[工具/软件] 开源通用网络爬虫框架
0 概述

通用万能爬虫 vs 聚焦领域爬虫

1 Java Spider
spider-flow
- Home URL : https://www.spiderflow.org/
20250311 : 1.9k fork / 9.8k star
20230306 : 7.7k starspider-flow 是一个爬虫平台,以图形化方式定义爬虫流程,无需代码即可实现一个爬虫

- 项目说明
活跃度低下,最近一次发版在 2020 年,相距已过去5年。
Webmagic 【推荐】
- URL
- http://webmagic.io/docs/en/ | http://webmagic.io/docs/zh/
- https://github.com/code4craft/webmagic
- http://git.oschina.net/flashsword20/webmagic
Github URL : 10.7K
20230306 : 10.7k star
20250311 : 4.2k fork / 11.5 star

- Intro
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
特性:
简单的API,可快速上手
模块化的结构,可轻松扩展
提供多线程和分布式支持
- 整体架构
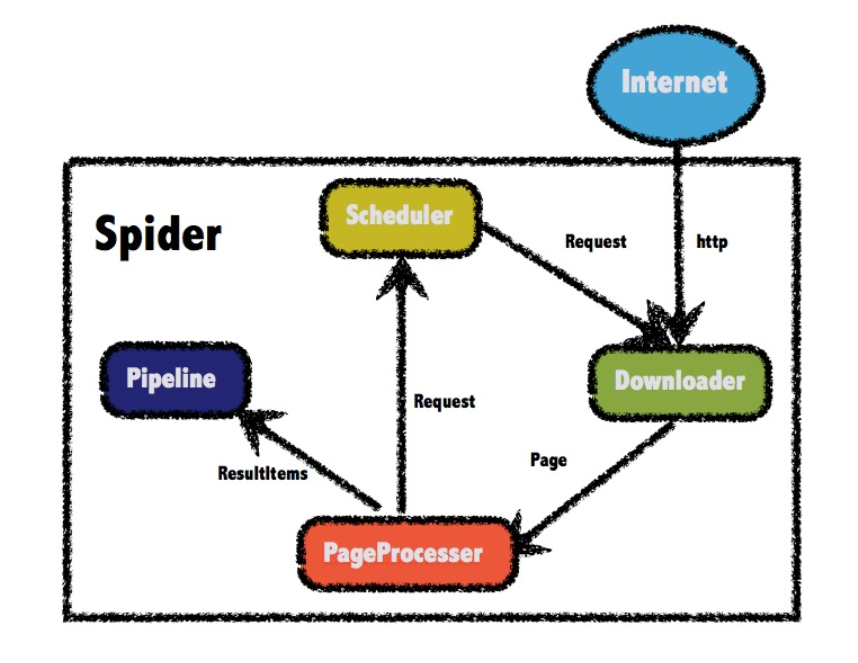
Heritrix 3
- Home URL : heritrix.readthedocs.io/
Heritrix 是一个开源,可扩展的 web 爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix 设计成严格按照 robots.txt 文件的排除指示和 META robots 标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
- Github Star : 2.4K
Selenium WebDriver 【推荐】
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.0.1</version>
</dependency>
- docs & demo
爬虫辅助开发类库
- jsoup 【推荐】
HTML解析工具
https://jsoup.org/
- httpclient : http请求框架 【推荐】
- okhttp : http请求框架 【推荐】
2 Python Spider
Scrapy 【推荐】
- Language : Python
- GitHub Star : 46.4K
20230306: 46.4k star
20250311 : 10.7k fork / 54.5k star
- URL :
https://scrapy.org/community/
https://github.com/scrapy/scrapy
【简介】
Scrapy 是一种高速的高层 Web 爬取和 Web 采集框架,可用于爬取网站页面,并从页面中抽取结构化数据。
Scrapy 的用途广泛,适用于从数据挖掘、监控到自动化测试。
Scrapy 设计上考虑了从网站抽取特定的信息,它支持使用 CSS 选择器和 XPath 表达式,使开发人员可以聚焦于实现数据抽取。
对于熟悉 Python 的开发人员,只需几分钟就能建立并运行 Scrapy。
支持运行在 Linux、Mac OS 和 Windows 系统上。
【特性】
内置支持从 HTML 和 XML 抽取数据、使用扩展的 CSS 选择器(Selector)和 XPath 表达式等特性。
支持以多种格式(JSON、CSV、XML)生成输出。
基于 Twisted 构建。
稳健的支持,自动检测编码方式。
快速,功能强大。
PySpider 【已停止维护】
- URL
- Home URL : https://docs.pyspider.org/en/latest/
- Github : https://github.com/binux/pyspider
20250311 : 3.7k fork / 16.5 star
PySpider 是一种 Python 编写的强大 Web 爬虫。
它支持 JavaScript 网页,并具有分布式架构。
PySpider 支持将爬取数据存储在用户选定的后台数据库,包括 MySQL, MongoDB, Redis, SQLite, Elasticsearch 等。
支持开发人员使用 RabbitMQ、Beanstalk 和 Redis 等作为消息队列。
提供强大 Web 界面,具有脚本编辑器、任务监控、项目管理器和结果查看器。
支持对重度 Ajax 网站的爬取。
易于实现适用、快速的爬取。
EasySpider 【个人项目/偏丑/基于Selenium】

- URL
- Github Star
- 20250311 : 4.7k fork / 37.9 star
- 20240702 : 3.3K fork / 28.4K star
-
Program Langua: JavaScript + Python
-
Document
- 中国国家知识产权局发明专利,一种自定义提取流程的服务封装系统, 2022年5月。
- 浙江大学硕士论文,面向WEB应用的智能化服务封装系统设计与实现,2020年6月。
- Intro
- EasySpider是一款集成了自动化测试、爬虫和数据采集功能的可视化工具。
- 它基于图形化界面,用户无需编写复杂的代码,通过简单的拖拽和配置即可实现数据的抓取和处理。
- 无论是进行网站自动化测试,还是对特定数据进行采集和分析,EasySpider都能够轻松应对。
- 同时,它还可以单独以命令行的方式进行执行,从而可以很方便的嵌入到其他系统中
- Demo Blog
Beautifulsoup 【推荐】
- URL
Beautiful Soup 一种设计用于实现 Web 爬取等快速数据获取项目的 Python 软件库。
它在设计上处于 HTML 或 XML 解析器之上,提供用于迭代、搜索和修改解析树等功能的 Python 操作原语。往往能为开发人员节省数小时乃至数天的工作。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,并将输出文档转换为 UTF-8 编码。
Beautiful Soup 处于一些广为采用的 Python 解析器(例如,lxml 和 html5lib)之上,支持用户尝试使用多种不同的解析策略,并在速度和灵活性上做出权衡。
Selenium WebDriver 【推荐】
- 参见本文: Java - Selenium WebDriver
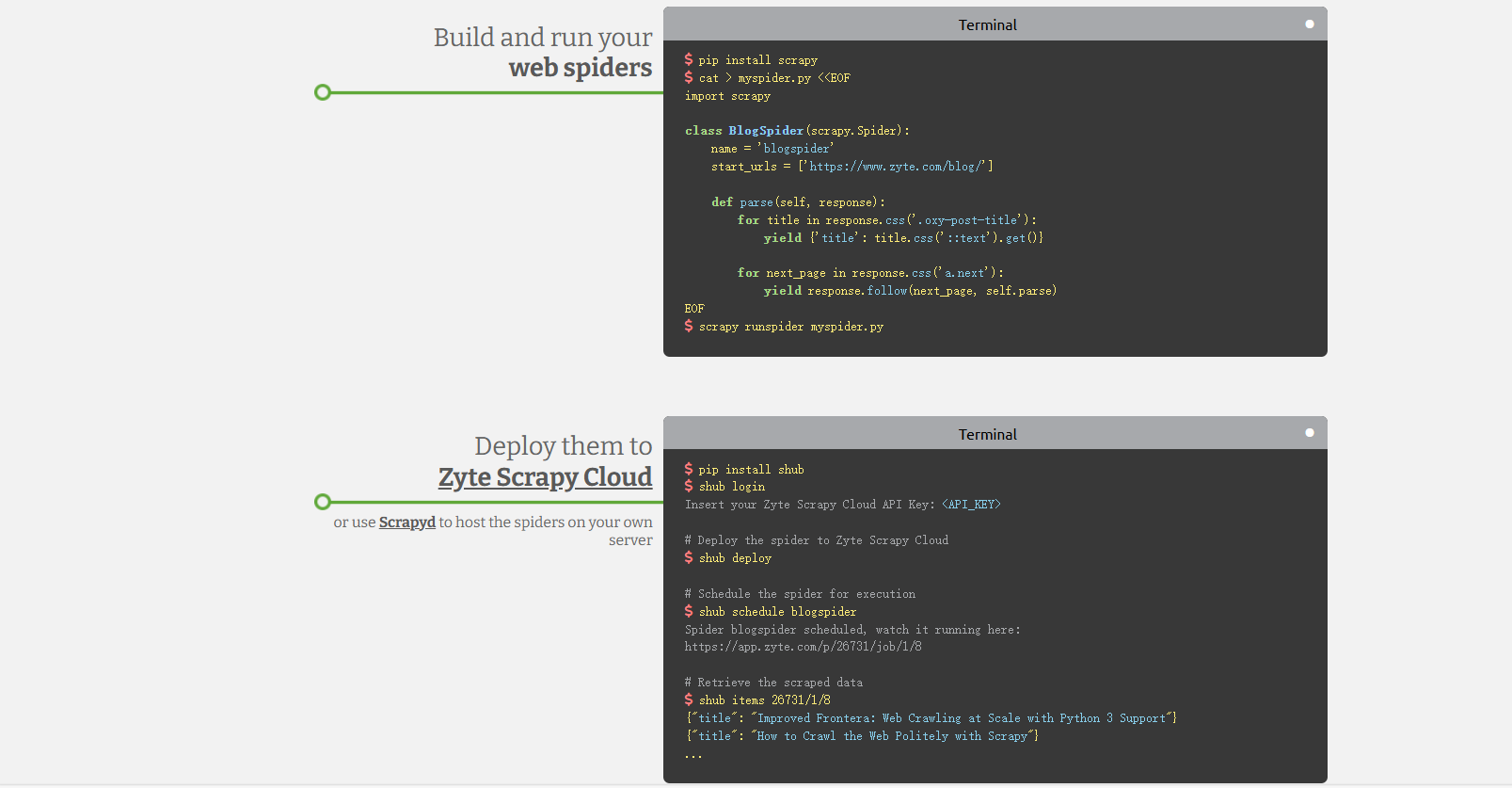
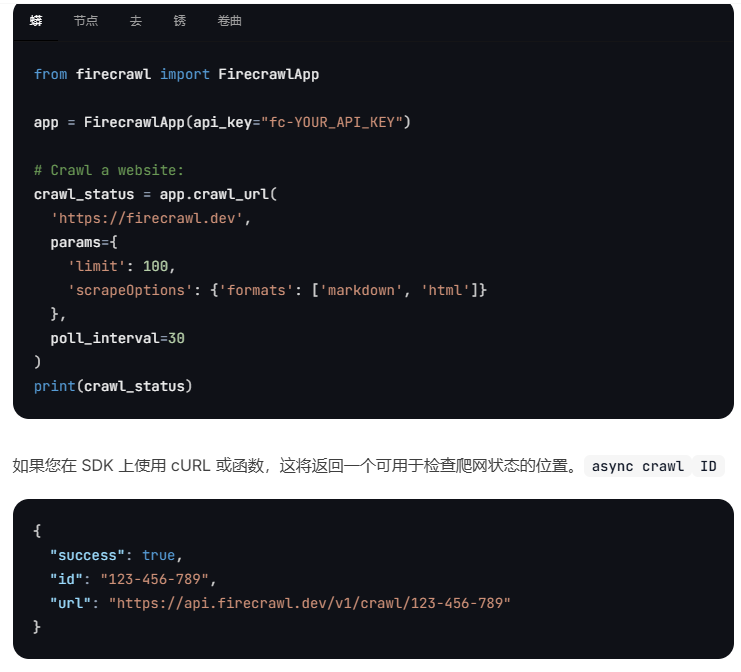
FireCrawl : TypeScript / Python 【推荐】
- FireCrawl是一款创新的爬虫工具,它能够无需站点地图,抓取任何网站的所有可访问子页面。
与传统爬虫工具相比,FireCrawl特别擅长处理使用
JavaScript动态生成内容的网站,并且可以转换为LLM-ready的数据。

- Firecrawl 是一种 API 服务,它获取 URL,抓取它,并将其转换为干净的 markdown。
我们抓取所有可访问的子页面,并为每个子页面提供干净的 markdown。无需站点地图。
- URL
20250311 : 2.6k fork / 30.2k star
- 主要功能
- LLM 就绪格式:markdown、结构化数据、屏幕截图、HTML、链接、元数据
- 难点:代理、反机器人机制、动态内容(js-rendered)、输出解析、编排
- 可定制性:排除标签、使用自定义标头在身份验证墙后面爬行、最大爬行深度等......
- 媒体解析:pdf、docx、图像
- 可靠性第一:旨在获取您需要的数据 - 无论多么困难
- 桌面操作:在提取数据之前单击、滚动、输入、等待等
- 批处理(新):使用新的异步端点同时抓取数千个 URL。
- 如何使用?

Jina Reader : HTML URL 转 markdown 【闭源/商用/不推荐】
- URL

- Jina API

Jina Python库
pip install Jina
-
Jina Python库是一款开源的神经搜索库,它利用深度学习技术为各种数据类型提供高效的搜索解决方案。它特别适用于处理非结构化数据,如文本、图片、音频和视频等。
-
Jina的核心概念包括Flow、Executor和Document等。
其中,Flow是Jina的核心组件,负责管理工作流程的各个阶段;
Executor是一个可插拔的神经网络处理单元,它执行特定的预处理、处理或后处理任务;
Document则是Jina处理的基本单元,代表了各种数据形式。
-
Jina的设计目标是简化跨多语言、多框架的深度学习应用开发,通过独立的执行单元和灵活的流式架构,让开发者可以轻松地构建和部署大规模的神经搜索应用。
-
Jina Reader 的主要功能
- 网页内容提取:将 HTML 网页转换为纯文本格式,去除不必要的标签和脚本。
- 格式选择:支持将网页内容输出为 Markdown、HTML、Text、Screenshot、Pageshot 等多种格式。
- 流模式:适用于大型和动态网页,支持更长时间的页面渲染,确保内容的完整性。
- JSON模式:输出包含 URL、标题和内容的结构化 JSON 数据,便于后续处理。
- Alt生成模式:为缺少 alt 标签的图片自动生成描述,帮助 LLMs 更好地理解网页中的图像内容。
- 目标选择器和等待选择器:用 CSS 选择器指定页面中特定部分的内容提取,或等待特定元素出现后再提取内容。
- Jina Reader 的技术原理
- 网页抓取与解析:使用网络爬虫技术抓取网页内容,基于 HTML 解析器解析网页的 DOM 树结构,提取出网页的文本内容。
- 内容清洗与结构化:清洗 HTML 标签、JavaScript 代码和 CSS 样式,只保留纯文本内容,并识别和提取网页中的标题、段落、链接、图片等结构化元素。
- 自然语言处理(NLP):对提取的文本进行自然语言处理,提高文本的质量,例如去除停用词、词干提取等,并生成图像的替代文本(alt text)。
- 动态内容处理:对于单页应用程序(SPA)和动态加载的内容,使用如 Puppeteer 这样的无头浏览器模拟用户交互,等待 JavaScript 执行完成,捕获最终的页面内容。
- 流式处理与实时解析:支持流式解析网页内容,对于大型和动态网页尤为重要,能实时处理网页内容。
Reader-LM
-
Jina Reader-LM是Jina AI发布的两个小型语言模型:Reader-LM-0.5B和Reader-LM-1.5B。 -
这些模型经过专门训练,可以将原始 HTML 转换为标记符,并且都是多语言模型,支持多达 256K 字节的上下文长度。
Reader-LM 系列旨在高效地应对将开放网络中原始、嘈杂的 HTML 转换为干净的标记符格式的挑战,重点关注成本效益和性能。
这些模型在 HTML 到标记符的转换这一特定任务中的表现优于许多大型模型,而体积却只有它们的几分之一。
Reader-LM 专为个人和企业环境的实际应用而设计,使用 Google Colab 可以轻松测试模型,而生产环境则可以利用 Azure 和 AWS 等平台。
这些模型非常适合在生产环境中自动从开放网络中提取和清理数据,通过将原始 HTML 转换为简洁的标记符,Reader-LM 实现了高效的数据处理,使下游 LLM 更容易从网络内容中总结、推理和生成见解。
项目案例集
CASE1:requests/scrapy(一般网络请求) + selenium(动态渲染网页) + beautifulsoup4(网页内容解析)

- 参考文献
- 爬虫常用库
requests、selenium、puppeteer,beautifulsoup4、pyquery、pymysql、pymongo、redis、lxml和scrapy框架
其中发起请求课可以使用requests和scrapy
解析内容可以用 beautifulsoup4,lxml,pyquery
存储内容可以使用 mysql(清洗后的数据) redis(代理池) mongodb(未清洗的数据)
抓取动态渲染的内容可以使用:selenium,puppeteer
- 增量爬虫
一个网站,本来一共有10页,过段时间之后变成了100页。假设,已经爬取了前10页,为了增量爬取,我们现在只想爬取第11-100页。
因此,为了增量爬取,我们需要将前10页请求的指纹保存下来。以下命令是将内存中的set里指纹保存到本地硬盘的一种方式。
scrapy crawl somespider -s JOBDIR=crawls/somespider-1
但还有更常用的,是将scrapy中的指纹存在一个redis数据库中,这个操作已经有造好轮子了,即scrapy-redis库。
scrapy-redis库将指纹保存在了redis数据库中,是可以持久保存的。
(基于此,还可以实现分布式爬虫,那是另外一个用途了)scrapy-redis库不仅存储了已请求的指纹,还存储了带爬取的请求,这样无论这个爬虫如何重启,每次scrapy从redis中读取要爬取的队列,将爬取后的指纹存在redis中。
如果要爬取的页面的指纹在redis中就忽略,不在就爬取。
FAQ
Q: Jina Reader 与 Fire Crawl 的区别?
Jina Reader 和 FireCrawl 都是用于网页抓取和解析的工具,但它们在功能、使用场景和特性上存在一些区别,以下是它们的主要对比:
| 特性 | Jina Reader | FireCrawl |
|---|---|---|
| 开发背景与目的 | 由 Jina AI 开发,专注于将网页内容转换为适合 LLM 处理的格式。 | 由 Mendable 开发,旨在提供一个强大的网页抓取工具,支持复杂任务和多种数据处理。 |
| 主要功能 | - 提取网页的纯文本或 Markdown 格式内容。 - 支持动态网页处理和流式解析。 |
- 支持整个网站的抓取,返回 Markdown、HTML、屏幕截图等多种格式。 - 支持 PDF、DOCX 等文件解析。 - 提供代理设置、反爬虫机制处理等功能。 |
| 使用方式 | - 通过 https://r.jina.ai/ 前缀快速抓取网页。- 支持 API 调用和自定义参数。 |
- 提供在线平台和本地运行选项。 - 支持多种编程语言 SDK(如 Python、Node.js、Go 等)。 |
| 易用性 | 用户友好,适合快速提取网页内容。 | 功能更强大,适合需要复杂任务处理的用户。 |
| 输出格式 | 主要输出纯文本或 Markdown 格式。 | 支持 Markdown、HTML、屏幕截图、精简 HTML、超链接和元数据等多种格式。 |
| 免费额度与限制 | 提供免费层级,但有速率限制。 | 提供免费额度,允许每月爬取 500 页。 |
| 开源与部署 | 开源项目,支持自部署。 | 支持本地运行和托管版本。 |
| 对 PDF 的处理能力 | 不支持 PDF 文件解析。 | 支持 PDF 文件解析,但效果不如 Jina Reader。 |
Jina Reader 更适合快速、简单地提取网页内容
而 FireCrawl 在功能上更为强大,适合需要处理复杂任务和多种数据格式的用户。
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号