[职业发展] 对数据行业及职业的理解
1 序

-
毕业那一年,栀子花香,衰喜交合。幸运的是,毕业设计与答辩之际幸运地遇到了人生中最重要的伴侣;误打误撞在最后一次考试机会里过了CET六级;根据毕业论文的思路,提交了又打回来,提交了又打回来,跌跌撞撞、历时2年整、最终还是在2021年通过了的一篇发明专利(hard级别最高的专利);把大学四年攒下的自信几乎快被消耗殆尽的驾照终于拿下;学会做饭(给爱人吃~);不幸的也很多,头铁二战考研,再次名落孙山————数学一直成为那个命门,政治倒是出奇的好(84分,这分数可能在当时省内也是top级别了吧...)。就这样,2019年到2020年的年初就没了。
-
毕业第二年,考研失利,慌忙择业,初入职场。考研失利是意料之中的事,你复xi的怎么样,你发挥得怎么样,其实是门儿清的,所以,当时考完就估计到了要死在数学手上。找工作的事儿,却拖到了二月末才开始,复xi了将jin一个月才开始投简历。此时,已经是四月上旬了,导致失去了很多去优质IT企业的良机,又加上不想和媳妇儿异地便留在了成都,没有选择去IT的殿堂级城市北京。最终,误打误撞进了现在这家ToB的大数据公司,从事着数据中心的数据仓库、数据管理与治理的业务。对目前的公司和业务,算是比较喜欢的。
-
工作的这一年,做过项目金额规模不等(50万-500万)的
数据仓库或交付运维的活儿(40%)、做过数据管理与治理平台软件的订制开发(20%)、也长期和各种项目的bug/漏洞做斗争(25%)、顺便偶尔兼职做做项目经理(15%),以推进部分项目的工作进度。经历了这一年,脑子里装了很多东西,对项目管理/软件工程、数据仓库/数据治理、大数据生态/各类数据库(Hive/Oracle/MySQL/ElasticSearch/Redis等)、系统运维、Web Server(Nginx/Tomcat/Apche)、debug和软件开发有了更深的了解。诚然,了解越多,也就发现自己越无知,越需要学的内容就多,迫切地需要挤出时间去做想要做的事儿、想要学的知识。而另一方面,由于数据项目确实是有很多累活脏活需要干,ToB型项目很多乱七八糟的事情(涉及:项目过程管理[立项、调研、系统设计、开发/实施、系统测试、初验/终验、审计合规{流程、资料/凭据、安全}等]、沟通协调、定需求、打漏洞、做开发、汇报等),每天都会抛进我的待办列表中,时常加班是必不可少了。
2 行业理解:大数据综述
- 大数据综述 - 博客园/千千寰宇
- [数据管理] DCMM : 数据管理能力成熟度评估模型
- 数据治理 | 数据仓库 | 数据中台 | 数据平台
3 技能堆栈:大数据生态 / 大数据技术栈
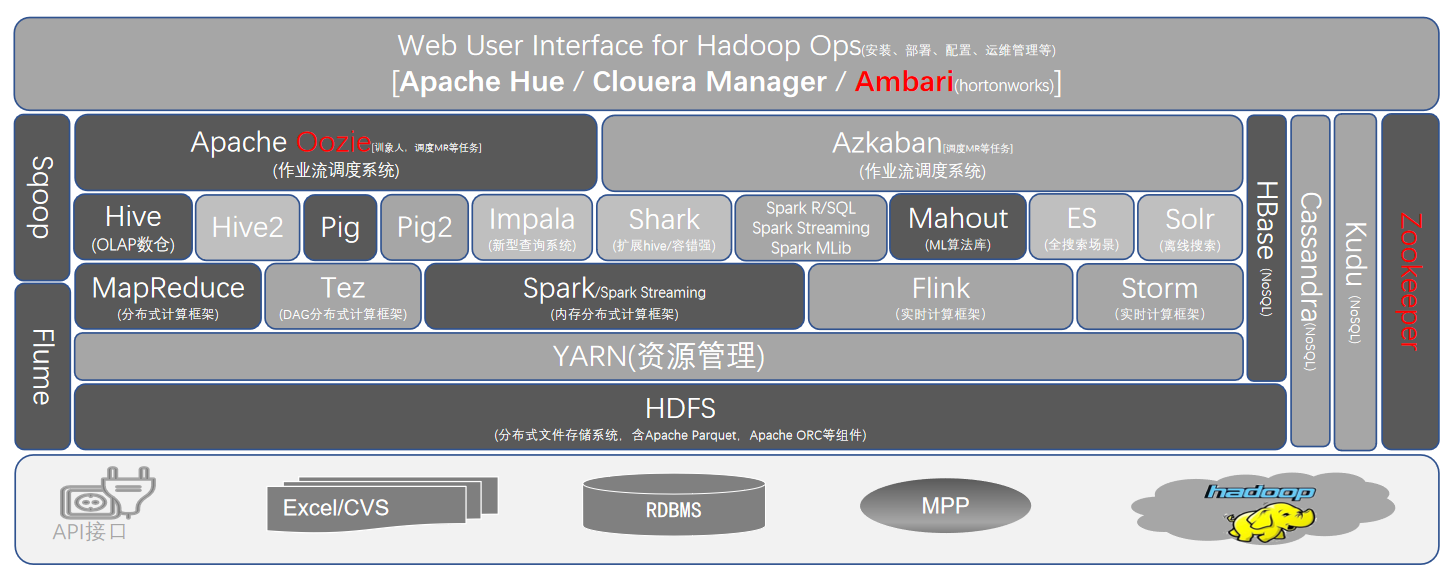
3.0 硬件及操作系统层
-
计算机设备的组成原理
-
[计算机组成原理/硬件/半导体 - 标签 - 博客园/千千寰宇](计算机组成原理/硬件/半导体 - 标签 - 千千寰宇 - 博客园)
-
[计算机组成原理-知识图谱 - 博客园/千千寰宇](计算机组成原理-知识图谱 - 千千寰宇 - 博客园)
-
CPU
-
显卡
-
-
Linux
3.1 数据集成层:数据采集与预处理层
采集工具
-
日志采集、埋点数据
- Flume(日志)
- ELK : Logstash / Es / Kibana(日志)
-
数据互导
- Sqoop(关系型数据库 ←→ HDFS/Hive)(不推荐,已非主流)
-
专业ETL & 数据集成框架
-
Kettle
-
Informatica
-
Datastage
-
Datax
-
Apache Nifi
-
Apache StreamSets
-
Datapipeline
-
...
-
基于 Binlog 监听
- Canal
- Apache Flink CDC
- Sea Tunnel
-
通用框架:
- Spark - Spark Streaming(毫秒级)
-
Flink(微秒级)
-
-
[商业化软件|订制/自研软件] 数据填报系统 / 数据交换共享系统 / ...
调度系统 & 自动化 & 工作流
本节的这些工具,在数据仓库的数据开发任务中也会被使用。
- 自动化脚本语言: Linux Shell / Python / ...
- 工作流/作业调度系统:
- 单机调度:
- Crontab / Quartz / ...
- 分布式调度:
- xxl-job
- elastic-job(基于Quartz,from 当当)
- Apache DolphinScheduler
- Apache Airflow / oozie / azkaban / chronos / zeus
- SchedulerX(阿里) / TBSchedule(阿里)/ ...
- 单机调度:
- 资源调度系统:
- Yarn / Mesos / Omega / Borg / 伏羲(阿里) / Gaia(腾讯) / Normandy(百度)
采集数据的数据源
-
采集来源:数据库
- RDBMS
- MPP
- 大数据 Hadoop
- NoSQL: MongoDB/RabbitMQ/Kafka(日志数据等)/Redis/HBase/ ...
-
采集来源:文件数据采集 U 网络数据采集
- 结构化数据采集: json、excel、xml、等
- 非结构化数据采集: 图片、文本/文档(日志数据等)、视频、音频等
3.2 数据传输层&缓冲层
- 传输
Kafka、RocketMQ、HTTP
- 缓冲
Elasticsearch、Redis
3.3 数据存储层
- 数据库存储
- RDBMS: Oracle/PostgreSQL/MySQL/DM/ ...
- MPP: Greeplum/GaussDB/GBase/ ...
- 大数据 Hadoop: Hive /
- NoSQL: MongoDB / Elasticsearch / Redis / HBase/ ...
- MQ:Kafka/RocketMQ/RabbitMQ/...
- 文件数据存储
- 文本: Elasticsearch / MgongoDB
- 文件: FastDFS / Hadoop HDFS / (S)FTP
3.4 数据处理层
MapReduce、Hive、Spark、Flink、Storm
-
离线计算:
- Hadoop MapReduce、Tez、Spark
-
流式、实时计算:
- Storm
- S4
- Heron
- Spark:Spark API / Spark SQL / Spark Streaming
- Flink:Flik API / Flink SQL
-
查询分析层:
- Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Kylin、Druid
- Clickhouse、Doris
3.5 数据管治层/数据中台:业务数据化,数据资产化,资产服务化
元数据
- 元数据管理
- 元数据采集
- 元数据地图
- 元数据检索
- 血缘关系
- 关联关系
数据模型
- 数据模型管理
数据资产
- 数据资产管理
- 数据资源
- 接入资源(业务系统>数据库>表)
- 数据中心资源(数仓分层分域>表)
- 资源目录(业务主题域>表)
- 数据驾驶舱
- 数据生命周期管理(识别、计划、获取/产生、加工/清洗、存储、共享、维护:监控、预警、应用、消亡:清理/迁移 等)
- 数据资源
数据标准
- 数据标准管理
数据质量
- 数据质量管控
数据安全
- 数据安全管控
数据服务
- 数据服务管理(数据服务化,面向应用)
任务调度 & 资源调度
-
任务调度
- 作业调度编排
- ...
-
资源调度
3.6 数据应用层
- 应用-智能挖掘层:
- 机器学习: SVM、PageRank、K-Means、KNN等
- 应用场景:推荐系统、广告营销、风险管控、用户画像等
- 应用-展现分析层:
- 可视化技术:Jquery、Echarts、EasyUI、Three.js
- 可视化软件:Tableu、FineBI/FineReport、SDC UE
3.X 开源框架与软件 && 解决方案与产品服务
4 职业发展:Java软件开发工程师(To 软件架构师) VS 数据开发工程师(To 数据架构师)
- 在没日没夜的学习技术、学习行业业务(数据仓库/ETL、数据治理、大数据Hadoop生态) 和 经历的工作任务的过程中,逐渐有了一定的对这个数据行业和岗位的认识。
4.1 职业发展
- 学好一门技术的3个阶段:
- 第一阶段:会用,大部分都会达到。也是新手变老手的必经之路。
- 第二阶段:会想,在使用的过程中呢,会思考遇到的问题,会独立查找资料解答心中的疑惑,这个过程是一个不断认证的的过程,时间会比较久,大部分人,会卡在第二阶段外面。
- 第三阶段:会玩,等你真正熟悉某一门技术时,你学会的不仅是技术本身,还有内在的技术原理以及设计思路,这时候你可以参与开源技术、回馈开源社区,贡献自己的一份力量。
以上三个阶段,第一个阶段很容易,第二个阶段需要自己额外的时间去思考,反问自己、别人的设计方案,不以完成任务为目的。第三个阶段,需要的综合能力就更多了,计算机嘛,绝对不是一招一式就能讲明白的。
- 对职业规划、对数据行业的核心认识:
0. 职业规划(中长期/3-5年目标)的重要性——————赶路不忘星空,抬头不迷失方向。
1. 坚信(IT行业下的)数据行业是当下的朝阳行业;数据正在成为生产要素,我们正在经历这个时代大浪潮中。
2. 因为深信、因为热爱,所以将致力于坚持深耕于数据行业这片热土。
- 职业规划的初步设想:
1. 工作1-2年: 技术型开发
JVM
基本开发框架: SSM / Spring Boot / Spring Cloud / MyBatis(Plus) / 工程通用脚手架 /
架构:
高性能/高并发:
各组件的性能极限及优化 /
并发/多线程编程 /
Nginx(静态资源/动静分离/前后端分离、正向代理、反向代理、负载均衡)
数据库扩容/分库分表[垂直拆分|水平拆分]、
CAP理论: 一致性(Consistency)| 可用性(Availability)| 分区容错性(Partition tolerance)
高可用:Keepalived(MySQL/Nginx+Keepalived)
事务一致性
多副本一致性
微服务架构
分布式架构:锁、事务、消息、缓存、文件系统、搜索、任务调度
CASE工具: Jenkins / Git/SVN / 禅道 / ...
软件过程
Devops
敏捷开发
软件项目管理
...
2. 工作3-5年: 数据开发
4.2 后端型开发
4.3 数据型开发
数据型开发岗位的分类
0. (开源)基础组件Contributor
优化或自研开源组件的开发者。
一般在中大型互联网公司、开源社区、国产化基础软件公司。
数据库及数据中间件的开发者居多,例如: HBase、Tendis、TiDB、PostgrelSQL、达梦数据库、南大通用数据库等...
1. 基础平台开发岗
Java 为主。主要做统一数据开发平台、大数据源码级别扩展优化、提供提升开发效率的工具、元数据管理、数据质量管理等。
技能要求:Java,Zookeeper,Hadoop,Hive,Spark,Kafka、ES等。
2. 数据应用产品开发岗
服务端 Java 为主,全部容器化管理服务。主要是数据报表平台、数据分析平台等。
3. 数据仓库开发岗
如果数据开发平台比较完善,一般以 sql 为主,不管是离线计算,还是实时计算,都只需要在数据开发平台上提交 sql 任务即可。更专注数据模型的建设,能够快速实现用户的数据分析需求。
如果平台不够完善,实时计算可能还是需要写代码,scala 为主。
技能要求:数据建模、数据管理与治理、报表开发、理解业务。
4. 数据分析岗
sql为主。分析数据趋势,挖掘潜在价值。
要求:数据分析技能➕Hadoop➕Hive➕部分Java
5. 数据挖掘(算法)岗
语言: Scala,Python,R。
理论:概率论与数理统计学、机器学习等
————————————————————
高阶: 数据架构师
数仓开发工程师 ≈ 数据开发工程师
工作范畴
- 数据资产开发:
流程: 数据接入 ----> 数据建模+数据开发 ----> 数据服务
1数据探查 1数据标准梳理 1服务需求调研(业务数据需求/数据安全)
2数据同步(ETL) 2数据需求调研 2(数据建模+数据开发 / 数据资源盘点)
3数据对账 3数据模型建模(对标) 3数据服务开发
4数据任务开发(ETL) 4服务管理
工具: 离线开发 | 实时开发 | 算法开发 | 数据服务 | 运维管控 |
1任务管理
2任务监控
3资源监控
数据开发工程师的“工作范畴”可以用一句话概括:
“把原始、散乱、不可用的数据,变成高质量、可复用、可服务化的数据资产,并保障其稳定、高效、安全地流动与存储。”
落到日常,可拆成 8 大任务域、30+ 子任务,覆盖离线、实时、云端、治理、安全、运维全链路——
1. 数据接入(Ingestion)
- 对接 50+ 源系统:业务 DB(MySQL、Oracle)、日志文件、埋点 SDK、IoT 传感器、第三方 API、消息队列(Kafka、Pulsar)
- 选型与实现:批量 Sqoop/DataX/SeaTunnel,实时 CDC(Flink CDC、Debezium),REST/GraphQL 爬虫
- 统一接入平台:配置化拉元数据、自动建表、权限申请、流量控制
2. 数据清洗与转换(ETL/ELT)
- 脏数据修复:编码乱码、时区错位、粒度不一致、金额单位差异
- 业务逻辑还原:订单状态机、退款链路、优惠券分摊、汇率补全
- 复杂字段解析:JSON 嵌套展平、正则拆解、数组 explode、地理位置 GEOHash
- Slowly Changing Dimension:拉链表、快照表、版本表
3. 数据建模与分层
- 分层体系:ODS(原始)→ DWD(明细)→ DWS(汇总)→ ADS(应用)
- 维度建模:星型/雪花/星座,事实表(事务、周期快照、累计快照)、维表(代理键、层级、属性)
- 主题域抽象:用户、商品、交易、营销、物流、财务、风控、设备
- 指标口径:原子指标、派生指标、复合指标、同比环比、留存、LTV、ROI
4. 离线计算开发
- 调度平台:Airflow、DolphinScheduler、Azkaban —— 配置 DAG、依赖、重跑、并发、告警
- 计算引擎:Hive、Spark SQL、Spark Core、MapReduce,写 SQL/Scala/Java
- 性能调优:分区裁剪、列式存储(ORC/Parquet)、小文件合并、Bucket Map Join、倾斜 key 加盐
- 回刷与补数:一键回溯 3 年数据,保证幂等、可重入
5. 实时计算开发
- 流式引擎:Flink(DataStream / SQL)、Spark Streaming、Kafka Streams
- 实时数仓:Kafka → Flink → ClickHouse/Doris/StarRocks → BI
- Exactly-Once:Checkpoint、两阶段提交、幂等写入
- 维表关联:异步维表缓存(Redis、HBase、Guava Cache)、Temporal Join
- 事件时间 & Watermark:解决乱序、延迟数据、窗口计算(Tumble/Hop/Session)
6. 数据服务化(Data-as-a-Service)
- 统一 API:GraphQL、REST、gRPC,支持点查、列表、聚合、推送
- 特征服务:在线特征存储(Redis、TiKV、HBase + Feature Store)供算法毫秒级调用
- 数据超市:自助查询平台,字段级权限、脱敏、行列过滤、SQL 审计
- 数据沙箱:提供 Jupyter/Spark 交互式集群,支持分析师自助跑数
7. 数据治理 & 质量
- 元数据管理:自动采集字段、血缘、热度,支持影响分析、下线提醒
- 数据质量:规则引擎(唯一性、完整性、准确性、及时性、一致性)→ 异常告警 → 工单闭环
- 数据标准:命名规范、编码表、单位字典、码值映射
- 生命周期:冷热分级(SSD→HDD→对象存储→磁带),30 天自动降冷、180 天自动删除
- 成本优化:存储压缩、计算按需弹性、Spot 实例、CU 预算告警
8. 运维 & 安全
- 高可用:双活/多 AZ、NameNode HA、Kafka MirrorMaker、Flink Savepoint 自动备份
- 监控:任务失败、延迟、数据漂移、内存溢出、GC、队列堆积 → Prometheus+Grafana+AlertManager
- 权限与安全:
- 行列级权限(Ranger、Atlas、Hive ACL)
- 敏感数据脱敏(手机号、身份证、银行卡)
- 审计日志、GDPR/网安法/等保 2.0 合规
- 灾备演练:跨机房恢复 ≤30 min,RPO<15 min
- On-Call:7×24 值班、War Room、根因分析(5 Whys)、事后复盘报告
总结
“接、洗、建、算、管、服、维、安”——
把数据从任何源头 接 进来, 洗 干净, 建 模分层,离线/实时 算 好,
管 理治理, 服 务化输出,运维保 维 稳定,全程 安 全合规。
能力要求
截至2025年,企业对「数据开发工程师 / 数据仓库工程师」的招聘要求已高度趋同,可概括为“底层平台 + 数据建模 + 性能调优 + 业务理解”四大维度,典型JD要点:
-
学历与年限
- 本科及以上,计算机/数学/统计/信息管理等专业;
- 校招/实习:0-1年即可;社招:2-5年以上大数据开发或数据仓库实施经验,有PB级、实时或云数仓项目经历优先。
-
核心技术栈
① 离线:Hadoop、Hive、Spark(SQL/Scala/Java)、ETL工具(Sqoop/DataX/Kettle);
② 实时:Kafka、Flink、Spark Streaming,能保障秒级延迟及10万+TPS稳定;
③ 存储:熟悉 OSS、HDFS、HBase、ClickHouse、Doris、Iceberg、StarRocks、ElasticSearch、Impala、Presto等至少2-3种;
④ 编程语言:精通复杂SQL,掌握Python/Java/Scala之一,能写UDF、脚本及调度;
⑤ 云原生:了解阿里云MaxCompute/AnalyticDB、AWS Redshift、GCP BigQuery等托管数仓,懂弹性扩缩与成本优化。
-
数据建模与架构
-
精通维度建模(星型/雪花/星座)、3NF、Data Vault,能独立设计ODS→DWD→DWS→ADS分层体系;
-
熟悉建模工具(PowerDesigner/ERWin),可输出逻辑/物理模型及建模规范。
-
-
数据可视化工具
- 掌握数据可视化工具,如Tableau、Power BI等
-
性能调优与治理
-
熟练使用分区、分桶、列式存储(ORC/Parquet)、索引、缓存(Redis/Alluxio)等手段优化查询与存储;
-
建立数据血缘、元数据管理、质量校验、SLA监控与告警,熟悉Atlas/DataHub等治理工具。
-
-
业务与协同
-
能快速理解电商、金融、制造、车联网等行业场景,把业务需求转化为稳定、可复用的数据服务(API/BI看板/标签/画像);
-
与产品、算法、运营、数据分析师高效对接,推动需求落地并持续迭代。
-
-
项目管理
具备一定的项目管理能力,能够合理安排工作进度,确保项目按时交付。
-
个人素质
-
自驱力。逻辑严谨,对数据敏感,具备强烈自驱力
-
影响力。对大数据开源社区有源码级贡献或大会分享经历者加分。
-
沟通能力。具备良好的沟通能力与团队协作意识,能够与业务部门、开发人员、测试人员等进行有效沟通。
-
学习能力/解决问题的能力/适应能力:具备较强的学习能力和解决问题的能力,能够【快速适应】新技术和新环境。
-
语言。具备一定的英语读写能力,能够阅读英文技术文档和资料。
-
抗压能力。具备一定的抗压能力,能够在高强度的工作环境下保持高效的工作状态。
-
一句话总结:企业希望你“既能把海量数据高效、稳定地搬进仓库,又能把仓库里的数据快速、准确地送到业务手里”,并能在云原生与实时化趋势下持续优化成本与性能。
细分工种
ETL工程师:数据采集与接入、...
数据开发工程师:
数据标准梳理、分层分域设计、数据模型建模(落地标准)、血缘关系维护、仓内大数据ETL任务开发、数据服务对接与开发
数据质量工程师:
标准落地到质量设计、质量需求调研与梳理、质量任务的设计、质量报告的分析与汇报、质量问题工单的跟踪闭环
...
数据分析工程师 && BI工程师
截至2025年,企业对「数据分析工程师」的招聘要求已收敛为“技术工具 × 业务洞察 × 沟通落地”三大维度,典型JD要点:
- 学历与年限
- 本科及以上,数学/统计/计算机/金融/经济等相关专业优先;
- 校招/实习:0-1年即可;社招:2-5年以上数据分析或商业分析经验,有互联网、金融、零售、制造等行业背景加分。
- 核心技能
- SQL:复杂查询、窗口函数、性能调优,面试必考;
- Excel:透视表、常用函数、Power Query,快速验证假设;
- Python/R:Pandas/Numpy数据清洗、统计建模、自动化报告;
- 可视化:Tableau、Power BI、FineBI 至少精通一种,能搭建交互式仪表盘;
- 统计学:描述统计、假设检验、相关与回归、聚类与分类基础;
- A/B Test:实验设计、样本量计算、显著性检验、因果推断;
- 大数据组件(加分):Hive/Spark 写简单脚本,能从数据仓库自助取数。
- 业务与场景
- 能快速理解电商、内容、金融、出行、SaaS 等核心业务链路,把“业务问题”翻译成“数据指标”;
- 熟悉用户行为分析(埋点、漏斗、留存、LTV)、流量/销售/供应链/风控等常见分析框架;
- 独立完成需求拆解 → 数据提取 → 建模/对比 → 洞察 → 可执行建议 → 推动业务落地闭环。
- 软技能
- 数据故事讲述:用图表+叙事让非技术管理层秒懂结论;
- 跨部门沟通:与产品、运营、财务、研发高效对齐需求与排期;
- 项目管理:在敏捷节奏下同时交付多个分析专题,按时输出高质量报告。
- 个人素质
- 数据敏感、逻辑严谨、自驱力强,对异常指标能“秒级”追问到底;
- 具备持续学习能力,关注大模型、自动化分析等新工具并快速落地试用。
一句话总结:企业希望你“用 SQL 取数、用 Python 清洗、用可视化讲故事、用统计验证假设”,最终把数据变成可落地、可量化、可复用的业务决策。
数据挖掘工程师 := 算法工程师
截至2025年,企业对「数据挖掘工程师」(常等同于“算法工程师”)的招聘门槛已普遍抬高到“硕士+硬核算法+海量数据+业务闭环”水平,典型JD可拆成5大模块:
-
学历与年限
- 本科起步,硕士及以上占比>45%;全球TOP50/985/QS200优先;
- 校招:0-1年科研或竞赛经历即可;社招:2-5年以上实际项目,有推荐、搜索、广告、风控、用户画像等场景落地经验。
-
算法与理论
- 机器学习:LR、SVM、Tree Model、GBDT/XGBoost/LightGBM、随机森林、聚类、关联规则;
- 深度学习:DNN、Wide&Deep、DeepFM、DIN、DIEN、双塔、Seq2Seq、Transformer、GNN、强化学习;
- 统计基础:概率论、假设检验、因果推断、AB实验设计与显著性分析;
- 前沿方向(加分):图神经网络、多任务学习、迁移学习、对比学习、大模型微调/RLHF。
-
工程与数据
- 编程:Python(NumPy/Pandas/Scikit-Learn)+ SQL必精;Java/Scala/C++至少能读;
- 框架:TensorFlow、PyTorch、Keras、MindSpore至少一种;
- 大数据:Hadoop、Hive、Spark、Flink、Kafka,能写分布式特征工程与离线/实时样本流;
- 特征工程:海量日志清洗、归一化/分箱/编码、维度压缩、实时特征服务(Redis+Feature Store);
- 模型上线:了解TensorFlow Serving、TorchServe、ONNX、Docker+K8s、A/B灰度、模型监控与漂移检测。
-
业务与场景
- 推荐/搜索:召回(多路协同过滤、向量检索)、排序(CTR/CVR预估)、重排(多样性、业务规则);
- 广告/营销:LTV预估、人群look-alike、智能出价、优惠券敏感度模型;
- 风控:反欺诈、信用评分、异常检测;
- 用户画像:标签挖掘、聚类分群、生命周期预测;
- 具备“把业务指标翻译成模型目标函数”的能力,能通过算法带来可量化的GMV、ROI或留存提升。
-
软技能与个人特质
- 数据敏感、逻辑严谨、自我驱动,对0.1pp的指标波动愿意刨根问底;
- 良好的跨团队沟通(产品、运营、平台、数据工程),能把复杂模型解释给非技术高层;
- 持续学习:跟进KDD/NIPS/ICML/ACL/CVPR等最新论文并快速落地试用;
- 竞赛/论文/专利:Kaggle、天池、KDD Cup、LeetCode 200+、顶会一作都是加分项。
一句话总结:企业希望你“既能手撕公式推模型,又能写分布式代码跑数据,最终把算法变成可灰度、可解释、可盈利的业务结果”。
数据(平台)架构师
数据运营工程师
数据产品经理
截至2025年,企业对数据产品经理的招聘要求可归纳为“硬技能+业务理解+项目落地”三大维度,典型JD要点:
-
专业与年限
- 本科及以上,统计学/数学/计算机/信息管理优先;
- 校招/实习:0-1年相关经验即可;社招:2-5年以上数据产品或数据分析经验,有数据中台、BI、SaaS、流量/用户行为等方向背景更受青睐。
-
数据能力
- 熟练使用SQL(MySQL/Hive)做数据提取与验证,能写复杂查询;
- 熟悉数据仓库分层、ETL流程、常见埋点及用户行为采集方案;
- 具备A/B Test、漏斗、归因、异动分析等方法论,能独立完成指标拆解与监控体系。
-
产品技能
- 能独立撰写PRD、绘制原型(Axure/墨刀/Sketch),掌握Visio/Xmind等工具;
- 熟悉数据可视化、数据治理、数据资产管理、标签/画像/推荐系统等产品形态;
- 具备从0-1或1-N的产品规划、竞品调研、需求评估、迭代管理、上线运营全流程经验。
-
业务与沟通
- 能快速理解电商、内容、金融、零售等核心业务场景,把业务痛点转化为数据解决方案;
- 跨部门推动能力强,可与数据开发、算法、平台、运营、业务方高效协同,把控进度与风险;
- 具备英文读写/口语能力、演讲及培训能力者加分。
-
个人素质
- 逻辑严谨、数据敏感、自我驱动,能在高强度环境下同时管理多项目;
- 对大数据生态(Hadoop/Spark/Flink)或数据科学算法有基础认知者更受青睐。
简言之,企业希望候选人“既懂数据又懂产品,还能把业务问题落到平台功能”,并能在快速迭代中持续产生可衡量的业务价值。
Y 推荐文献
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号