spark shuffle读操作
提出问题
1. shuffle过程的数据是如何传输过来的,是按文件来传输,还是只传输该reduce对应在文件中的那部分数据?
2. shuffle读过程是否有溢出操作?是如何处理的?
3. shuffle读过程是否可以排序、聚合?是如何做的?
。。。。。。
概述
在 spark shuffle的写操作之准备工作 中的 ResultTask 和 ShuffleMapTask 看到了,rdd读取数据是调用了其 iterator 方法。
计算或者读取RDD
org.apache.spark.rdd.RDD#iterator源码如下,它是一个final方法,只在此有实现,子类不允许重实现这个方法:

思路:如果是已经缓存下来了,则调用 org.apache.spark.rdd.RDD#getOrCompute 方法,通过底层的存储系统或者重新计算来获取父RDD的map数据。否则调用 org.apache.spark.rdd.RDD#computeOrReadCheckpoint ,从checkpoint中读取或者是通过计算来来获取父RDD的map数据。
我们逐一来看其依赖方法:
org.apache.spark.rdd.RDD#getOrCompute 源码如下:
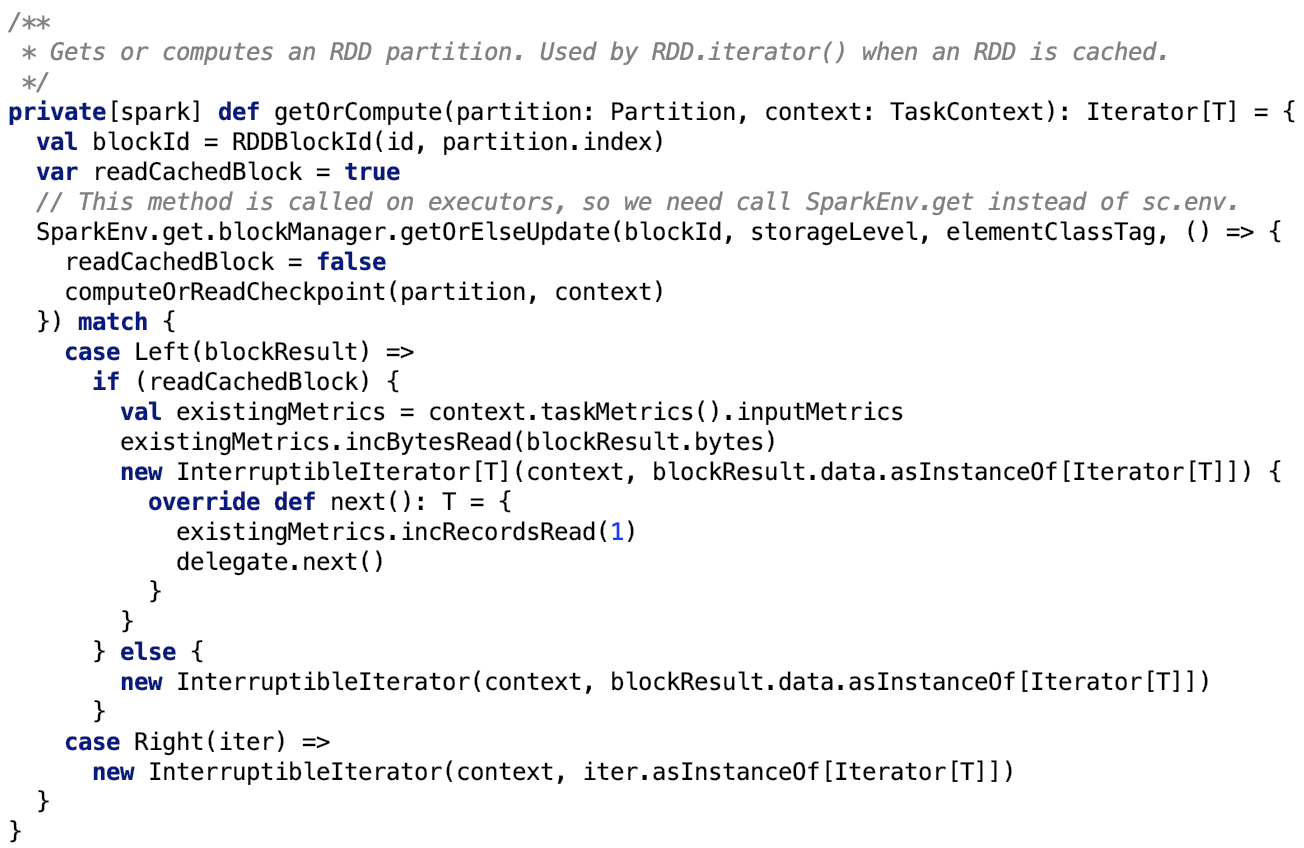
首先先通过Spark底层的存储系统获取 block。如果底层存储没有则调用 org.apache.spark.rdd.RDD#computeOrReadCheckpoint,其源码如下:

主要通过三种途径获取数据 -- 通过spark 底层的存储系统、通过父RDD的checkpoint、直接计算。
处理返回的数据
读取完毕之后,数据的处理基本上一样,都使用 org.apache.spark.InterruptibleIterator 以迭代器的形式返回,org.apache.spark.InterruptibleIterator 源码如下:

比较简单,使用委托模式,将迭代下一个行为委托给受委托类。
下面我们逐一来看三种获取数据的实现细节。
通过spark 底层的存储系统
其核心源码如下:

思路:首先先从本地或者是远程executor中的存储系统中获取到block,如果是block存在,则直接返回,如果不存在,则调用 computeOrReadCheckpoint计算或者通过读取父RDD的checkpoint来获取RDD的分区信息,并且将根据其持久化级别(即StorageLevel)将数据做持久化。 关于持久化的内容 可以参考 Spark 源码分析系列 中的 Spark存储部分 做深入了解。
通过父RDD的checkpoint
其核心源码如下:
![]()
通过父RDD的checkpoint也是需要通过spark底层存储系统或者是直接计算来得出数据的。
不做过多的说明。
下面我们直接进入主题,看shuffle的读操作是如何进行的。
直接计算
其核心方法如下:
![]()
首先,org.apache.spark.rdd.RDD#compute是一个抽象方法。
我们来看shuffle过程reduce的读map数据的实现。
表示shuffle结果的是 org.apache.spark.rdd.ShuffledRDD。
其compute 方法如下:

整体思路:首先从 shuffleManager中获取一个 ShuffleReader 对象,并调用该reader对象的read方法将数据读取出来,最后将读取结果强转为Iterator[(K,C)]
该shuffleManager指的是org.apache.spark.shuffle.sort.SortShuffleManager。
其 getReader 源码如下:

简单来说明一下参数:
handle:是一个ShuffleHandle的实例,它有三个子类,可以参照 spark shuffle的写操作之准备工作 做深入了解。
startPartition:表示开始partition的index
endPartition:表示结束的partition的index
context:表示Task执行的上下文对象
其返回的是一个 org.apache.spark.shuffle.BlockStoreShuffleReader 对象,下面直接来看这个对象。
BlockStoreShuffleReader
这个类的继承关系如下:
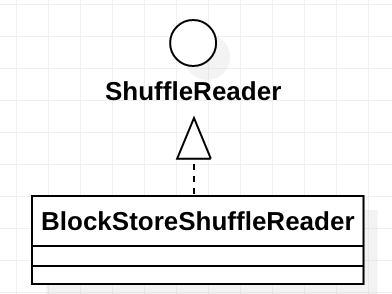
其中ShuffleReader的说明如下:
Obtained inside a reduce task to read combined records from the mappers.
ShuffleReader只有一个read方法,其子类BlockStoreShuffleReader也比较简单,也只有一个实现了的read方法。
下面我们直接来看这个方法的源码。

在上图,把整个流程划分为5个步骤 -- 获取block输入流、反序列化输入流、添加监控、数据聚合、数据排序。
下面我们分别来看这5个步骤。这5个流程中输入流和迭代器都没有把大数据量的数据一次性全部加载到内存中。并且即使在数据聚合和数据排序阶段也没有,但是会有数据溢出的操作。我们下面具体来看每一步的具体流程是如何进行的。
获取block输入流
其核心源码如下:

我们先来对 ShuffleBlockFetcherIterator 做进一步了解。
使用ShuffleBlockFetcherIterator获取输入流
这个类就是用来获取block的输入流的。
blockId等相关信息传入构造方法
其构造方法如下:

它继承了Iterator trait,是一个 [(BlockId,InputStream)] 的迭代器。
对构造方法参数做进一步说明:
context:TaskContext,是作业执行的上下文对象
shuffleClieent:默认为 NettyBlockTransferService,如果使用外部shuffle系统则使用 ExternalShuffleClient
blockManager:底层存储系统的核心类
blocksByAddress:需要的block的blockManager的信息以及block的信息。
通过 org.apache.spark.MapOutputTracker#getMapSizesByExecutorId 获取,其源码如下:
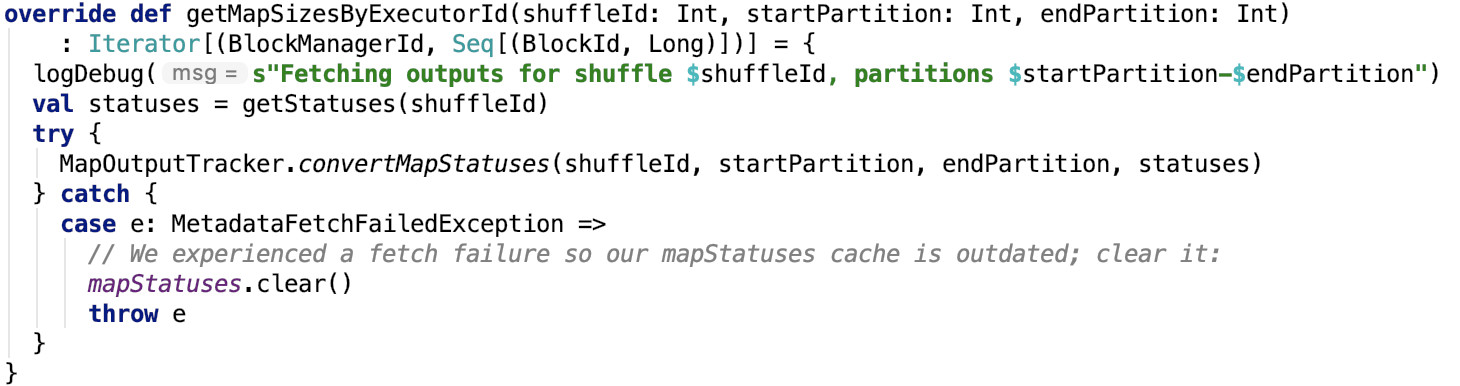
org.apache.spark.MapOutputTrackerWorker#getStatuses 其源码如下:

思路:如果有shuffleId对应的MapStatus则返回,否则使用 MapOutputTrackerMasterEndpointRef 请求 driver端的 MapOutputTrackerMaster 返回 对应的MapStatus信息。
org.apache.spark.MapOutputTracker#convertMapStatuses 源码如下:

思路:将MapStatus转换为一个可以迭代查看BlockManagerId、BlockId以及对应大小的迭代器。
streamWrapper:输入流的解密以及解压缩操作的包装器,其依赖方法 org.apache.spark.serializer.SerializerManager#wrapStream 源码如下:

这部分在 spark 源码分析之十三 -- SerializerManager剖析 部分有相关剖析,不再说明。
maxBytesInFlight: max size (in bytes) of remote blocks to fetch at any given point.
maxReqsInFlight: max number of remote requests to fetch blocks at any given point.
maxBlocksInFlightPerAddress: max number of shuffle blocks being fetched at any given point
maxReqSizeShuffleToMem: max size (in bytes) of a request that can be shuffled to memory.
detectCorrupt: whether to detect any corruption in fetched blocks.
读取数据
在迭代方法next中不断去读取远程的block以及本地的block输入流。不做详细剖析,见 ShuffleBlockFetcherIterator.scala 中next 相关方法的剖析。
反序列化输入流
核心方法如下:

其依赖方法 scala.collection.Iterator#flatMap 源码如下:

可见,即使是在这里,数据并没有全部落到内存中。流跟管道的概念很类似,数据并没有一次性加载到内存中。它只不过是在使用迭代器的不断衔接,最终形成了新的处理链。在这个链中的每一个环节,数据都是懒加载式的被加载到内存中,这在处理大数据量的时候是一个很好的技巧。当然也是责任链的一种具体实现方式。
添加监控
其实这一步跟上一步本质上区别并不大,都是在责任链上添加了一个新的环节,其核心源码如下:

其中,核心方法 scala.collection.Iterator#map 源码如下:

又是一个新的迭代器处理环节被加到责任链中。
数据聚合
数据聚合其实也很简单。
其核心源码如下:

在聚合的过程中涉及到了数据的溢出操作,如果有溢出操作还涉及 ExternalSorter的溢出合并操作。
其核心源码不做进一步解释,有兴趣可以看 spark shuffle写操作三部曲之SortShuffleWriter 做进一步了解。
数据排序
数据排序其实也很简单。如果使用了排序,则使用ExternalSorter则在分区内部进行排序。
其核心源码如下:
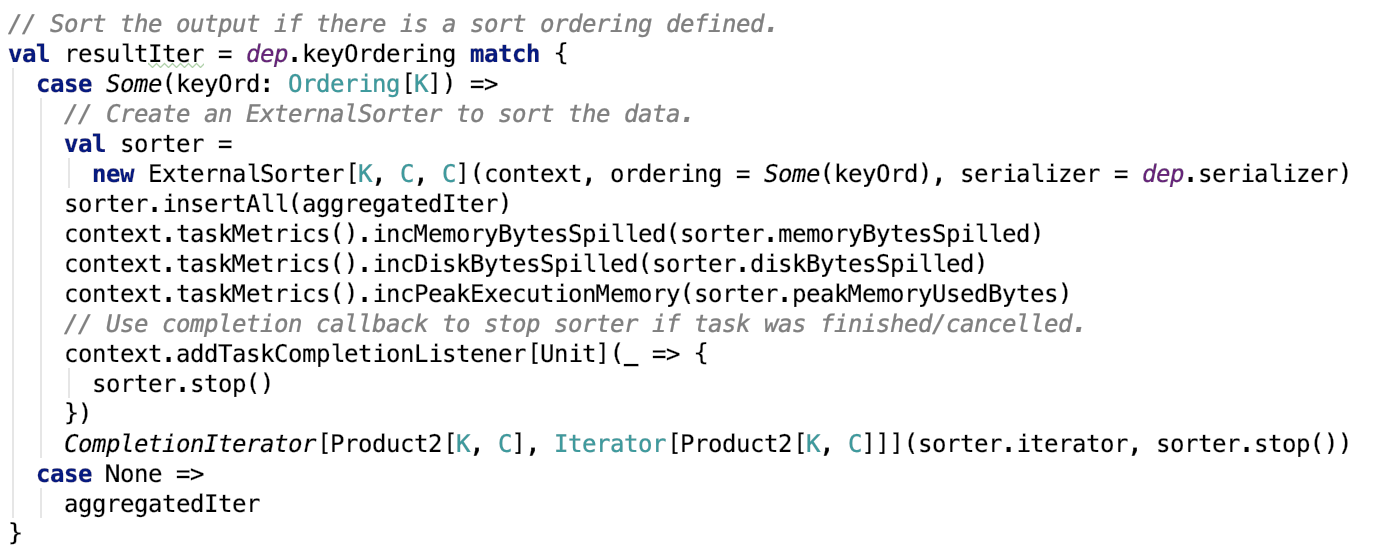
其内部使用了ExternalSorter进行排序,其中也涉及到了溢出操作的处理。有兴趣可以看 spark shuffle写操作三部曲之SortShuffleWriter 做进一步了解。
总结
主要从实现细节和设计思路上来说。
实现细节
首先在实现细节上,先使用ShuffleBlockFetcherIterator获取本地或远程节点上的block并转化为流,最终返回一小部分数据的迭代器,随后序列化、解压缩、解密流操作被放在一个迭代器中该迭代器后执行,然后添加了监控相关的迭代器、数据聚合相关的迭代器、数据排序相关的迭代器等等。这些迭代器保证了处理大量数据的高效性,在数据聚合和排序阶段,大数据量被不断溢出到磁盘中,数据最终还是以迭代器形式返回,确保了内存不会被大数据量占用,提高了数据的吞吐量和处理数据的高效性。
设计思路
在设计上,主要说三点:
- 责任链和迭代器的混合使用,即使得程序易扩展,处理环节可插拔,处理流程清晰易懂。
- 关于聚合和排序的使用,在前面文章中shuffle写操作也提到了,聚合和排序的类是独立出来的,跟shuffle的处理耦合性很低,这使得在shuffle的读和写阶段的数据内存排序聚合溢出操作的处理类可以重复使用。
- shuffle数据的设计也很巧妙,shuffle的数据是按reduceId分区的,分区信息被保存在索引文件中,这使得每一个reduce task只需要取得一个文件中属于它分区的那部分shuffle数据就可以了,极大地减少无用了数据量的网络传输,提高了shuffle的效率。还值得说的是,shuffle数据的格式是一个约定,不管map阶段的数据是如何被处理,最终数据形式肯定是约定好的,这使得map和reduce阶段的处理类之间的耦合性大大地降低。
至此,spark 的shuffle阶段的细节就彻底剖析完毕。
最后,明天周末,玩得开心~

