[Linux] 常用命令之【cat/echo/iconv/vi/vim/grep/find/head/tail/tailf】
cat
cat [选项] [文件]..
# 一次显示整个文件或从键盘创建一个文件或将几个文件合并成一个文件
cat -n file1
# 编号文件内容再输出
echo
-n 输出后不换行
-e 遇到转义字符特殊处理
# eg:
echo "he\nhe" # 显示he\nhe
ehco -e "he\nhe" # 显示he(换行了)he
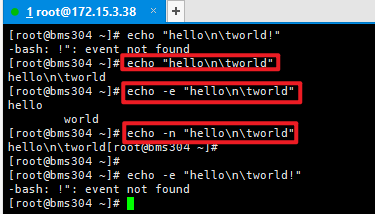
- 不执行/不引用输出的内容
关键点:单引号
echo 'xxxx'
echo 'zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz' >> /opt/Python-3.9.9/Modules/Setup
文本内将追加1行:
xxxx
文本内将追加1行:zlib zlibmodule.c -I$(prefix)/include -L$(exec_prefix)/lib -lz
iconv
当前文件编码为gb2312(from),转换为utf-8(to)
iconv -f gb2312 -t utf-8 inputfilename > outputfilename
VI / VIM
安装 vim
- 安装 vim
Ubuntu Linux
apt-get update
apt-get -y install vim
CENTOS Linux
//安装 常用支持库 (可选步骤)
yum install -y gcc gdb strace gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs patch e2fsprogs-devel krb5-devel libidn libidn-devel openldap-devel nss_ldap openldap-clients openldap-servers libevent-devel libevent uuid-devel uuid mysql-devel
//安装 vim-enhanced-7.0.109-7.el5 vim-minimal-7.0.109-7.el5 vim-common-7.0.109-7.el5
yum -y install vim*
vi中查找字符内容
- step1 命令模式下输入
/字符串。例如:/Section 3
/ 向后搜索
? 向前搜索
- step2 如果查找
上/下一个,按N/n即可
要自当前光标位置向上搜索,请使用以下命令: /pattern Enter
其中,pattern表示要搜索的特定字符序列。
要自当前光标位置向下搜索,请使用以下命令: ?pattern Enter
按行号显示文件文本
替代性方案: cat -n
或 nl
开启行号
ESC键 + 输入(: set number 或者 : set nu)
关闭行号
ESC键 + 输入(: set nonumber)
跳到指定行
:$ 跳到文件最后一行
:0 或 :1 跳到文件第一行
文件内全局替换字符串
:%s/源字符串/目标字符串/g 【:%s/str1/str2/ 替换文本内每一行中所有str1为str2】
替换文本的其它方法:
find $TOMCAT_HOME/webapps/ -name jdbc.properties | xargs sed -i 's/53302/3306/g'
其他操作
恢复vi编辑时不正常退出的文件(将会自动生成.swp隐藏文件)
vi -r <fileName>
:wq
rm -f <fileName.swp>
:d 清空当前文件,后保存(:w)即可
(等效于 cat /dev/null > file_name 或 echo "" > file_name【此法会在文件中写入1个空行“\n"】)
:w 保存当前文件
:w filename 保存当前文件(如果进入 vim 的时候没有指定要编辑的文件名,需要在保存文件的时候加上文件名 filename,如果进入 vim 的时候指定了 文件名,那么该用法相当于“另存为”)
:q 退出当前正在编辑的文件
:q! 强制退出当前正在编辑的文件并放弃最近一次保存到现在的所有操作
:wq 保存文件并退出
u 撤销最近一次操作。(按 Ctrl+r 恢复撤销掉的操作)
i 在光标所在的位置前面插入字符
a 在光标所在的位置后面插入字符
o 在光标所在行的下一行插入新的一行
O 在光标所在行的上一行插入新的一行
x 剪切光标处所在的字符。(x 前可先按一个数字,则剪切若干个字符)
dd 剪切光标处所在的一行。(dd 前可先按一个数字,则剪切若干行)
yy 复制光标处所在的一行。(yy 前可先按一个数字,则复制若干行)
:数字 跳转到指定行(:18 跳转到18行; :$ 跳到最后1行)
p 将剪切板中的资料粘贴到光标所在处
r 修改光标所在的字符,r 之后接跟你要修正的字符(比如你要把 fox 中 的 o 改成 i,只需将光标停在 o 上,接着连续按下 r 和 i)
h 将光标向前移动一个字符
j 将光标向下移动一个字符
k 将光标向上移动一个字符
l(小写的 L)将光标向后移动一个字符
gg 跳到文本的最初一行
G 跳到文本的最末一行
Ctrl + u 向上(up)翻页
Ctrl + d 向下(down)翻页
:%s/old/new 将文件中所有的 old 字符串替换成 new
/string 从光标处往下查找字符串 string,注意在输完你要查找的字符串 string。之后要按回车键。如果你要找的字符串 string 有多个,你可以按 n 将 光标跳到下一个位置,按 N 将光标跳到上一个位置
?string 跟上面的</string>是一样的,区别是它从光标处往上查找

grep
grep亦支持正则搜索,可参见: Linux命令- grep +正则表达式[推荐] - CSDN
grep [-acinv] [--color=auto] '搜寻字符串bai' filename
选项/参数:
-a :将 binary 文件以 text 文件的方式搜寻数du据
-c :计算找到zhi '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行
-m <-num-> / --max-count=<-num-> : 查看前N次出现的目标内容
-o, --only-matching : 只显示一行中匹配PATTERN 的部分
-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
--color=auto :【搜索的文本 字体高亮】;可以将找到的关键词部分加上颜色的显示喔!
- 利用
grep -v {keyword}过滤不含有{keyword}字样的行
- 常用命令:
grep -v grep,并结合管道命令 :grep -v "grep" 就是查找不含有 grep 字段的行
root@ecs-5c77:~# ps -ef | grep -i "xxl-job-executor"
root 3076404 1 1 16:54 pts/0 00:00:35 java -jar /opt/xxljob-executor/bdp-xxl-job-executor-app.jar
root 3101423 3071911 0 17:30 pts/1 00:00:00 grep --color=auto -i xxl-job-executor
root@ecs-5c77:~# ps -ef | grep -i "xxl-job-executor" | grep -v grep
root 3076404 1 1 16:54 pts/0 00:00:35 java -jar /opt/xxljob-executor/bdp-xxl-job-executor-app.jar
- 过滤空白行
grep -v '^$' abc.txt
- 不显示以#开头的行
grep -v '^#' /etc/profile
- 递归的
-R、逐行/显示行号的-n、在指定路径<dirPath>下的文本内查找关键字keywords
# grep -nR "keyword" <dirPath>

- 【高亮色彩
--color=auto】显示指定文件集-name "*.sql"内(【忽略大小写】-i)出现指定关键字的情况,需:【显示文件名-H】、【显示行号-n】
$ find ./ -name "etl_task_resource*.sql" | xargs grep -Hni --color=auto 'create database'
./etl_task_resource-data.mysql.10.0.11.138.202104012104.bak.sql:22:CREATE DATABASE /*!32312 IF NOT EXISTS*/ `ETL_TASK_SOURCE_234` /*!40100 DEFAULT CHARACTER SET utf8 */;

- 列出在当前路径下查找出现指定关键词的文件名
[root@localhost opt]# grep -i apple -rl --include="*.out"
output.out
[root@sdc04 opt]# grep -i apple -rl --include="*.out" | xargs cat
hello world
apple tree follow
test-demo.txt 2435
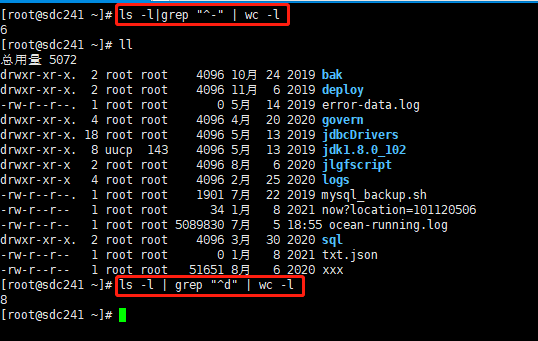
- 统计 指定目录下的
文件/文件夹个数
ls -l | grep "^-" | wc -l
# 统计文件个数
ls -l | grep "^d" | wc -l
# 统计文件夹个数
- 查看文件中出现关键词的行数
grep -c 'keyword' <fileName>
- 查看文件中出现关键词的次数
grep -o 'keyword' <fileName> | wc -l
wc -l : 统计次数

- 查看前N次出现的目标内容
grep -m <-num-> <-fileName-> = grep --max-count=<-num-> <-fileName->
Stop reading the file after num matches.
(尤其在查看Tomcat日志时,需要查看第一次出现异常在什么时间 (防止无故背锅!!!) 非常有效!!!)
注:亦可结合head方法使用,详见本文:head
---- 2020-10-17 12:16
[root@govern ~]# cat /xx/xx/xxdataxxalxxy/logs/catalina.out | grep -m 1 -C 100 'KettleDatabaseException'
29-Sep-2020 13:20:29.308 信息 [localhost-startStop-1] org.apache.jasper.servlet.TldScanner.scanJars 至少有一个JAR被扫描用于TLD但尚未包含TLD。 为此记录器启用调试日志记录,以获取已扫描但未在其中找到TLD的完整JAR列表。 在扫描期间跳过不需要的JAR可以缩短启动时间和JSP编译时间。
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
加载Etl资源仓库管理构造方法
PluginFilesFolder:plugins/logging
PluginFilesFolder:/home/sdc/.kettle/plugins/logging
PluginXmlFolder:plugins
PluginXmlFolder:plugins/valuemeta
PluginFilesFolder:plugins/valuemeta
PluginXmlFolder:/home/sdc/.kettle/plugins
PluginXmlFolder:/home/sdc/.kettle/plugins/valuemeta
PluginFilesFolder:/home/sdc/.kettle/plugins/valuemeta
PluginXmlFolder:/home/sdc/wydataquality/webapps/wydataquality/WEB-INF/classes//plugins
PluginFilesFolder:plugins/passwordencoder
PluginFilesFolder:/home/sdc/.kettle/plugins/passwordencoder
PluginFilesFolder:plugins/logging
PluginFilesFolder:/home/sdc/.kettle/plugins/logging
PluginXmlFolder:plugins
PluginXmlFolder:plugins/valuemeta
PluginFilesFolder:plugins/valuemeta
PluginXmlFolder:/home/sdc/.kettle/plugins
...
Error connecting to the repository!
Error occurred while trying to connect to the database
驱动程序类'org.gjt.mm.mysql.Driver'无法找到,请确保 'MySQL' 驱动程序(jar文件)已安装.
org.gjt.mm.mysql.Driver
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryConnectionDelegate.connect(KettleDatabaseRepositoryConnectionDelegate.java:160)
at org.pentaho.di.repository.kdr.KettleDatabaseRepository.connect(KettleDatabaseRepository.java:193)
at org.pentaho.di.repository.kdr.KettleDatabaseRepository.connect(KettleDatabaseRepository.java:182)
at com.cdsf.common.objectPool.factory.ETLRepositoryFactory.createNew(ETLRepositoryFactory.java:78)
...
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.pentaho.di.core.exception.KettleDatabaseException:
Error occurred while trying to connect to the database
驱动程序类'org.gjt.mm.mysql.Driver'无法找到,请确保 'MySQL' 驱动程序(jar文件)已安装.
org.gjt.mm.mysql.Driver
at org.pentaho.di.core.database.Database.normalConnect(Database.java:432)
at org.pentaho.di.core.database.Database.connect(Database.java:325)
at org.pentaho.di.core.database.Database.connect(Database.java:296)
at org.pentaho.di.core.database.Database.connect(Database.java:284)
at org.pentaho.di.repository.kdr.delegates.KettleDatabaseRepositoryConnectionDelegate.connect(KettleDatabaseRepositoryConnectionDelegate.java:142)
... 54 more
此 grep + head的组合命令亦有效:
grep -C 200 'KettleDatabaseException' /xx/yy/wmmdzzzquality/logs/catalina.out | head -200
- 最后1次出现的目标内容
(大文件,性能低)
grep -C 200 'KettleDatabaseException' /xx/yy/wmmdzzzquality/logs/catalina.out | tail -200
- 匹配多个关键字
grep -E "word1|word2|word3" file.txt
匹配 file.txt 中包含 word1 或 word2 或 word3 的行。
满足其中任意条件(word1、word2和word3之一)就会匹配。
ps -ef | grep apusic | grep -E "/opt/govern/wydataeye| /opt/govern/datasource | /opt/govern/wydataquality| /opt/govern/wytaskwatcher"
- 查看目标搜索内容的上下N行
grep -C N
[ ] 显示filename文件中,targetContentStr行上下N行内容(含targetContentStr行)
grep -C 3 love filename 显示filename文件中,love行【上下】3行内容(含love行)
grep -A 3 love filename 显示filename文件中,love行【下】3行内容(含love行)
grep -B 3 love filename 显示filename文件中,love行【上】3行内容(含love行)
- 示例:打印指定文件中出现关键词所在行的前 n 个字符
grep "关键词" 文件名 | cut -c1-1000
详情参见: 示例:打印指定文件中出现关键词所在行的前 n 个字符 - 常用命令之【nl/sed/awk/wc/xargs/perl/sort/uniq/comm/cut】 - 博客园/千千寰宇
find
- 列出目标路径下,文本内含有指定字符串的文件
find <targetDirPath> -type f | xargs grep -Hn --color=auto "<key-word>"
find <targetDirPath> -name "*.json" | xargs grep <key-word> # 查找所有含有<key-word>关键词的<json>文件
find <targetDirPath> -user johnny | xargs grep -Hn --color=auto "<key-word>"
# 查找所有含有<key-word>关键词的、且属于用户johnny的文件
(示例:↓)
[root@sdc228 ~]# find /var/ftp/www/share-portal-biz/ -name "*.*" | xargs grep -i discovery-server.sefon.com
/var/ftp/www/share-portal-biz/conf/bootstrap.yml: server-addr: discovery-server.sefon.com:57102
/var/ftp/www/share-portal-biz/conf/bootstrap.yml: server-addr: discovery-server.sefon.com:57102
- 统计指定条件的文件数量
部分find的核心参数:
-type查找某一类型的文件。诸如:
b- 块设备文件。d- 目录。c- 字符设备文件。p- 管道文件。l- 符号链接文件。f- 普通文件。s- socket文件
-o: 或者-a: 而且-not: 相反-empty: 搜索空文件或空目录
# 统计类型为文件夹、文件名称符合sync*的文件数量
# find synchronoss* -type d | wc -l
# 统计类型为文件夹、文件夹为空、文件名称符合sync*的文件数量
# find synchronoss* -type d -empty | wc -l
- 列出目标路径下,文件名含有指定字符的文件
ll <targetDirPath> | grep "<key-word>"
或
find <targetDirPath> -name "*<key-word>*"
- 替换文本内容
find <targetDirPath> -name *.properties |xargs sed -i 's/old_str/new_str/g' # 替换<targetDirPath>目录下所有名为.properties的文件内字符串old_str为new_str

head
- 基本用法
[root@linux ~]# head /etc/passwd #默认,显示开头前10行
[root@linux ~]# head -10 /etc/passwd #显示开头前10行
[root@linux ~]# head -q -n 10 file1 file2 file3 #显示多文件开头前10行,并且不显示文件名的文件头
[root@linux ~]# head -n -10 /etc/passwd #除最后10行外,显示剩余全部内容。
- 查看首次出现的目标内容
在出现【关键词(KettleDatabaseException)】的前后(200)行的查询结果中,查看首次出现目标内容块的前(200)行
grep -C 200 'KettleDatabaseException' /xx/yy/zzztaquality/logs/catalina.out | head -200
tail
- 实时输出最后n行文件内容
tail -f -n 100 /var/log/example.log
-f参数表示实时输出,-n参数表示输出最后n行内容
- 查看文件前100行
cat filename | head -n 100
- 查看文件后50行
cat filename | tail -n 50
- 从1000行开始显示 / 显示1000行以后的
tail -n +1000
- 显示1000行到3000行内容
cat filename |head -n 3000 | tail -n +1000
直接用sed命令: sed -n '5,10p' filename # 只查看文件的第5行到第10行
- 从第3000行开始,显示1000行
即 显示 第3000~3999行
cat filename | tail -n +3000 | head -n 1000
tailf
tail 与 tailf 的辨析 : tailf ≈ tail -f
-
tailf命令几乎等同于tail -f,严格说来应该与 tail --follow=name 更相似些。 -
当文件改名之后它也能继续跟踪,特别适合于日志文件的跟踪(
follow the growth of a log file)。 -
与
tail -f不同的是,如果文件不增长,它不会去访问磁盘文件。 -
tailf特别适合那些便携机上跟踪日志文件,因为它能省电,因为减少了磁盘访问。 -
tailf命令不是个脚本,而是一个用C代码编译后的二进制执行文件,某些 Linux 安装之后没有这个命令。 -
tailf 和 tail -f 的区别
- tailf 总是从文件开头一点一点的读, 而 tail -f 则是从文件尾部开始读。
tailfcheck 文件增长时,使用的是文件名,用stat系统调用;而tail -f则使用的是已打开的文件描述符。
- 注:tail 也可以做到类似跟踪文件名的效果;
- 但是tail总是使用
fstat系统调用,而不是stat系统调用;- 结果就是:默认情况下,当
tail的文件被偷偷删除时,tail是不知道的,而tailf是知道的。
tail -f等于--follow=descriptor,根据文件描述进行追踪,当文件改名或删除后,停止追踪。tail -F等于--follow=name == retry,根据文件名字进行追踪,当文件改名或删除后,保持重试,当有新的文件和他同名时,继续追踪tailf等于tail -f -n 10(tail -f或-F默认也是打印最后 10 行,然后追踪文件),与 tail -f 不同的是,如果文件不增长,它不会去访问磁盘文件,所以 tailf 特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电。
命令与参数
- tailf 命令语法:
tailf logfile# 动态跟踪日志文件logfile,最初的时候打印文件的最后10行内容。
-
命令选项
-
-n,--lines NUMBER# 输出最后数行 -
-NUMBER# 与NUMBER相同 `-n NUMBER' -
-V,--version# 输出版本信息并退出 -
-h,--help# 显示帮助并退出 -
样例
- 显示文件最后 5 行内容
tailf -n 5 request_IP_1502.log
- 实时跟踪/打印日志
tailf几乎等同于tail -f
tail -f store.error.log
安装
- 部分linux发布版中没有包含
tailf指令,使用时会报bash: tailf: command not found错误。
如下是在不同操作系统中的安装方式
# Debian
apt-get install util-linux
# Ubuntu
apt-get install util-linux
# Alpine
apk add util-linux
# Arch Linux
pacman -S util-linux
# Kali Linux
apt-get install util-linux
# CentOS
yum install util-linux
# Fedora
dnf install util-linux
# OS X
brew install util-linux
# Raspbian
apt-get install util-linux
# Docker
docker run cmd.cat/tailf tailf
参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号