spark 源码分析之十六 -- Spark内存存储剖析
上篇spark 源码分析之十五 -- Spark内存管理剖析 讲解了Spark的内存管理机制,主要是MemoryManager的内容。跟Spark的内存管理机制最密切相关的就是内存存储,本篇文章主要介绍Spark内存存储。
总述
跟内存存储的相关类的关系如下:
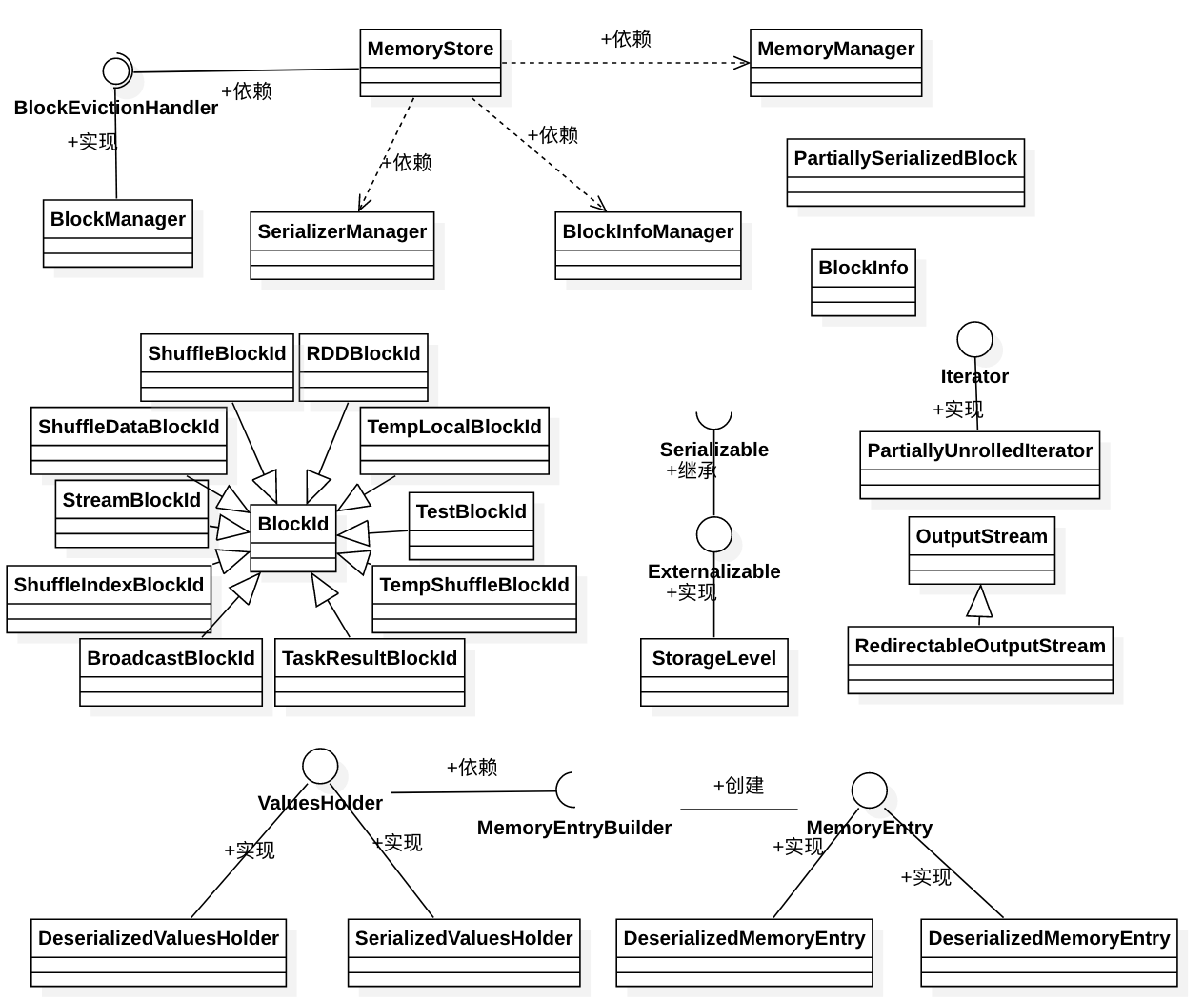
MemoryStore是负责内存存储的类,其依赖于BlockManager、SerializerManager、BlockInfoManager、MemoryManager。
BlockManager是BlockEvictionHandler的实现类,负责实现dropFromMemory方法,必要时从内存中把block丢掉,可能会转储到磁盘上。
SerializerManager是负责持久化的一个类,可以参考文章spark 源码分析之十三 -- SerializerManager剖析做深入了解。
BlockInfoManager是一个实现了对block读写时的一个锁机制,具体可以看下文。
MemoryManager 是一个内存管理器,从Spark 1.6 以后,其存储内存池大小和执行内存池大小是可以动态扩展的。即存储内存和执行内存必要时可以从对方内存池借用空闲内存来满足自己的使用需求。可以参考文章 spark 源码分析之十五 -- Spark内存管理剖析 做深入了解。
BlockInfo 保存了跟block相关的信息。
BlockId的name不同的类型有不同的格式,代表不同的block类型。
StorageLevel 表示block的存储级别,它本身是支持序列化的。
当存储一个集合为序列化字节数组时,失败的结果由 PartiallySerializedBlock 返回。
当存储一个集合为Java对象数组时,失败的结果由 PartiallyUnrolledIterator 返回。
RedirectableOutputStream 是对另一个outputstream的包装outputstream,负责直接将数据中转到另一个outputstream中。
ValueHolder是一个内存中转站,其有一个getBuilder方法可以获取到MemoryEntryBuilder对象,该对象会负责将中转站的数据转换为对应的可以保存到MemStore中的MemoryEntry。
我们逐个来分析其源码:
BlockInfo
它记录了block 的相关信息。
level: StorageLevel 类型,代表block的存储级别
classTag:block的对应类,用于选择序列化类
tellMaster:block 的变化是否告知master。大部分情况下都是需要告知的,除了广播的block。
size: block的大小(in byte)
readerCount:block 读的次数
writerTask:当前持有该block写锁的taskAttemptId,其中 BlockInfo.NON_TASK_WRITER 表示非 task任务 持有锁,比如driver线程,BlockInfo.NO_WRITER 表示没有任何代码持有写锁。
BlockId
A Block can be uniquely identified by its filename, but each type of Block has a different set of keys which produce its unique name. If your BlockId should be serializable, be sure to add it to the BlockId.apply() method.
其子类,在上图中已经标明。
BlockInfoManager
文档介绍如下:
Component of the BlockManager which tracks metadata for blocks and manages block locking. The locking interface exposed by this class is readers-writer lock. Every lock acquisition is automatically associated with a running task and locks are automatically released upon task completion or failure. This class is thread-safe.
它有三个成员变量,如下:
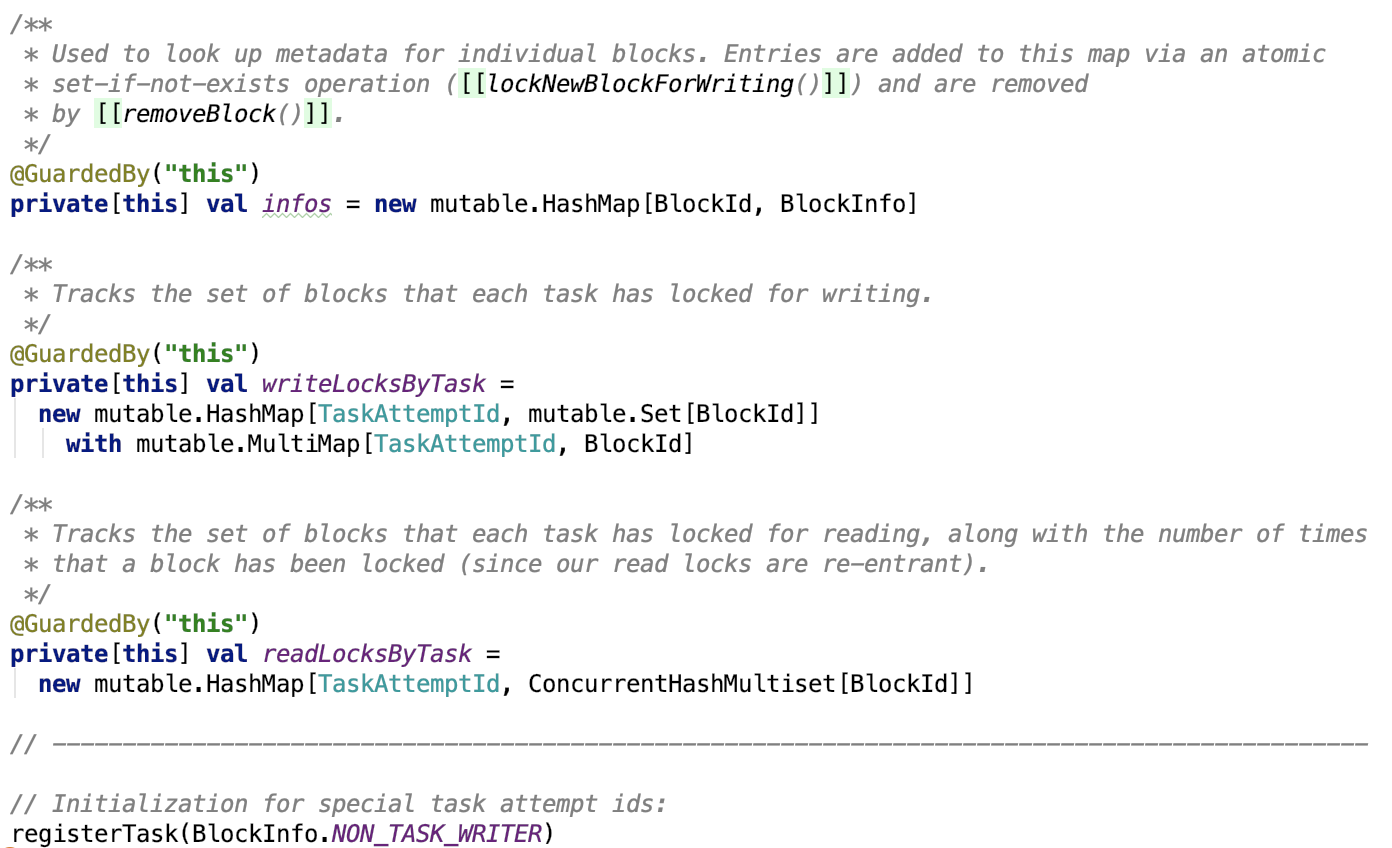
infos 保存了 Block-id 和 block信息的对应关系。
writeLocksByTask 保存了每一个任务和任务持有写锁的block-id
readLockByTasks 保存了每一个任务和任务持有读锁的block-id,因为读锁是可重入的,所以 ConcurrentHashMultiset 是支持多个重复值的。
方法如下:

1. 注册task

2. 获取当前task

3. 获取读锁

思路:如果block存在,并且没有task在写,则直接读即可,否则进入锁等待区等待。
4. 获取写锁
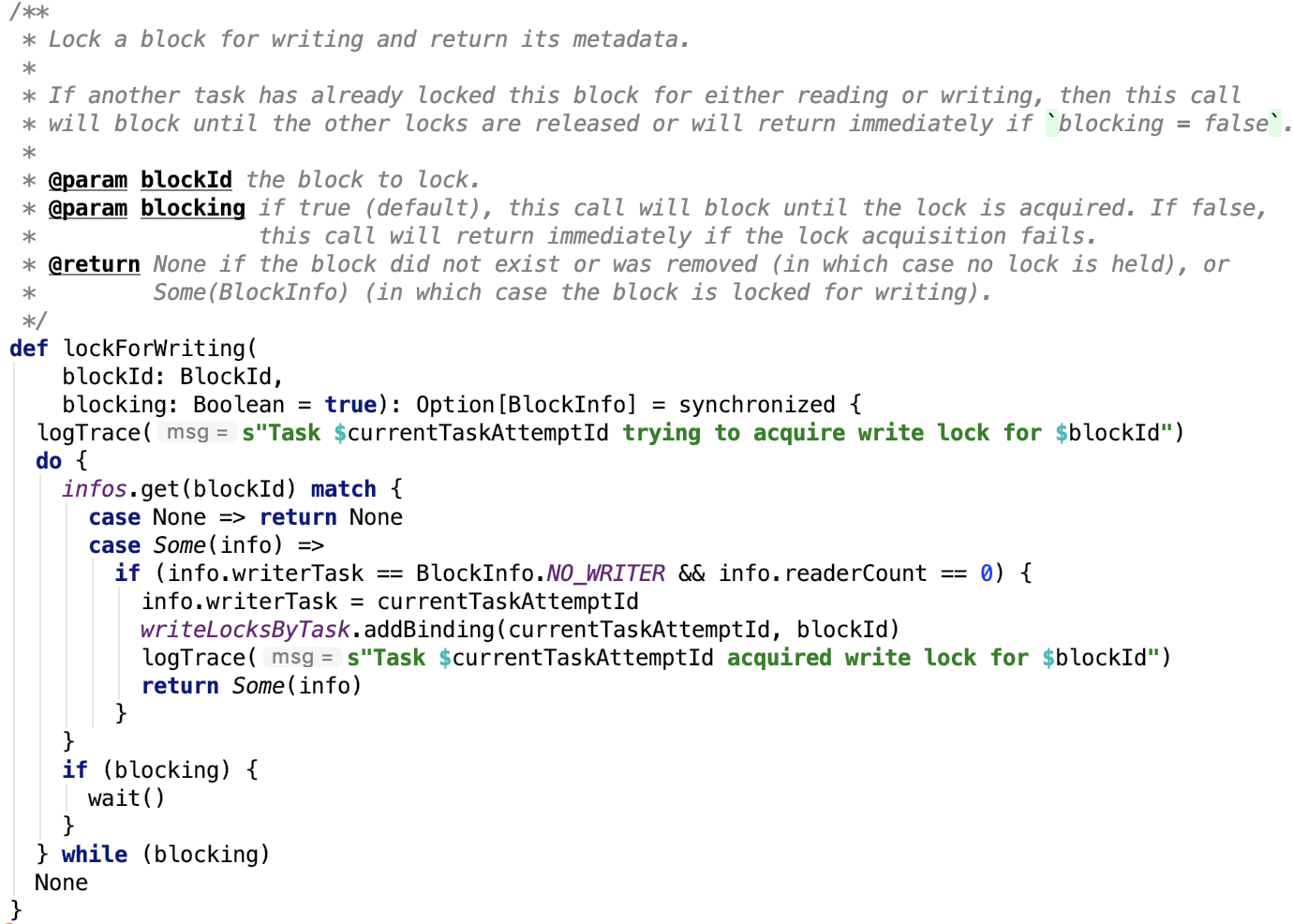
思路:如果block存在,且没有task在读,也没有task在写,则在写锁map上记录task,表示已获取写锁,否则进入等待区等待
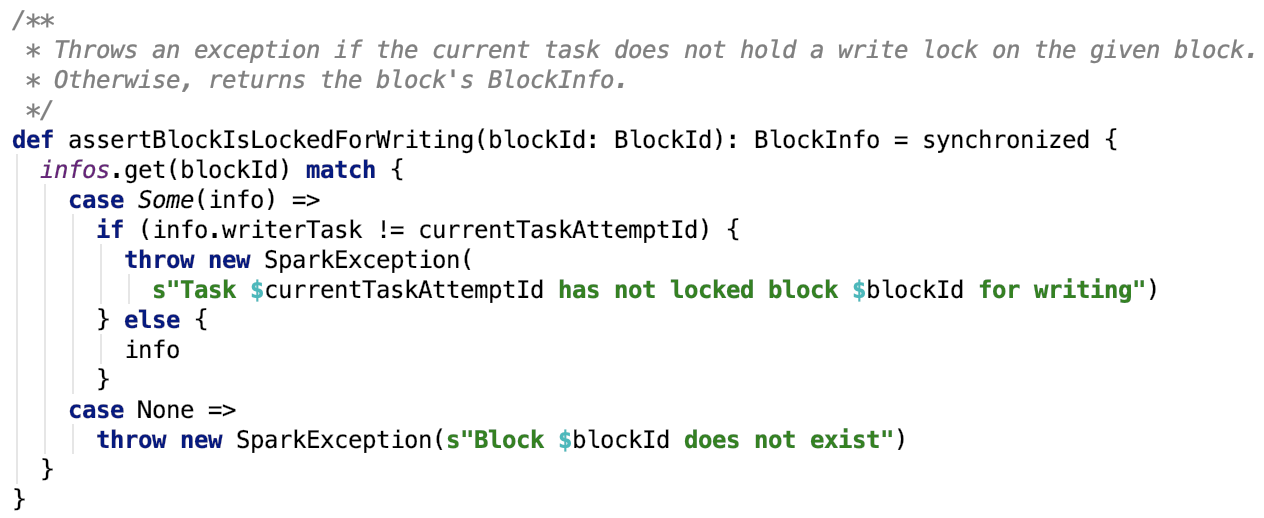
5. 断言有task持有写锁写block
6. 写锁降级

思路:首先把和block绑定的task取出并和当前task比较,若是同一个task,则调用unlock方法
7. 释放锁:
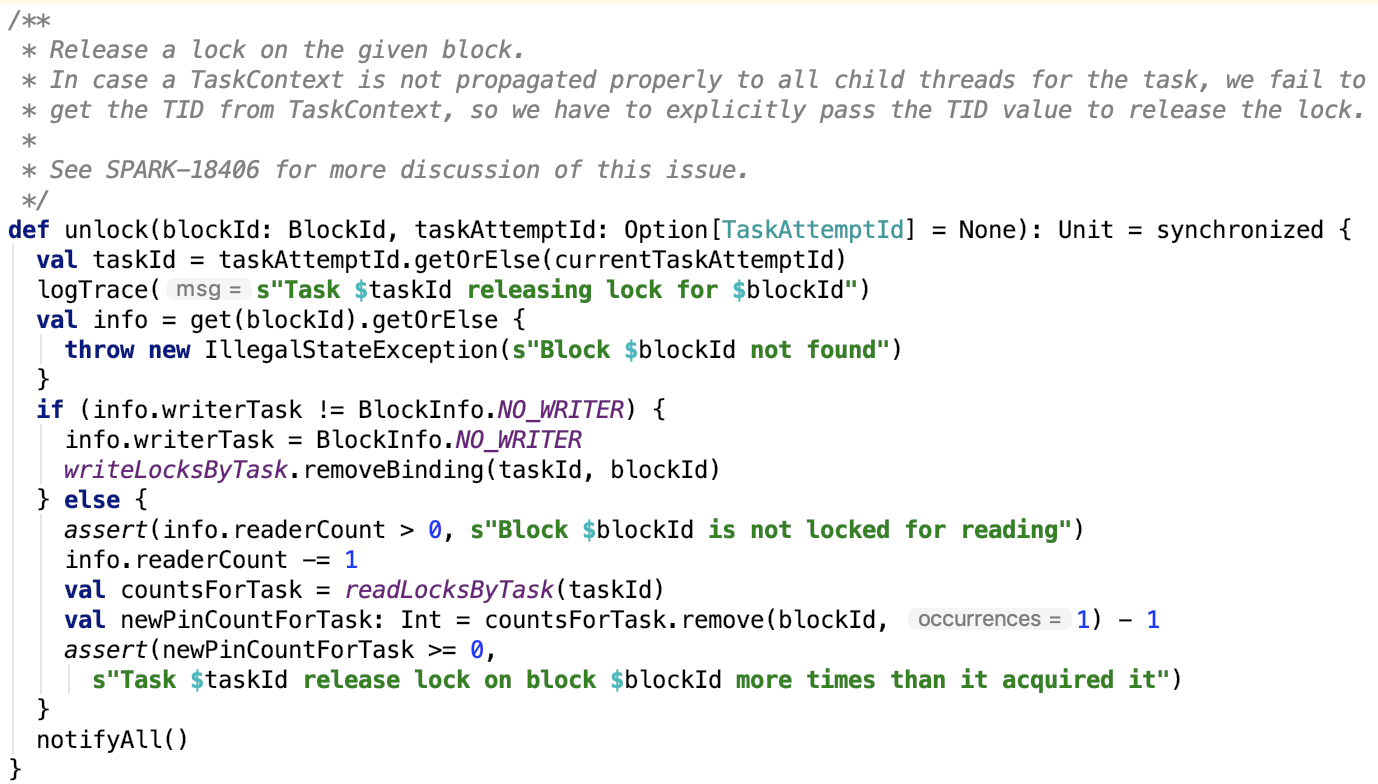
思路:若当前任务持有写锁,则直接释放,否则读取次数减1,并且从读锁记录中删除一条读锁记录。最后唤醒在锁等待区等待的task。
8. 获取为写一个新的block获取写锁

9. 释放掉指定task的所有锁
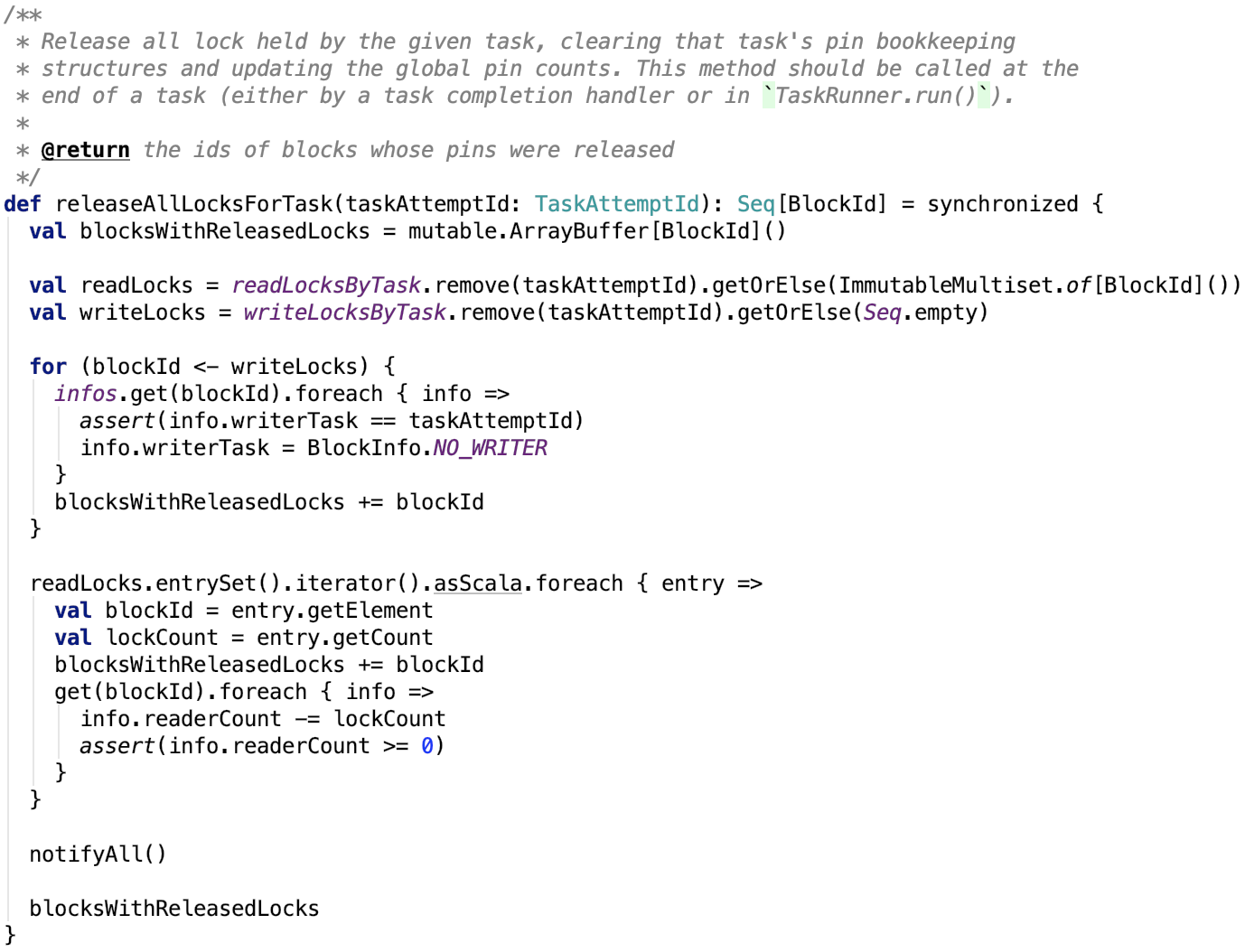
思路:先获取该task的读写锁记录,然后移除写锁记录集中的每一条记录,移除读锁记录集中的每一条读锁记录。
10. 移除并释放写锁
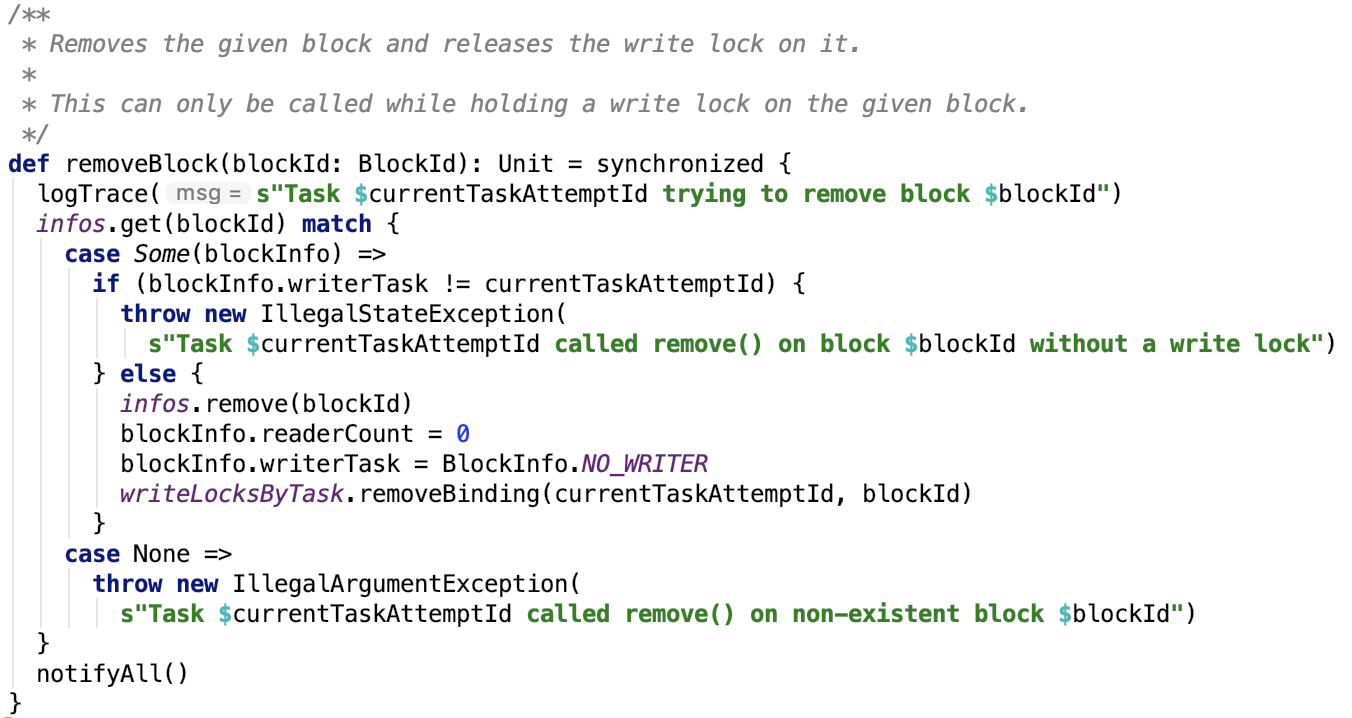
读写锁记录清零,解除block-id和block信息的绑定。
还有一些查询方法,不再做详细说明。
简单总结一下:
读锁支持可重入,即可以重复获取读锁。可以获取读锁的条件是:没有task在写该block,对有没有task在读block没有要求。
写锁当且仅当一个task获取,可以获取写锁的条件是:没有task在读block,没有task在写block。
注意,这种设计可以用在一个block的读的次数远大于写的次数的情况下。我们可以来做个假设:假设一个block写的次数远超过读的次数,同时多个task写同一个block的操作就变成了串行的,写的效率,因为只有一个BlockInfoManager对象,即一个锁,即所有在锁等待区等待的writer们都在竞争一个锁。对于读的次数远超过写的次数情况下,reader们可以肆无忌惮地读取数据数据,基本处于无锁情况下,几乎没有了锁切换带来的开销,并且可以允许不同task同时读取同一个block的数据,读的吞吐量也提高了。
总之,BlockInfoManager自己实现了block的一套读写锁机制,这种读写锁的设计思路是非常经典和值得学习的。
RedirectableOutputStream
文档说明:
A wrapper which allows an open [[OutputStream]] to be redirected to a different sink.
即这个类可以将outputstream重定向到另一个outputstream。
源码也很简单:

os成员变量就是重定向的目标outputstream
MemoryEntry
memoryEntry本质上就是内存中一个block,指向了存储在内存中的真实数据。
如上图,它有两个子类:

其中,DeserializedMemoryEntry 是用来保存反序列化之后的java对象数组的,value是一个数据,保存着真实的反序列化数据,size表示,classTag记录着数组中被擦除的数据的Class类型,这种数据只能保存在堆内内存中。
SerializedMemoryEntry 是用来保存序列化之后的ByteBuffer数组的,buffer中记录的是真实的Array[ByteBuffer]数据。memoryMode表示数据存储的内存区域,堆外内存还是堆内内存,classTag记录着序列化前被擦除的数据的Class类型,size表示字节数据大小。
MemoryEntryBuilder

build方法将内存数据构建到MemoryEntry中
ValuesHolder
本质上来说,就是一个内存中转站。数据被临时写入到这个中转站,然后调用其getBuilder方法获取 MemoryEntryBuilder 对象,这个对象用于构建MemoryEntry 对象。

storeValues用于写入数据,estimateSize用于评估holder中内存的大小。调用getBuilder之后会返回 MemoryEntryBuilder对象,后续可以拿这个builder创建MemoryEntry
调用getBuilder之后,会关闭流,禁止数据写入。
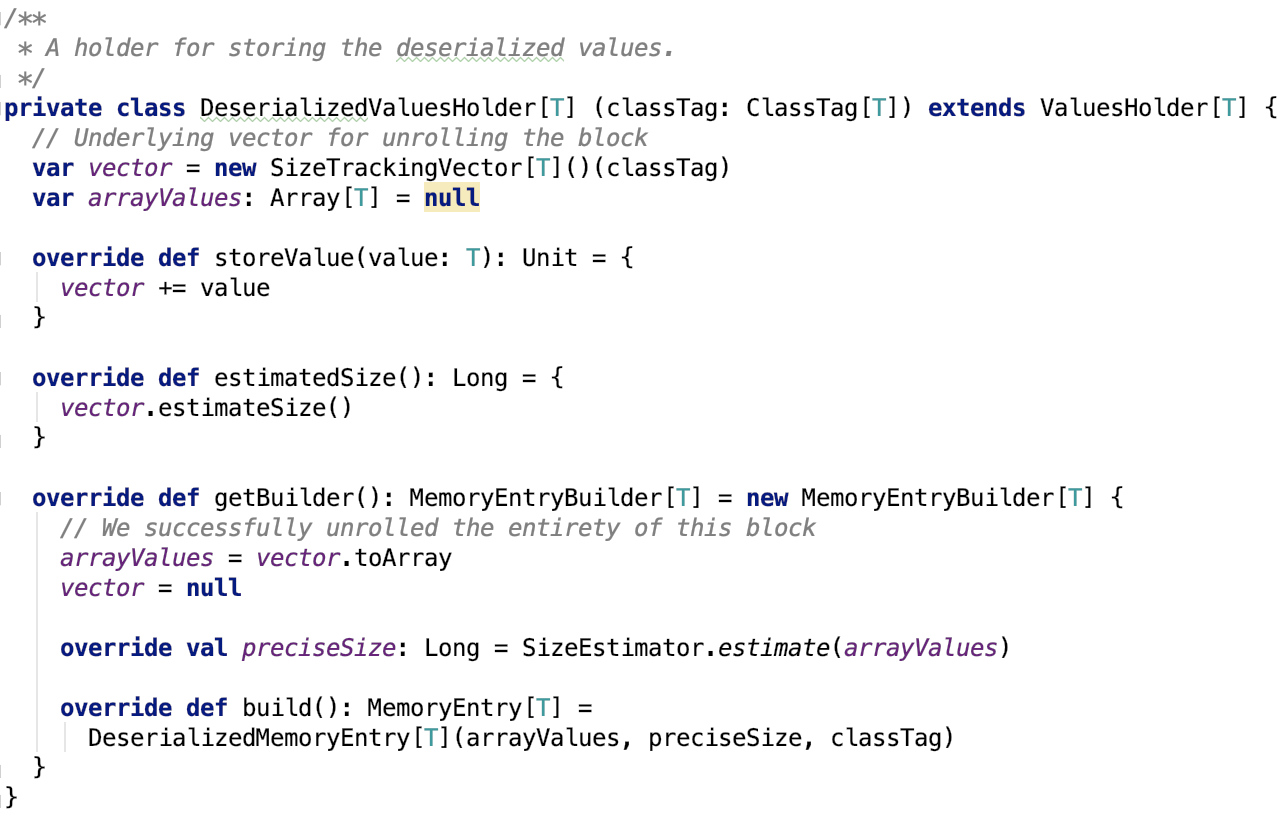
它有两个子类:用于中转Java对象的DeserializedValuesHolder和用于中转字节数据的SerializedValuesHolder。
其实现类具体如下:
1. DeserializedValuesHolder
2. SerializedValuesHolder

接下来,我们看一下Spark内存存储中的重头戏 -- MemoryStore
MemoryStore
文档说明:
Stores blocks in memory, either as Arrays of deserialized Java objects or as serialized ByteBuffers.
类内部结构如下:

对成员变量的说明:

entries 本质上就是在内存中保存blockId和block内容的一个map,它的 accessOrder为true,即最近访问的会被移动到链表尾部。
onHeapUnrollMemoryMap 记录了taskAttemptId和需要摊开一个block需要的堆内内存大小的关系
offHeapUnrollMemoryMap 记录了taskAttemptId和需要摊开一个block需要的堆外内存大小的关系
unrollMemoryThreshold 表示在摊开一个block 之前给request分配的初始内存,可以通过 spark.storage.unrollMemoryThreshold 来调整,默认是 1MB
下面,开门见山,直接剖析比较重要的方法:
1. putBytes:这个方法只被BlockManager调用,其中_bytes回调用于生成直接被缓存的ChunkedByteBuffer:
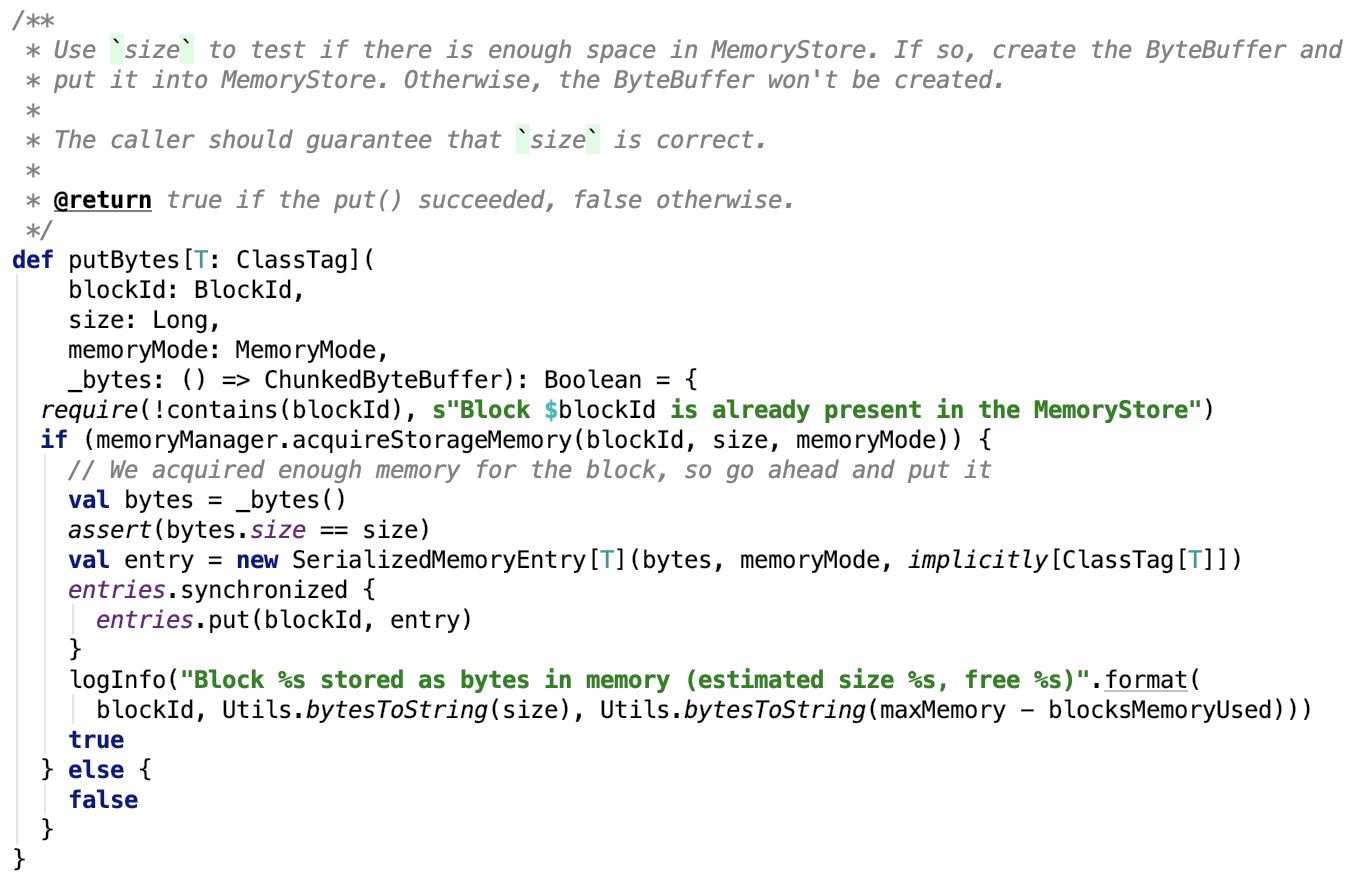
思路:先从MemoryManager中申请内存,如果申请成功,则调用回调方法 _bytes 获取ChunkedByteBuffer数据,然后封装成 SerializedMemoryEntry对象 ,最后将封装好的SerializedMemoryEntry对象缓存到 entries中。
2. 把迭代器中值保存为内存中的Java对象
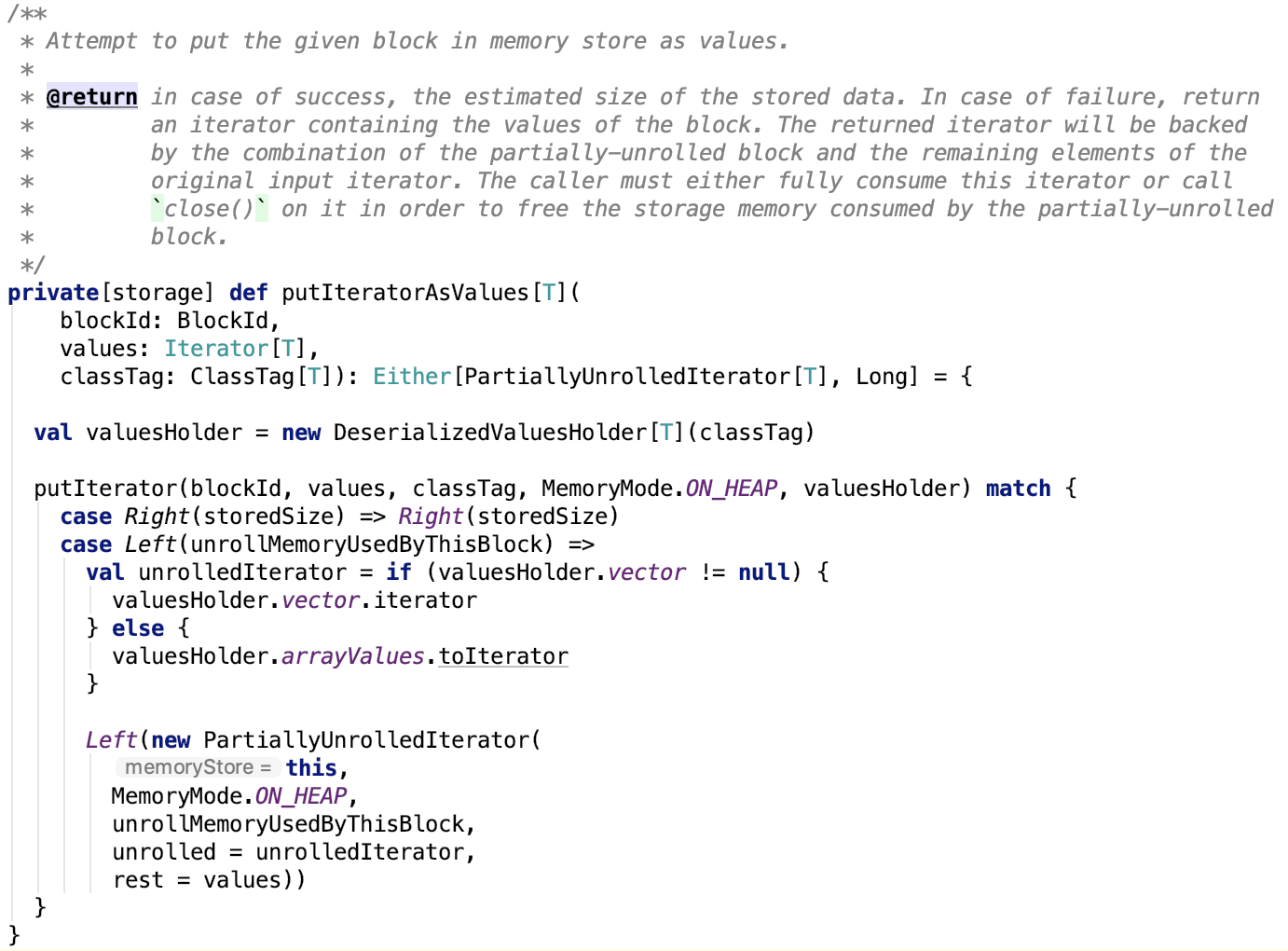
思路:转换为DeserializedValueHolder对象,进而调用putIterator方法,ValueHolder就是一个抽象,使得putIterator既可以缓存序列化的字节数据又可以缓存Java对象数组。
3. 把迭代器中值保存为内存中的序列化字节数据

思路:转换为 SerializedValueHolder 对象,进而调用putIterator方法。
MAX_ROUND_ARRARY_LENGTH和unrollMemoryThreshold的定义如下:
1 public static int MAX_ROUNDED_ARRAY_LENGTH = Integer.MAX_VALUE - 15;
2 private val unrollMemoryThreshold: Long = conf.getLong("spark.storage.unrollMemoryThreshold", 1024 * 1024)
unrollMemoryThreshold 默认是 1MB,可以通过 spark.storage.unrollMemoryThreshold 参数调整大小。
4. putIterator方法由参数ValueHolder,使得缓存字节数据和Java对象可以放到一个方法来。 方法2跟3 都调用了 putIterator 方法,如下:

思路:
第一步:定义摊开内存初始化大小,摊开内存增长率,摊开内存检查频率等变量。
第二步:向MemoryManager请求申请摊开初始内存,若成功,则记录这笔摊开内存。
第三步:然后进入223~240行的while循环,在这个循环里:
- 循环条件:如果还有值需要摊开并且上次内存申请是成功的,则继续进行该次循环
- 不断想ValueHolder中add数据。如果摊开的元素个数不是UNROLL_MEMORY_CHECK_PERIOD的整数倍,则摊开个数加1;否则,查看ValueHolder中的内存是否大于了已分配内存,若大于,则请求MemoryManager分配内存,并将分配的内存累加到已分配内存中。
第四步:
若上一次向MemoryManager申请内存成功,则从ValueHolder中获取builder,并且计算准确内存开销。查看准确内存是否大于了已分配内存,若大于,则请求MemoryManager分配内存,并将分配的内存累加到已分配内存中。
否则,否则打印内存使用情况,返回为摊开该block申请的内存
第五步:
若上一次向MemoryManager申请内存成功,首先调用MemoryEntryBuilder的build方法构建出可以直接存入内存的MemoryEntry,并向MemoryManager请求释放摊开内存,申请存储内存,并确保存储内存申请成功。最后将数据存入内存的entries中。
否则打印内存使用情况,返回为摊开该block申请的内存
其实之前不是很理解unroll这个词在这里的含义,一直译作摊开,它其实指的就是集合的数据转储到中转站这个操作,摊开内存指这个操作需要的内存。
下面来看一下这个方法里面依赖的常量和方法:
4. 1 unrollMemoryThreshold 在上一个方法已做说明。UNROLL_MEMORY_CHECK_PERIOD 和 UNROLL_MEMORY_GROWTH_FACTOR 常量定义如下:

即,UNROLL_MEMORY_CHECK_PERIOD默认是16,UNROLL_MEMORY_GROWTH_FACTOR 默认是 1.5
4.2 reserveUnrollMemoryForThisTask方法源码如下,思路大致上是先从MemoryManager 申请摊开内存,若成功,则根据memoryMode在堆内或堆外记录摊开内存的map上记录新分配的内存。

4.3 releaseUnrollMemoryForThisTask方法如下,实现思路:先根据memoryMode获取到对应记录堆内或堆外内存的使用情况的map,然后在该task的摊开内存上减去这笔内存开销,如果减完之后,task使用内存为0,则直接从map中移除对该task的内存记录。

4.4 日志打印block摊开内存和当前内存使用情况

5. 获取缓存的值:

思路:直接根据blockId从entries中取出MemoryEntry数据,然后根据MemoryEntry类型取出数据即可。
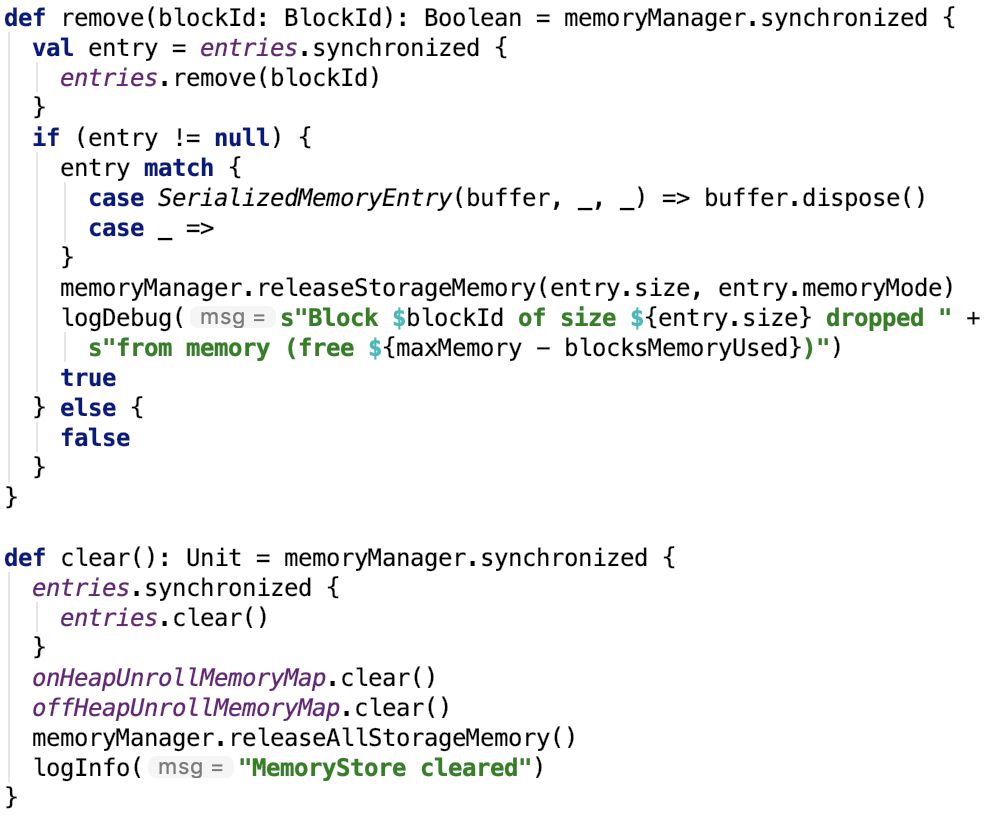
6. 移除Block或清除缓存,比较简单,不做过多说明:
7. 尝试驱逐block来释放指定大小的内存空间来存储给定的block,代码如下:

该方法有三个参数:要分配内存的blockId,block大小,内存类型(堆内还是堆外)。
第 469~485 行:dropBlock 方法思路: 先从MemoryEntry中获取data,再调用 BlockManager从内存中驱逐出该block,如果该block 的StorageLevel允许落地到磁盘,则先落到磁盘,再从内存中删除之,最后更新该block的StorageLevel,最后检查新的StorageLevel,若该block还在内存或磁盘中,则释放锁,否则,直接从BlockInfoManager中删除之。
第 443 行: 找到block对应的rdd。
第451~467 行:先给entries上锁,然后遍历entries集合,检查block 是否可以从内存中驱逐,若可以则把它加入到selectedBlocks集合中,并把该block大小累加到freedMemory中。
461行的 lockForWriting 方法,不堵塞,即如果第一次拿不到写锁,则一直不停地轮询,直到可以拿到写锁为止。那么问题来了,为什么要先获取写锁呢?因为写锁具有排他性并且不具备可重入性,一旦拿到写锁,其他锁就不能再访问该block了。
487行~ 528 行:若计划要释放的内存小于存储新block需要的内存大小,则直接释放写锁,不从内存中驱逐之前选择的block,直接返回。
若计划要释放的内存不小于存储新block需要的内存大小,则遍历之前选择的每一个block,获取entry,并调用dropMemory方法,返回释放的内存大小。finally 代码块是防止在dropMemory过程中,该线程被中断,其余block写锁不能被释放的情况。
其依赖的方法如下:

存储内存失败之后,会返回 PartiallySerializedBlock 或者 PartiallyUnrolledIterator。
PartiallyUnrolledIterator 是一个Iterator,可以用来遍历block数据,同时负责释放摊开内存。
PartiallySerializedBlock 它可以将失败的block转化成 PartiallyUnrolledIterator 用来遍历,可以直接丢弃失败的block,也可以把数据转储到给定的可以落地的outputstream中,同时释放摊开内存。
总结:
本篇文章主要讲解了Spark的内存存储相关的内容,重点讲解了BlockInfoManager实现的锁机制、跟ValuesHolder中转站相关的MemoryEntry、EmmoryEntryBuilder等相关内容以及内存存储中的重头戏 -- MemStore相关的Block存储、Block释放、为新Block驱逐内存等等功能。

