[NLP/机器学习] Gensim之Word2Vec 详解
一 前言
Word2Vec是同上一篇提及的PageRank一样,都是Google的工程师和机器学习专家所提出的的;在学习这些算法、模型的时候,最好优先去看Google提出者的原汁Paper和Project,那样带来的启发将更大。因为创造者对自己所创之物的了解程度优于这世上的绝大部分者,这句话,针对的是爱看博文的读者,like me。
另外,补充几句。
1.防止又被抄袭,故关键笔记以图贴之。
2.标题前带阿拉伯数字标号的内容,便是使用Gensim的Word2Vec模型过程中的完整流程序号,通常也较为常用且重要。
二 鸣谢
感谢如下文章/论文的详细描述,它们亦是本文的主要测试依据,尤其需要感谢最后四篇博文的精彩解说。
- Word2Vec Introduction - Google - [推荐]
- Gensim - Word2Vec - Github
- Gensim - Github
- 基于 Gensim 的 Word2Vec 实践
- 翻译Gensim的word2vec说明
- Gensim之Word2Vec使用手册 - [推荐]
- word2vec词向量中文语料处理(python gensim word2vec总结)
三 Word2Vec 概要
Word2Vec 简介
简介
- 2013年,Google 工程师 Tomas Mikilov 及其团队提出了
Word2Vec(Word to Vector)模型,该模型又常被理解为“词嵌入(Word Embedding)”、“词向量”。 - 该模型可以将每个词语映射到由用户指定的、相对低维维度的向量空间中,最终每个词汇对应一条相对低维的一维词向量。
优点
- 此模型不但解决了
One-Hot独热编码的维数灾难问题、以及基于词频统计的TF-IDF等传统模型出现的“词汇鸿沟”等缺陷,而且提出了基于词汇的上下文来理解词汇的新思维方式。
应用场景
Word2Vec所生成的词向量可以直接进行词汇间相似度计算、词汇“距离”运算等操作,效果良好。
因此,在现阶段的自然语言处理领域中,Word2Vec常被作为其它更高阶文本数据挖掘领域的预处理工具。
- 在工业界,可以被用于社交网络领域推荐好友;电子商务领域根据用户以往购物或浏览商品记录计算其相似度来推荐商品、广告等。
子模型:CBOW、Skip Gram
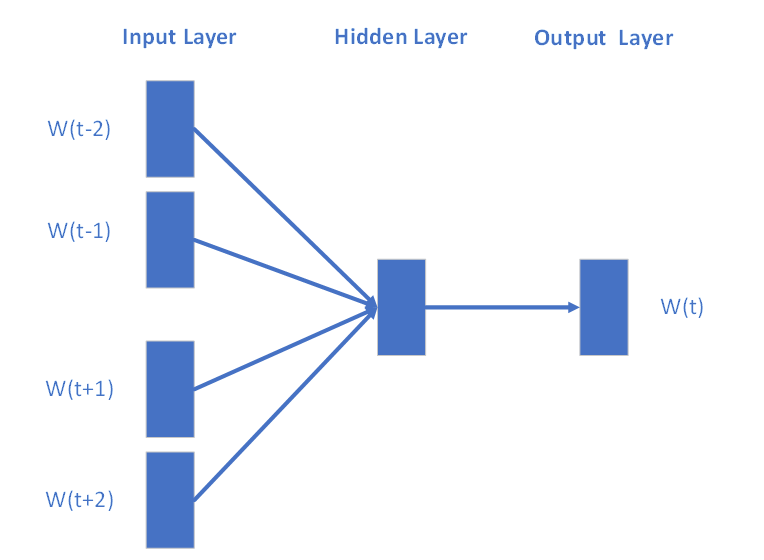
CBOW 模型
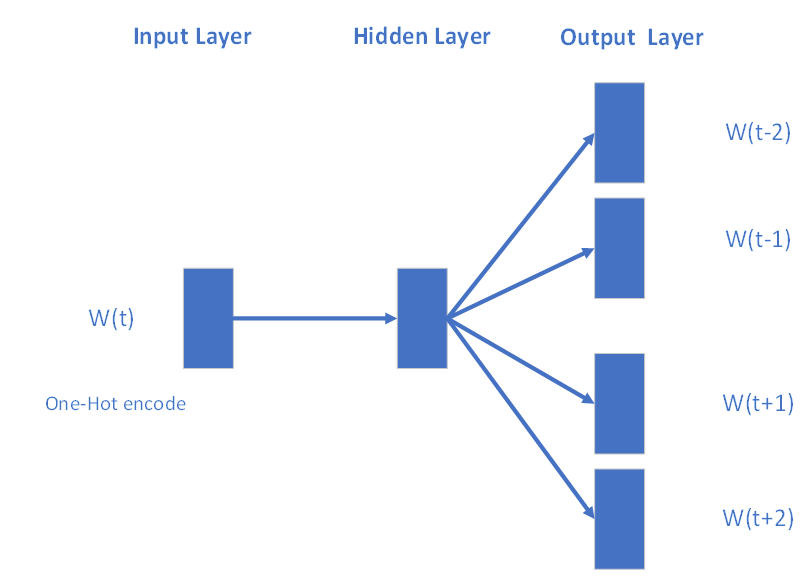
Skip Gram 模型
Word2Vec模型包含了两种子模型,分别是连续词袋模型CBOW(Continuous Bag of Words)和Skip-Gram模型。
Word2Vec是经由NNLM神经网络语言模型改造、简化而来,其两子模型均分为三层:输入层、隐含层、输出层。- 前者根据文本中当前词语的上下文预测当前词的概率;
- 后者根据当前词预测其上下文词汇的概率。
- 在预测过程中,不断迭代其模型中的权重矩阵
W和W',迭代训练结束以后,将获得包含了词汇表中每一词汇词向量的权重矩阵W, 其每一行(列)便作为词向量。
-
训练过程的目标 : 预测当前词的上下文或者预测当前词汇,更像是一道“伪”任务,而模型的真正目的是得到词向量权重矩阵W。
-
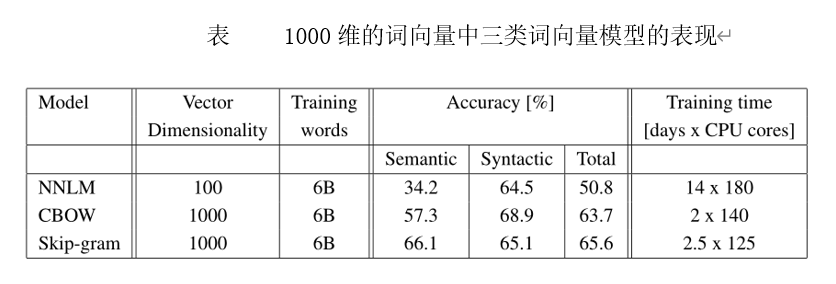
从模型提出者的评测结果(如下表)来看,尽管
Skip-Gram的计算复杂度稍高于CBOW,但在综合语义、语法等指标后,最终结果显示Skip-Gram模型更精确。
Word2Vec的核心原理
以Skip-Gram为例,阐述其词向量模型的构建过程。
在正式阐述前,假定:语料库经过预处理以后,得到一份对于每一个词汇在其内都是唯一的词汇表(Vocabulary),词汇表大小为V;模型使用者指定最终生成的任意词汇的词向量长度为N。
【输入层】
确定每一批次取词的上下文窗口大小、迭代训练次数等模型基本数据项,以训练过程中遍历到当前词汇1行V列的one-hot编码X(t)作为输入。
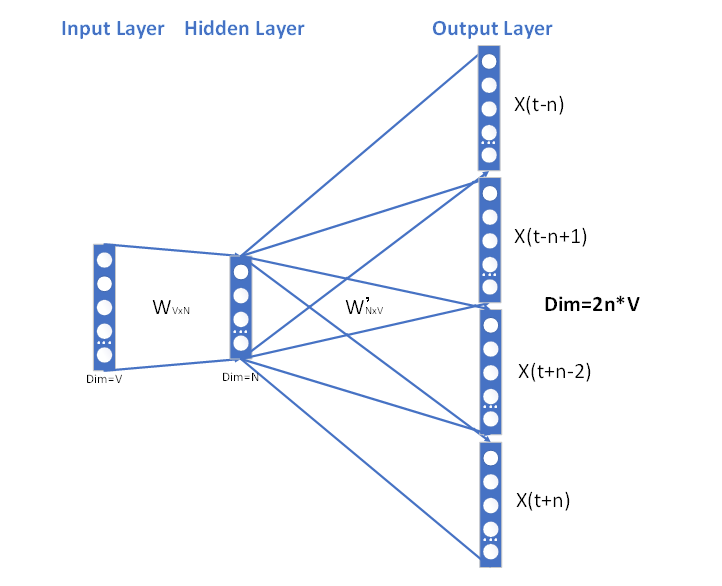
Skip Gram 模型
【隐含层】
- 在输入层到隐含层之间,包含语料中所有词汇的一份V行N列的权重矩阵W和参数b。
- 词汇的1行V列的
one-hot编码通过向W矩阵点乘,在隐含层获得该词汇的1行N列的词向量C(t),这一经典过程,实现了高维词汇向低维向量空间的转换,也叫 “词嵌入”。
在编程实现时,也叫“查表”,本质原因是输入词汇的one-hot编码中永远仅含一位寄存位为1,则权重矩阵W中对应行便是该词汇的词向量。
其中,权重矩阵W初始化时,可为任意实数值。
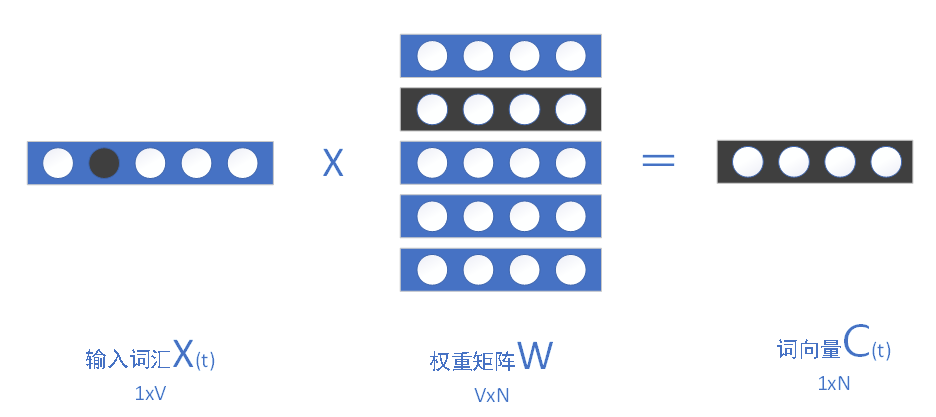
词嵌入原理
【输出层】
- 对于输入的
当前词汇X(t),在隐含层中转换为词向量C(t); - 隐含层到输出层之间,存在另一N行V列的隐含权重矩阵
W', - 在隐含层到输出层之间建立新的映射Y,其中:
Y=〖W'C〗^T+b。 - 最终,在当前词汇的上下文窗口中获得预测的上下文词汇
Y(t-n),Y(t-n+1),…,Y(t-1),Y(t+1),…,Y(t+n)。
【训练的目标】
- 在该模型中,每次学习的目标是最大化对数似然函数,见公式(x)。

- 通过反复训练的过程中迭代更新权重矩阵
W和W',最终学习得到包含词汇表中所有词向量的权重矩阵W。
Word2Vec 词向量模型的构建过程、使用过程
默认,依赖于gensim的Word2Vec算法模块,实现词向量模型的构建
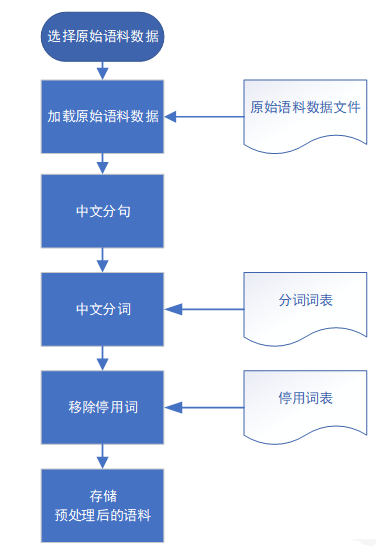
Step1 加载原始新闻语料
Step2 语料预处理
- 处理后的语料格式必须符合一行一句,句内词汇间空格隔开的数据格式。
articlesFilesSavePath = "E:/dataset/corpusWords/news2016/";
corpusReader.handleArticlesToSentencesWordsMatrixAsFilesSave(articlesFilesSavePath,maxArticleSize=100000,encoding="utf-8"); # 预处理
Step3 模型的预训练
- 选择Word2Vec模型策略,并训练模型。系统中采用了基于Skip-Gram模型,窗口大小为10,词向量维数为100,线程数为30,迭代计算5次的训练策略。
sentences=gensim.models.word2vec.PathLineSentences( articlesFilesSavePath,max_sentence_length=10000,limit=None);
model=gensim.models.Word2Vec(sentences,size=100,window=10,sg=1,workers=30, iter=5);
Step4 词向量模型的持久化
- 存储训练完成的词向量模型。词向量模型构建完成。
saveNews2016CorpusWord2VecModelFilePath = r"E:\\dataset\model\news2016- 2019-05 23-1501-sg-1 -size- 100-iter- 5-model";
model.save(saveNews2016CorpusWord2VecModelFilePath);
Step5 加载预训练的词向量模型,并使用
- 加载预训练的词向量模型,并初步检测训练效果。
model=gensim.models.Word2Vec.load( saveNews2016CorpusWord2VecModelFilePath ); # 加载模型
print(model.similarity(words[0],words[3])); # 查看某两词汇的相似度
print(model[words[i]]); # 查询某词汇的词向量 1x100维
print(model.most_similar(words[i]),topn=5); # 与当前词欧式距离最相近的词汇
重要API/类
- gensim.models.KeyedVectors
- gensim.models.word2vec
- gensim.models.word2vec.Word2Vec(sentences,min_count,size,worker)
- gensim.models.Word2Vec(sentences,min_count,size,worker)
Word2Vec类:构建Word2Vec词向量模型

四 Word2Vec 详解
- 注:标题前带阿拉伯数字标号的内容,便是使用Gensim的Word2Vec模型过程中的完整流程序号,通常也较为常用且重要。
1 加载语料库
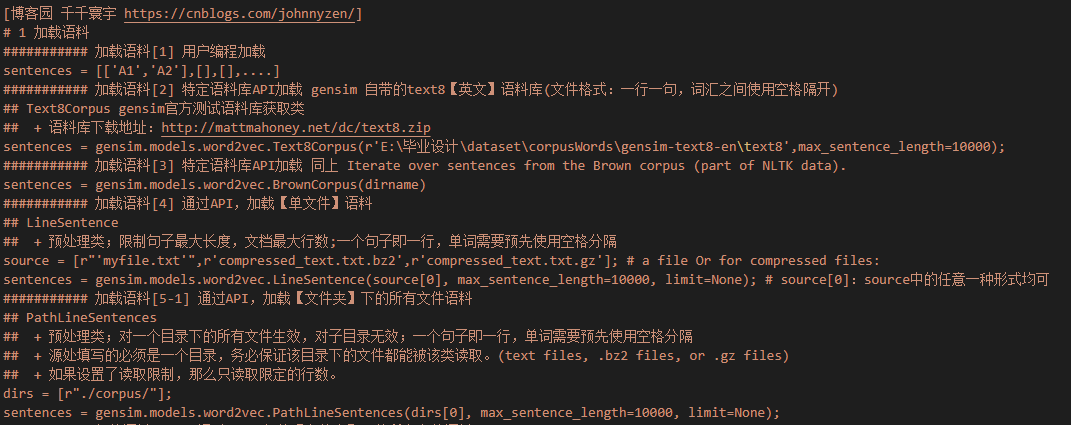
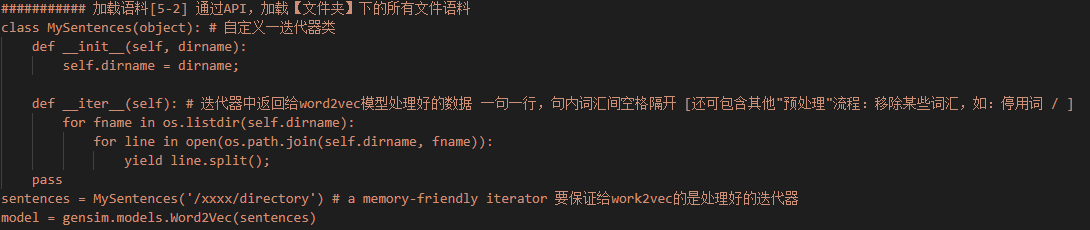
2 (初次)训练

手动构建词汇表

3 追加训练(更新模型)

4 存储模型

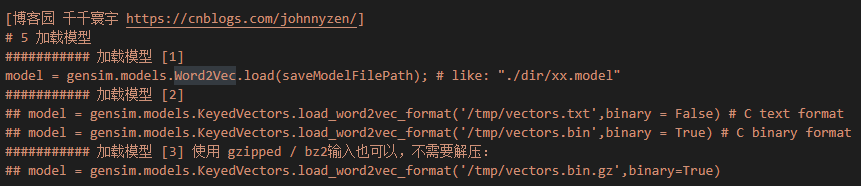
5 加载模型
6 获取词向量

加载词向量

7 模型应用

8 模型评估

五 补充
- 欢迎探讨,欢迎Follow~

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号