[Python/NLP] 中文自然语言处理工具库:SnowNLP(情感分析/分词/自动摘要)
一 安装与介绍
1.1 概述
-
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。 -
SnowNLP
1.2 特点

# s as SnowNLP(text)
1) s.words 词语
2) s.sentences 句子/分句
3) s.sentiments 情感偏向,0-1之间的浮点数,越靠近1越积极(正面)
4) s.pinyin 转为拼音
5) s.han 转为简体
6) s.keywords(n) 提取关键字,n默认为5
7) s.summary(n) 提取摘要,n默认为5
8) s.tf 计算term frequency词频
9) s.idf 计算inverse document frequency逆向文件频率
10) s.sim(doc,index) 计算相似度
1.3 安装
pip install snownlp
二 模块解析
2.1 seg [分词模块]
分词库仍以jieba的中文分词效果最佳。
个人认为:jieba(多种分词模式/用户可自定义领域词汇) / pynlpir (二者可结合) >> snownlp
from snownlp import seg
from snownlp import SnowNLP
s = SnowNLP(u"今天我很快乐。你怎么样呀?");
print("[words]",s.words); # 分词
seg.train(trainDataFileOfPath); # 训练用户提供的自定义的新的训练分词词典的数据集
seg.save(targetDir+'seg2.marshal'); #保存训练后的模型
print(seg.data_path) # 查看 or 设置snownlp提供的默认分词的词典的路径
# [output]
[words] ['今天', '我', '很', '快乐', '。', '你', '怎么样', '呀', '?']
D:\Program Files (x86)\Anaconda3\lib\site-packages\snownlp\seg\seg.marshal
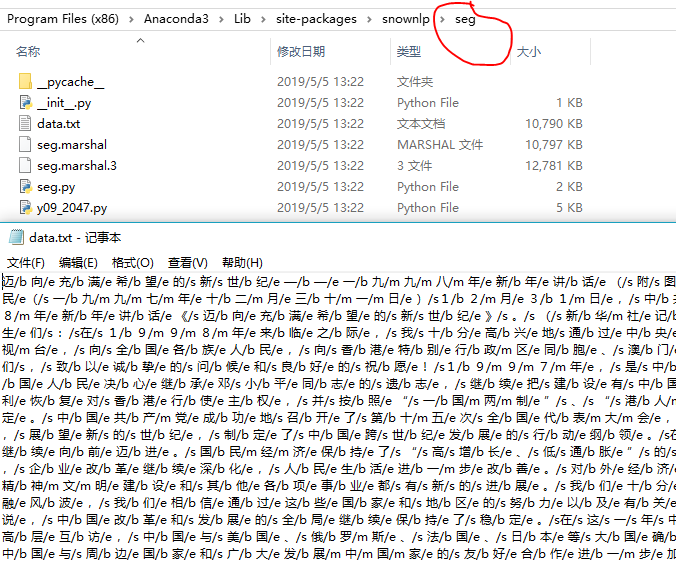
# 打开其目录seg中的data.txt:
迈/b 向/e 充/b 满/e 希/b 望/e 的/s 新/s 世/b 纪/e
中/b 共/m 中/m 央/e 总/b 书/m 记/e
# /b代表begin,/m代表middle,/e代表end,分别代表一个词语的开始,中间词和结尾,/s代表single,一个字是一个词的意思
2.2 sentiment [情感分析]
from snownlp import sentiment
s = SnowNLP(u"今天我很快乐。你怎么样呀?");
print("[sentiments]",s.sentiments); #情感性分析
sentiment.train(neg1.txt,pos1.txt); # 训练用户提供的自定义的新的训练分词词典的负面情感数据集和正面情感数据集
sentiment.save('sentiment2.marshal'); #保存训练后的模型
print(sentiment.data_path) # 查看 or 设置snownlp提供的默认情感分析模型的路径
# [output]
[sentiments] 0.971889316039116 #有博客博友推荐,设定 value>0.6:正面; value < 20%:负面; 反之:中性
D:\Program Files (x86)\Anaconda3\lib\site-packages\snownlp\sentiment\sentiment.marshal
2.3 summary [文本摘要]
算法基于TextRank。
from snownlp import summary
text=u"https://news.ifeng.com/c/7kdJkIAg 2OO2月26日,四川大学华西医院化妆品评价中心在微信公众号上发布了一条招募信息,希望招募有脱发困扰的试用者,来测试一款防脱育发液产品,该消息很快引发网友关注,北青报记者27日上午从华西医院工作人员处了解到,发布该消息仅一天时间,就已经有8000多人报名,但是医院实际上只需要30名试用者即可。据四川大学华西医院化妆品评价中心发布的消息显示,这次试用者招募有几项目要求,要求试用者年龄为18到60周岁,性别不限,有脱发困扰,目前未参加中心的其他项目。该招募信息称,试用者3月1日到中心领取育发液,回家试用,产品试用期为28天,每周五到中心回访,连续四周,同时,该实验还有相应的报酬。“现在被脱发困扰的人很多,又因为这条信息里有‘脱发’字样,所以很快引起了大家的关注,还上了微博热搜。”华西大学工作人员告诉北青报记者,“我27日上午了解了一下,到目前为止已经有8000多人报名了。”该工作人员表示,这次招募是医院的化妆品评价中心需要为一款产品做测试,需要30名左右的试用者,所以现在有这么多人报名,肯定是需要进行筛选的,“但是现在还无法统计报名的人主要集中地年龄段,不过现在脱发已经有年轻化的趋势,所以应该从18到60岁的报名者都有。这次入选的人会给发放一定的报酬,但是金额应该不会太多,主要是为了解决试用者来医院的交通费用等。”医院工作人员告诉北青报记者,华西医院化妆品评价中心经常会发布一些试用者招募活动,之前这些招募可能并未引起太多人的关注,“这次招募防脱育发液试用者,也让我们的其他招募受到了关注,很多项目都增加了很多报名的试用者。”北青报记者看到,医院的化妆品评价中心之前确实发不过许多试用者招募信息,例如“法国进口改善皮肤暗沉提高皮肤含水量产品招募试用者”、“皮肤封闭式斑贴实验项目志愿者招募”、“男士护肤品免费试用啦”等,对此,有网友表示,“找到了一条免费使用化妆品之路”。";
s = SnowNLP(text);
print("[summary]",s.summary(3));
# [output]
[summary] ['华西医院化妆品评价中心经常会发布一些试用者招募活动', '医院的化妆品评价中心之前确实发不过许多试用者招募信息', '希望招募有脱发困扰的试用者']
三 快速示例教程
# [code]
import os
from snownlp import SnowNLP
from snownlp import sentiment
from snownlp import seg
# snownlp - demo
text = [u"今天我很快乐。你怎么样呀?",u"苏宁易购,是谁给你们下架OV的勇气",u"恐怖",u"质量不太好"];
s = SnowNLP(text[2]) #载入文本
print("[words]",s.words); # 分词
print("[sentiments]",s.sentiments); #情感性分析
for sentence in s.sentences :#分句
print("[sentence]",sentence);
pass;
#sentiment.train('./neg.txt', './pos.txt');# 重新训练语料模型
#sentiment.save('sentiment.marshal'); # 保存好新训练的词典模型
print("[seg.data_path]",seg.data_path); # 查看seg子模块的词典位置
print("[sentiment.data_path]",sentiment.data_path); # 查看sentiment子模块的词典位置
#seg.data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'sentiment.marshal') # 设置词典位置
# [output]
[words] ['恐怖']
[sentiments] 0.293103448275862
[sentence] 恐怖
[seg.data_path] D:\Program Files (x86)\Anaconda3\lib\site-packages\snownlp\seg\seg.marshal
[sentiment.data_path] D:\Program Files (x86)\Anaconda3\lib\site-packages\snownlp\sentiment\sentiment.marshal
四 推荐文献
- SnowNLP

本文作者:
千千寰宇
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!
本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号