[操作系统]字符|编码
0 问题
- 什么是字符?字符集?字符编码?编码表?
- ASCII、UTF-8、GBK、GB2312、Unicode、Big5之间的关联关系?
- 什么是:编码、解码、转码、乱码?
- 乱码现象的本质是什么?导致乱码有哪些可能的原因?有哪些预防方法、解决方案?
- 计算机是如何【存储】、【显示】:文字、图形(矢量)、图像(位图)?(原理、具体过程)
1 概念
1.0 编码 VS 解码
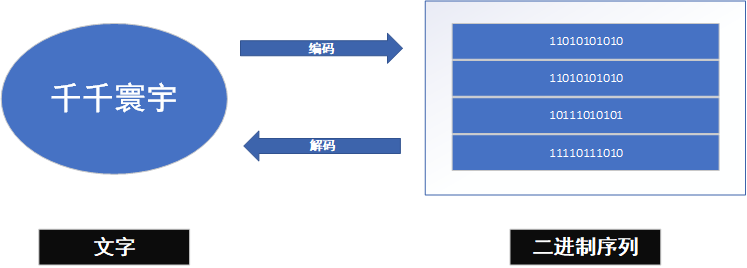
1.1 字符 Character
各种【文字】和【符号】的总称,包括:各国文字、标点符号、图形符号、数字等
1.2 字符集 Character Set
- 多个【字符的集合】,字符集种类较多,每个字符集包含的字符、字符个数均不同。
- 常见的字符集名称:ASCII字符集、Big5(中文最早的编码表/字符集)、GB2312字符集、GBK字符集、GB18030字符集、Unicode字符集(万国码)
- 计算机要准确地处理各种字符集文字,需进行字符集【编码】,以便计算机能够【识别、存储】各种文字。
1.3 字符编码/字集码 Character Encoding
字符编码,也称【字集码】;把字符集中的字符,【编码】为指定集合中的某一对象,以便文本在计算机中【存储】和通过【网络通信】进行传递。
例如:
- Unicode字符集可根据需要,以UTF-8、UTF-16、UTF-32等方法编码;
- GB2312可使用ISO/IEC2022、EUC等标准编码
- 而BIG-5这类字符集通常不需要编码,即可使用。即 BIG-5既是字符集,又是字符编码。
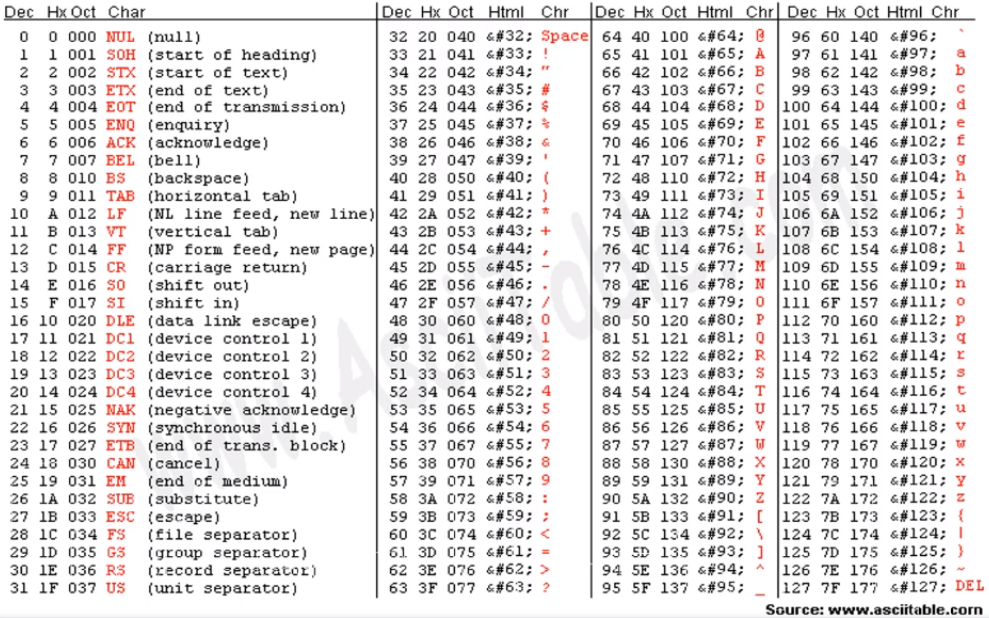
1.3.1 ASCII码

ASCII码(America Standard Code for Information Interchange),即 美国信息交换标准码。
它已被国际标准化组织(ISO)定为国际标准,称为 ISO 646标准。
适用于所有拉丁文字母。
ASCII码是单字节编码,使用指定的7位或把8位二进制数组合起来表示128或256个字符。
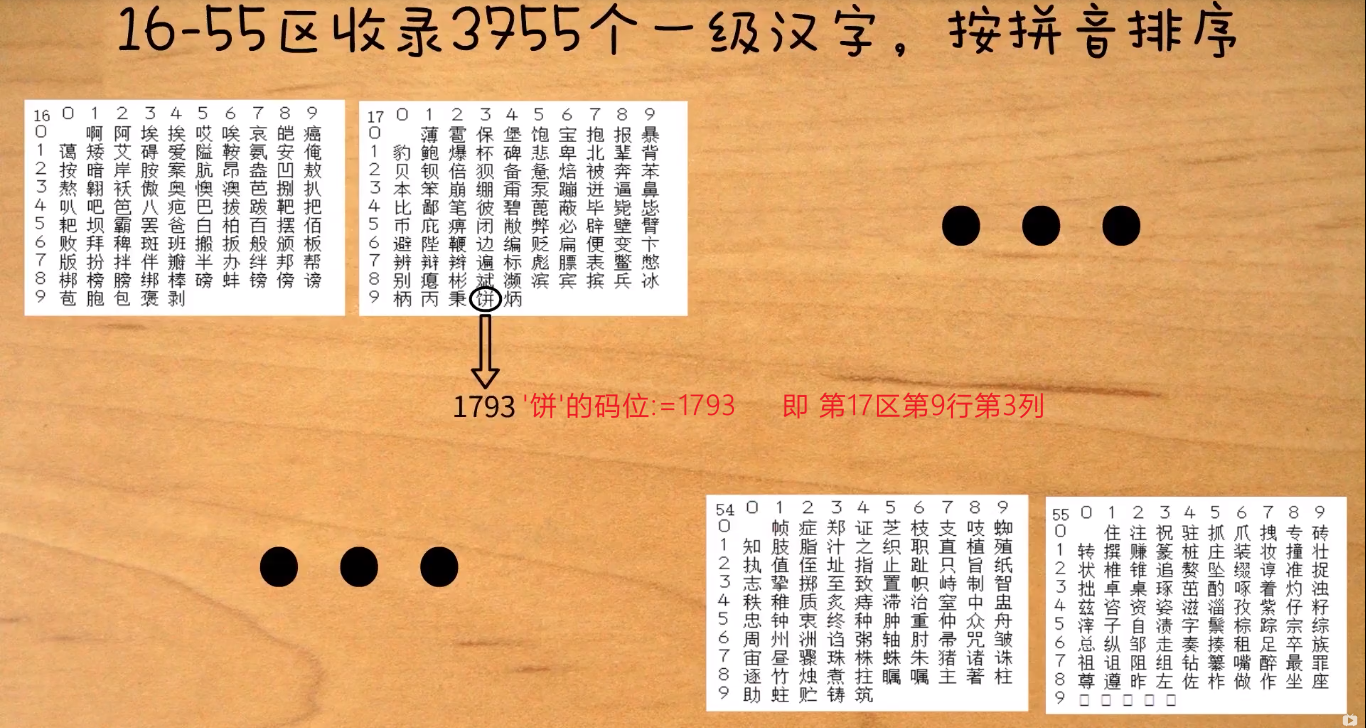
1.3.2 GBK编码
GBK编码是汉字编码标准之一,全称《汉字内码扩展规范》,由中华人民共和国全国信息技术标准化技术委员会于1995年12月1日制订,由国家技术监督局标准化司、电子工业部科技与质量监督司于1995年12月15日以技监标函1995 229号文件的形式,将它确定为技术规范指导性文件。
GBK即“国标”、“扩展”汉语拼音的首字母,英文名: Chinese Internal Code Specification。
【GBK编码】兼容【GB2312】,GBK是对GB2312的扩充,中文Windows的默认/缺省内码就是GBK编码。



'y'的码位:0389(03即03区)

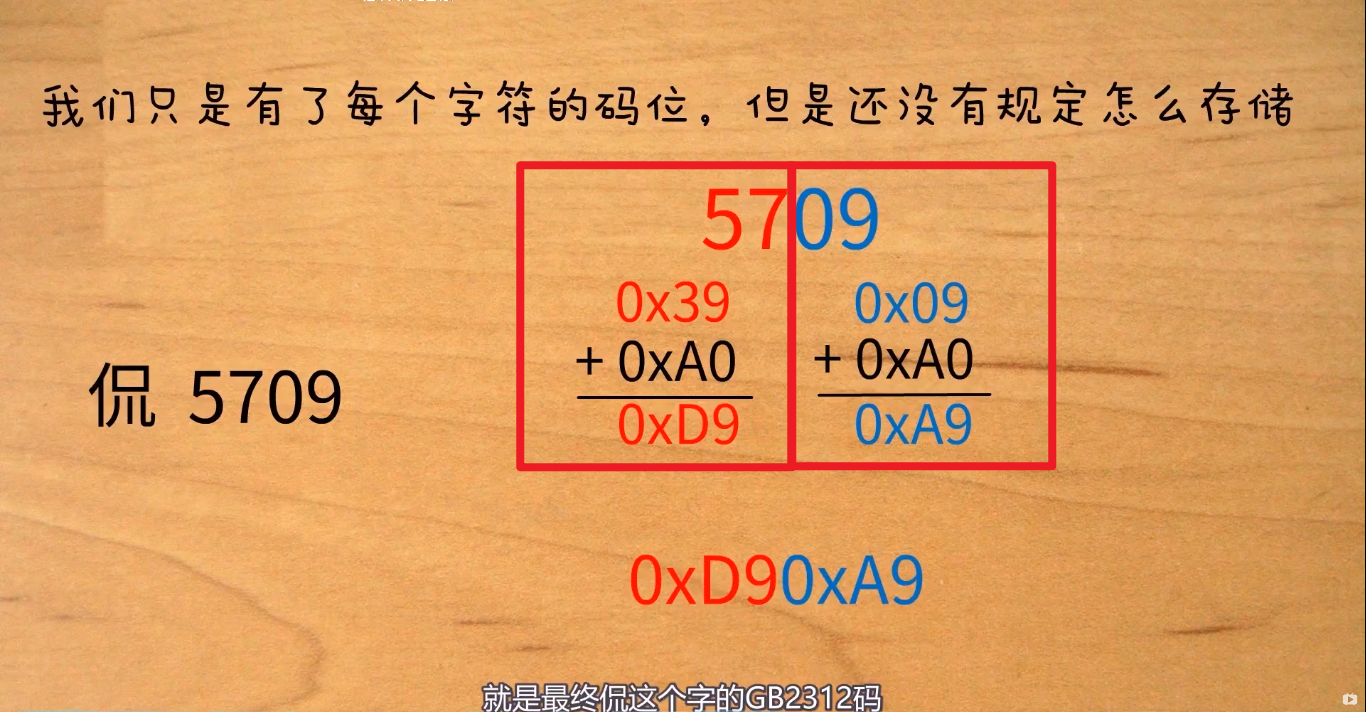
+0xA0,是为了达到GB2312向下兼容ASCII码时,需与ASCII码作区分,也便于计算机判别是GB2312还是ASCII
1.3.3 Unicode编码
Unicode字符集(编码),又称:统一码、万国码。(标准、规范、字符集)
定义了这世界上几乎所有字符的表示,以满足跨语言、跨平台进行文本转换、处理的要求。
且Unicode还兼容了许多老版本的编码规范,例如: ASCII码。
- 【码点】 / 【Unicode转换格式(UTF)】
【码点】是指Unicode给每个字符分配的数字ID,且具有唯一性。
Unicode字符集可根据不同需要,以UTF-8、UTF-16、UTF-32等方法编码;
【码点】的实现方式成为【Unicode转换格式】(Unicode Transformation Format,简称UTF)。
【Unicode转换格式(UTF)】是为了解决【码点】在计算机的存储方式而设计的;
UTF-8、UTF-16、UTF-32都是将【文字/符号】转换到【程序数据】的编码方案。
- 【码元】(Code Unit)
码点经映射后得到的二进制串的【转换格式单位】,称之为:【码元】(Code Unit)。
【码点】就是一串二进制数,而【码元】就是切分这个二进制数的方法。
[示例1] 假定字符x的码点二进制表示有N字节(N*8个二进制数),其每个码元为8位(1个字节),则:
其拥有N个码元。
[示例2]
UTF-8 即 每读码点的08位(码元:08位),就代表1个字符。每08位去读下一个码点。
UTF-16 即 每读码点的16位(码元:16位),就代表1个字符。每16位去读下一个码点
- 【UTF-8编码】
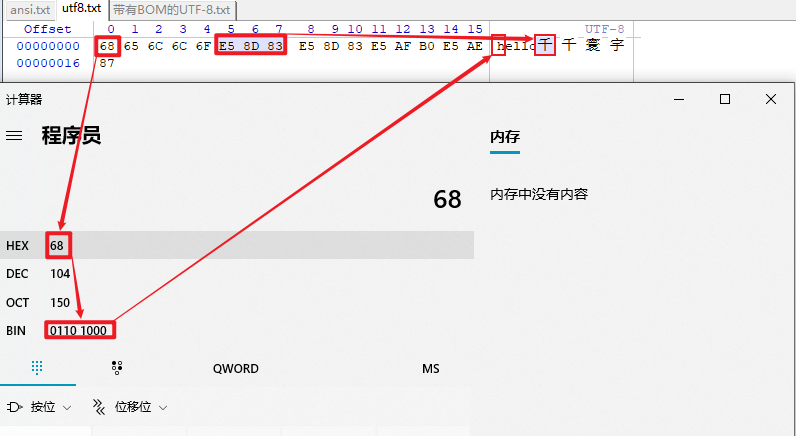
【UTF-8编码】是在互联网上【使用最广】的1种【Unicode字符集实现方式】,它是1种【可变长的编码方式】,它可以使用1-4字节表示1个字符,根据不同的符号而变化字节长度。
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此,对于英文字母,UTF-8和ASCII码是相同的。
2)对于N字节的符号(N>1),第一个字节的前N位都设为1,第N+1位设为0,后面字节的前2位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。

2 参考
3 推荐

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号