供了丰富的可视化选项,但相比其他专业的商业数据可视化工具,其功能可能相对有限,特别是在高级分析和可视化方面。此外,某些高级功能仍需使用第三方插件或扩展来实现,这进一步限制了Grafana在某些特定场景下的应用能力。
- 告警功能仍存在局限性:4.0 版本及之后虽支持告警功能,但 某些高级告警功能仍需使用第三方插件或扩展来实现(如Promethus的Aler Manager);
- 核心概念
1)数据源(Datasource):定义了将用方式来查询数据展示在 grafana 上面,不同的 datasource 有不同的查询语法,grafana 支持多种数据源,官方支持数据源:Graphite, InfluxDB, OpenTSDB, Prometheus, ES 等等。每个数据源的查询语言和能力各不同,我们可将自多个数据 源的数据组合到一个仪表盘中,但每个面板都绑定到属于特定组织的特定数据源。
2)仪表盘(Dashboard):通过数据源定义好的可视化的数据来源后,可选择的实现数据
的可视化。
-
社区活跃度

-
编程语言:TypeScript 57.5% / Go 39% / ...
-
URL
- 生态解决方案:Loki (3.3k fork / 22.8k star | Since : 2018.3.15)
Loki是一个受Prometheus启发的水平可扩展、高可用性、多租户日志聚合系统。
它被设计为非常经济高效且易于操作。它不会索引日志的内容,而是索引每个日志流的一组标签。
基于 Loki 的日志堆栈由 3 个组件组成: 1)promtail是代理,负责收集日志并发送给Loki。 2)loki是主服务器,负责存储日志和处理查询。 3)Grafana用于查询和显示日志。

Loki Commit 活跃度
BI类:Kibana【推荐(ELK日志系统)】
- 简介
kibana是Elastic stack中web页面,可以在kibana中查看到数据。还有以下几个功能:
- 搜索、观察并保护数据:从发现文档到分析日志,再到查找安全漏洞,Kibana 是访问这些功能及其他功能的门户。
- 分析数据:搜索隐藏的信息,用图表、仪表、地图、图形等方式可视化发现的内容,并在仪表板上进行组合。
- 管理、监控和保障 Elastic Stack 的安全。管理数据,监控 Elastic Stack 集群的健康状况,并控制哪些用户有权访问哪些功能。
-
Kibana的分析流程

-
ELK日志系统
-
URL
基础组件类:ECharts : 19.6 fork / 59.7k star | Since : 2013.05.26 【推荐】
- ECharts | 基于 JavaScript 的开源可视化图表库
- 社区活跃度

基础组件类:D3.js : 22.9 fork / 108k star | Since: 2011 【推荐】
- 简介
D3.js(Data-Driven Documents)是一种用于创建动态、交互式数据可视化的JavaScript库。
它通过使用HTML、CSS和SVG等Web标准,将数据与文档结合,使得数据可以以一种直观和易于理解的方式进行呈现。
D3.js的重要性在于它赋予了开发者更大的自由度和灵活性,使得数据可视化可以根据需求进行定制和创新。
- 由来、目标、理念
D3.js由美国斯坦福大学的一位计算机科学家
Mike Bostock于2011年创造。
它的设计目标是帮助开发者使用数据来操作文档对象模型(DOM)并创建数据可视化。
D3.js的核心理念是将数据绑定到DOM元素上,并使用数据驱动的方式来更新元素的样式、位置和属性。

- 功能/特点
D3.js具有许多强大的功能和特点。
- 数据绑定机制:它提供了丰富的数据绑定机制,使得开发者可以轻松地将数据与DOM元素进行关联
- 允许开发者的DOM操作:D3.js允许开发者使用JavaScript来操作DOM,从而实现动态的数据可视化效果。
- 丰富的元素库:D3.js还提供了丰富的可视化元素库,如图表、地图和网络图,使得开发者可以快速创建各种类型的数据可视化。

- 数据可视化
D3.js在数据可视化方面有着广泛的应用。
通过D3.js,开发者可以创建各种类型的图表,如折线图、柱状图和饼图,以直观地呈现数据的分布和趋势。
此外,D3.js还支持地图可视化,可以将数据绘制在地图上,展示地理位置相关的信息。
另外,D3.js还可以用于创建网络图,用于展示复杂的关系和连接。

- D3.js和Echarts的对比
- 技术栈和语言:
ECharts:ECharts是由百度开发的基于JavaScript的可视化库,它使用了Canvas和SVG技术来绘制图表。
D3.js:D3.js是一个基于JavaScript的数据驱动文档库,它使用了HTML、CSS和SVG来创建交互式的数据可视化。
> + 功能和易用性:
ECharts:ECharts提供了丰富的图表类型和交互功能,包括折线图、柱状图、饼图、地图等。它具有简单易用的API和配置项,使得开发者可以快速创建和定制图表。
D3.js:D3.js是一个非常灵活和强大的库,它提供了丰富的数据操作和可视化功能。D3.js可以通过底层的API来创建自定义的图表和动画效果,但相对于ECharts,它的学习曲线较陡峭,需要更多的编码和理解。
> + 社区支持和生态系统:
ECharts:ECharts有一个活跃的社区和广泛的用户群体,它提供了详细的文档和示例,使得开发者可以轻松上手并解决问题。此外,ECharts还提供了在线编辑器和可视化设计工具,方便用户进行图表的定制和调试。
D3.js:D3.js也有一个庞大的社区和丰富的资源,但相对于ECharts,它的学习和使用门槛较高。D3.js的社区提供了大量的示例和教程,但在解决问题时可能需要更多的自行研究和编码。
> + 性能和扩展性:
ECharts:ECharts在性能方面表现良好,它通过优化算法和渲染引擎来提高图表的渲染速度和交互性能。此外,ECharts还提供了插件机制和扩展接口,使得开发者可以定制和扩展功能。
D3.js:D3.js具有很高的灵活性和可扩展性,可以满足各种复杂的可视化需求。但由于其底层的API和自定义性较高,需要开发者自行优化和处理性能问题。
>> 综上所述:
>> `ECharts`适合快速创建和定制常见的图表,对于**非专业的开发者**来说更易上手。
>> 而`D3.js`则适合需要更高度自定义和复杂交互的可视化需求,对于**有较强编程能力的开发者**来说更为适用。选择使用哪个库取决于具体的项目需求和开发者的技术水平。
+ 社区活跃度
+ 代码示例
> + 创建一个SVG元素并绘制一个矩形
``` javascript
var svg = d3.select("body")
.append("svg")
.attr("width", 200)
.attr("height", 200);
svg.append("rect")
.attr("x", 50)
.attr("y", 50)
.attr("width", 100)
.attr("height", 100)
.style("fill", "blue");
- 使用D3.js绑定数据并创建一个柱状图
var data = [10, 20, 30, 40, 50];
var svg = d3.select("body")
.append("svg")
.attr("width", 200)
.attr("height", 200);
svg.selectAll("rect")
.data(data)
.enter()
.append("rect")
.attr("x", function(d, i) { return i * 30; })
.attr("y", function(d) { return 200 - d; })
.attr("width", 20)
.attr("height", function(d) { return d; })
.style("fill", "blue");
- URL
基础组件类:Three.js : 35.2 fork / 101k star | Since : 2010.5.21
- 简介
Three.js 是基于 WebGL(Web Graphics Library) 的 JavaScript 的开源框架。简言之,就是能够实现 3D 效果的 JS库。
Slogan : JavaScript 3D Library.
WebGL: 一种 JavaScript 的 3D 图形接口,把 JavaScript 的 OpenGL ES 2.0 结合在一起。OpenGL: 开放式图形标准,跨编程语言、跨平台,JavaScript、Java、C、C++、Python等都能支持 OpenGL,Open GL的JavaScript实现就是 Web GL。另外,很多 CAD制图软件也都采用这种标准。OpenGL ES 2.0是 Open GL 的子集,针对 手机、游戏主机等嵌入式设备而设计。Canvas: HTML的画布元素。在使用 Canvas 时,需要用到 Canvs 的上下文,可以用在 2D上下文数据绘制二维图形,也可以使用3D上下文数据绘制三维图像,其中3D上下文数据就是指WebGL。

- 应用场景
- 【3D 动画】:利用 Three.js 可以制作很多炫酷的 3D 动画,并且 Three.js 还可以通过鼠标、键盘、拖拽等事件形成交互,在页面上增加一些3D动画交互,可以产生更好的用户体验。
- 【3D 全景视图(VR)】:通过 Three.js 可以制作 全景视图,这些全景视图应用在房产、家装行业能够带来更直观的视觉体验。在电商行业,利用 Three.js 可以实现产品的 3D 效果。这样用户就可以 360度全方位地观察商品了,给用户带来更好的购物体验。
- 【3D 小游戏】 :另外,使用 Three.js 还可以制作类似微信跳一跳那样的小游戏。
... 随着技术的发展、基础网络的建设,Web 3D 技术还能得到更广泛的应用。

- 主要组件:
在 Three.js 中,有了场景(Scene)、相机(Camera)和渲染器(Randerer),这3个组件才能将物体渲染到网页中去。
- 场景:场景是一个容器,可以看作摄影的房间,在房间中可以布置背景、摆放拍摄的物品、添加灯光设备等。
- 相机:相机是用来拍摄的工具,通过控制相机的位置和方向可以获取不同角度的图像。
- 渲染器:渲染器利用场景和相机进行渲染,渲染过程好奇摄影师拍摄图像。如果只渲染一次就是静态的图像;如果连续渲染就能得到动态的画面。在JS中可以使用 Request AnimationFrame 实现高效的连续渲染。
- 常用相机:透视相机、正交相机

- 示例代码
/** 场景 **/
var scene = new THREE.Scene();
scene.add(new THREE.AxesHelper(10) ); //添加坐标轴辅助线
/** 几何体 **/
//这是自定义的创建几何体方法,如果创建几何体后续会介绍
var kleinGeom = createKleinGeom();
scene.add(kleinGeom);//场景中添加几何体
/** 相机 **/
var camera = new THREE.PerspectiveCamera(45, width/height, 1, 100);
camera.position.set(5, 10, 25); // 设置相机的位置
camera.lookAt(new THREE.Vector3(0, 0, 0)); //相机看向原点
/** 渲染器 **/
var renderer = new THREE.WebGLRenderer( {antialias:true} );
renderer.setSize(width , height);
//将 canvas 元素添加到 body
document.body.appendChild( renderer.domElement );
//进行渲染
renderer.render( scene, camera);
- URL
- 社区活跃度

基础组件:ArcGIS API for JavaScript
- 简介
- Slogan: 通过交互式地图,将人员、位置和数据连接起来。 使用智能数据驱动样式和直观分析工具。 与全世界或特定群组分享您的见解。
- 是一个WebGIS二次开发(如果不知道什么是WebGIS请用搜索引擎···)的前端开发包,使用JavaScript语言
- 出自美国Esri公司、是Esri的ArcGIS Runtime SDK家族中的一员
- 它不是纯Js写的库
- 它能制作在线地理信息系统平台,能做数据分析、空间分析、数据展示等;
- 英文资料多,虽然中文也有一定数量的资料(博客、书籍等),但是呢,由于Esri更新贼快,一年三四更的,中文资料不一定跟得上速度;
- 你可能需要学很多附属的东西,这个API很庞大、很笨重,入门门槛其实不高,但是深入难,前端上,你得知道造这个API的基础——Dojo框架,而Dojo框架由于历史渊源,又来自从属AMD(异步模块定义)规范的RequireJs,要想了解AMD,又不得不去看一些前端和后端的发展史,甚至不可避免要学一些基础的后端。
- 这个API当前有两个大支线,一个是3.x版本,一个是4.x版本。3.x版本已经很成熟,用于2D的WebGIS二次开发很完美,如果你用的是ArcGIS整套产品;较为简单的4.x版本,因为它最大的特征是数据视图分离、支持3D,旗帜鲜明对接ArcGIS Pro。
1 如果你的项目需求很大,大量用到空间分析、三维展示,频繁交互ArcGIS家族的产品(Server、ArcGIS Desktop等),请学`ArcGIS`;
2 如果你的项目需求比较小,也可以学,当然也可以有别的选择:
开源解决方案:Openlayers/Leaflets替代JsAPI。
3.1 Openlayers和Leaflets同样是WebGIS二次开发工具包,排名很靠前,二者区别是ol自己提供了封装好的功能模块,而lf则支持插件式,它的插件很多。他们都支持npm方式引入。
当然,为了实现简单的三维GIS,Cesium了解一下;
3.2 如果只是3D数据展示,ThreeJs了解一下;
3.3 如果数据源缺乏,不想自己做数据服务,对WebGIS标准缺少耐心,可以试试高德地图API、百度地图API等。
3.4 如果想全开源,就目前而言3DGIS,还是ArcGIS最强外,传统二维WebGIS可以用QGIS代替ArcGIS Desktop、用PostgreSQL代替Geodatabase、用GeoServer代替ArcGIS for Server。
4 小结:使用JsAPI最强大的特征就是真三维空间分析+无比强大的ArcTools工具箱了。
- URL
- https://www.arcgis.com/index.html
- https://developers.arcgis.com/javascript/latest/sample-code/sandbox/?sample=intro-mapview
- https://www.arcgis.com/apps/mapviewer/index.html
- 第三方文档
2.10 调度系统 & 工作流系统
Apache Dolphi Scheduler 【推荐】
- Apache Dolphi Scheduler
一个分布式和可扩展的开源工作流协调平台,具有强大的DAG可视化界面

XXL-JOB 【推荐】
- XXL-Job
X 参考文献
- 数据治理操作指南 - Weixin/BAT大数据架构
- 【开源项目推荐】OpenMetadata——基于开放元数据的一体化数据治理平台 - Weixin/大数据流动
- 有哪些开源的BI工具? - Zhihu/Terry陈
- 开源免费的数据质量管理工具 Data Quality - Zhihu 【TODO】
- 数据字典管理系统-后台管理界面-UI设计 - 站酷
- 聊聊大数据质量监控的那些事 - CSDN
- 一文读懂:D3.js的前世今生,以及与echarts的对比 - CSDN
- MetaBase VS. DataEase:架构、功能和效果对比 - Zhihu 【推荐】
- Redash、Superset、DataEase、Metabase、FineBI 和 Power BI 报表系统的优缺点 - CSDN 【推荐】
- 数据可视化的开源 BI 工具: Superset vs DataEase vs Metabase - Zhihu
- Redash和Metabase深度比较之一:概述 - Zhihu
- 数据可视化的开源方案: Superset vs Redash vs Metabase (二) - 腾讯云

本文链接: https://www.cnblogs.com/johnnyzen/p/18029696/data-governance-tools
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 【全网最全教程】使用最强DeepSeekR1+联网的火山引擎,没有生成长度限制,DeepSeek本体
2023-02-23 [知识管理] 服务器
2023-02-23 [知识管理] 家庭数据中心