
MySQL系列之日志汇总:redo log、undo log、binlog、errorlog、slow query log、general log、relay log
概述
MySQL中至少有7种日志文件:
- 重做日志(redo log)
- 回滚日志(undo log)
- 二进制日志(binlog)
- 错误日志(errorlog)
- 慢查询日志(slow query log)
- 一般查询日志(general log)
- 中继日志(relay log)。
MySQL Server Log有4种:Error Log、General Query Log、Binary Log 和 Slow Query Log。其中重做日志和回滚日志与事务操作息息相关,二进制日志也与事务操作有一定的关系。注:老版本MySQL还有更新日志(Update Log),参考,被二进制日志替代。
redo log
作用:
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启MySQL服务时,可根据redo log进行重做,从而达到事务的持久性这一特性。
内容:
物理格式的日志,记录的是物理数据页面的修改的信息,其redo log是顺序写入redo log file的物理文件中去的。
创建时间:
事务开始之后就产生redo log,redo log的落盘并不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo log文件中。
删除时间:
当对应事务的脏页写入到磁盘之后,redo log的使命完成,重做日志占用的空间就可以重用(被覆盖)。
对应的物理文件:
默认情况下,对应的物理文件位于数据库的data目录下的ib_logfile1, ib_logfile2,innodb_log_group_home_dir 指定日志文件组所在的路径,默认./,表示在数据库的数据目录下。
redolog的大小是固定的,MySQL中可通过修改以下2个配置参数,redolog采用循环写的方式记录,当写到结尾时,会回到开头循环写日志:
innodb_log_file_size:文件大小
innodb_log_files_in_group:文件数量,默认2
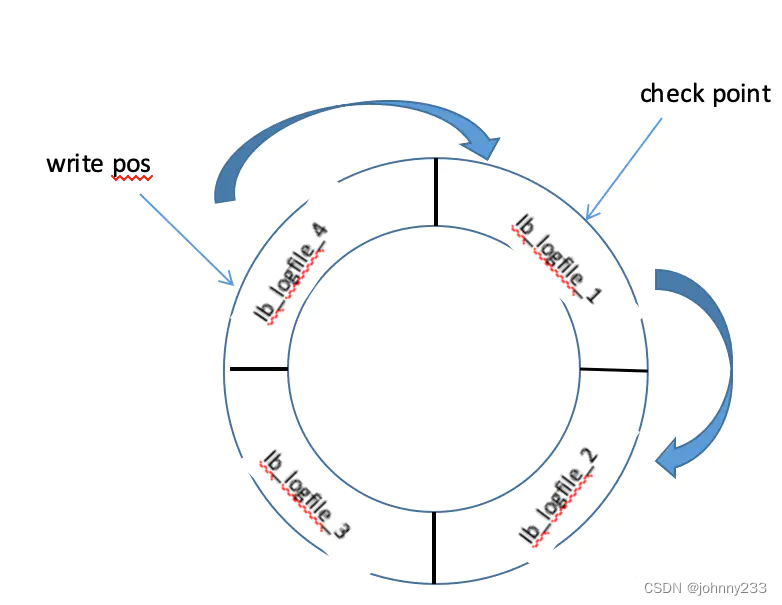
write pos表示日志当前记录的位置,当ib_logfile_4写满后,会从ib_logfile_1从头开始记录;check point表示将日志记录的修改写进磁盘,完成数据落盘,数据落盘后checkpoint会将日志上的相关记录擦除掉,即write pos->checkpoint之间的部分是redo log空着的部分,用于记录新的记录,checkpoint->write pos之间是redo log待落盘的数据修改记录。当writepos追上checkpoint时,得先停下记录,先推动checkpoint向前移动,空出位置记录新的日志。
innodb_mirrored_log_groups:指定日志镜像文件组的数量,默认1
redo log是在事务开始之后逐步写盘的。重做日志是在事务开始之后逐步写入重做日志文件,而不一定是事务提交才写入重做日志缓存,原因,重做日志有一个缓存区innodb_log_buffer,其默认大小为8M,Innodb存储引擎先将重做日志写入innodb_log_buffer中。
以下三种情况触发innodb_log_buffer日志刷新到磁盘:
- Master Thread 每秒一次执行刷新
innodb_log_buffer到重做日志文件 - 每个事务提交时会将重做日志刷新到重做日志文件
- 当重做日志缓存可用空间 少于一半时,重做日志缓存被刷新到重做日志文件
重做日志通过不止一种方式写入到磁盘,尤其是对于第一种方式,innodb_log_buffer到redo log是Master Thread线程的定时任务。重做日志的写盘,并不一定是随着事务的提交才写入重做日志文件的,而是随着事务的开始,逐步开始的。
即使某个事务还没有提交,Innodb存储引擎仍然每秒会将重做日志缓存刷新到重做日志文件。
这可以很好地解释再大的事务的提交(commit)的时间也是很短暂的。《MySQL技术内幕 Innodb 存储引擎》
undo log
作用:
保存事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
内容:
逻辑格式的日志,在执行undo时,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。
创建时间:
事务开始之前,将当前的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性。
删除时间:
当事务提交之后,undo log并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
对应的物理文件:
MySQL5.6之前,undo表空间位于共享表空间的回滚段中,共享表空间的默认的名称是ibdata,位于数据文件目录中。
MySQL5.6之后,undo表空间可以配置成独立的文件,但是提前需要在配置文件中配置,完成数据库初始化后生效且不可改变undo log文件的个数
如果初始化数据库之前没有进行相关配置,那么就无法配置成独立的表空间。
MySQL5.7之后的独立undo表空间配置参数如下:
innodb_undo_directory = /data/undospace/ –undo独立表空间的存放目录
innodb_undo_logs = 128 –回滚段为128KB
innodb_undo_tablespaces = 4 –指定有4个undo log文件
如果undo使用的共享表空间,这个共享表空间中又不仅仅是存储undo的信息,共享表空间的默认为与MySQL的数据目录下面,其属性由参数innodb_data_file_path配置:innodb_data_file_path=ibdata1:1G:autoextend
其他:
undo是在事务开始之前保存的被修改数据的一个版本,产生undo日志时,同样会伴随类似于保护事务持久化机制的redolog的产生。
默认情况下undo文件是保持在共享表空间的,也即ibdatafile文件中,当数据库中发生一些大的事务性操作时,要生成大量的undo信息,全部保存在共享表空间中的。
因此共享表空间可能会变的很大,默认情况下,也就是undo 日志使用共享表空间的时候,被“撑大”的共享表空间是不会也不能自动收缩的。
因此,mysql5.7之后的“独立undo 表空间”的配置就显得很有必要了。
redo log vs undo log
同:
异:
redo log 记录数据的物理变化,binlog记录数据的逻辑变化;
redo log的作用是为持久化而生的。写完内存,如果数据库挂了,那我们可以通过redo log来恢复内存还没来得及刷到磁盘的数据,将redo log加载到内存里边,那内存就能恢复到挂掉之前的数据了。
binlog
官方文档,binlog是MySQL server层维护的一种二进制日志,与InnoDB引擎中的redo/undo log是完全不同的日志。
binlog记录数据库表结构和表数据变更,比如update/delete/insert/truncate/create,为复制和恢复而生的,哪怕整个数据库都被删除。主从服务器需要保持数据的一致性,通过binlog来同步数据。
作用:
- 复制:从库利用主库上的binlog进行重播,实现主从同步,达到master-slave数据一致的目的
- 恢复:通过mysqlbinlog工具实现基于时间点的数据恢复
创建时间:
事务提交时,一次性将事务中的SQL语句(一个事务可能对应多个SQL语句)按照一定的格式记录到binlog中。
redo log并不一定是在事务提交时刷新到磁盘,redo log是在事务开始之后就开始逐步写入磁盘。
因此对于事务的提交,即便是较大的事务,提交(commit)都是很快的,但是在开启bin_log的情况下,对于较大事务的提交,可能会变得比较慢一些。
这是因为binlog是在事务提交的时候一次性写入的造成的,这些可以通过测试验证。
删除时间:
binlog默认保留时间由参数expire_logs_days配置,也就是说对于非活动的日志文件,在生成时间超过expire_logs_days配置的天数之后,会被自动删除。show variables like '%expire_logs_days%';
参数
通过命令查看binlog相关的参数:show variables like '%binlog%';
binlog_cache_size:在事务过程中容纳binlog SQL语句的缓存大小;binlog缓存是服务器支持事务存储引擎并且服务器启用二进制日志(—log-bin选项)的前提下为每个Session分配的内存;
主要是用来提高binlog的写速度;可以通过MySQL的以下2个状态变量来判断当前的binlog_cache_size的状况:binlog_cache_use(使用缓冲区存放binlog的次数)和binlog_cache_disk_use(使用临时文件存放binlog的次数)。binlog_stmt_cache_size:发生事务时非事务语句的缓存的大小,可通过MySQL以下2个状态变量来判断当前的binlog_stmt_cache_size的状况:binlog_stmt_cache_use(缓冲区存放binlog的次数)和binlog_stmt_cache_disk_use(临时文件存放binlog的次数)。max_binlog_cache_size:和binlog_cache_size相对应,但是所代表的是binlog能够使用的最大cache内存大小;binlog_cache_size对应的每个Session,max_binlog_cache_size对应所有Session;当执行多语句事务的时候,所有Session的使用的内存超过max_binlog_cache_size的值时,系统可能会报出”Multi-statement transaction required more than ‘max_binlog_cache_size’ bytes of storage”的错误。max_binlog_stmt_cache_size:同max_binlog_cache_size类似,非事务语句binlog能够使用的最大cache内存大小。max_binlog_size:binlog日志最大值,默认1G。该大小并不能非常严格控制binlog大小,当binlog比较靠近尾部而又遇到一个较大事务时,系统为了保证事务的完整性,不可能做切换日志的动作,只能将该事务的所有SQL都记录进入当前日志,直到该事务结束。sync_binlog:同步binlog_cache中数据到磁盘的频率。sync_binlog=n(可选值区间为0-4294967295),表示当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。默认设置为0,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让FileSystem自行决定什么时候来做同步,或cache满之后才同步到磁盘;这种情况下性能最好,风险最大,可能导致binlog_cache中的数据丢失;sync_binlog=1性能最差,风险最小。binlog_direct_non_transactional_updates:innodb_locks_unsafe_for_binlog:max_binlog_stmt_cache_size:binlog_format:设置binlog的格式,可选值:STATEMENT(默认), ROW, MIXED
日志格式
-
STATEMENT模式
statement-based replication,SBR。每一条修改数据的SQL都会被记录到binlog中,slave端再根据SQL语句重现,不会产生大量的binlog数据;
优点:不需要记录每一行的变化,减少binlog日志量,节约IO提高性能。
缺点:为了让SQL能在slave端正确重现,需要记录SQL的执行上下文信息;在复制某些特殊的函数或者功能时会出现问题,比如sleep()函数。 -
ROW模式
row-based replication,RBR。5.1.5版本的MySQL开始支持,日志中记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。在ROW模式下bin-log中可以不记录执行的SQL语句的上下文相关的信息,只需要记录哪条数据被修改成什么样,不会因为某些语法复制出现问题(比如function,trigger等);
缺点:每行数据的修改都会记录,最明显的就是update语句,导致更新多少条数据就会产生多少事件,使bin-log文件很大,而复制要网络传输,影响性能。
新版本的MySQL中对row level模式也被优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。 -
MIXED模式
mixed-based replication,MBR。从5.1.8版本开始,MySQL提供Mixed格式,前面两种模式的结合。在Mixed模式下,一般的语句修改使用statment格式保存binlog;如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog。MySQL会根据执行的每一条具体的SQL语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
事件
解析
binlog解析
工具
binlog vs redo log
当数据库发生宕机重启后,可通过redo log将未落盘的数据恢复,即保证已经提交的事务记录不会丢失。
已有redo log,为啥还需要binlog呢?
- redo log的大小是固定的,日志上的记录修改落盘后,日志会被覆盖掉,无法用于数据回滚/数据恢复等操作
- redo log是innodb引擎层实现,并不是所有引擎都有
另外:
- binlog是server层实现,所有引擎都可以使用binlog日志
- binlog通过追加的方式写入的,可通过配置参数
max_binlog_size设置每个binlog文件的大小,当文件大小大于给定值后,日志会发生滚动,之后的日志记录到新的文件上 - binlog有两种记录模式,statement格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。
binlog和redo log必须保持一致,不允许出现binlog有记录但redo log没有的情况,反之亦然。在一个事务中,redo log有prepare和commit两种状态,所以,在redo log状态为prepare时记录binlog可保证两日志的记录一致,
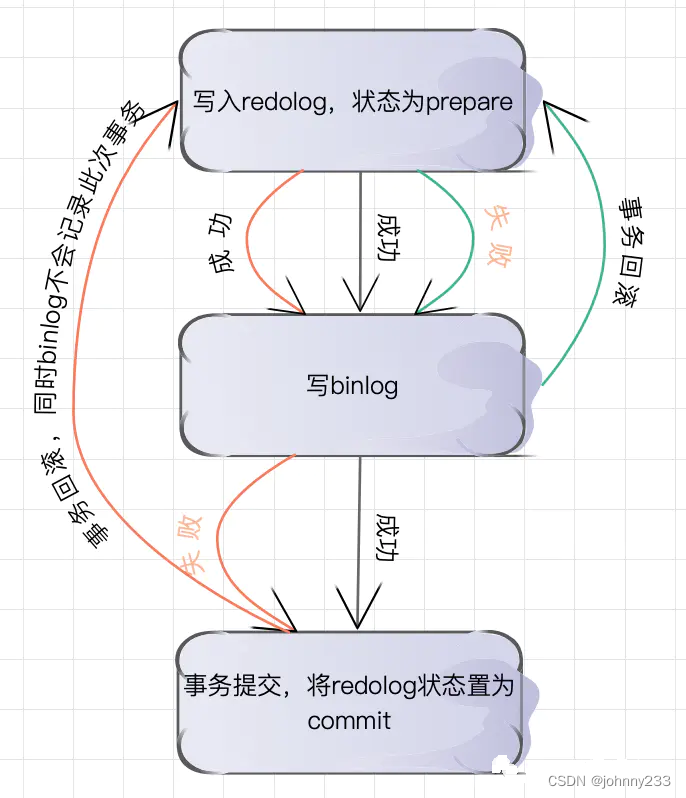
完整的流程图
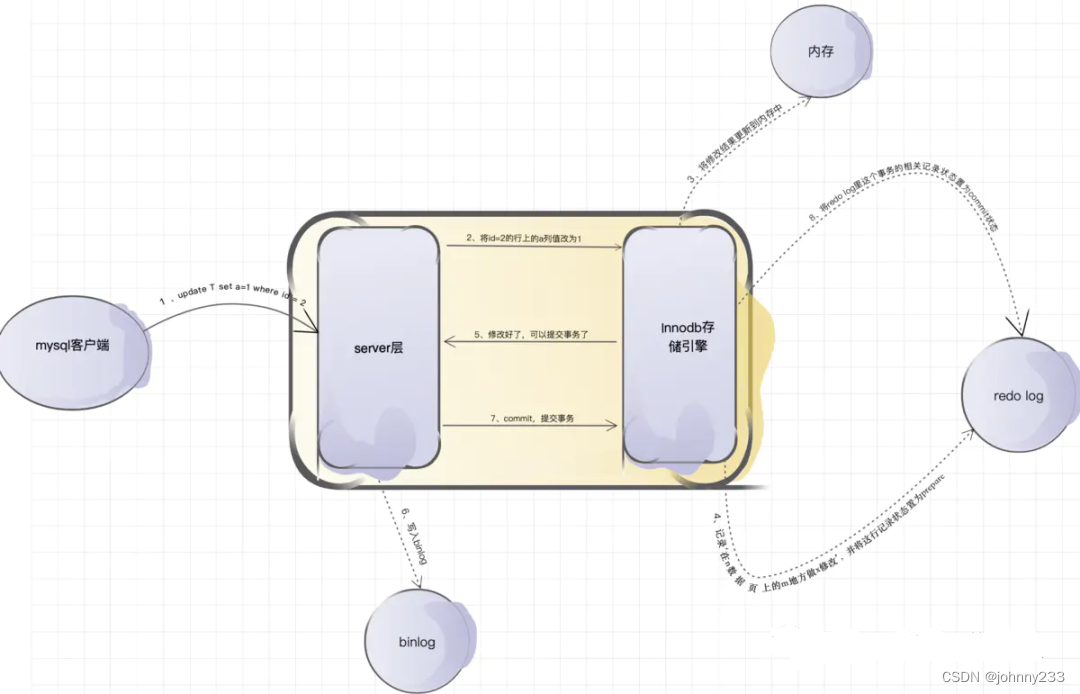
参数设置:
innodb_flush_log_at_trx_commit:设置为1,表示每次事务的redo log都直接持久化到磁盘,保证MySQL重启后数据不丢失sync_binlog:设置为1,表示每次事务的binlog都直接持久化到磁盘,保证MySQL重启后binlog记录完整
errorlog
记录mysqld启动和关闭过程的信息,启停slave以及死锁日志,bug,core dump等错误日志。
slow query log
MySQL的慢查询日志用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中(日志可以写入文件或者数据库表,如果对性能要求高的话,建议写文件)。默认情况下,MySQL数据库是不开启慢查询日志的,long_query_time的默认值为10(即10秒,通常设置为1秒)。
查询慢查询日志相关参数:show variables like '%query%';
- slow_query_log:ON为开启慢查询日志
- slow_query_log_file:指定慢查询日志保存到文件中(默认名为主机名.log)
- long_query_time:指定慢查询的阈值,默认值为10秒。
- log_queries_not_using_indexes 如果值设置为ON,则会记录所有没有利用索引的查询(注意:如果只是将log_queries_not_using_indexes设置为ON,而将slow_query_log设置为OFF,此时该设置也不会生效,即该设置生效的前提是slow_query_log的值设置为ON),一般在性能调优的时候会暂时开启。
如何查询当前慢查询语句的个数?
MySQL中有一个变量Slow_queries专门记录当前慢查询语句的个数:show global status like '%slow%';
查看慢查询日志的输出格式,可选值FILE、TABLE:show variables like '%log_output%';。
设置慢查询日志的输出格式,表为mysql.slow_log,英文逗号分隔:set global log_output='TABLE';
myql.slow_log表数据格式如下:
select * from mysql.slow_log limit 1;
| start_time | user_host | query_time | lock_time | rows_sent | rows_examined | db | last_insert_id | insert_id | server_id | sql_text | thread_id |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-0711:16:55 | root[root] @ [121.196.203.51] | 00:00:00 | 00:00:00 | 13 | 40 | jp_core_db | 0 | 0 | 0 | select pd.lastAuction from Product pd where pd.status = 'O’and pd.auctionStatus = ‘A’ | 1621 |
mysql_slow.log文件数据格式:
# Time: 180118 14:58:37# User@Host: root[root] @ localhost [] Id: 150# Query_time: 0.000270 Lock_time: 0.000109 Rows_sent: 0 Rows_examined: 6SET timestamp=1516258717;deletefrom user where User='app';
不管是表还是文件,都具体记录:是那条语句导致慢查询(sql_text),该慢查询语句的查询时间(query_time),锁表时间(Lock_time),以及扫描过的行数(rows_examined)等信息。
工具
MySQL自带慢查询日志分析工具mysqldumpslow,Perl语言写的:
mysqldumpslow –sc –t 10 slow-query.log
-s:表示按何种方式排序,c, t, l, r分别按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar表示相应的倒序
-t n, top:表示返回前面多少条数据
-g:正则表达式匹配,大小写不敏感
输出示例:Count: 66216 Time=0.00s (127s) Lock=0.00s (2s) Rows=1.7 (115074), root[root]@[121.196.200.51]
解释:
- Count表示语句出现次数;
- Time表示执行最长时间(累计总耗时)
- Lock表示等待锁最长时间(累计等待锁耗时)
- Rows表示发送给客户端最多的行数(累计发送给客户端的行数)
general log
记录建立的客户端连接和执行的语句。日志文件的存储格式可以是FILE、TABLE,与slow query log类似。set global log_output='TABLE';这种设置命令只对当前session生效,MySQL重启失效;如果要永久生效,需配置my.cnf。
配置:
general_log=ON,默认关闭
general_log_file=/mysql/general.log,配置文件名(含完整路径)
mysql.general_log表结构:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| event_time | timestamp | NO | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | |
| user_host | mediumtext | NO | NULL | ||
| thread_id | bigint(21) unsigned | NO | NULL | ||
| server_id | int(10) unsigned | NO | NULL | ||
| command_type | varchar(64) | NO | NULL | ||
| argument | mediumtext | NO | NULL |
relay log
官方文档:slave-logs-relaylog,MySQL进行主主复制或主从复制时会在配置文件制定的目录下面产生相应的relay log,查看所有relay log相关参数:show variables like '%relay%';
max_relay_log_size:标记relay log 允许的最大值,如果该值为0,则默认值为max_binlog_size(1G);relay_log:定义relay_log的位置和名称,如果值为空,则默认位置在数据文件的目录,文件名为host_name-relay-bin.nnnnnn(By default, relay log file names have the form host_name-relay-bin.nnnnnn in the data directory);relay_log_index:同relay_log,定义relay_log的位置和名称;relay_log_info_file:设置relay-log.info的位置和名称(relay-log.info记录MASTER的binary_log的恢复位置和relay_log的位置),也可以配置记录到MySQL库中的slave_relay_log_info表中;relay_log_purge:是否自动清空不再需要的中继日志。默认为ON(启用)。relay_log_recovery:当slave从库宕机后,假如relay-log损坏,导致一部分中继日志没有处理,则自动放弃所有未执行的relay_log,并且重新从master上获取日志,保证relay-log的完整性。默认情况下该功能是关闭的,设置relay_log_recovery=1,可在slave从库上开启该功能,建议开启。开启该参数需同时开启relay_log_purge参数。
This variable also interacts with relay-log-purge, which controls purging of logs when they are no longer needed. Enabling the --relay-log-recovery option when relay-log-purge is disabled risks reading the relay log from files that were not purged, leading to data inconsistency, and is therefore not crash-safe.
relay_log_space_limit:防止中继日志写满磁盘,设置中继日志最大限额。但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已,不推荐使用;sync_relay_log:参考sync_binlog,默认值10000,可动态修改,建议采用默认值。sync_relay_log_info:和sync_relay_log参数一样,当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay-log.info里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。当设置为0时,并不是马上就刷入relay-log.info里,而是由操作系统决定何时来写入,虽然安全性降低,但可以减少大量的磁盘I/O操作。默认值10000,可动态修改,建议采用默认值。relay_log_info_repository:输出TABLE,表示?relay_log_basename:relay_log_index去掉后缀名
复制过程和relay_log
??
relay_log vs binlog
日志清理
日志要站磁盘空间,且越来越多,故而需要定期清理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号