spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系。
总述
先看 BlockManager相关类之间的关系如下:

我们从NettyRpcEnv 开始,做一下简单说明。
NettyRpcEnv是Spark 的默认的RpcEnv实现,它提供了个Spark 集群各个节点的底层通信环境,可以参照文章 spark 源码分析之十二--Spark RPC剖析之Spark RPC总结 做深入了解。
MemoryManager 主要负责Spark内存管理,可以参照 spark 源码分析之十五 -- Spark内存管理剖析做深入了解。
MemoryStore 主要负责Spark单节点的内存存储,可以参照 spark 源码分析之十六 -- Spark内存存储剖析 做深入了解。
DiskStore 主要负责Spark单节点的磁盘存储,可以参照 spark 源码分析之十七 -- Spark磁盘存储剖析 做深入了解。
SecurityManager 主要负责底层通信的安全认证。
BlockManagerMaster 主要负责在executor端和driver的通信,封装了 driver的RpcEndpointRef。
NettyBlockTransferService 使用netty来获取一组数据块。
MapOutputTracker 是一个跟踪 stage 的map 输出位置的类,driver 和 executor 有对应的实现,分别是 MapOutputTrackerMaster 和 MapOutputTrackerWorker。
ShuffleManager在SparkEnv中初始化,它在driver端和executor端都有,负责driver端生成shuffle以及executor的数据读写。
BlockManager 是Spark存储体系里面的核心类,它运行在每一个节点上(drievr或executor),提供写或读本地或远程的block到各种各样的存储介质中,包括磁盘、堆内内存、堆外内存。
下面我们剖析一下之前没有剖析过,图中有的类:
SecurityManager
概述
类说明如下:
Spark class responsible for security. In general this class should be instantiated by the SparkEnv and most components should access it from that.
There are some cases where the SparkEnv hasn't been initialized yet and this class must be instantiated directly.
This class implements all of the configuration related to security features described in the "Security" document.
Please refer to that document for specific features implemented here.
这个类主要就是负责Spark的安全的。它是由SparkEnv初始化的。
类结构
其结构如下:
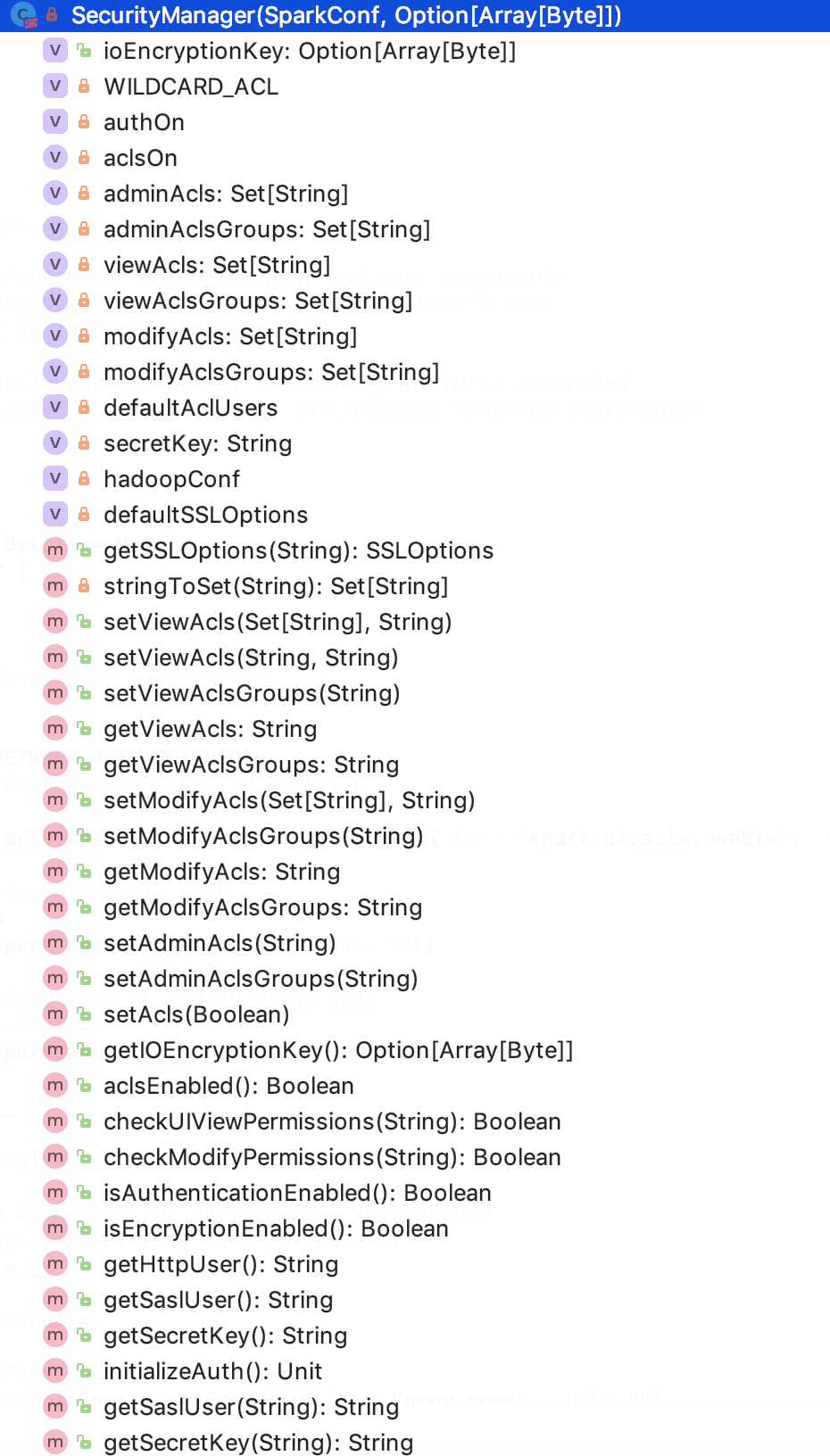
成员变量
WILDCARD_ACL:常量为*,表示允许所有的组或用户拥有查看或修改的权限。
authOn:表示网络传输是否启用安全,由参数 spark.authenticate控制,默认为 false。
aclsOn:表示,由参数 spark.acls.enable 或 spark.ui.acls.enable 控制,默认为 false。
adminAcls:管理员权限,由 spark.admin.acls 参数控制,默认为空字符串。
adminAclsGroups:管理员所在组权限,由 spark.admin.acls.groups 参数控制,默认为空字符串。
viewAcls:查看控制访问列表用户。
viewAclsGroups:查看控制访问列表用户组。
modifyAcls:修改控制访问列表用户。
modifyAclsGroups:修改控制访问列表用户组。
defaultAclUsers:默认控制访问列表用户。由user.name 参数和 SPARK_USER环境变量一起设置。
secretKey:安全密钥。
hadoopConf:hadoop的配置对象。
defaultSSLOptions:默认安全选项,如下:

其中SSLOption的parse 方法如下,主要用于一些安全配置的加载:

defaultSSLOptions跟getSSLOptions方法搭配使用:

核心方法
1. 设置获取 adminAcls、viewAclsGroups、modifyAcls、modifyAclsGroups变量的方法,比较简单,不再说明。
2. 检查UI查看的权限以及修改权限:

3. 获取安全密钥:

4. 获取安全用户:

5. 初始化安全:
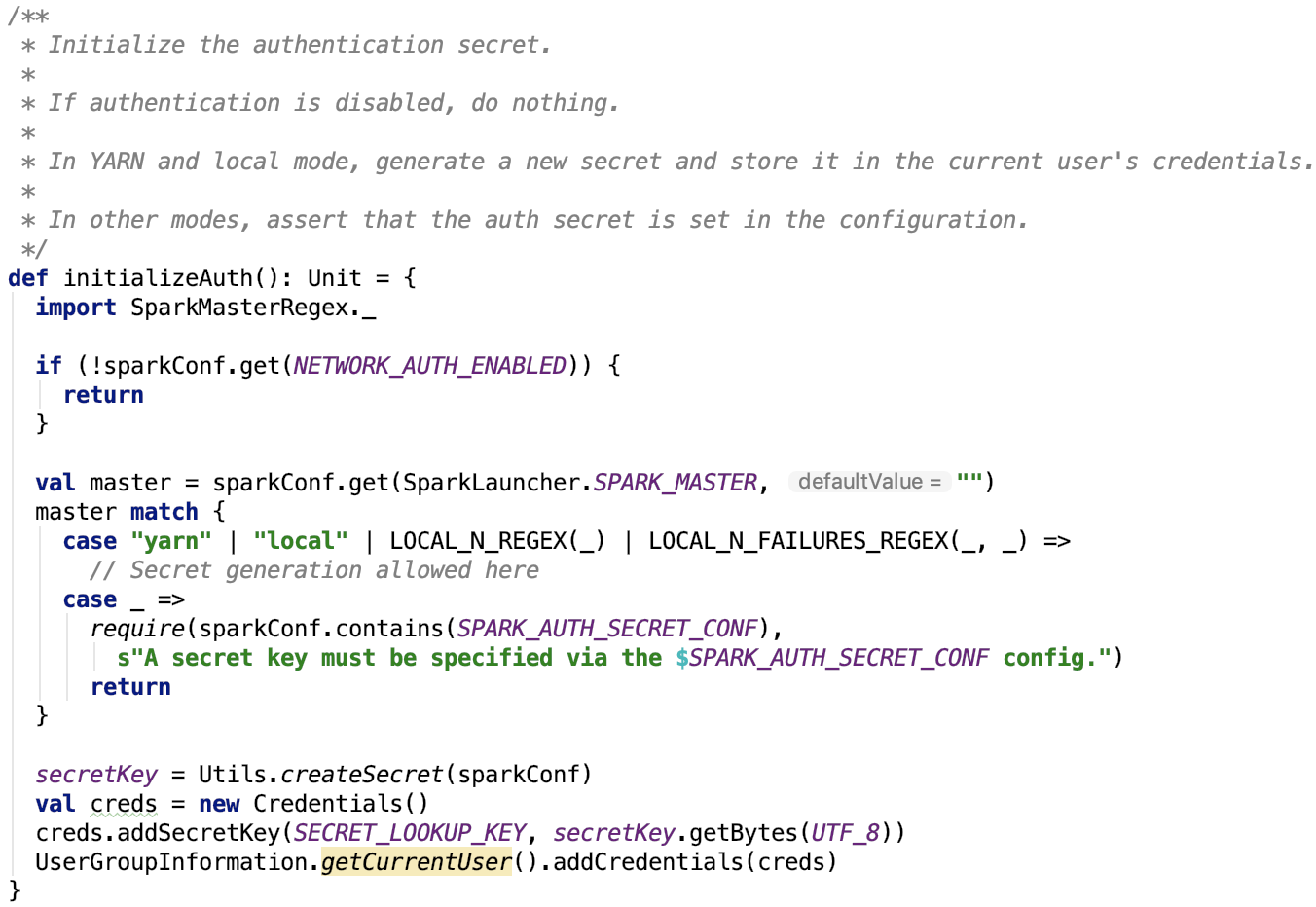
总结
这个类主要是用于Spark安全的,主要包含了权限的设置和获取的方法,密钥的获取、安全用户的获取、权限验证等功能。
下面来看一下BlockManagerMaster类。
BlockManagerMaster
概述
BlockManagerMaster 这个类是对 driver的 EndpointRef 的包装,可以说是 driver EndpointRef的一个代理类,在请求访问driver的时候,调用driver的EndpointRef的对应方法,并处理其返回。
类结构
其类结构如下:
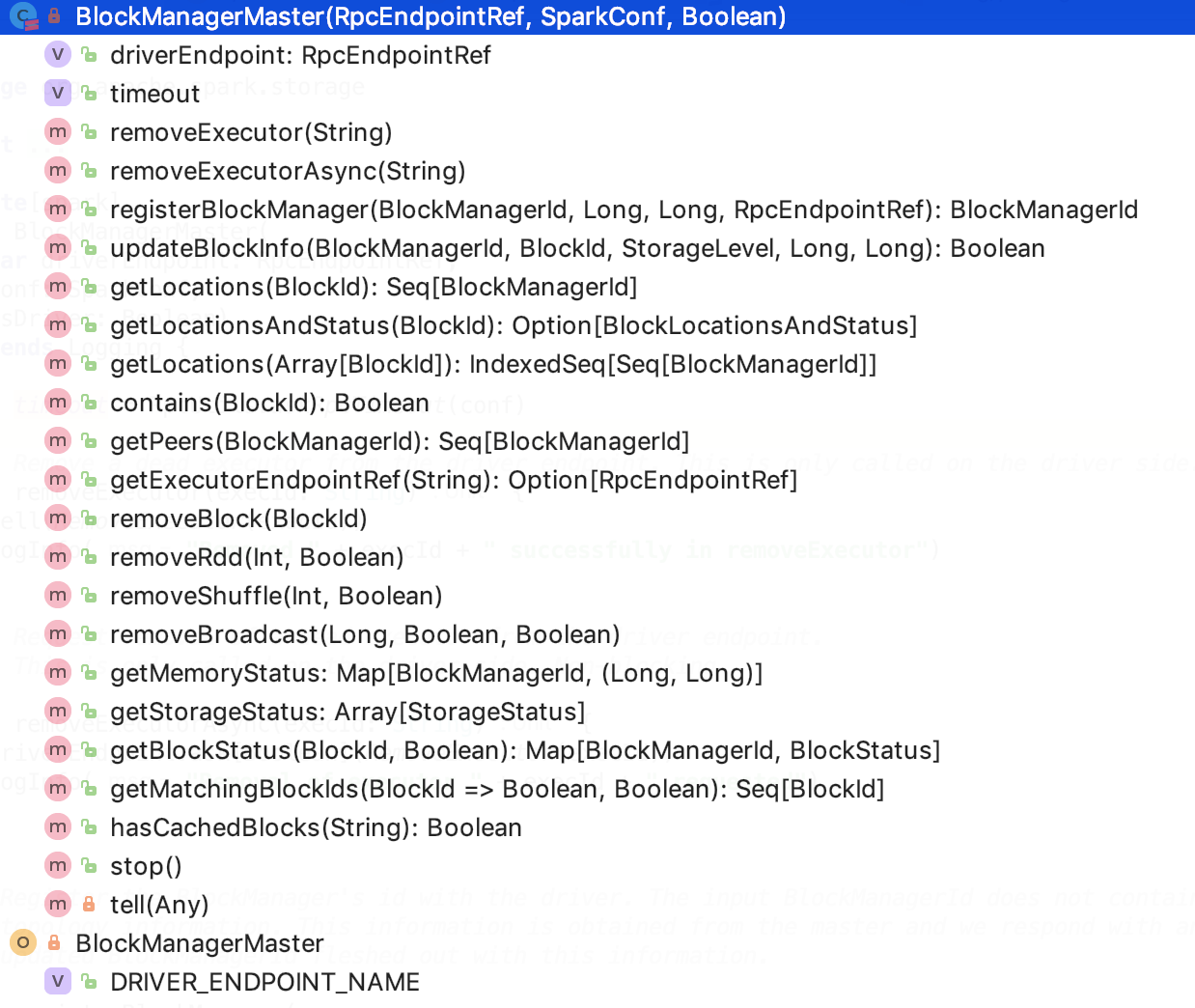
主要是一些通过driver获取的节点或block、或BlockManager信息的功能函数。
成员变量
driverEndpoint是一个EndpointRef 对象,可以指本地的driver 的endpoint 或者是远程的 endpoint引用,通过它既可以和本地的driver进行通信,也可以和远程的driver endpoint 进行通信。
timeout 是指的 Spark RPC 超时时间,默认为 120s,可以通过spark.rpc.askTimeout 或 spark.network.timeout 参数来设置。
核心方法:
1. 移除executor,有同步和异步两种方案,这两个方法只会在driver端使用。如下:

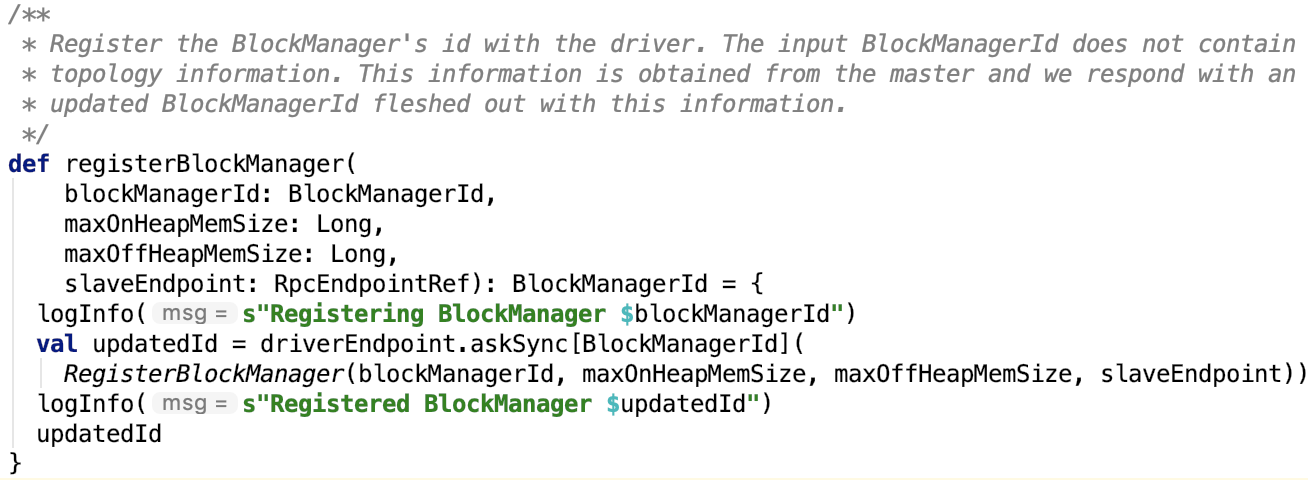
2. 向driver注册blockmanager
3. 更新block信息

4. 向driver请求获取block对应的 location信息

5. 向driver 请求获得集群中所有的 blockManager的信息

4. 向driver 请求executor endpoint ref 对象
![]()
5. 移除block、RDD、shuffle、broadcast
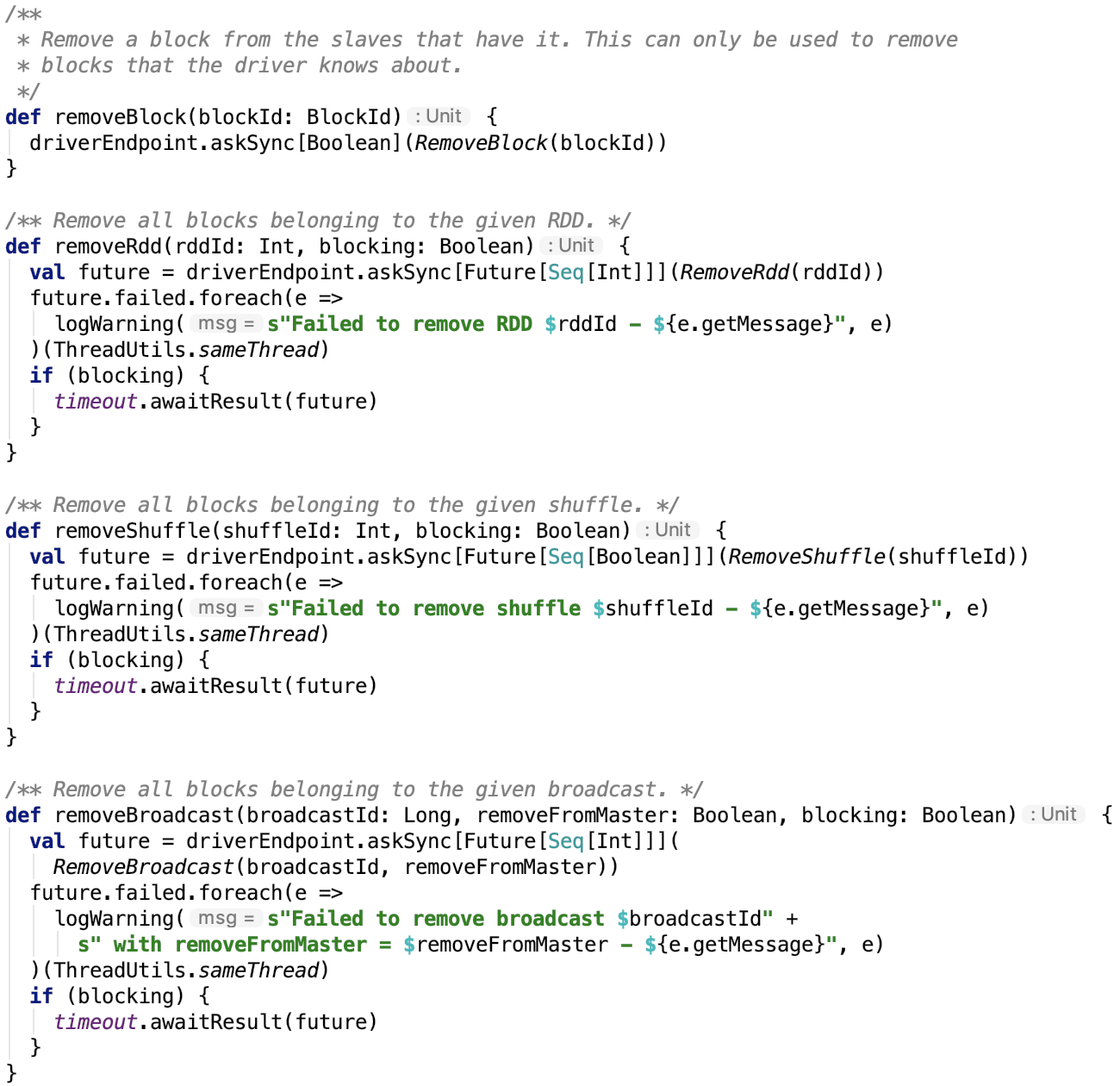
6. 向driver 请求获取每一个BlockManager内存状态

7. 向driver请求获取磁盘状态
![]()
8. 向driver请求获取block状态

9. 是否有匹配的block
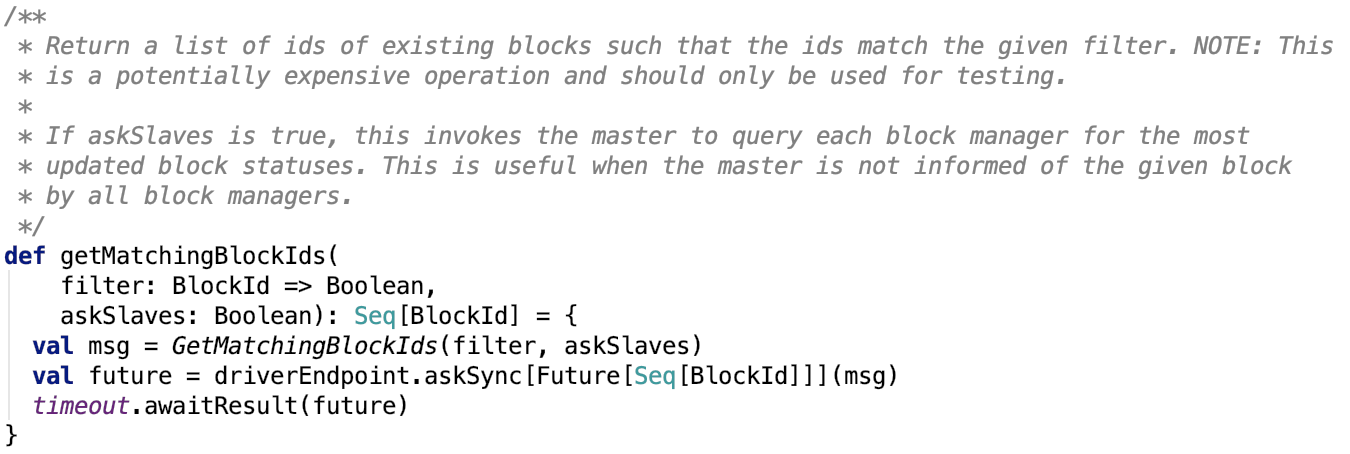
10.检查是否缓存了block

其依赖方法tell 方法如下:

总结
BlockManagerMaster 主要负责和driver的交互,来获取跟底层存储相关的信息。
ShuffleClient
类说明
它定义了从executor或者是外部服务读取shuffle数据的接口。

核心方法
1. init方法用于初始化ShuffleClient,需要指定executor 的appId
2. fetchBlocks 用于异步从另一个节点请求获取blocks,参数解释如下:
host – the host of the remote node.
port – the port of the remote node.
execId – the executor id.
blockIds – block ids to fetch.
listener – the listener to receive block fetching status.
downloadFileManager – DownloadFileManager to create and clean temp files. If it's not null, the remote blocks will be streamed into temp shuffle files to reduce the memory usage, otherwise, they will be kept in memory.
3. shuffleMetrics 用于记录shuffle相关的metrics信息
BlockTransferService
类说明
它是ShuffleClient的子类。它是ShuffleClient的抽象实现类,定义了读取shuffle的基础框架。

核心方法
init 方法,它额外提供了使用BlockDataManager初始化的方法,方便从本地获取block或者将block存入本地。
close:关闭ShuffleClient
port:服务正在监听的端口
hostname:服务正在监听的hostname
fetchBlocks 跟继承类一样,没有实现,由于继承关系可以不写。
uploadBlocks:上传block到远程节点,返回一个future对象
fetchBlockSync:同步抓取远程节点的block,直到block数据获取成功才返回,如下:

它定义了block 抓取后,对返回结果处理的基本框架。
uploadBlockSync 方法:同步上传信息,直到上传成功才结束。如下:
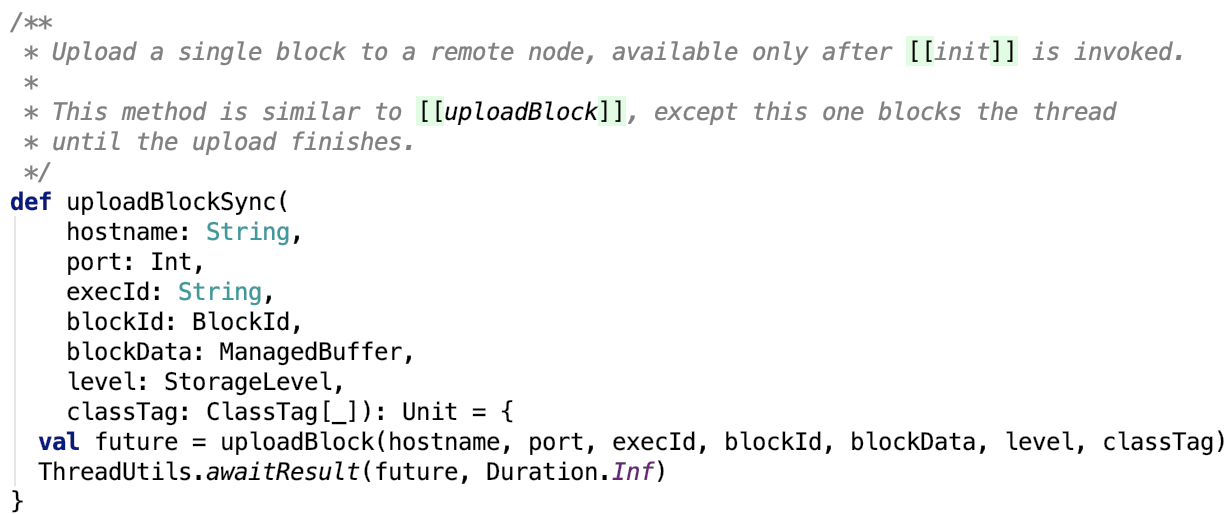
ManagedBuffer的三个子类
在 spark 源码分析之十七 -- Spark磁盘存储剖析 中已经提及过ManagedBuffer类。
下面看一下ManagedBuffler的三个子类:FileSegmentManagedBuffer、EncryptedManagedBuffer、NioManagedBuffer
FileSegmentManagedBuffer:由文件中的段支持的ManagedBuffer。
EncryptedManagedBuffer:由加密文件中的段支持的ManagedBuffer。
NioManagedBuffer:由ByteBuffer支持的ManagedBuffer。
NettyBlockTransferService
类说明:
它是BlockTransferService,使用netty来一次性获取shuffle的block数据。

成员变量
hostname:TransportServer 监听的hostname
serializer:JavaSerializer 实例,用于序列化反序列化java对象。
authEnabled:是否启用安全
transportConf:TransportConf 对象,主要是用于初始化shuffle的线程数等配置。,spark.shuffle.io.serverThreads 和 spark.shuffle.io.clientThreads,默认是线程数在 [1,8] 个,这跟可用core的数量和指定core数量有关。 这两个参数决定了底层netty server端和client 端的线程数。
transportContext:TransportContext 用于创建TransportServer和TransportClient的上下文。
server:TransportServer对象,是Netty的server端线程。
clientFactory:TransportClientFactory 用于创建TransportClient
appId:application id,由 spark.app.id 参数指定
核心方法
1. init 方法主要用于初始化底层netty的server和client,如下:
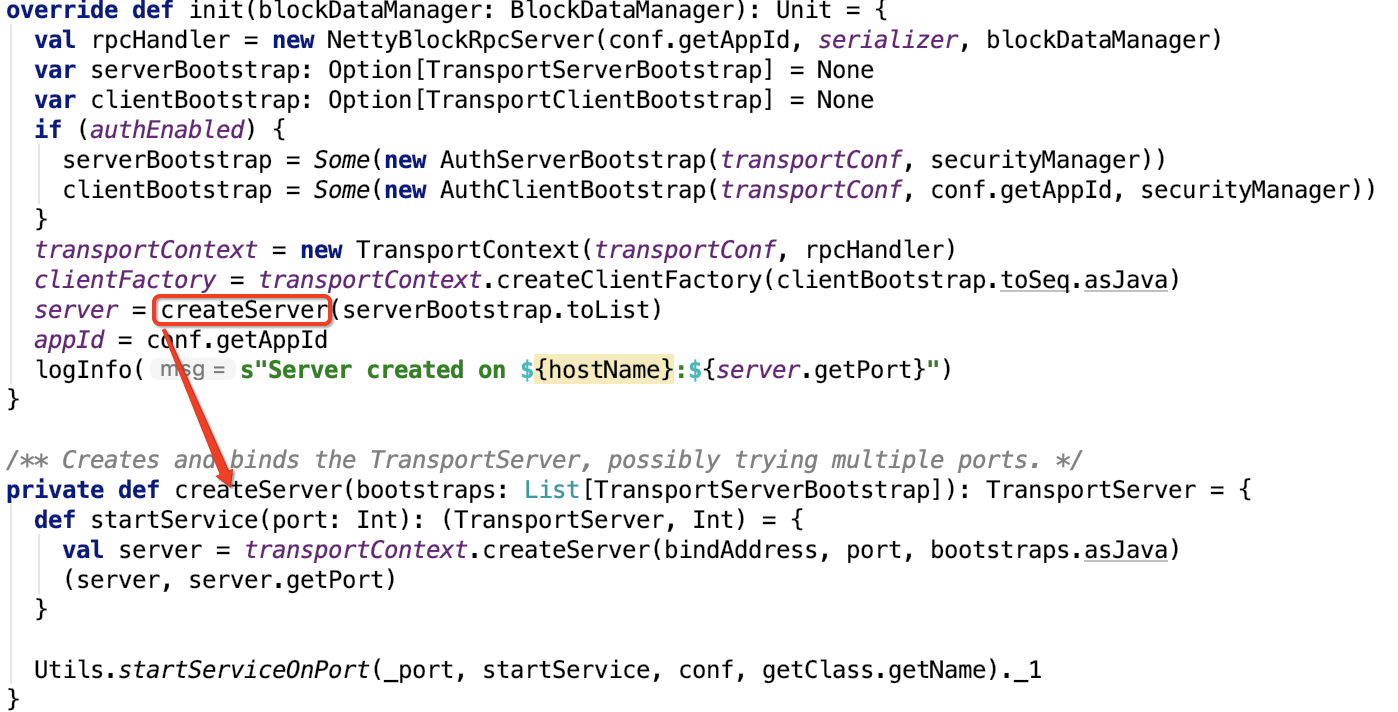
关于底层RPC部分的内容,在Spark RPC 剖析系列已经做过说明,参照 spark 源码分析之十二--Spark RPC剖析之Spark RPC总结 做进一步了解。
2. 关闭ShuffleClient:

3. 上传数据:

config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM 是由spark.maxRemoteBlockSizeFetchToMem参数决定的,默认是 整数最大值 - 512.
所以整数范围内的block数据,是由 netty RPC来处理的,128MB显然是在整数范围内的,所以hdfs上的block 数据spark都是通过netty rpc来通信传输的。
4. 从远程节点获取block数据,源码如下:
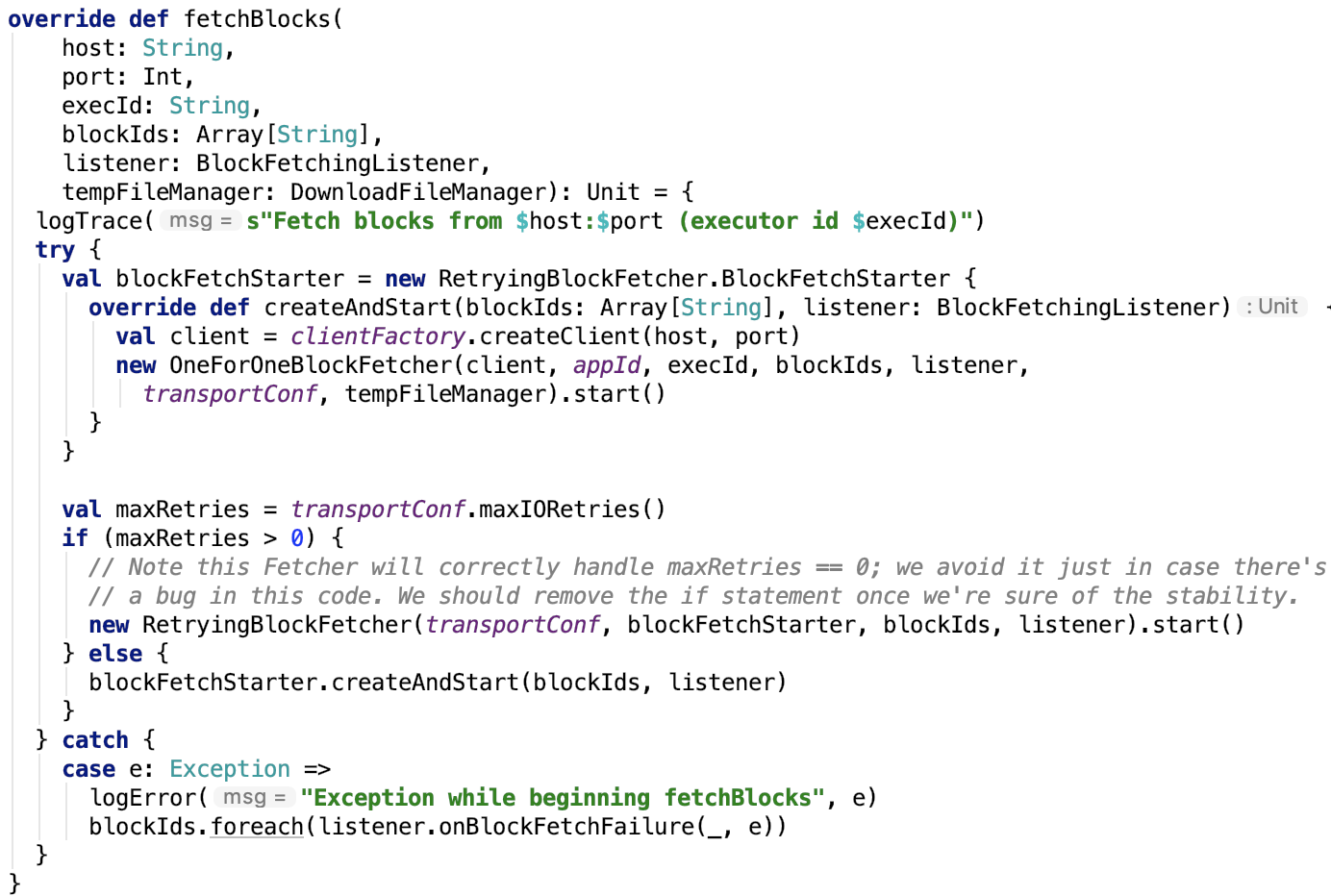
首先数据抓取是可以支持重试的,重试次数默认是3次,可以由参数 spark.shuffle.io.maxRetries 指定,实际上是由OneForOneBlockFetcher来远程抓取数据的。
重试抓取远程block机制的设计
当重试次数不大于0时,直接使用的是BlockFetchStarter来生成 OneForOneBlockFetcher 抓取数据。
当次数大于0 时,则使用 RetryingBlockFetcher 来重试式抓取数据。
先来看一下其成员变量:
executorService: 用于等待执行重试任务的共享线程池
fetchStarter:初始化 OneForOneBlockFetcher 对象
listener:监听抓取block成功或失败的listener
maxRetries;最大重试次数。
retryWaitTime:下一次重试间隔时间。可以通过 spark.shuffle.io.retryWait参数设置,默认是 5s。
retryCount:已重试次数。
outstandingBlocksIds:剩余需要抓取的blockId集合。
currentListener:它只监听当前fetcher的返回。
核心方法:
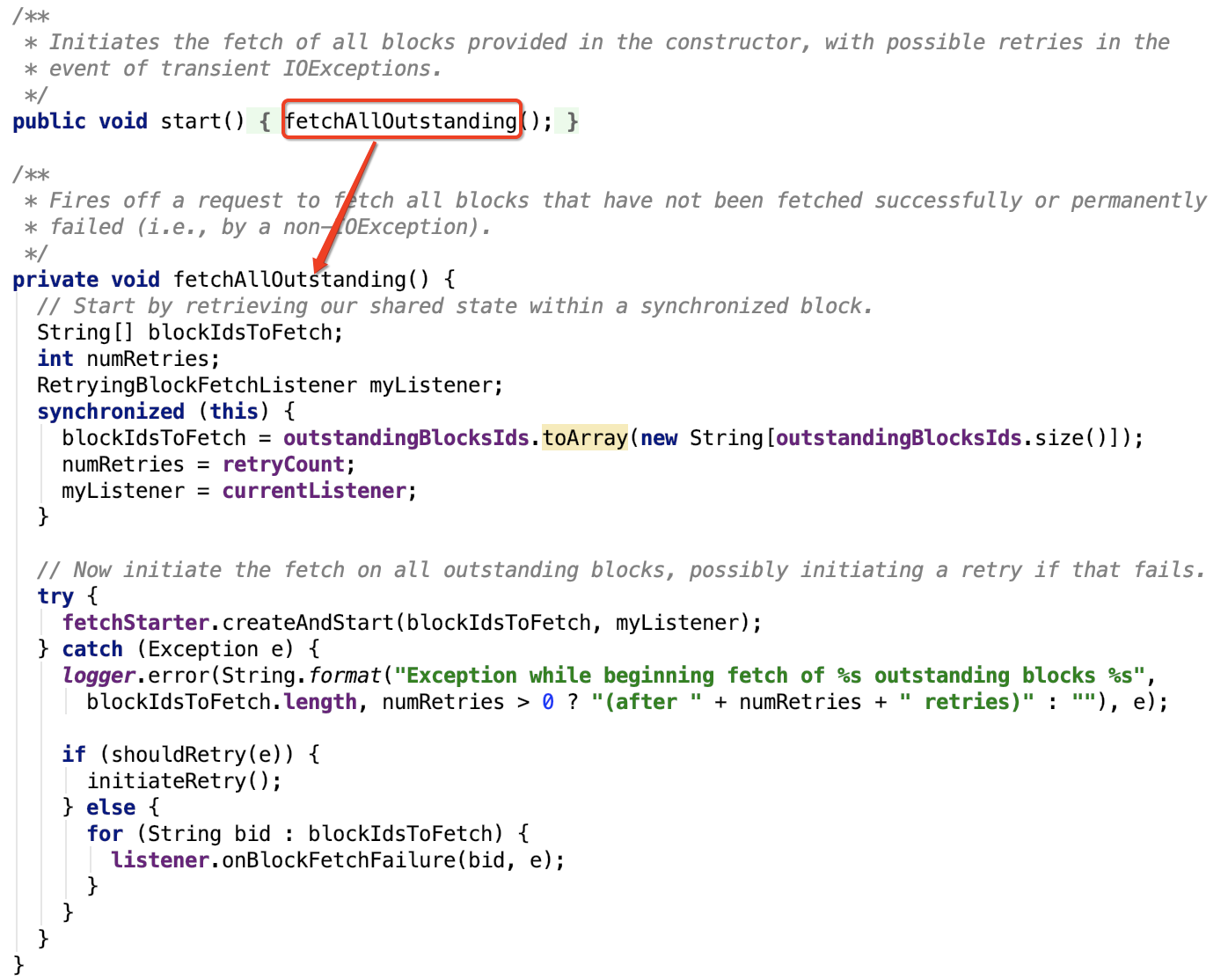
思路:首先,初始化需要抓取的blockId列表,已重试次数,以及currentListener。然后去调用fetcherStarter开始抓取任务,每一个block抓取成功后,都会调用currentListener对应成功方法,失败则会调用 currentListener 失败方法。在fetch过程中数据有异常出现,则先判断是否需要重试,若需重试,则初始化重试,将wait和fetch任务放到共享线程池中去执行。
下面看一下,相关方法和类:
1. RetryingBlockFetchListener 类。它有两个方法,一个是抓取成功的回调,一个是抓取失败的回调。
在抓取成功回调中,会先判断当前的currentListener是否是它本身,并且返回的blockId在需要抓取的blockId列表中,若两个条件都满足,则会从需要抓取的blockId列表中把该blockId移除并且去调用listener相对应的抓取成功方法。
在抓取失败回调中,会先判断当前的currentListener是否是它本身,并且返回的blockId在需要抓取的blockId列表中,若两个条件都满足,再判断是否需要重试,如需重试则重置重试机制,否则直接调用listener的抓取失败方法。

2. 是否需要重试:

思路:如果是IO 异常并且还有剩余重试次数,则重试。
3. 初始化重试:

总结:该重试的blockFetcher 引入了中间层,即自定义的RetryingBlockFetchListener 监听器,来完成重试或事件的传播机制(即调用原来的监听器的抓取失败成功对应方法)以及需要抓取的blockId列表的更新,重试次数的更新等操作。
MapOutputTracker
类说明
MapOutputTracker 是一个定位跟踪 stage 的map 输出位置的类,driver 和 executor 有对应的实现,分别是 MapOutputTrackerMaster 和 MapOutputTrackerWorker。
其类结构如下:

成员变量
trackerEndpoint:它是一个EndpointRef对象,是driver端 MapOutputTrackerMasterEndpoint 的在executor的代理对象。
epoch:The driver-side counter is incremented every time that a map output is lost. This value is sent to executors as part of tasks, where executors compare the new epoch number to the highest epoch number that they received in the past. If the new epoch number is higher then executors will clear their local caches of map output statuses and will re-fetch (possibly updated) statuses from the driver.
eposhLock: 一个锁对象
核心方法
1. 向driver端trackerEndpoint 发送消息

2. excutor 获取每一个shuffle中task 需要读取的范围的 block信息,partition范围包头不包尾。

3. 删除指定的shuffle的状态信息

4. 停止服务
![]()
其子类MapOutputTrackerMaster 和 MapOutputTrackerWorker在后续shuffle 剖许再作进一步说明。
ShuffleManager
类说明
它是一个可插拔的shuffle系统,ShuffleManager 在driver和每一个executor的SparkEnv中基于spark.shuffle.manager参数创建,driver使用这个类来注册shuffle,executor或driver本地任务可以请求ShuffleManager 来读写任务。
类结构

1. registerShuffle:Register a shuffle with the manager and obtain a handle for it to pass to tasks.
2. getWriter:Get a writer for a given partition. Called on executors by map tasks.
3. getReader:Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive). Called on executors by reduce tasks.
4. unregisterShuffle:Remove a shuffle's metadata from the ShuffleManager.
5. shuffleBlockResolver:Return a resolver capable of retrieving shuffle block data based on block coordinates.
6. stop:Shut down this ShuffleManager.
其有唯一子类 SortShuffleManager,我们在剖析spark shuffle 过程时,再做进一步说明。
下面,我们来看Spark存储体系里面的重头戏 -- BlockManager
BlockManager
类说明
Manager running on every node (driver and executors) which provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap).
Note that initialize( ) must be called before the BlockManager is usable.
它运行在每一个节点上(drievr或executor),提供写或读本地或远程的block到各种各样的存储介质中,包括磁盘、堆内内存、堆外内存。
构造方法

其中涉及的变量,之前基本上都已作说明,不再说明。
这个类结构非常庞大,不再展示类结构图。下面分别对其成员变量和比较重要的方法做一下说明。
成员变量

externalShuffleServiceEnabled: 是否启用外部shuffle 服务,通过spark.shuffle.service.enabled 参数配置,默认是false
remoteReadNioBufferConversion:是否 xxxxx, 通过 spark.network.remoteReadNioBufferConversion 参数配置,默认是 false
diskBlockManager:DiskBlockManager对象,用于管理block和物理block文件的映射关系的
blockInfoManager:BlockInfoManager对象,Block读写锁
futureExecutionContext:ExecutionContextExecutorService 内部封装了一个线程池,线程前缀为 block-manager-future,最大线程数是 128
memoryStore:MemoryStore 对象,用于内存存储。
diskStore:DiskStore对象,用于磁盘存储。
maxOnHeapMemory:最大堆内内存
maxOffHeapMemory:最大堆外内存
externalShuffleServicePort: 外部shuffle 服务端口,通过 spark.shuffle.service.port 参数设置,默认为 7337
blockManagerId:BlockManagerId 对象是blockManager的唯一标识
shuffleServerId:BlockManagerId 对象,提供shuffle服务的BlockManager的唯一标识
shuffleClient:如果启用了外部存储,即externalShuffleServiceEnabled为true,使用ExternalShuffleClient,否则使用通过构造参数传过来的 blockTransferService 对象。
maxFailuresBeforeLocationRefresh:下次从driver刷新block location时需要重试的最大次数。通过spark.block.failures.beforeLocationRefresh 参数来设置,默认时 5
slaveEndpoint:BlockManagerSlaveEndpoint的ref对象,负责监听处理master的请求。
asyncReregisterTask:异步注册任务
asyncReregisterLock:锁对象
cachedPeers:Spark集群中所有的BlockManager
peerFetchLock:锁对象,用于获取spark 集群中所有的blockManager时用
lastPeerFetchTime:最近获取spark 集群中所有blockManager的时间
blockReplicationPolicy:BlockReplicationPolicy 对象,它有两个子类 BasicBlockReplicationPolicy 和 RandomBlockReplicationPolicy。
remoteBlockTempFileManager:RemoteBlockDownloadFileManager 对象
maxRemoteBlockToMem:通过 spark.maxRemoteBlockSizeFetchToMem 参数控制,默认为整数最大值 - 512
核心方法[简版]
注:未做过多的分析,大部分内容在之前内存存储和磁盘存储中都已涉及。
1. 初始化方法

思路:初始化 blockReplicationPolicy, 可以通过参数 spark.storage.replication.policy 来指定,默认为 RandomBlockReplicationPolicy;初始化BlockManagerId并想driver注册该BlockManager;初始化shuffleServerId
2. 重新想driver注册blockManager方法:

思路: 通过 BlockManagerMaster 想driver 注册 BlockManager
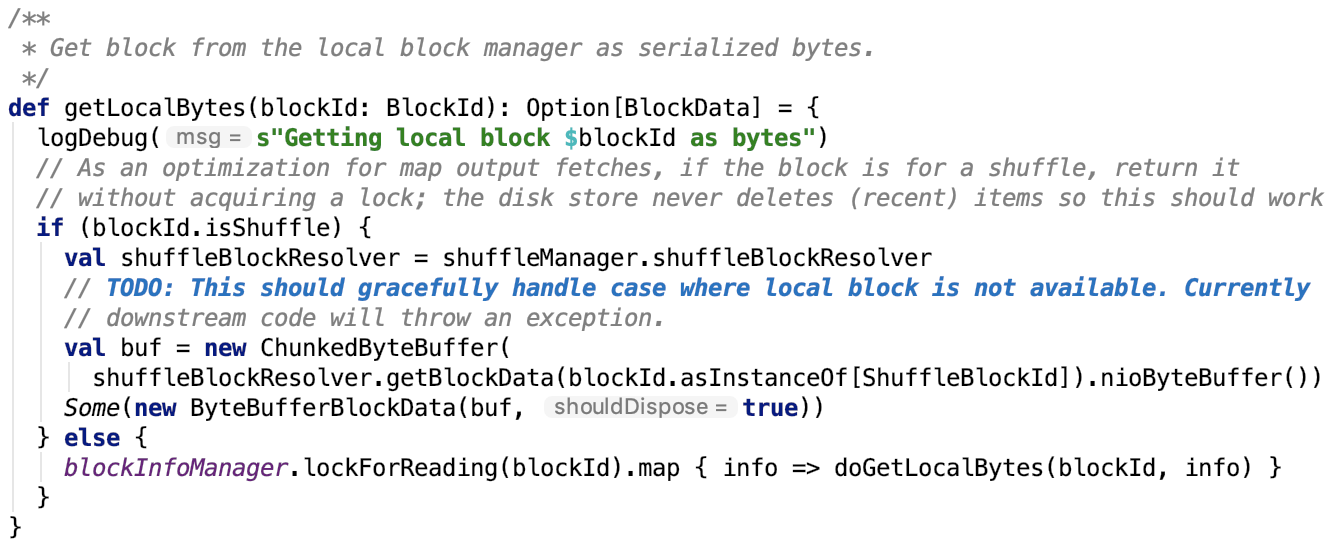
3. 获取block数据,如下:

其依赖方法 getLocalBytes 如下,思路:如果是shuffle的数据,则通过shuffleBlockResolver获取block信息,否则使用BlockInfoManager加读锁后,获取数据。
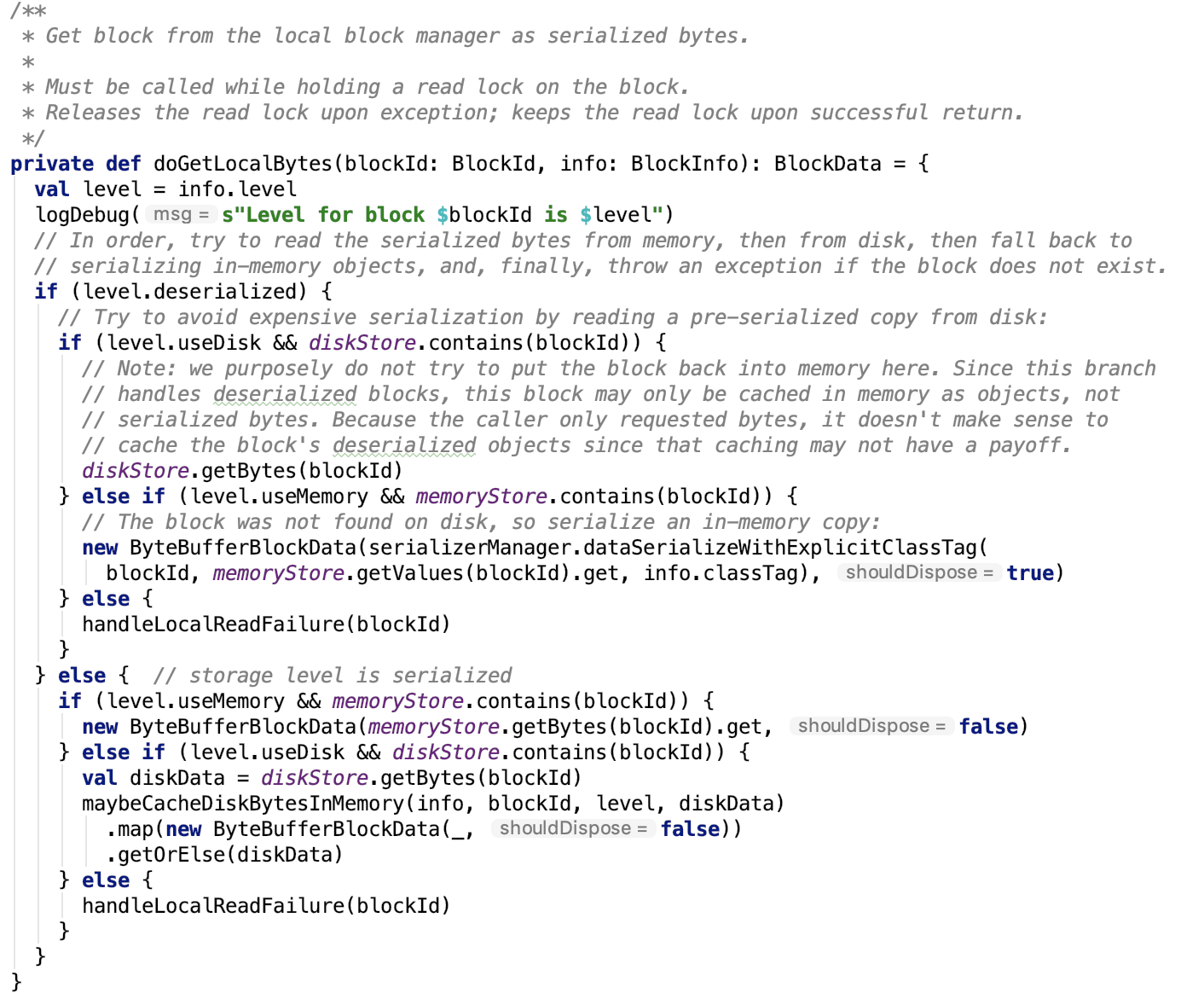
doGetLocalBytes 方法如下,思路:按照是否需要反序列化、是否保存在磁盘中,做相应处理,操作直接依赖与MemoryStore和DiskStore。
4. 存储block数据,直接调用putBytes 方法:

其依赖方法如下,直接调用doPutBytes 方法:
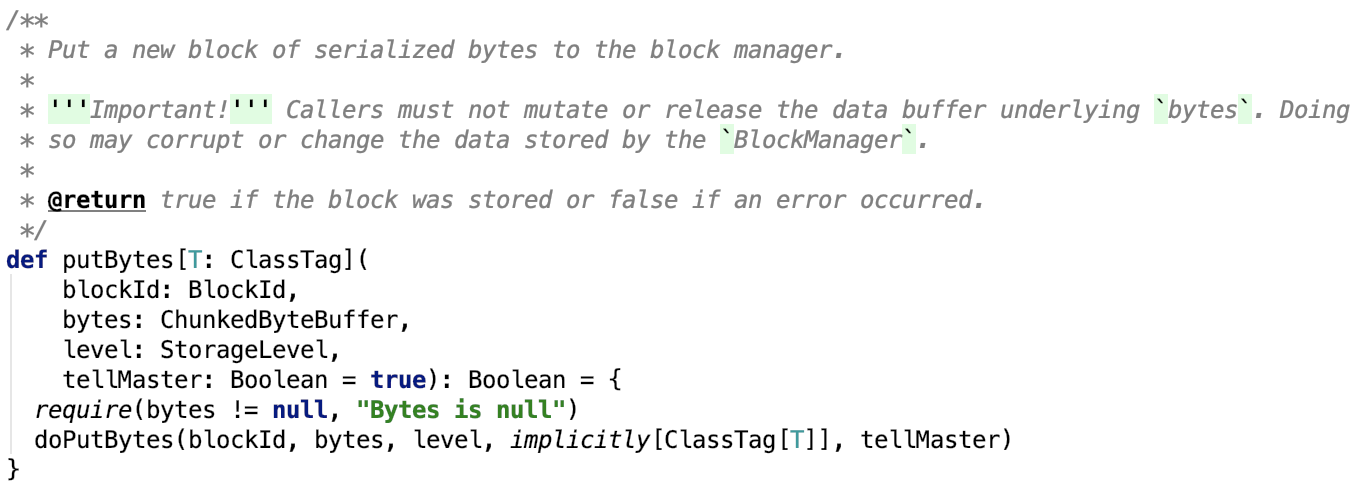
doPutBytes 方法如下:

doPut 方法如下,思路,加写锁,执行putBody方法:

5. 保存序列化之后的字节数据

6. 保存java对象:

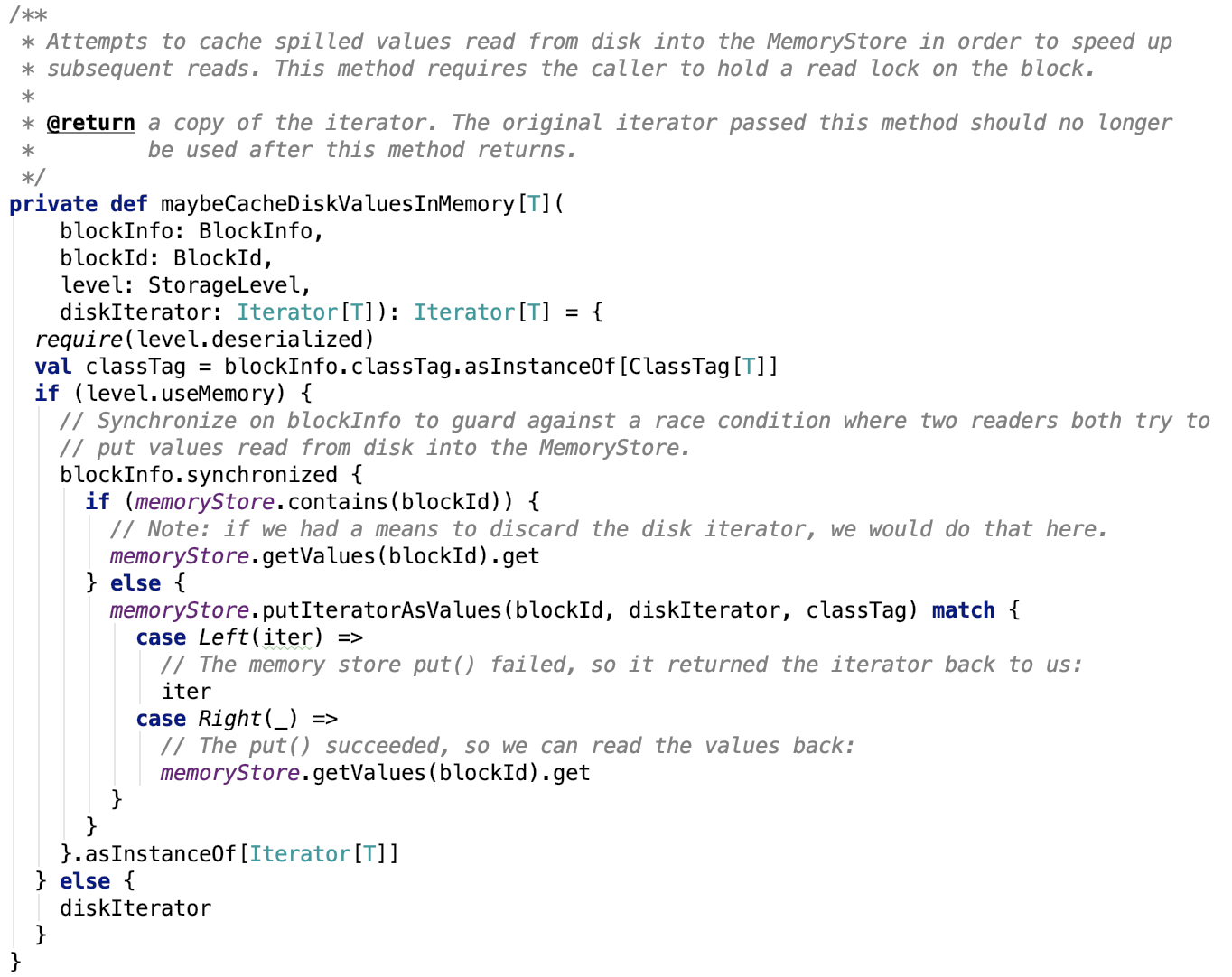
7. 缓存读取的数据在内存中:

8. 获取Saprk 集群中其他的BlockManager信息:

9. 同步block到其他的replicas:
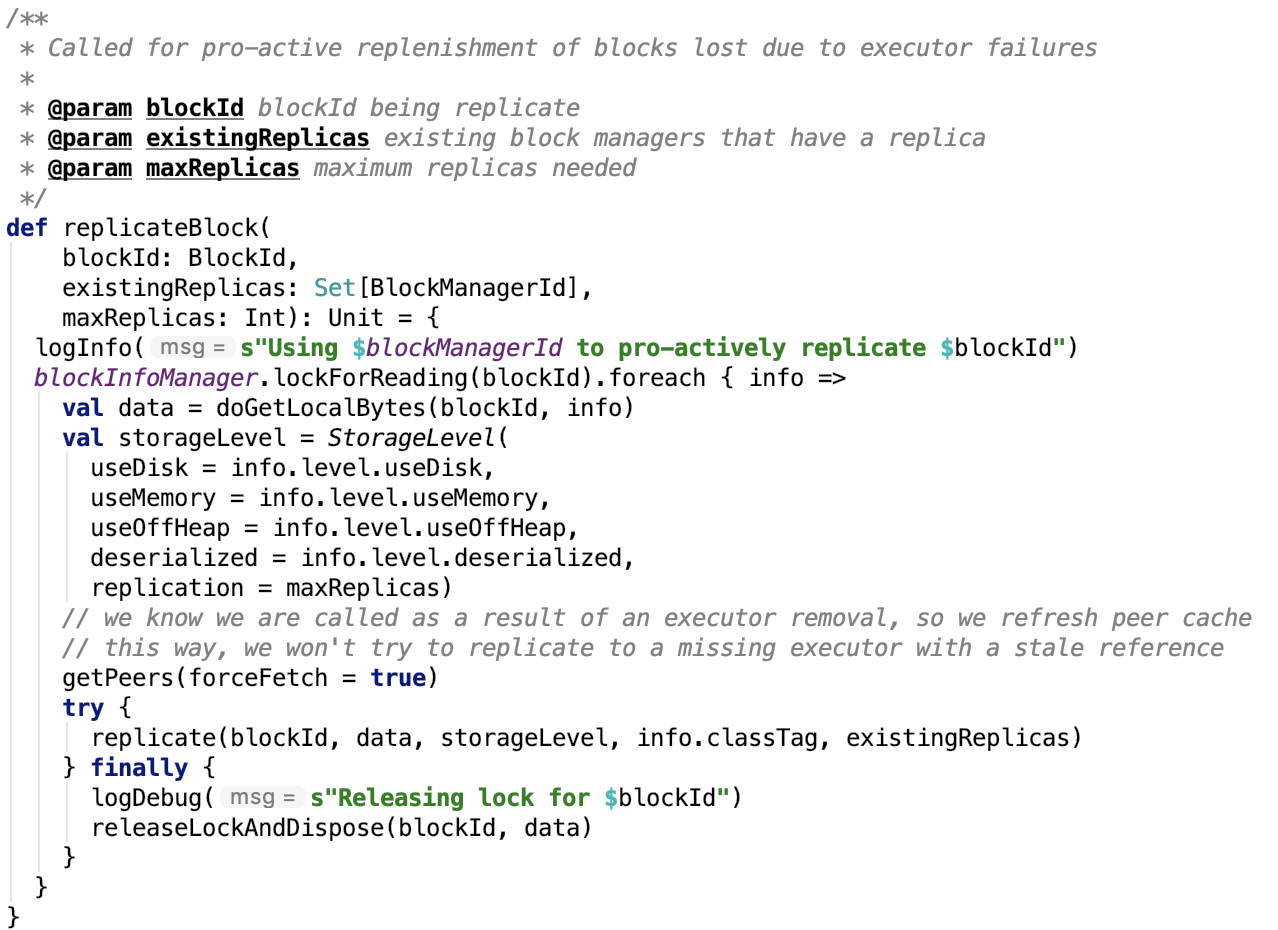
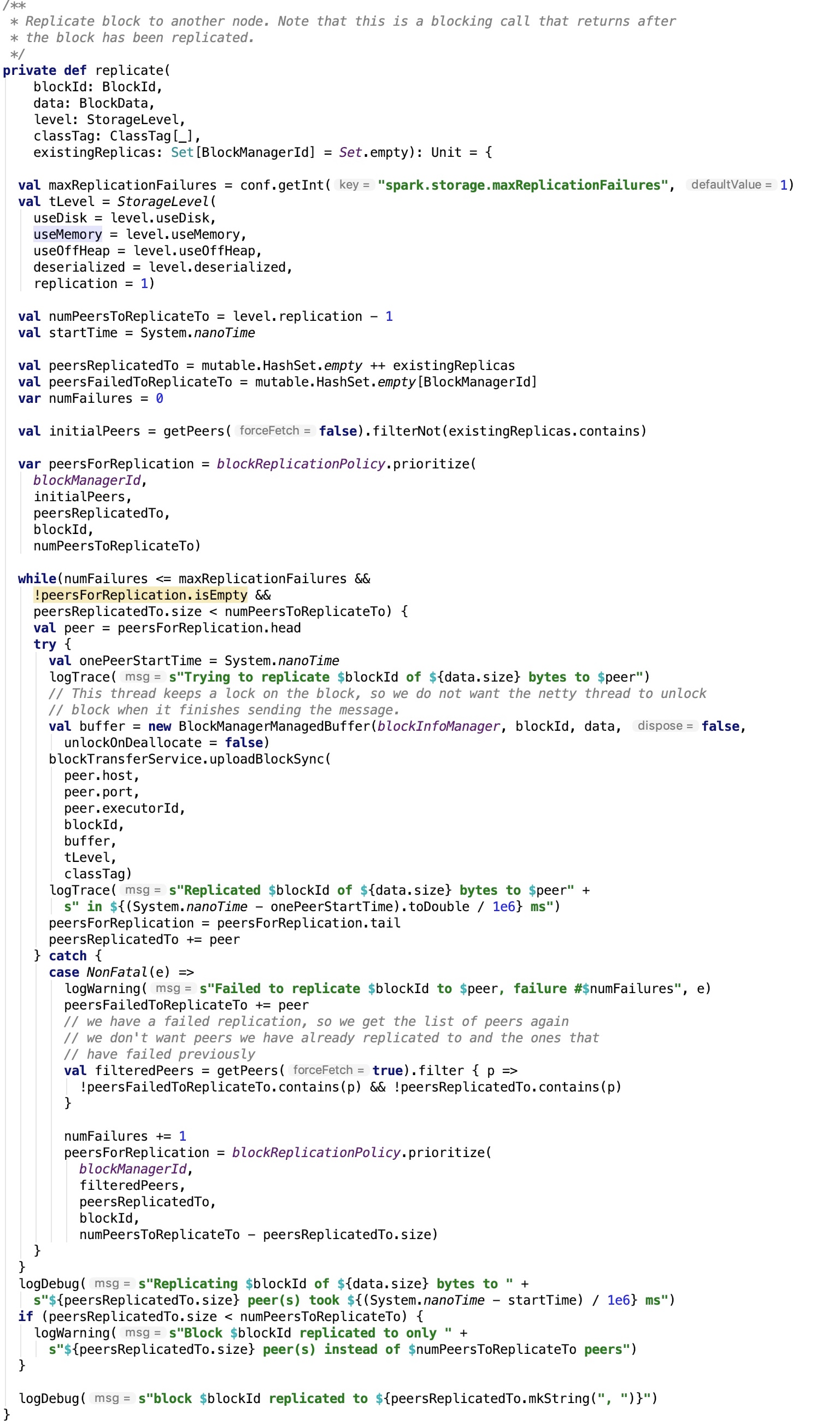
其依赖方法如下:
10.把block从内存中驱逐:

11. 移除block:

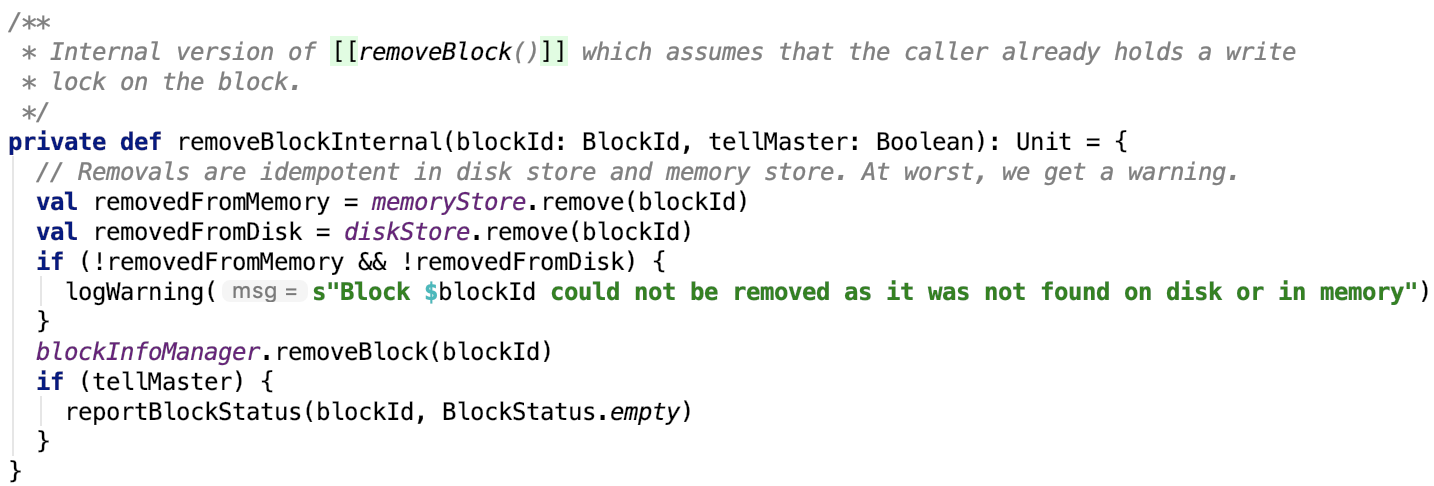
12. 停止方法

BlockManager 主要提供写或读本地或远程的block到各种各样的存储介质中,包括磁盘、堆内内存、堆外内存。获取Spark 集群的BlockManager的信息、驱逐内存中block等等方法。
其远程交互依赖于底层的netty模块。有很多的关于存储的方法都依赖于MemoryStore和DiskStore的实现,不再做一一解释。
总结
本篇文章介绍了Spark存储体系的最后部分内容。行文有些仓促,有一些类可能会漏掉,但对于理解Spark 存储体系已经绰绰有余。本地存储依赖于MemoryStore和DiskStore,远程调用依赖于NettyBlockTransferService、BlockManagerMaster、MapOutputTracker等,其底层绝大多数依赖于netty与driver或其他executor通信。
Spark shuffle、broadcast等也是依赖于存储系统的。接下来将进入spark的核心部分,去探索Spark底层的RDD是如何构建Stage作业以及每一个作业是如何工作的。

